ZooKeeper+Kafka+ELK+Filebeat集群搭建实现大批量日志收集和展示
文章目录
- 一、集群环境准备
- 二、搭建 ZooKeeper 集群和配置
- 三、搭建 Kafka 集群对接zk
- 四、搭建 ES 集群和配置
- 五、部署 Logstash 消费 Kafka数据写入至ES
- 六、部署 Filebeat 收集日志
- 七、安装 Kibana 展示日志信息
一、集群环境准备
1.1 因为资源原因这里我就暂时先一台机器部署多个应用给大家演示
| 硬件资源 | 节点 | 组件 |
|---|---|---|
| 8c16g 50 | node1-192.168.40.162 | Kafka+ZooKeeper,ES-7.9.2+Logstash-7.9.2 |
| 8c16g 50 | node2-192.168.40.163 | Kafka+ZooKeeper,ES-7.9.2,Kibana-7.9.2 |
| 8c16g 50 | node3-192.168.40.164 | Kafka+ZooKeeper,ES-7.9.2,Filebeat-7.9.2,Elasticsearch-head |
二、搭建 ZooKeeper 集群和配置
2.1 修改时区 - 修改主机名 - 安装JDK环境变量 - 停防火墙(三台一样设置)
[root@node1 ~]# rm -f /etc/localtime && ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
[root@node1 ~]# date
#修改主机名
[root@node1 ~]# hostnamectl set-hostname node3
#检查JDK环境变量
[root@node1 ~]# java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
#停防火墙并关闭
[root@node1 ~]# systemctl stop firewalld && setenforce 0 && systemctl disable firewalld
#三台都设置同样的DNS解析
[root@node1 ~]# vim /etc/hosts
192.168.40.162 node1
192.168.40.163 node2
192.168.40.164 node3
2.1 安装 ZooKeeper
#下载zk安装包
[root@node1 ~]# wget http://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
#解压到指定目录并修改文件夹名
[root@node1 ~]# tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /usr/local/
[root@node1 ~]# mv /usr/local/apache-zookeeper-3.8.0-bin/ /usr/local/zookeeper-3.8.0
#备份原始配置文件
[root@node1 ~]# mv /usr/local/zookeeper-3.8.0/conf/zoo_sample.cfg /usr/local/zookeeper-3.8.0/conf/zoo.cfg
[root@node1 ~]# cp /usr/local/zookeeper-3.8.0/conf/zoo.cfg /usr/local/zookeeper-3.8.0/conf/zoo.cfg_bak
2.2 修改三台 zk 配置文件
[root@node1 ~]# vim /usr/local/zookeeper-3.8.0/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
#这个目录要自己创建不然启动会报错,省了重新创建一次
dataDir=/tmp/zookeeper
clientPort=2181
#集群地址
server.1=192.168.40.162:3188:3288
server.2=192.168.40.163:3188:3288
server.3=192.168.40.164:3188:3288
# 其他两台都执行以上的部署和修改文件,配置文件可以通过scp进行传输
[root@node1 ~]# cd /usr/local/zookeeper-3.8.0/conf/
[root@node1 ~]# scp zoo_sample.cfg 192.168.40.163:/usr/local/zookeeper-3.8.0/conf 192.168.40.164:/usr/local/zookeeper-3.8.0/conf
#创建文件并指定节点号 注意:每台都要执行,并且节点号不能相同 myid 必须在dataDir 数据目录下
[root@node1 ~]# echo 1 > /tmp/zookeeper/myid
[root@node2 ~]# echo 2 > /tmp/zookeeper/myid
[root@node3 ~]# echo 3 > /tmp/zookeeper/myid

2.3 启动 3台的 zk 并查看集群状态
#要三台都起起来 才能看到主从
[root@node1 ~]# sh /usr/local/zookeeper/bin/zkServer.sh start
[root@node1 ~]# sh /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader #主
[root@node2 ~]# sh /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower #从
[root@node2 ~]# sh /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower #从
三、搭建 Kafka 集群对接zk
3.1 安装 Kafka
#下载 kafka安装包
[root@node1 ~]# wget http://archive.apache.org/dist/kafka/2.7.1/kafka_2.13-2.7.1.tgz
#解压到指定目录
[root@node1 ~]# tar -zxvf kafka_2.13-2.7.1.tgz -C /usr/local/
[root@node1 ~]# mv /usr/local/kafka_2.13-2.7.1/ /usr/local/kafka
[root@node1 ~]# cp /usr/local/kafka/config/server.properties /usr/local/kafka/config/server.properties_bak
3.2 修改三台 zk 配置文件 并配置环境变量
[root@node1 ~]# vim /usr/local/kafka/config/server.properties
#borkerid 每台都不一样 不能重复
broker.id=1
#本地监听地址
listeners=PLAINTEXT://192.168.40.162:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zk 集群地址
zookeeper.connect=192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
#borkerid 每台都不一样 不能重复
broker.id=2
#本地监听地址
listeners=PLAINTEXT://192.168.40.163:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zk 集群地址
zookeeper.connect=192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
#borkerid 每台都不一样 不能重复
broker.id=3
#本地监听地址
listeners=PLAINTEXT://192.168.40.164:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zk 集群地址
zookeeper.connect=192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
[root@node1 ~]# vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@node1 ~]# source /etc/profile
3.3 启动kafka (命令可以在任意路径执行,不需要填写绝对路径)
[root@node1 ~]# sh /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
#检查端口
[root@node1 ~]# netstat -tunlp | grep 9092
3.4 Kafka常用命令行操作
#查看当前服务器中的所有topic
kafka-topics.sh --list --zookeeper 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
#查看某个topic的详情
kafka-topics.sh --describe --zookeeper 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181
#发布消息
kafka-console-producer.sh --broker-list 192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092 --topic test
#消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092 --topic test --from-beginning
--from-beginning 会把主题中以往所有的数据都读取出来
#修改分区数
kafka-topics.sh --zookeeper 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181 --alter --topic test --partitions 6
#删除topic
kafka-topics.sh --delete --zookeeper 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181 --topic test
3.5 Kafka命令创建Topic
[root@node1 ~]# sh /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper \
> 192.168.40.162:2181,192.168.40.163:2181,192.168.40.164:2181 \
> --partitions 3 \
> --replication-factor 2 \
> --topic test
Created topic test.
--zookeeper: 定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor: 定义分区副本数,1 代表单副本,建议为 2
--partitions: 定义分区数
--topic: 定义 topic 名称
#查看Topic 信息,三台都随便查某个节点
[root@node1 ~]# sh /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.40.163:2181
Topic: test PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: test Partition: 1 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: test Partition: 2 Leader: 1 Replicas: 1,3 Isr: 1,3
3.6 测试 Kafka-Topic
#发布消息
[root@node1 logs]# kafka-console-producer.sh --broker-list 192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092 --topic test
>1
>2
>3
>4
>5
>6
>7
#消费消息
[root@node1 logs]# kafka-console-consumer.sh --bootstrap-server 192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092 --topic test --from-beginning
5
6
exit
3
4
quit
1
2
7
qu
q
四、搭建 ES 集群和配置
4.1 三台主机安装 ES 修改配置文件并启动
#下载ES安装包
[root@node1 ~]# wget http://dl.elasticsearch.cn/elasticsearch/elasticsearch-7.9.2-x86_64.rpm
#安装
[root@node1 ~]# rpm -ivh elasticsearch-7.9.2-x86_64.rpm
#备份原始配置文件
[root@node1 ~]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml_bak
#修改 Node1 配置文件
[root@node1 elasticsearch]# vim /etc/elasticsearch/elasticsearch.yml
#集群名
cluster.name: my-application
#节点名
node.name: node1
#数据存放路径,生产建议改为挂载盘
path.data: /var/lib/elasticsearch
#日志存放路径
path.logs: /var/log/elasticsearch
#网络
network.host: 0.0.0.0
#监听端口
http.port: 9200
#集群节点设置,不需要写端口号默认9300 内部通信端口
discovery.seed_hosts: ["192.168.40.162", "192.168.40.163", "192.168.40.164"]
#集群Master节点数
cluster.initial_master_nodes: ["node1","node2","node3"]
#修改 Node2 配置文件
#集群名
cluster.name: my-application
#节点名
node.name: node2
#数据存放路径,生产建议改为挂载盘
path.data: /var/lib/elasticsearch
#日志存放路径
path.logs: /var/log/elasticsearch
#网络
network.host: 0.0.0.0
#监听端口
http.port: 9200
#集群节点设置,不需要写端口号默认9300 内部通信端口
discovery.seed_hosts: ["192.168.40.162", "192.168.40.163", "192.168.40.164"]
#集群Master节点数
cluster.initial_master_nodes: ["node1","node2","node3"]
#修改 Node3 配置文件
#集群名
cluster.name: my-application
#节点名
node.name: node3
#数据存放路径,生产建议改为挂载盘
path.data: /var/lib/elasticsearch
#日志存放路径
path.logs: /var/log/elasticsearch
#网络
network.host: 0.0.0.0
#服务端口
http.port: 9200
#集群节点设置,不需要写端口号默认9300 内部通信端口
discovery.seed_hosts: ["192.168.40.162", "192.168.40.163", "192.168.40.164"]
#集群Master节点数
cluster.initial_master_nodes: ["node1","node2","node3"]
#启动三台ES 并设置开机自启动,浏览器访问服务端口,检查集群是否监控
[root@node1 elasticsearch]# systemctl start elasticsearch && systemctl enable elasticsearch
● elasticsearch.service - Elasticsearch
Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2023-04-07 15:31:50 CST; 1min 24s ago
Docs: https://www.elastic.co
Main PID: 38495 (java)
CGroup: /system.slice/elasticsearch.service
├─38495 /usr/share/elasticsearch/jdk/bin/java -Xshare:auto -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 ...
└─38705 /usr/share/elasticsearch/modules/x-pack-ml/platform/linux-x86_64/bin/controller
Apr 07 15:31:28 node3 systemd[1]: Starting Elasticsearch...
Apr 07 15:31:50 node3 systemd[1]: Started Elasticsearch.
#status key 为green 则为健康
[root@node1 elasticsearch]# curl http://192.168.40.162:9200/_cluster/health?pretty
{
"cluster_name" : "my-application",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}

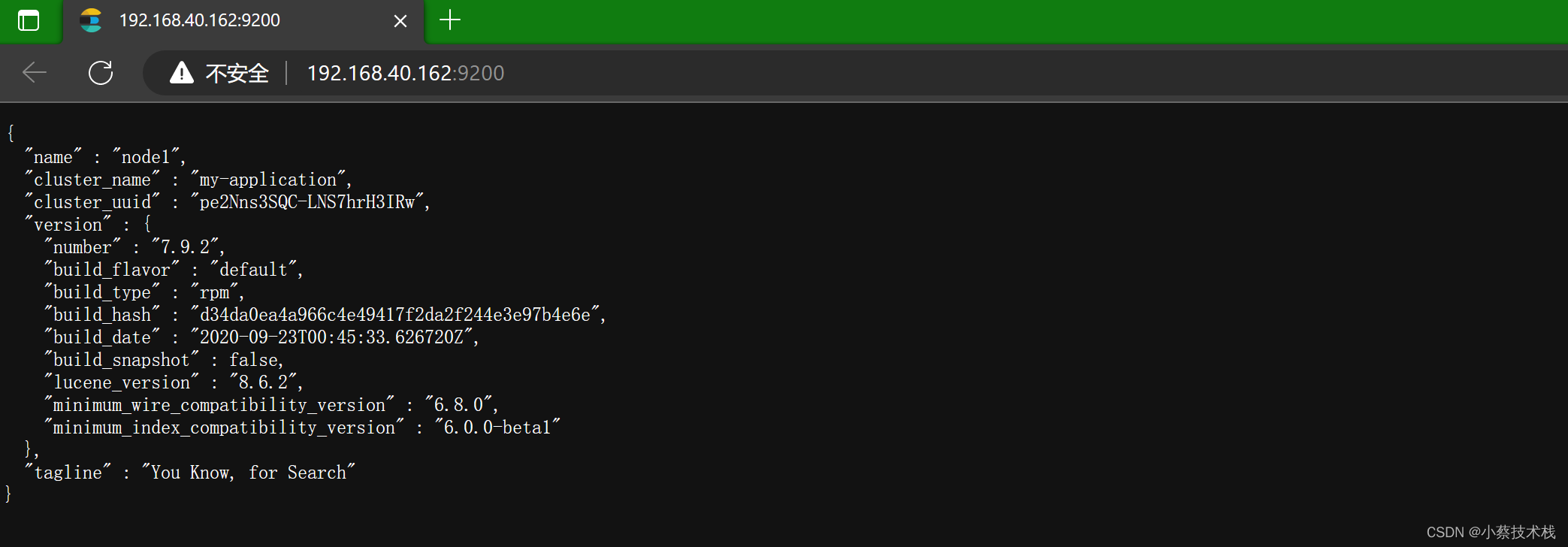
4.2 部署 Elasticsearch-head 数据可视化工具
# head插件是Nodejs实现的,所以需要先安装Nodejs
[root@node3 ~]# wget https://nodejs.org/dist/v12.18.4/node-v12.18.4-linux-x64.tar.xz
#注意这里是 -xf 参数
[root@node3 ~]# tar -xf node-v12.18.4-linux-x64.tar.xz
[root@node3 ~]# vim /etc/profile
# 添加 如下配置
export NODE_HOME=/root/node-v12.18.4-linux-x64
export PATH=$NODE_HOME/bin:$PATH
#从Git 上下载安装包
[root@node3 ~]# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
[root@node3 ~]# unzip master.zip
[root@node3 ~]# mv elasticsearch-head-master/ elasticsearch-head
[root@node3 ~]# cd elasticsearch-head
#此步安装的比较慢耐心等待
[root@node3 elasticsearch-head]# npm install
#后台启动插件
[root@node3 elasticsearch-head]# npm run start &
#修改三台的ES配置文件
--末尾添加以下内容--
http.cors.enabled: true #开启跨域访问支持,默认为false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有
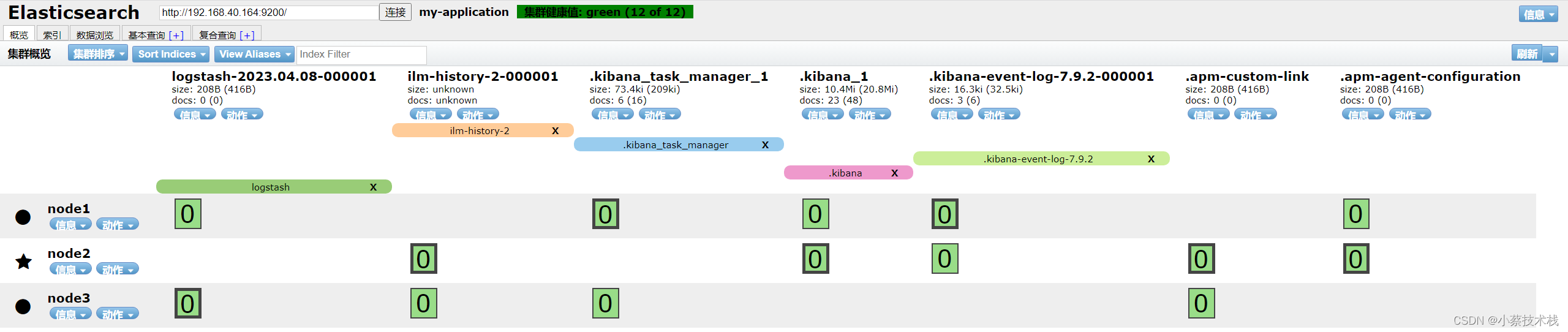
4.3 访问 Elasticsearch-head
http://192.168.40.164:9100/
五、部署 Logstash 消费 Kafka数据写入至ES
5.1 安装 Logstash
#我这里安装三台,你也可以安装在一台上进行测试
[root@node1 ~]# wget http://dl.elasticsearch.cn/logstash/logstash-7.9.2.rpm
[root@node1 ~]# rpm -ivh logstash-7.9.2.rpm
[root@node1 ~]# vim /etc/logstash/conf.d/logstash.conf
#下面一定要按照格式写,不然会不识别
input {
kafka {
codec => "plain"
topics => ["test"]
bootstrap_servers => "192.168.40.162:9092,192.168.40.163:9092,192.168.40.164:9092"
max_poll_interval_ms => "3000000"
session_timeout_ms => "6000"
heartbeat_interval_ms => "2000"
auto_offset_reset => "latest"
group_id => "logstash"
type => "logs"
}
}
output {
elasticsearch {
hosts => ["http://192.168.40.162:9200", "http://192.168.40.163:9200","http://192.168.40.164:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
#配置软连 方便用命令检查配置文件
[root@node1 ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
[root@node1 ~]# logstash -t
5.2 检查配置的时候报错提示如下 寻找这个文件失败,原因是因为我用rpm 装的,文件位置在/etc/logstash/ 下面,它去标红的路径下面去找了
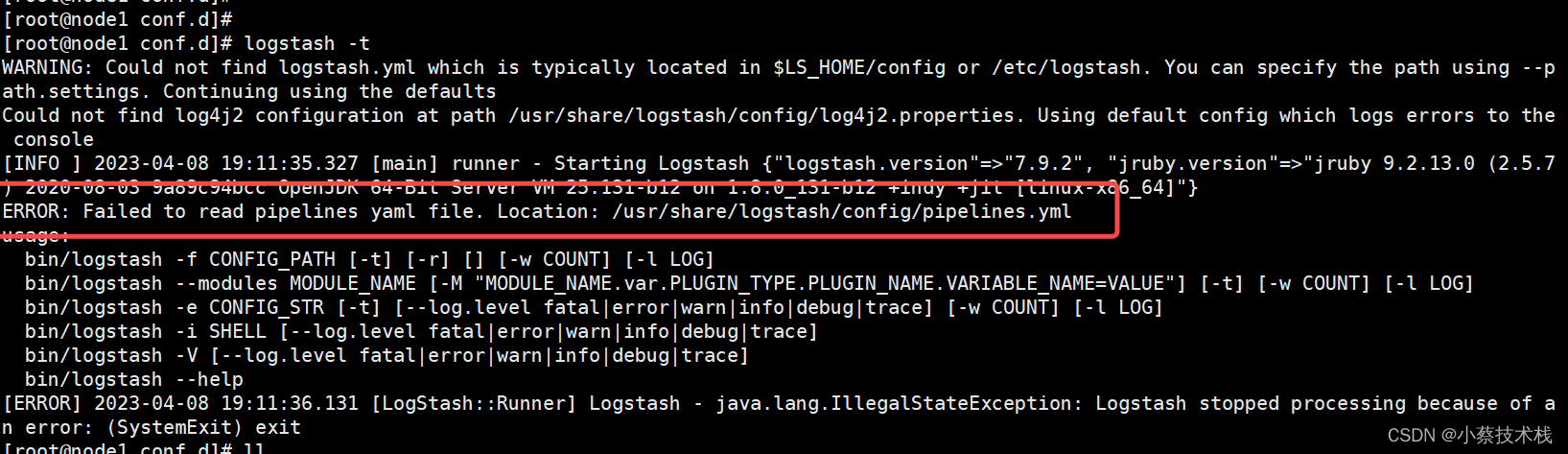
#/usr/share/logstash/ 目录下面少了一层config,我们这里来创建
[root@node1 ~]# mkdir -p /usr/share/logstash/config/
#把/etc/logstash/pipelines.yml cp到 /usr/share/logstash/config/下面
[root@node1 ~]# cp /etc/logstash/pipelines.yml /usr/share/logstash/config/
5.3 再次测试文件的时候 又报了一个错误,这个错误是因为 配置文件配置的有误导致的
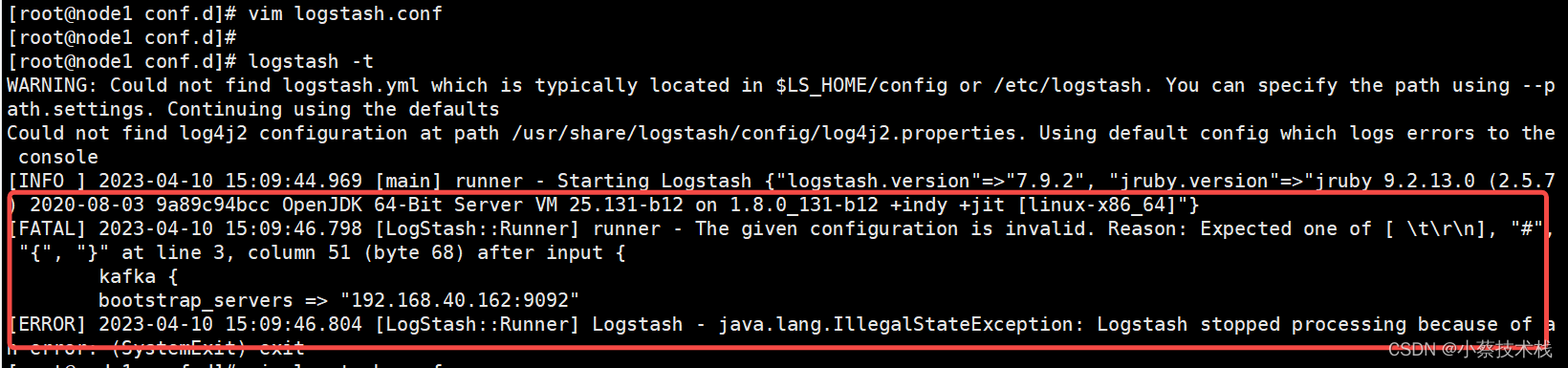
#启动 Logstash
[root@node1 ~]# systemctl start logstash && systemctl enable logstash
#查看日志是否消费了Kafka信息
[root@node1 ~]# tail -f /var/log/logstash/logstash-plain.log
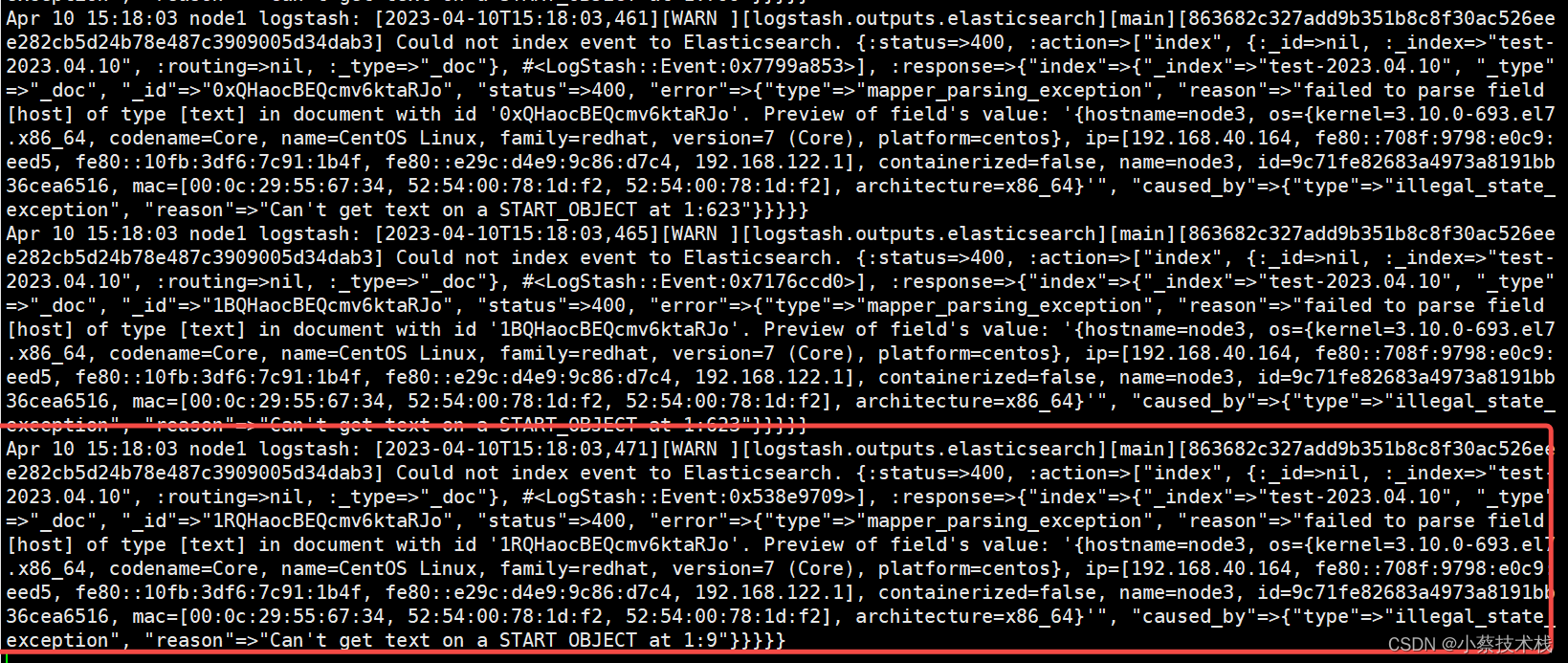
六、部署 Filebeat 收集日志
[root@node3 ~]# wget http://dl.elasticsearch.cn/filebeat/filebeat-7.9.2-x86_64.rpm
[root@node3 ~]# rpm -ivh filebeat-7.9.2-x86_64.rpm
#配置Filebeat 收集NG日志信息
[root@node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: false
paths:
#收集日志地址
- /usr/local/openresty/nginx/logs/*.log
output.kafka:
#配置Kafka地址
hosts: ["192.168.40.162:9092","192.168.40.163:9092","192.168.40.164:9092"]
#这个Topic 要和Kafka一致
topic: 'test'

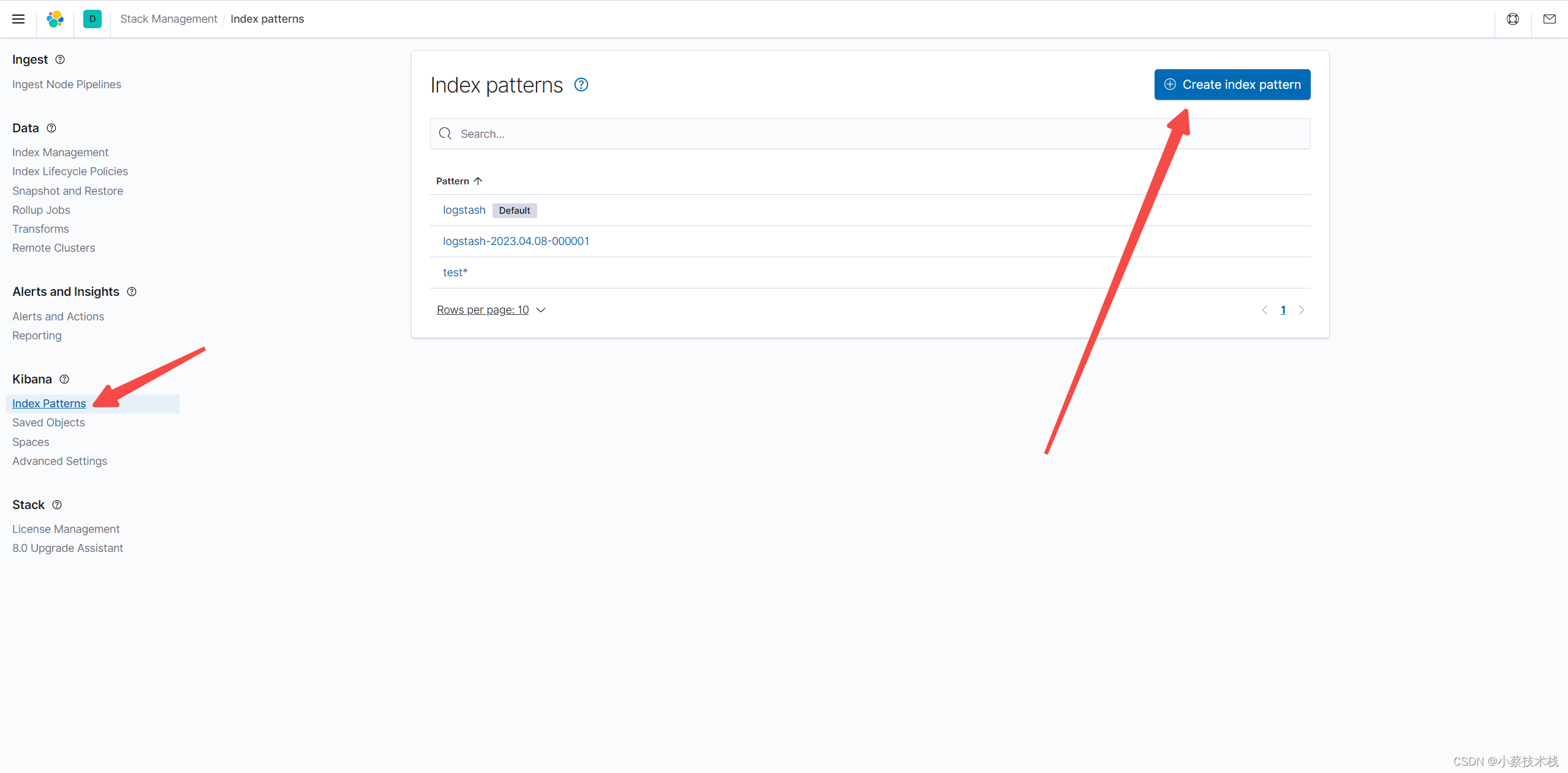
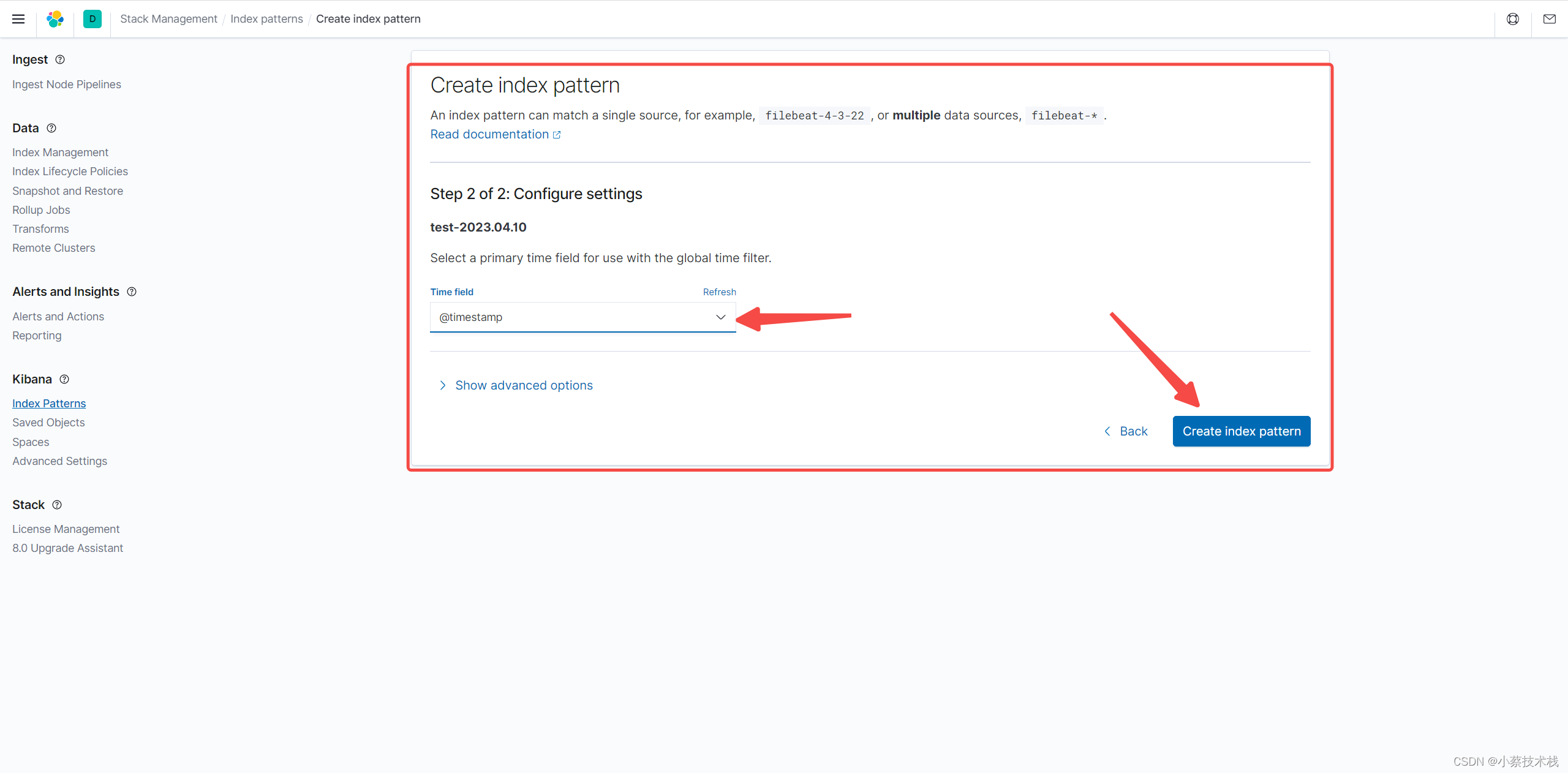
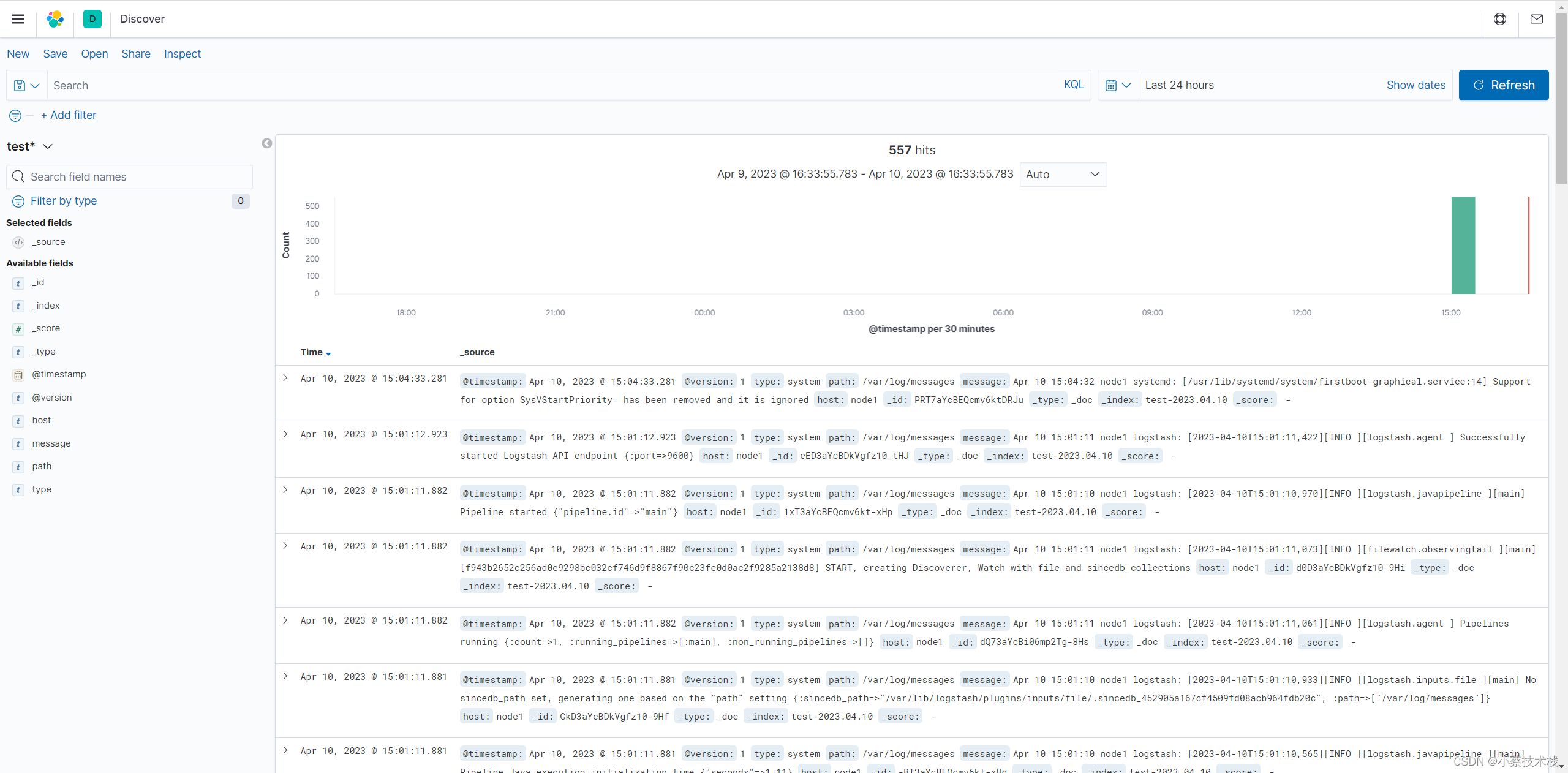
七、安装 Kibana 展示日志信息
7.1 安装并配置
#下载
[root@node2 ~]# wget http://dl.elasticsearch.cn/kibana/kibana-7.9.2-x86_64.rpm
[root@node2 ~]# rpm -ivh kibana-7.9.2-x86_64.rpm
[root@node2 ~]# vim /etc/kibana/kibana.yml
#WEB访问端口
server.port: 5601
server.host: "0.0.0.0"
#ES集群地址
elasticsearch.hosts: ["http://192.168.40.162:9200/","http://192.168.40.163:9200/","http://192.168.40.164:9200/"]
kibana.index: ".kibana"
7.2 配置索引