TensorFlow 深度学习第二版:6~10
原文:Deep Learning with TensorFlow Second Edition
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
六、RNN 和梯度消失或爆炸问题
较深层的梯度计算为多层网络中许多激活函数梯度的乘积。当这些梯度很小或为零时,它很容易消失。另一方面,当它们大于 1 时,它可能会爆炸。因此,计算和更新变得非常困难。
让我们更详细地解释一下:
- 如果权重较小,则可能导致称为消失梯度的情况,其中梯度信号变得非常小,以至于学习变得非常慢或完全停止工作。这通常被称为消失梯度。
- 如果该矩阵中的权重很大,则可能导致梯度信号太大而导致学习发散的情况。这通常被称为爆炸梯度。
因此,RNN 的一个主要问题是消失或爆炸梯度问题,它直接影响表现。事实上,反向传播时间推出了 RNN,创建了一个非常深的前馈神经网络。从 RNN 获得长期背景的不可能性正是由于这种现象:如果梯度在几层内消失或爆炸,网络将无法学习数据之间的高时间距离关系。
下图显示了发生的情况:计算和反向传播的梯度趋于在每个时刻减少(或增加),然后,在一定数量的时刻之后,成本函数趋于收敛到零(或爆炸到无穷大) )。
我们可以通过两种方式获得爆炸梯度。由于激活函数的目的是通过压缩它们来控制网络中的重大变化,因此我们设置的权重必须是非负的和大的。当这些权重沿着层次相乘时,它们会导致成本的大幅变化。当我们的神经网络模型学习时,最终目标是最小化成本函数并改变权重以达到最优成本。
例如,成本函数是均方误差。它是一个纯凸函数,目的是找到凸起的根本原因。如果你的权重增加到一定量,那么下降的时刻就会增加,我们会反复超过最佳状态,模型永远不会学习!
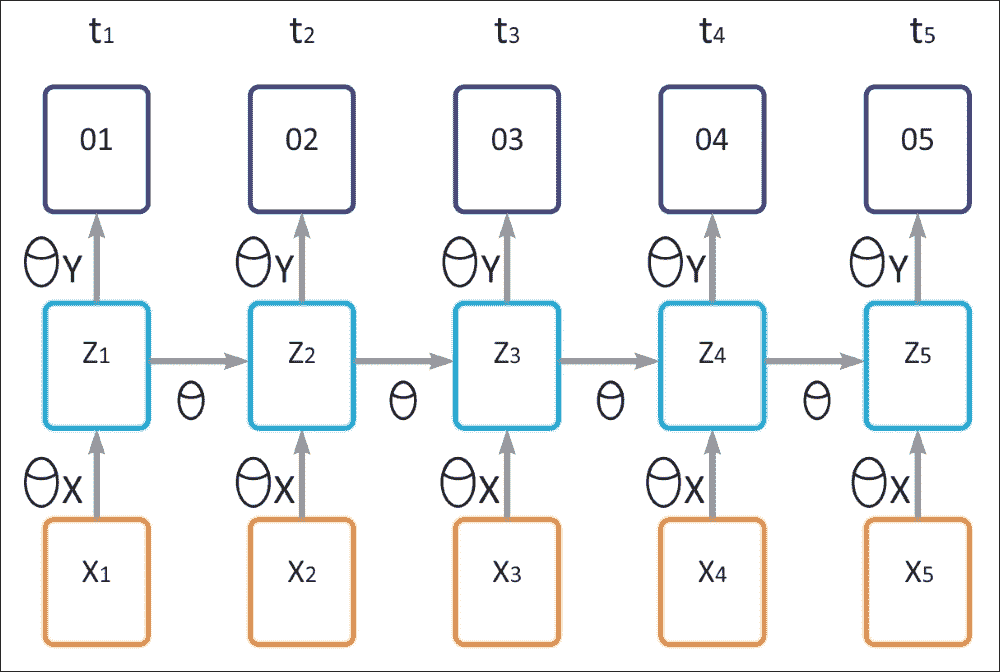
在上图中,我们有以下参数:
θ表示隐藏的循环层的参数θ[x]表示隐藏层的输入参数θ[y]表示输出层的参数σ表示隐藏层的激活函数- 输入表示为
X[t] - 隐藏层的输出为
h[t] - 最终输出为
o[t] t(时间步长)
注意,上图表示下面给出的循环神经网络模型的时间流逝。现在,如果你回忆一下图 1,输出可以表示如下:

现在让E代表输出层的损失:E = f(O[t])。然后,上述三个方程告诉我们E取决于输出O[t]。输出O[t]相对于层的隐藏状态(h[t])的变化而变化。当前时间步长(h[t])的隐藏状态取决于先前时间步长(h[t-1])的神经元状态。现在,下面的等式将清除这个概念。
相对于为隐藏层选择的参数的损失变化率= ∂E/∂θ,这是一个可以表述如下的链规则:
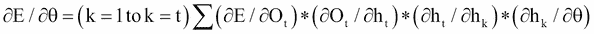
(I)
在前面的等式中,项∂h[t]/∂h[k]不仅有趣而且有用。
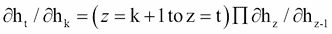
(II)
现在,让我们考虑t = 5和k = 1然后

(III)
微分方程(II)相对于(h[t-1])给出了:

(IV)
现在,如果我们将方程(III)和(IV)结合起来,我们可以得到以下结果:
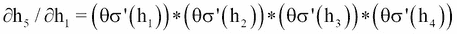
在这些情况下,θ也随着时间步长而变化。上面的等式显示了当前状态相对于先前状态的依赖性。现在让我们解释这两个方程的解剖。假设您处于时间步长 5(t = 5),那么k的范围从 1 到 5(k = 1到 5),这意味着您必须为以下内容计算k):
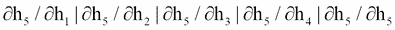
现在来看上面的每一个等式(II)
而且,它取决于循环层的参数θ。如果在训练期间你的权重变大,那么由于每个时间步长的等式(I)(II)的乘法,它们将会出现梯度爆炸的问题。
为了克服消失或爆炸问题,已经提出了基本 RNN 模型的各种扩展。将在下一节介绍的 LSTM 网络就是其中之一。
LSTM 网络
一种 RNN 模型是 LSTM。 LSTM 的精确实现细节不在本书的范围内。 LSTM 是一种特殊的 RNN 架构,最初由 Hochreiter 和 Schmidhuber 于 1997 年构思。
最近在深度学习的背景下重新发现了这种类型的神经网络,因为它没有消失梯度的问题,并且提供了出色的结果和表现。基于 LSTM 的网络是时间序列的预测和分类的理想选择,并且正在取代许多传统的深度学习方法。
这个名称意味着短期模式不会被遗忘。 LSTM 网络由彼此链接的单元(LSTM 块)组成。每个 LSTM 块包含三种类型的门:输入门,输出门和遗忘门,它们分别实现对单元存储器的写入,读取和复位功能。这些门不是二元的,而是模拟的(通常由映射在[0, 1]范围内的 Sigmoid 激活函数管理,其中 0 表示总抑制,1 表示总激活)。
如果你认为 LSTM 单元是一个黑盒子,它可以像基本单元一样使用,除了它会表现得更好;训练将更快地收敛,它将检测数据中的长期依赖性。在 TensorFlow 中,您只需使用BasicLSTMCell代替BasicRNNCell:
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=n_neurons)
LSTM 单元管理两个状态向量,并且出于表现原因,它们默认保持独立。您可以通过在创建BasicLSTMCell时设置state_is_tuple=False来更改此默认行为。那么,LSTM 单元如何工作?基本 LSTM 单元的架构如下图所示:

图 11:LSTM 单元的框图
现在,让我们看看这个架构背后的数学符号。如果我们不查看 LSTM 框内的内容,LSTM 单元本身看起来就像常规存储单元,除了它的状态被分成两个向量,h(t)和c(t):
h(t)是短期状态c(t)是长期状态
现在,让我们打开盒子吧!关键的想法是网络可以学习以下内容:
- 在长期的状态中存储什么
- 扔掉什么
- 怎么读它
由于长期c(t)从左到右穿过网络,你可以看到它首先通过一个遗忘门,丢弃一些内存,然后它添加一些新的存储器通过加法运算(增加了输入门选择的存储器)。结果c(t)直接发送,没有任何进一步的变换
因此,在每个时间步骤,都会丢弃一些内存并添加一些内存。此外,在加法运算之后,长期状态被复制并通过 tanh 函数,该函数产生[-1, +1]范围内的输出。
然后输出门过滤结果。这会产生短期h(t)(等于此时间步的单元输出y(t))。现在,让我们来看看新记忆的来源以及大门如何运作。首先,当前输入x(t)和之前的短路h(t-1)被馈送到四个不同的完全连接。这些门的存在允许 LSTM 单元无限期地记住信息:事实上,如果输入门低于激活阈值,单元格将保持先前的状态,如果启用当前状态,它将与输入值组合。顾名思义,遗忘门重置单元的当前状态(当其值被清除为 0 时),输出门决定是否必须执行单元的值。
以下等式用于对单个实例的单元的长期状态,其短期状态及其在每个时间步的输出进行 LSTM 计算:
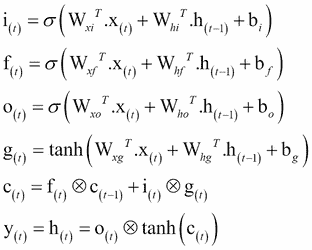
在前面的方程中,W[xi],W[xf],W[xo]和W[xg]是四个层中每个层的权重矩阵,用于与输入向量x(t)连接。另一方面,W[hi],W[hf],W[ho],和W[hg]是四层中每一层的权重矩阵,它们与先前的短期状态有关。b[i]、b[f]、b[o]、b[g]是四层中每一层的偏差项。 TensorFlow 初始化它们为一个全 1 的向量而不是全 0 的向量。这可以防止它在训练开始时遗忘一切。
GRU 单元
LSTM 单元还有许多其他变体。一种特别流行的变体是门控循环单元(GRU)。 Kyunghyun Cho 和其他人在 2014 年的论文中提出了 GRU 单元,该论文还介绍了我们前面提到的自编码器网络。
从技术上讲,GRU 单元是 LSTM 单元的简化版本,其中两个状态向量合并为一个称为h(t)的向量。单个门控制器控制遗忘门和输入门。如果门控制器的输出为 1,则输入门打开并且遗忘门关闭。
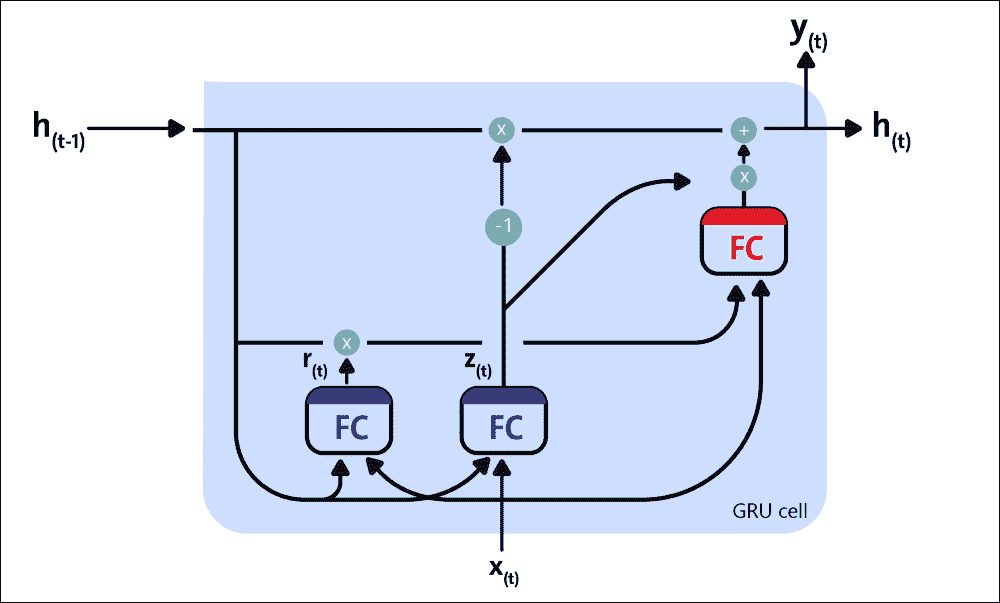
图 12:GRU 单元
另一方面,如果输出为 0,则相反。每当必须存储存储器时,首先擦除存储它的位置,这实际上是 LSTM 单元本身的常见变体。第二种简化是因为在每个时间步输出满状态向量,所以没有输出门。但是,新的门控制器控制先前状态的哪一部分将显示给主层。
以下等式用于为单个实例,在每个时间步计算 GRU 单元的长期状态,其短期状态及其输出的:
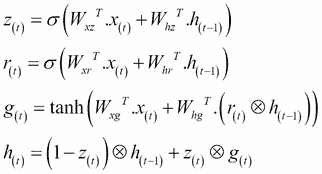
在 TensorFlow 中创建 GRU 单元非常简单。这是一个例子:
gru_cell = tf.nn.rnn_cell.GRUCell(num_units=n_neurons)
这些简化并不是这种架构的弱点;它似乎成功地执行。 LSTM 或 GRU 单元是近年来 RNN 成功背后的主要原因之一,特别是在 NLP 中的应用。
我们将在本章中看到使用 LSTM 的示例,但下一节将介绍使用 RNN 进行垃圾邮件/火腿文本分类的示例。
实现 RNN 进行垃圾邮件预测
在本节中,我们将看到如何在 TensorFlow 中实现 RNN 来预测文本中的垃圾邮件。
数据描述和预处理
将使用来自 UCI ML 仓库的流行垃圾数据集,可从此链接下载amcollection.zip。
该数据集包含来自多个电子邮件的文本,其中一些被标记为垃圾邮件。在这里,我们将训练一个模型,该模型将学习仅使用电子邮件文本区分垃圾邮件和非垃圾邮件。让我们开始导入所需的库和模型:
import os
import re
import io
import requests
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from zipfile import ZipFile
from tensorflow.python.framework import ops
import warnings
另外,如果您需要,我们可以停止打印由 TensorFlow 产生的警告:
warnings.filterwarnings("ignore")
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
ops.reset_default_graph()
现在,让我们为图创建 TensorFlow 会话:
sess = tf.Session()
下一个任务是设置 RNN 参数:
epochs = 300
batch_size = 250
max_sequence_length = 25
rnn_size = 10
embedding_size = 50
min_word_frequency = 10
learning_rate = 0.0001
dropout_keep_prob = tf.placeholder(tf.float32)
让我们手动下载数据集并将其存储在temp目录的text_data.txt文件中。首先,我们设置路径:
data_dir = 'temp'
data_file = 'text_data.txt'
if not os.path.exists(data_dir):
os.makedirs(data_dir)
现在,我们直接以压缩格式下载数据集:
if not os.path.isfile(os.path.join(data_dir, data_file)):
zip_url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip'
r = requests.get(zip_url)
z = ZipFile(io.BytesIO(r.content))
file = z.read('SMSSpamCollection')
我们仍然需要格式化数据:
text_data = file.decode()
text_data = text_data.encode('ascii',errors='ignore')
text_data = text_data.decode().split('\n')
现在,在文本文件中存储前面提到的目录:
with open(os.path.join(data_dir, data_file), 'w') as file_conn:
for text in text_data:
file_conn.write("{}\n".format(text))
else:
text_data = []
with open(os.path.join(data_dir, data_file), 'r') as file_conn:
for row in file_conn:
text_data.append(row)
text_data = text_data[:-1]
让我们分开单词长度至少为 2 的单词:
text_data = [x.split('\t') for x in text_data if len(x)>=1]
[text_data_target, text_data_train] = [list(x) for x in zip(*text_data)]
现在我们创建一个文本清理函数:
def clean_text(text_string):
text_string = re.sub(r'([^\s\w]|_|[0-9])+', '', text_string)
text_string = " ".join(text_string.split())
text_string = text_string.lower()
return(text_string)
我们调用前面的方法来清理文本:
text_data_train = [clean_text(x) for x in text_data_train]
现在我们需要做一个最重要的任务,即创建单词嵌入 - 将文本更改为数字向量:
vocab_processor = tf.contrib.learn.preprocessing.VocabularyProcessor(max_sequence_length, min_frequency=min_word_frequency)
text_processed = np.array(list(vocab_processor.fit_transform(text_data_train)))
现在让我们随意改变数据集的平衡:
text_processed = np.array(text_processed)
text_data_target = np.array([1 if x=='ham' else 0 for x in text_data_target])
shuffled_ix = np.random.permutation(np.arange(len(text_data_target)))
x_shuffled = text_processed[shuffled_ix]
y_shuffled = text_data_target[shuffled_ix]
现在我们已经改组了数据,我们可以将数据分成训练和测试集:
ix_cutoff = int(len(y_shuffled)*0.75)
x_train, x_test = x_shuffled[:ix_cutoff], x_shuffled[ix_cutoff:]
y_train, y_test = y_shuffled[:ix_cutoff], y_shuffled[ix_cutoff:]
vocab_size = len(vocab_processor.vocabulary_)
print("Vocabulary size: {:d}".format(vocab_size))
print("Training set size: {:d}".format(len(y_train)))
print("Test set size: {:d}".format(len(y_test)))
以下是上述代码的输出:
>>>
Vocabulary size: 933
Training set size: 4180
Test set size: 1394
在我们开始训练之前,让我们为 TensorFlow 图创建占位符:
x_data = tf.placeholder(tf.int32, [None, max_sequence_length])
y_output = tf.placeholder(tf.int32, [None])
让我们创建嵌入:
embedding_mat = tf.get_variable("embedding_mat", shape=[vocab_size, embedding_size], dtype=tf.float32, initializer=None, regularizer=None, trainable=True, collections=None)
embedding_output = tf.nn.embedding_lookup(embedding_mat, x_data)
现在是构建我们的 RNN 的时候了。以下代码定义了 RNN 单元:
cell = tf.nn.rnn_cell.BasicRNNCell(num_units = rnn_size)
output, state = tf.nn.dynamic_rnn(cell, embedding_output, dtype=tf.float32)
output = tf.nn.dropout(output, dropout_keep_prob)
现在让我们定义从 RNN 序列获取输出的方法:
output = tf.transpose(output, [1, 0, 2])
last = tf.gather(output, int(output.get_shape()[0]) - 1)
接下来,我们定义 RNN 的权重和偏置:
weight = bias = tf.get_variable("weight", shape=[rnn_size, 2], dtype=tf.float32, initializer=None, regularizer=None, trainable=True, collections=None)
bias = tf.get_variable("bias", shape=[2], dtype=tf.float32, initializer=None, regularizer=None, trainable=True, collections=None)
然后定义logits输出。它使用前面代码中的权重和偏置:
logits_out = tf.nn.softmax(tf.matmul(last, weight) + bias)
现在我们定义每个预测的损失,以便稍后,它们可以为损失函数做出贡献:
losses = tf.nn.sparse_softmax_cross_entropy_with_logits_v2(logits=logits_out, labels=y_output)
然后我们定义损失函数:
loss = tf.reduce_mean(losses)
我们现在定义每个预测的准确率:
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits_out, 1), tf.cast(y_output, tf.int64)), tf.float32))
然后我们用RMSPropOptimizer创建training_op:
optimizer = tf.train.RMSPropOptimizer(learning_rate)
train_step = optimizer.minimize(loss)
现在让我们使用global_variables_initializer()方法初始化所有变量 :
init_op = tf.global_variables_initializer()
sess.run(init_op)
此外,我们可以创建一些空列表来跟踪每个周期的训练损失,测试损失,训练准确率和测试准确率:
train_loss = []
test_loss = []
train_accuracy = []
test_accuracy = []
现在我们已准备好进行训练,让我们开始吧。训练的工作流程如下:
- 打乱训练数据
- 选择训练集并计算周期
- 为每个批次运行训练步骤
- 运行损失和训练的准确率
- 运行评估步骤。
以下代码包括上述所有步骤:
shuffled_ix = np.random.permutation(np.arange(len(x_train)))
x_train = x_train[shuffled_ix]
y_train = y_train[shuffled_ix]
num_batches = int(len(x_train)/batch_size) + 1
for i in range(num_batches):
min_ix = i * batch_size
max_ix = np.min([len(x_train), ((i+1) * batch_size)])
x_train_batch = x_train[min_ix:max_ix]
y_train_batch = y_train[min_ix:max_ix]
train_dict = {x_data: x_train_batch, y_output: \
y_train_batch, dropout_keep_prob:0.5}
sess.run(train_step, feed_dict=train_dict)
temp_train_loss, temp_train_acc = sess.run([loss,\
accuracy], feed_dict=train_dict)
train_loss.append(temp_train_loss)
train_accuracy.append(temp_train_acc)
test_dict = {x_data: x_test, y_output: y_test, \
dropout_keep_prob:1.0}
temp_test_loss, temp_test_acc = sess.run([loss, accuracy], \
feed_dict=test_dict)
test_loss.append(temp_test_loss)
test_accuracy.append(temp_test_acc)
print('Epoch: {}, Test Loss: {:.2}, Test Acc: {:.2}'.format(epoch+1, temp_test_loss, temp_test_acc))
print('\nOverall accuracy on test set (%): {}'.format(np.mean(temp_test_acc)*100.0))
以下是前面代码的输出:
>>>
Epoch: 1, Test Loss: 0.68, Test Acc: 0.82
Epoch: 2, Test Loss: 0.68, Test Acc: 0.82
Epoch: 3, Test Loss: 0.67, Test Acc: 0.82
…
Epoch: 997, Test Loss: 0.36, Test Acc: 0.96
Epoch: 998, Test Loss: 0.36, Test Acc: 0.96
Epoch: 999, Test Loss: 0.35, Test Acc: 0.96
Epoch: 1000, Test Loss: 0.35, Test Acc: 0.96
Overall accuracy on test set (%): 96.19799256324768
做得好! RNN 的准确率高于 96%,非常出色。现在让我们观察损失如何在每次迭代中传播并随着时间的推移:
epoch_seq = np.arange(1, epochs+1)
plt.plot(epoch_seq, train_loss, 'k--', label='Train Set')
plt.plot(epoch_seq, test_loss, 'r-', label='Test Set')
plt.title('RNN training/test loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='upper left')
plt.show()
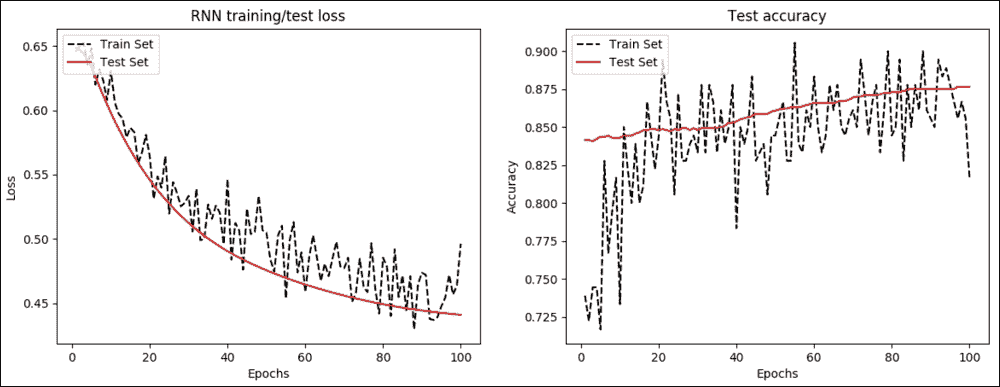
图 13:a)每个周期的 RNN 训练和测试损失 b)每个周期的测试精度
我们还随时间绘制准确率:
plt.plot(epoch_seq, train_accuracy, 'k--', label='Train Set')
plt.plot(epoch_seq, test_accuracy, 'r-', label='Test Set')
plt.title('Test accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='upper left')
plt.show()
下一个应用使用时间序列数据进行预测建模。我们还将看到如何开发更复杂的 RNN,称为 LSTM 网络。
开发时间序列数据的预测模型
RNN,特别是 LSTM 模型,通常是一个难以理解的主题。由于数据中的时间依赖性,时间序列预测是 RNN 的有用应用。时间序列数据可在线获取。在本节中,我们将看到使用 LSTM 处理时间序列数据的示例。我们的 LSTM 网络将能够预测未来的航空公司乘客数量。
数据集的描述
我将使用的数据集是 1949 年至 1960 年国际航空公司乘客的数据。该数据集可以从[此链接](https://datamarket.com/data/set/22u3/international-airlinepassengers- monthly-totals-in#!ds=22u3&display=line)。以下屏幕截图显示了国际航空公司乘客的元数据:

图 14:国际航空公司乘客的元数据(来源:https://datamarket.com/)
您可以通过选择“导出”选项卡,然后在“导出”组中选择 CSV 来下载数据。您必须手动编辑 CSV 文件以删除标题行以及其他页脚行。我已经下载并保存了名为international-airline-passengers.csv的数据文件。下图是时间序列数据的一个很好的图:
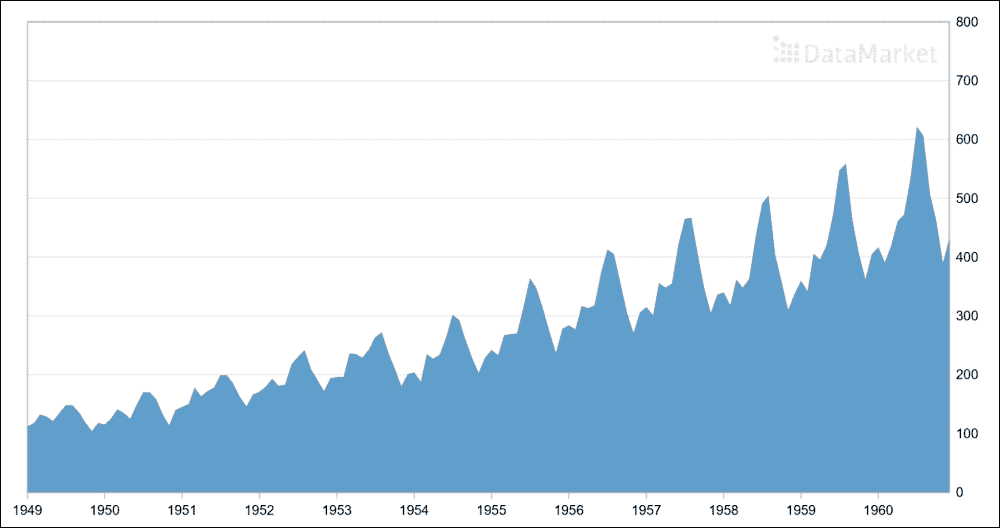
图 15:国际航空公司乘客:1 月 49 日至 12 月 60 日的月度总数为千人
预处理和探索性分析
现在让我们加载原始数据集并查看一些事实。首先,我们加载时间序列如下(见time_series_preprocessor.py):
import csv
import numpy as np
在这里,我们可以看到load_series()的签名,它是一个用户定义的方法,可以加载时间序列并对其进行正则化:
def load_series(filename, series_idx=1):
try:
with open(filename) as csvfile:
csvreader = csv.reader(csvfile)
data = [float(row[series_idx]) for row in csvreader if len(row) > 0]
normalized_data = (data - np.mean(data)) / np.std(data)
return normalized_data
except IOError:
Print("Error occurred")
return None
现在让我们调用前面的方法加载时间序列并打印(在终端上发出$ python3 plot_time_series.py)数据集中的序列号:
import csv
import numpy as np
import matplotlib.pyplot as plt
import time_series_preprocessor as tsp
timeseries = tsp.load_series('international-airline-passengers.csv')
print(timeseries)
以下是前面代码的输出:
>>>
[-1.40777884 -1.35759023 -1.24048348 -1.26557778 -1.33249593 -1.21538918
-1.10664719 -1.10664719 -1.20702441 -1.34922546 -1.47469699 -1.35759023
…..
2.85825285 2.72441656 1.9046693 1.5115252 0.91762667 1.26894693]
print(np.shape(timeseries))
>>>
144
这意味着时间序列中有144条目。让我们绘制时间序列:
plt.figure()
plt.plot(timeseries)
plt.title('Normalized time series')
plt.xlabel('ID')
plt.ylabel('Normalized value')
plt.legend(loc='upper left')
plt.show()
以下是上述代码的输出:
>>>
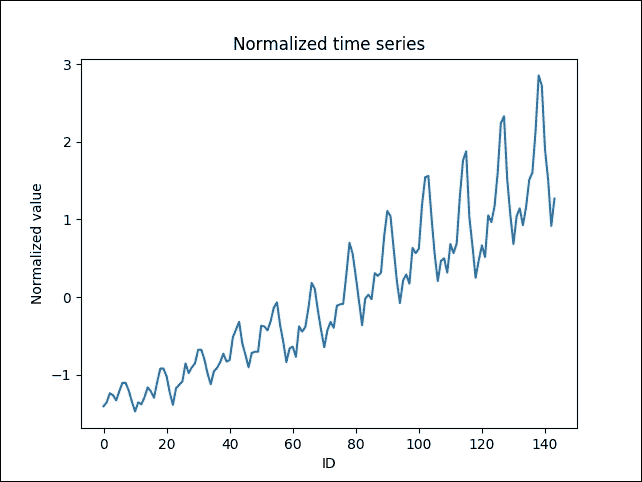
图 16:时间序列(y 轴,标准化值与 x 轴,ID)
加载时间序列数据集后,下一个任务是准备训练集。由于我们将多次评估模型以预测未来值,因此我们将数据分为训练和测试。更具体地说,split_data()函数将数据集划分为两个部分,用于训练和测试,75% 用于训练,25% 用于测试:
def split_data(data, percent_train):
num_rows = len(data)
train_data, test_data = [], []
for idx, row in enumerate(data):
if idx < num_rows * percent_train:
train_data.append(row)
else:
test_data.append(row)
return train_data, test_data
LSTM 预测模型
一旦我们准备好数据集,我们就可以通过以可接受的格式加载数据来训练预测器。在这一步中,我编写了一个名为TimeSeriesPredictor.py的 Python 脚本,它首先导入必要的库和模块(在此脚本的终端上发出$ python3 TimeSeriesPredictor.py命令):
import numpy as np
import tensorflow as tf
from tensorflow.python.ops import rnn, rnn_cell
import time_series_preprocessor as tsp
import matplotlib.pyplot as plt
接下来,我们为 LSTM 网络定义超参数(相应地调整它):
input_dim = 1
seq_size = 5
hidden_dim = 5
我们现在定义权重变量(无偏差)和输入占位符:
W_out = tf.get_variable("W_out", shape=[hidden_dim, 1], dtype=tf.float32, initializer=None, regularizer=None, trainable=True, collections=None)
b_out = tf.get_variable("b_out", shape=[1], dtype=tf.float32, initializer=None, regularizer=None, trainable=True, collections=None)
x = tf.placeholder(tf.float32, [None, seq_size, input_dim])
y = tf.placeholder(tf.float32, [None, seq_size])
下一个任务是构建 LSTM 网络。以下方法LSTM_Model()采用三个参数,如下所示:
x:大小为[T, batch_size, input_size]的输入W:完全连接的输出层权重矩阵b:完全连接的输出层偏置向量
现在让我们看一下方法的签名:
def LSTM_Model():
cell = rnn_cell.BasicLSTMCell(hidden_dim)
outputs, states = rnn.dynamic_rnn(cell, x, dtype=tf.float32)
num_examples = tf.shape(x)[0]
W_repeated = tf.tile(tf.expand_dims(W_out, 0), [num_examples, 1, 1])
out = tf.matmul(outputs, W_repeated) + b_out
out = tf.squeeze(out)
return out
此外,我们创建了三个空列表来存储训练损失,测试损失和步骤:
train_loss = []
test_loss = []
step_list = []
下一个名为train()的方法用于训练 LSTM 网络:
def trainNetwork(train_x, train_y, test_x, test_y):
with tf.Session() as sess:
tf.get_variable_scope().reuse_variables()
sess.run(tf.global_variables_initializer())
max_patience = 3
patience = max_patience
min_test_err = float('inf')
step = 0
while patience > 0:
_, train_err = sess.run([train_op, cost], feed_dict={x: train_x, y: train_y})
if step % 100 == 0:
test_err = sess.run(cost, feed_dict={x: test_x, y: test_y})
print('step: {}\t\ttrain err: {}\t\ttest err: {}'.format(step, train_err, test_err))
train_loss.append(train_err)
test_loss.append(test_err)
step_list.append(step)
if test_err < min_test_err:
min_test_err = test_err
patience = max_patience
else:
patience -= 1
step += 1
save_path = saver.save(sess, 'model.ckpt')
print('Model saved to {}'.format(save_path))
接下来的任务是创建成本优化器并实例化training_op:
cost = tf.reduce_mean(tf.square(LSTM_Model()- y))
train_op = tf.train.AdamOptimizer(learning_rate=0.003).minimize(cost)
另外,这里有一个叫做保存模型的辅助op:
saver = tf.train.Saver()
现在我们已经创建了模型,下一个方法称为testLSTM(),用于测试模型在测试集上的预测能力:
def testLSTM(sess, test_x):
tf.get_variable_scope().reuse_variables()
saver.restore(sess, 'model.ckpt')
output = sess.run(LSTM_Model(), feed_dict={x: test_x})
return output
为了绘制预测结果,我们有一个名为plot_results()的函数。签名如下:
def plot_results(train_x, predictions, actual, filename):
plt.figure()
num_train = len(train_x)
plt.plot(list(range(num_train)), train_x, color='b', label='training data')
plt.plot(list(range(num_train, num_train + len(predictions))), predictions, color='r', label='predicted')
plt.plot(list(range(num_train, num_train + len(actual))), actual, color='g', label='test data')
plt.legend()
if filename is not None:
plt.savefig(filename)
else:
plt.show()
模型评估
为了评估模型,我们有一个名为main()的方法,它实际上调用前面的方法来创建和训练 LSTM 网络。代码的工作流程如下:
- 加载数据
- 在时间序列数据中滑动窗口以构建训练数据集
- 执行相同的窗口滑动策略来构建测试数据集
- 在训练数据集上训练模型
- 可视化模型的表现
让我们看看方法的签名:
def main():
data = tsp.load_series('international-airline-passengers.csv')
train_data, actual_vals = tsp.split_data(data=data, percent_train=0.75)
train_x, train_y = [], []
for i in range(len(train_data) - seq_size - 1):
train_x.append(np.expand_dims(train_data[i:i+seq_size], axis=1).tolist())
train_y.append(train_data[i+1:i+seq_size+1])
test_x, test_y = [], []
for i in range(len(actual_vals) - seq_size - 1):
test_x.append(np.expand_dims(actual_vals[i:i+seq_size], axis=1).tolist())
test_y.append(actual_vals[i+1:i+seq_size+1])
trainNetwork(train_x, train_y, test_x, test_y)
with tf.Session() as sess:
predicted_vals = testLSTM(sess, test_x)[:,0]
# Following prediction results of the model given ground truth values
plot_results(train_data, predicted_vals, actual_vals, 'ground_truth_predition.png')
prev_seq = train_x[-1]
predicted_vals = []
for i in range(1000):
next_seq = testLSTM(sess, [prev_seq])
predicted_vals.append(next_seq[-1])
prev_seq = np.vstack((prev_seq[1:], next_seq[-1]))
# Following predictions results where only the training data was given
plot_results(train_data, predicted_vals, actual_vals, 'prediction_on_train_set.png')
>>>
最后,我们将调用main()方法来执行训练。训练完成后,它进一步绘制模型的预测结果,包括地面实况值与预测结果,其中只给出了训练数据:
>>>
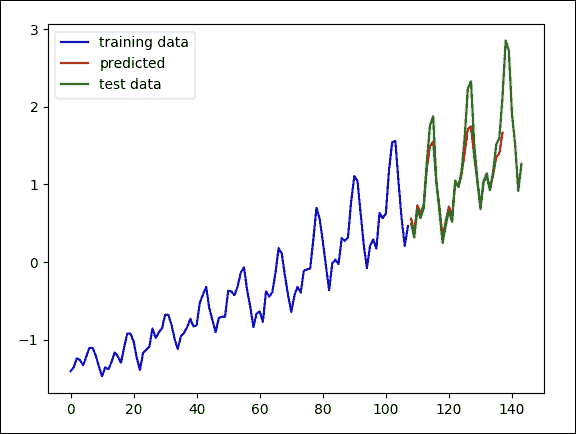
图 17:模型对地面实况值的结果
下图显示了训练数据的预测结果。此过程可用的信息较少,但它仍然可以很好地匹配数据中的趋势:
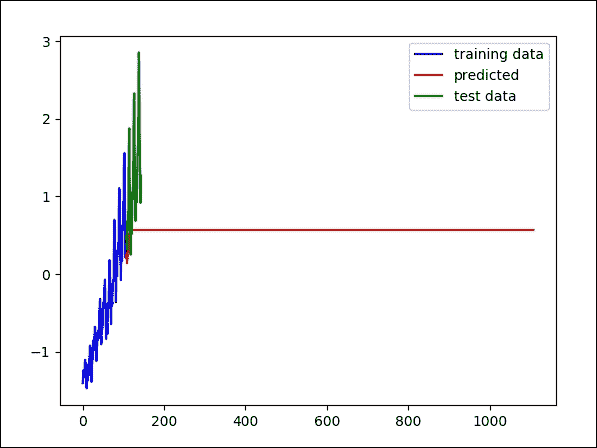
图 18:训练集上模型的结果
以下方法帮助我们绘制训练和测试误差:
def plot_error():
# Plot training loss over time
plt.plot(step_list, train_loss, 'r--', label='LSTM training loss per iteration', linewidth=4)
plt.title('LSTM training loss per iteration')
plt.xlabel('Iteration')
plt.ylabel('Training loss')
plt.legend(loc='upper right')
plt.show()
# Plot test loss over time
plt.plot(step_list, test_loss, 'r--', label='LSTM test loss per iteration', linewidth=4)
plt.title('LSTM test loss per iteration')
plt.xlabel('Iteration')
plt.ylabel('Test loss')
plt.legend(loc='upper left')
plt.show()
现在我们调用上面的方法如下:
plot_error()
>>>
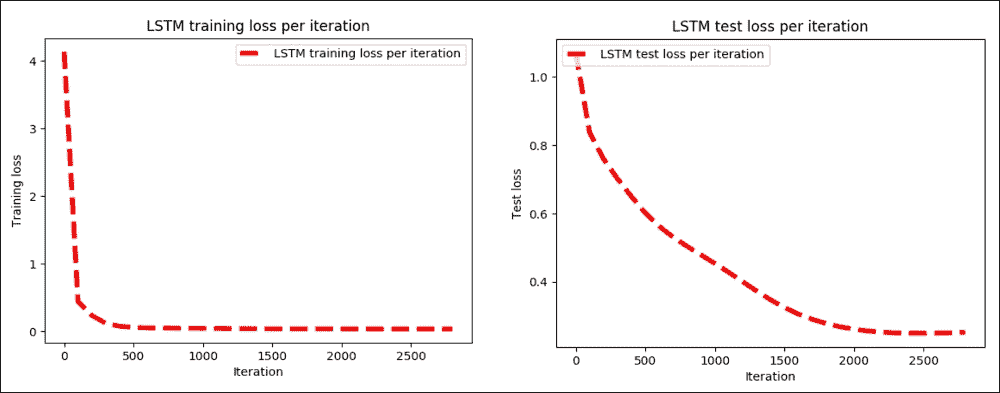
图 19:a)每次迭代的 LSTM 训练损失,b)每次迭代的 LSTM 测试损失
我们可以使用时间序列预测器来重现数据中的实际波动。现在,您可以准备自己的数据集并执行其他一些预测分析。下一个示例是关于产品和电影评论数据集的情感分析。我们还将了解如何使用 LSTM 网络开发更复杂的 RNN。
用于情感分析的 LSTM 预测模型
情感分析是 NLP 中使用最广泛的任务之一。 LSTM 网络可用于将短文本分类为期望的类别,即分类问题。例如,一组推文可以分为正面或负面。在本节中,我们将看到这样一个例子。
网络设计
实现的 LSTM 网络将具有三层:嵌入层,RNN 层和 softmax 层。从下图可以看到对此的高级视图。在这里,我总结了所有层的功能:
-
嵌入层:我们将在第 8 章中看到一个示例,显示文本数据集不能直接馈送到深度神经网络(DNN),因此一个名为嵌入层是必需的。对于该层,我们将每个输入(k 个单词的张量)变换为 k 个 N 维向量的张量。这称为字嵌入,其中 N 是嵌入大小。每个单词都与在训练过程中需要学习的权重向量相关联。您可以在单词的向量表示中更深入地了解单词嵌入。
-
RNN 层:一旦我们构建了嵌入层,就会有一个名为 RNN 层的新层,它由带有压降包装的 LSTM 单元组成。在训练过程中需要学习 LSTM 权重,如前几节所述。动态展开 RNN 层(如图 4 所示),将 k 个字嵌入作为输入并输出 k 个 M 维向量,其中 M 是 LSTM 单元的隐藏大小。
-
Softmax 或 Sigmoid 层:RNN 层的输出在
k个时间步长上平均,获得大小为M的单个张量。最后,例如,softmax 层用于计算分类概率。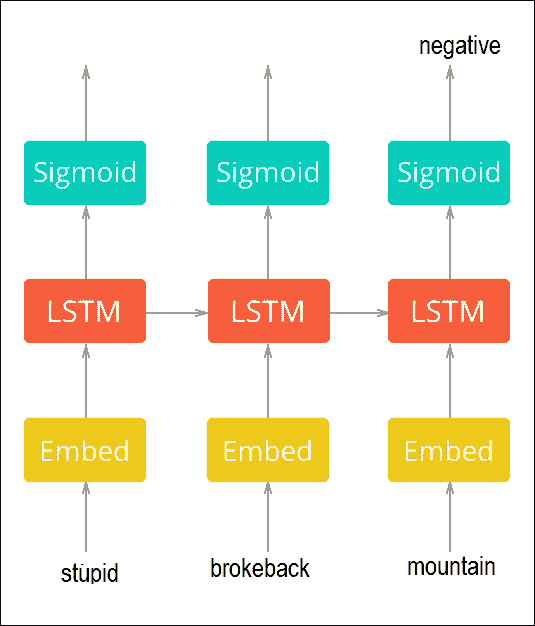
图 20:用于情感分析的 LSTM 网络的高级视图
稍后我们将看到交叉熵如何用作损失函数,RMSProp是最小化它的优化器。
LSTM 模型训练
UMICH SI650 - 情感分类数据集(删除了重复)包含有关密歇根大学捐赠的产品和电影评论的数据,可以从此链接下载。在获取令牌之前,已经清除了不需要的或特殊的字符(参见data.csv文件)。
以下脚本还会删除停用词(请参阅data_preparation.py)。给出一些标记为阴性或阳性的样本(1 为正面,0 为负面):
| 情感 | 情感文本 |
|---|---|
| 1 | 达芬奇密码书真棒。 |
| 1 | 我很喜欢达芬奇密码。 |
| 0 | 天哪,我讨厌断背山。 |
| 0 | 我讨厌哈利波特。 |
表 1:情感数据集的样本
现在,让我们看一下为此任务训练 LSTM 网络的分步示例。首先,我们导入必要的模块和包(执行train.py文件):
from data_preparation import Preprocessing
from lstm_network import LSTM_RNN_Network
import tensorflow as tf
import pickle
import datetime
import time
import os
import matplotlib.pyplot as plt
在前面的导入声明中,data_preparation和lstm_network是两个辅助 Python 脚本,用于数据集准备和网络设计。我们稍后会看到更多细节。现在让我们为 LSTM 定义参数:
data_dir = 'data/' # Data directory containing 'data.csv'
stopwords_file = 'data/stopwords.txt' # Path to stopwords file
n_samples= None # Set n_samples=None to use the whole dataset
# Directory where TensorFlow summaries will be stored'
summaries_dir= 'logs/'
batch_size = 100 #Batch size
train_steps = 1000 #Number of training steps
hidden_size= 75 # Hidden size of LSTM layer
embedding_size = 75 # Size of embeddings layer
learning_rate = 0.01
test_size = 0.2
dropout_keep_prob = 0.5 # Dropout keep-probability
sequence_len = None # Maximum sequence length
validate_every = 100 # Step frequency to validate
我相信前面的参数是不言自明的。下一个任务是准备 TensorBoard 使用的摘要:
summaries_dir = '{0}/{1}'.format(summaries_dir, datetime.datetime.now().strftime('%d_%b_%Y-%H_%M_%S'))
train_writer = tf.summary.FileWriter(summaries_dir + '/train')
validation_writer = tf.summary.FileWriter(summaries_dir + '/validation')
现在让我们准备模型目录:
model_name = str(int(time.time()))
model_dir = '{0}/{1}'.format(checkpoints_root, model_name)
if not os.path.exists(model_dir):
os.makedirs(model_dir)
接下来,让我们准备数据并构建 TensorFlow 图(参见data_preparation.py文件):
data_lstm = Preprocessing(data_dir=data_dir,
stopwords_file=stopwords_file,
sequence_len=sequence_len,
test_size=test_size,
val_samples=batch_size,
n_samples=n_samples,
random_state=100)
在前面的代码段中,Preprocessing是一个继续的类(详见data_preparation.py)几个函数和构造器,它们帮助我们预处理训练和测试集以训练 LSTM 网络。在这里,我提供了每个函数及其功能的代码。
该类的构造器初始化数据预处理器。此类提供了一个接口,用于将数据加载,预处理和拆分为训练,验证和测试集。它需要以下参数:
data_dir:包含数据集文件data.csv的数据目录,其中包含名为SentimentText和Sentiment的列。stopwords_file:可选。如果提供,它将丢弃原始数据中的每个停用词。sequence_len:可选。如果m是数据集中的最大序列长度,则需要sequence_len >= m。如果sequence_len为None,则会自动分配给m。n_samples:可选。它是从数据集加载的样本数(对大型数据集很有用)。如果n_samples是None,则将加载整个数据集(注意;如果数据集很大,则可能需要一段时间来预处理每个样本)。test_size:可选。0 < test_size < 1。它表示要包含在测试集中的数据集的比例(默认值为0.2)。val_samples:可选但可用于表示验证样本的绝对数量(默认为100)。random_state:这是随机种子的可选参数,用于将数据分成训练,测试和验证集(默认为0)。ensure_preprocessed:可选。如果ensure_preprocessed=True,它确保数据集已经过预处理(默认为False)。
构造器的代码如下:
def __init__(self, data_dir, stopwords_file=None, sequence_len=None, n_samples=None, test_size=0.2, val_samples=100, random_state=0, ensure_preprocessed=False):
self._stopwords_file = stopwords_file
self._n_samples = n_samples
self.sequence_len = sequence_len
self._input_file = os.path.join(data_dir, 'data.csv')
self._preprocessed_file=os.path.join(data_dir,"preprocessed_"+str(n_samples)+ ".npz")
self._vocab_file = os.path.join(data_dir,"vocab_" + str(n_samples) + ".pkl")
self._tensors = None
self._sentiments = None
self._lengths = None
self._vocab = None
self.vocab_size = None
# Prepare data
if os.path.exists(self._preprocessed_file)and os.path.exists(self._vocab_file):
print('Loading preprocessed files ...')
self.__load_preprocessed()
else:
if ensure_preprocessed:
raise ValueError('Unable to findpreprocessed files.')
print('Reading data ...')
self.__preprocess()
# Split data in train, validation and test sets
indices = np.arange(len(self._sentiments))
x_tv, self._x_test, y_tv, self._y_test,tv_indices, test_indices = train_test_split(
self._tensors,
self._sentiments,
indices,
test_size=test_size,
random_state=random_state,
stratify=self._sentiments[:, 0])
self._x_train,self._x_val,self._y_train,self._y_val,train_indices,val_indices= train_test_split(x_tv, y_tv, tv_indices, test_size=val_samples,random_state = random_state,
stratify=y_tv[:, 0])
self._val_indices = val_indices
self._test_indices = test_indices
self._train_lengths = self._lengths[train_indices]
self._val_lengths = self._lengths[val_indices]
self._test_lengths = self._lengths[test_indices]
self._current_index = 0
self._epoch_completed = 0
现在让我们看看前面方法的签名。我们从_preprocess()方法开始,该方法从data_dir / data.csv加载数据,预处理每个加载的样本,并存储中间文件以避免以后进行预处理。工作流程如下:
- 加载数据
- 清理示例文本
- 准备词汇词典
- 删除最不常见的单词(它们可能是语法错误),将样本编码为张量,并根据
sequence_len用零填充每个张量 - 保存中间文件
- 存储样本长度以备将来使用
现在让我们看看下面的代码块,它代表了前面的工作流程:
def __preprocess(self):
data = pd.read_csv(self._input_file, nrows=self._n_samples)
self._sentiments = np.squeeze(data.as_matrix(columns=['Sentiment']))
self._sentiments = np.eye(2)[self._sentiments]
samples = data.as_matrix(columns=['SentimentText'])[:, 0]
samples = self.__clean_samples(samples)
vocab = dict()
vocab[''] = (0, len(samples)) # add empty word
for sample in samples:
sample_words = sample.split()
for word in list(set(sample_words)): # distinct words
value = vocab.get(word)
if value is None:
vocab[word] = (-1, 1)
else:
encoding, count = value
vocab[word] = (-1, count + 1)
sample_lengths = []
tensors = []
word_count = 1
for sample in samples:
sample_words = sample.split()
encoded_sample = []
for word in list(set(sample_words)): # distinct words
value = vocab.get(word)
if value is not None:
encoding, count = value
if count / len(samples) > 0.0001:
if encoding == -1:
encoding = word_count
vocab[word] = (encoding, count)
word_count += 1
encoded_sample += [encoding]
else:
del vocab[word]
tensors += [encoded_sample]
sample_lengths += [len(encoded_sample)]
self.vocab_size = len(vocab)
self._vocab = vocab
self._lengths = np.array(sample_lengths)
self.sequence_len, self._tensors = self.__apply_to_zeros(tensors, self.sequence_len)
with open(self._vocab_file, 'wb') as f:
pickle.dump(self._vocab, f)
np.savez(self._preprocessed_file, tensors=self._tensors, lengths=self._lengths, sentiments=self._sentiments)
接下来,我们调用前面的方法并加载中间文件,避免数据预处理:
def __load_preprocessed(self):
with open(self._vocab_file, 'rb') as f:
self._vocab = pickle.load(f)
self.vocab_size = len(self._vocab)
load_dict = np.load(self._preprocessed_file)
self._lengths = load_dict['lengths']
self._tensors = load_dict['tensors']
self._sentiments = load_dict['sentiments']
self.sequence_len = len(self._tensors[0])
一旦我们预处理数据集,下一个任务就是清理样本。工作流程如下:
- 准备正则表达式模式。
- 清理每个样本。
- 恢复 HTML 字符。
- 删除
@users和 URL。 - 转换为小写。
- 删除标点符号。
- 用
C替换C+(连续出现两次以上的字符) - 删除停用词。
现在让我们以编程方式编写上述步骤。为此,我们有以下函数:
def __clean_samples(self, samples):
print('Cleaning samples ...')
ret = []
reg_punct = '[' + re.escape(''.join(string.punctuation)) + ']'
if self._stopwords_file is not None:
stopwords = self.__read_stopwords()
sw_pattern = re.compile(r'\b(' + '|'.join(stopwords) + r')\b')
for sample in samples:
text = html.unescape(sample)
words = text.split()
words = [word for word in words if not word.startswith('@') and not word.startswith('http://')]
text = ' '.join(words)
text = text.lower()
text = re.sub(reg_punct, ' ', text)
text = re.sub(r'([a-z])\1{2,}', r'\1', text)
if stopwords is not None:
text = sw_pattern.sub('', text)
ret += [text]
return ret
__apply_to_zeros()方法返回使用的padding_length和填充张量的 NumPy 数组。首先,它找到最大长度m,并确保m>=sequence_len。然后根据sequence_len用零填充列表:
def __apply_to_zeros(self, lst, sequence_len=None):
inner_max_len = max(map(len, lst))
if sequence_len is not None:
if inner_max_len > sequence_len:
raise Exception('Error: Provided sequence length is not sufficient')
else:
inner_max_len = sequence_len
result = np.zeros([len(lst), inner_max_len], np.int32)
for i, row in enumerate(lst):
for j, val in enumerate(row):
result[i][j] = val
return inner_max_len, result
下一个任务是删除所有停用词(在data / StopWords.txt file中提供)。此方法返回停用词列表:
def __read_stopwords(self):
if self._stopwords_file is None:
return None
with open(self._stopwords_file, mode='r') as f:
stopwords = f.read().splitlines()
return stopwords
next_batch()方法将batch_size>0作为包含的样本数,在完成周期后返回批量大小样本(text_tensor,text_target,text_length),并随机抽取训练样本:
def next_batch(self, batch_size):
start = self._current_index
self._current_index += batch_size
if self._current_index > len(self._y_train):
self._epoch_completed += 1
ind = np.arange(len(self._y_train))
np.random.shuffle(ind)
self._x_train = self._x_train[ind]
self._y_train = self._y_train[ind]
self._train_lengths = self._train_lengths[ind]
start = 0
self._current_index = batch_size
end = self._current_index
return self._x_train[start:end], self._y_train[start:end], self._train_lengths[start:end]
然后使用称为get_val_data()的下一个方法来获取在训练期间使用的验证集。它接受原始文本并返回验证数据。默认情况下,它返回original_text(original_samples,text_tensor,text_target,text_length),否则返回text_tensor,text_target,text_length:
def get_val_data(self, original_text=False):
if original_text:
data = pd.read_csv(self._input_file, nrows=self._n_samples)
samples = data.as_matrix(columns=['SentimentText'])[:, 0]
return samples[self._val_indices], self._x_val, self._y_val, self._val_lengths
return self._x_val, self._y_val, self._val_lengths
最后, 是一个名为get_test_data()的附加方法,用于准备将在模型评估期间使用的测试集:
def get_test_data(self, original_text=False):
if original_text:
data = pd.read_csv(self._input_file, nrows=self._n_samples)
samples = data.as_matrix(columns=['SentimentText'])[:, 0]
return samples[self._test_indices], self._x_test, self._y_test, self._test_lengths
return self._x_test, self._y_test, self._test_lengths
现在我们准备数据,以便 LSTM 网络可以提供它:
lstm_model = LSTM_RNN_Network(hidden_size=[hidden_size],
vocab_size=data_lstm.vocab_size,
embedding_size=embedding_size,
max_length=data_lstm.sequence_len,
learning_rate=learning_rate)
在前面的代码段中,LSTM_RNN_Network是一个包含多个函数和构造器的类,可帮助我们创建 LSTM 网络。即将推出的构造器构建了 TensorFlow LSTM 模型。它需要以下参数:
hidden_size:一个数组,保存 rnn 层的 LSTM 单元中的单元数vocab_size:样本中的词汇量大小embedding_size:将使用此大小的向量对单词进行编码max_length:输入张量的最大长度n_classes:类别的数量learning_rate:RMSProp 算法的学习率random_state:丢弃的随机状态
构造器的代码如下:
def __init__(self, hidden_size, vocab_size, embedding_size, max_length, n_classes=2, learning_rate=0.01, random_state=None):
# Build TensorFlow graph
self.input = self.__input(max_length)
self.seq_len = self.__seq_len()
self.target = self.__target(n_classes)
self.dropout_keep_prob = self.__dropout_keep_prob()
self.word_embeddings = self.__word_embeddings(self.input, vocab_size, embedding_size, random_state)
self.scores = self.__scores(self.word_embeddings, self.seq_len, hidden_size, n_classes, self.dropout_keep_prob,
random_state)
self.predict = self.__predict(self.scores)
self.losses = self.__losses(self.scores, self.target)
self.loss = self.__loss(self.losses)
self.train_step = self.__train_step(learning_rate, self.loss)
self.accuracy = self.__accuracy(self.predict, self.target)
self.merged = tf.summary.merge_all()
下一个函数被称为_input(),它采用一个名为max_length的参数,它是输入张量的最大长度。然后它返回一个输入占位符,其形状为[batch_size, max_length],用于 TensorFlow 计算:
def __input(self, max_length):
return tf.placeholder(tf.int32, [None, max_length], name='input')
接下来,_seq_len()函数返回一个形状为[batch_size]的序列长度占位符。它保持给定批次中每个张量的实际长度,允许动态序列长度:
def __seq_len(self):
return tf.placeholder(tf.int32, [None], name='lengths')
下一个函数称为_target()。它需要一个名为n_classes的参数,它包含分类类的数量。最后,它返回形状为[batch_size, n_classes]的目标占位符:
def __target(self, n_classes):
return tf.placeholder(tf.float32, [None, n_classes], name='target')
_dropout_keep_prob()返回一个持有丢弃的占位符保持概率以减少过拟合:
def __dropout_keep_prob(self):
return tf.placeholder(tf.float32, name='dropout_keep_prob')
_cell()方法用于构建带有压差包装器的 LSTM 单元。它需要以下参数:
hidden_size:它是 LSTM 单元中的单元数dropout_keep_prob:这表示持有丢弃保持概率的张量seed:它是一个可选值,可确保丢弃包装器的随机状态计算的可重现性。
最后,它返回一个带有丢弃包装器的 LSTM 单元:
def __cell(self, hidden_size, dropout_keep_prob, seed=None):
lstm_cell = tf.nn.rnn_cell.LSTMCell(hidden_size, state_is_tuple=True)
dropout_cell = tf.nn.rnn_cell.DropoutWrapper(lstm_cell, input_keep_prob=dropout_keep_prob, output_keep_prob = dropout_keep_prob, seed=seed)
return dropout_cell
一旦我们创建了 LSTM 单元格,我们就可以创建输入标记的嵌入。为此,__word_embeddings()可以解决这个问题。它构建一个形状为[vocab_size, embedding_size]的嵌入层,输入参数如x,它是形状[batch_size, max_length]的输入。vocab_size是词汇量大小,即可能出现在样本中的可能单词的数量。embedding_size是将使用此大小的向量表示的单词,种子是可选的,但确保嵌入初始化的随机状态。
最后,它返回具有形状[batch_size, max_length, embedding_size]的嵌入查找张量:
def __word_embeddings(self, x, vocab_size, embedding_size, seed=None):
with tf.name_scope('word_embeddings'):
embeddings = tf.get_variable("embeddings",shape=[vocab_size, embedding_size], dtype=tf.float32, initializer=None, regularizer=None, trainable=True, collections=None)
embedded_words = tf.nn.embedding_lookup(embeddings, x)
return embedded_words
__rnn_layer ()方法创建 LSTM 层。它需要几个输入参数,这里描述:
hidden_size:这是 LSTM 单元中的单元数x:这是带形状的输入seq_len:这是具有形状的序列长度张量dropout_keep_prob:这是持有丢弃保持概率的张量variable_scope:这是变量范围的名称(默认层是rnn_layer)random_state:这是丢弃包装器的随机状态
最后,它返回形状为[batch_size, max_seq_len, hidden_size]的输出:
def __rnn_layer(self, hidden_size, x, seq_len, dropout_keep_prob, variable_scope=None, random_state=None):
with tf.variable_scope(variable_scope, default_name='rnn_layer'):
lstm_cell = self.__cell(hidden_size, dropout_keep_prob, random_state)
outputs, _ = tf.nn.dynamic_rnn(lstm_cell, x, dtype=tf.float32, sequence_length=seq_len)
return outputs
_score()方法用于计算网络输出。它需要几个输入参数,如下所示:
embedded_words:这是具有形状[batch_size, max_length, embedding_size]的嵌入查找张量seq_len:这是形状[batch_size]的序列长度张量hidden_size:这是一个数组,其中包含每个 RNN 层中 LSTM 单元中的单元数n_classes:这是类别的数量dropout_keep_prob:这是持有丢弃保持概率的张量random_state:这是一个可选参数,但它可用于确保丢弃包装器的随机状态
最后,_score()方法返回具有形状[batch_size, n_classes]的每个类的线性激活:
def __scores(self, embedded_words, seq_len, hidden_size, n_classes, dropout_keep_prob, random_state=None):
outputs = embedded_words
for h in hidden_size:
outputs = self.__rnn_layer(h, outputs, seq_len, dropout_keep_prob)
outputs = tf.reduce_mean(outputs, axis=[1])
with tf.name_scope('final_layer/weights'):
w = tf.get_variable("w", shape=[hidden_size[-1], n_classes], dtype=tf.float32, initializer=None, regularizer=None, trainable=True, collections=None)
self.variable_summaries(w, 'final_layer/weights')
with tf.name_scope('final_layer/biases'):
b = tf.get_variable("b", shape=[n_classes], dtype=tf.float32, initializer=None, regularizer=None,trainable=True, collections=None)
self.variable_summaries(b, 'final_layer/biases')
with tf.name_scope('final_layer/wx_plus_b'):
scores = tf.nn.xw_plus_b(outputs, w, b, name='scores')
tf.summary.histogram('final_layer/wx_plus_b', scores)
return scores
_predict()方法将得分作为具有形状[batch_size, n_classes]的每个类的线性激活,并以形状[batch_size, n_classes]返回 softmax(以[0, 1]的比例标准化得分)激活:
def __predict(self, scores):
with tf.name_scope('final_layer/softmax'):
softmax = tf.nn.softmax(scores, name='predictions')
tf.summary.histogram('final_layer/softmax', softmax)
return softmax
_losses()方法返回具有形状[batch_size]的交叉熵损失(因为 softmax 用作激活函数)。它还需要两个参数,例如得分,作为具有形状[batch_size, n_classes]的每个类的线性激活和具有形状[batch_size, n_classes]的目标张量:
def __losses(self, scores, target):
with tf.name_scope('cross_entropy'):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=scores, labels=target, name='cross_entropy')
return cross_entropy
_loss()函数计算并返回平均交叉熵损失。它只需要一个参数,称为损耗,它表示形状[batch_size]的交叉熵损失,并由前一个函数计算:
def __loss(self, losses):
with tf.name_scope('loss'):
loss = tf.reduce_mean(losses, name='loss')
tf.summary.scalar('loss', loss)
return loss
现在,_train_step()计算并返回RMSProp训练步骤操作。它需要两个参数,learning_rate,这是RMSProp优化器的学习率;和前一个函数计算的平均交叉熵损失:
def __train_step(self, learning_rate, loss):
return tf.train.RMSPropOptimizer(learning_rate).minimize(loss)
评估表现时,_accuracy()函数计算分类的准确率。它需要三个参数,预测,softmax 激活具有哪种形状[batch_size, n_classes];和具有形状[batch_size, n_classes]的目标张量和当前批次中获得的平均精度:
def __accuracy(self, predict, target):
with tf.name_scope('accuracy'):
correct_pred = tf.equal(tf.argmax(predict, 1), tf.argmax(target, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32), name='accuracy')
tf.summary.scalar('accuracy', accuracy)
return accuracy
下一个函数被称为initialize_all_variable(),正如您可能猜到的那样,它初始化所有变量:
def initialize_all_variables(self):
return tf.global_variables_initializer()
最后,我们有一个名为variable_summaries()的静态方法,它将大量摘要附加到 TensorBoard 可视化的张量上。它需要以下参数:
var: is the variable to summarize
mean: mean of the summary name.
签名如下:
@staticmethod
def variable_summaries(var, name):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean/' + name, mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev/' + name, stddev)
tf.summary.scalar('max/' + name, tf.reduce_max(var))
tf.summary.scalar('min/' + name, tf.reduce_min(var))
tf.summary.histogram(name, var)
现在我们需要在训练模型之前创建一个 TensorFlow 会话:
sess = tf.Session()
让我们初始化所有变量:
init_op = tf.global_variables_initializer()
sess.run(init_op)
然后我们保存 TensorFlow 模型以备将来使用:
saver = tf.train.Saver()
现在让我们准备训练集:
x_val, y_val, val_seq_len = data_lstm.get_val_data()
现在我们应该编写 TensorFlow 图计算的日志:
train_writer.add_graph(lstm_model.input.graph)
此外,我们可以创建一些空列表来保存训练损失,验证损失和步骤,以便我们以图形方式查看它们:
train_loss_list = []
val_loss_list = []
step_list = []
sub_step_list = []
step = 0
现在我们开始训练。在每个步骤中,我们记录训练误差。验证误差记录在每个子步骤中:
for i in range(train_steps):
x_train, y_train, train_seq_len = data_lstm.next_batch(batch_size)
train_loss, _, summary = sess.run([lstm_model.loss, lstm_model.train_step, lstm_model.merged],
feed_dict={lstm_model.input: x_train,
lstm_model.target: y_train,
lstm_model.seq_len: train_seq_len,
lstm_model.dropout_keep_prob:dropout_keep_prob})
train_writer.add_summary(summary, i) # Write train summary for step i (TensorBoard visualization)
train_loss_list.append(train_loss)
step_list.append(i)
print('{0}/{1} train loss: {2:.4f}'.format(i + 1, FLAGS.train_steps, train_loss))
if (i + 1) %validate_every == 0:
val_loss, accuracy, summary = sess.run([lstm_model.loss, lstm_model.accuracy, lstm_model.merged],
feed_dict={lstm_model.input: x_val,
lstm_model.target: y_val,
lstm_model.seq_len: val_seq_len,
lstm_model.dropout_keep_prob: 1})
validation_writer.add_summary(summary, i)
print(' validation loss: {0:.4f} (accuracy {1:.4f})'.format(val_loss, accuracy))
step = step + 1
val_loss_list.append(val_loss)
sub_step_list.append(step)
以下是上述代码的输出:
>>>
1/1000 train loss: 0.6883
2/1000 train loss: 0.6879
3/1000 train loss: 0.6943
99/1000 train loss: 0.4870
100/1000 train loss: 0.5307
validation loss: 0.4018 (accuracy 0.9200)
…
199/1000 train loss: 0.1103
200/1000 train loss: 0.1032
validation loss: 0.0607 (accuracy 0.9800)
…
299/1000 train loss: 0.0292
300/1000 train loss: 0.0266
validation loss: 0.0417 (accuracy 0.9800)
…
998/1000 train loss: 0.0021
999/1000 train loss: 0.0007
1000/1000 train loss: 0.0004
validation loss: 0.0939 (accuracy 0.9700)
上述代码打印了训练和验证误差。训练结束后,模型将保存到具有唯一 ID 的检查点目录中:
checkpoint_file = '{}/model.ckpt'.format(model_dir)
save_path = saver.save(sess, checkpoint_file)
print('Model saved in: {0}'.format(model_dir))
以下是上述代码的输出:
>>>
Model saved in checkpoints/1517781236
检查点目录将至少生成三个文件:
config.pkl包含用于训练模型的参数。model.ckpt包含模型的权重。model.ckpt.meta包含 TensorFlow 图定义。
让我们看看训练是如何进行的,也就是说,训练和验证损失如下:
# Plot loss over time
plt.plot(step_list, train_loss_list, 'r--', label='LSTM training loss per iteration', linewidth=4)
plt.title('LSTM training loss per iteration')
plt.xlabel('Iteration')
plt.ylabel('Training loss')
plt.legend(loc='upper right')
plt.show()
# Plot accuracy over time
plt.plot(sub_step_list, val_loss_list, 'r--', label='LSTM validation loss per validating interval', linewidth=4)
plt.title('LSTM validation loss per validation interval')
plt.xlabel('Validation interval')
plt.ylabel('Validation loss')
plt.legend(loc='upper left')
plt.show()
以下是上述代码的输出:
>>>
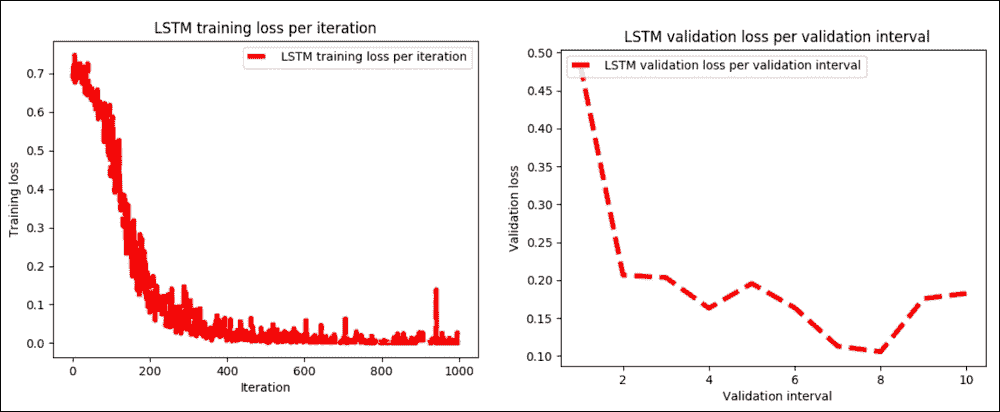
图 21:a)测试集上每次迭代的 LSTM 训练损失,b)每个验证间隔的 LSTM 验证损失
如果我们检查前面的绘图,很明显训练阶段和验证阶段的训练都很顺利,只有 1000 步。然而,读者应加大训练步骤,调整超参数,看看它是如何去。
通过 TensorBoard 的可视化
现在让我们观察 TensorBoard 上的 TensorFlow 计算图。只需执行以下命令并在localhost:6006/访问 TensorBoard:
tensorboard --logdir /home/logs/
图选项卡显示执行图,包括使用的梯度,loss_op,精度,最终层,使用的优化器(在我们的例子中是RMSPro),LSTM 层(即 RNN 层),嵌入层和save_op:
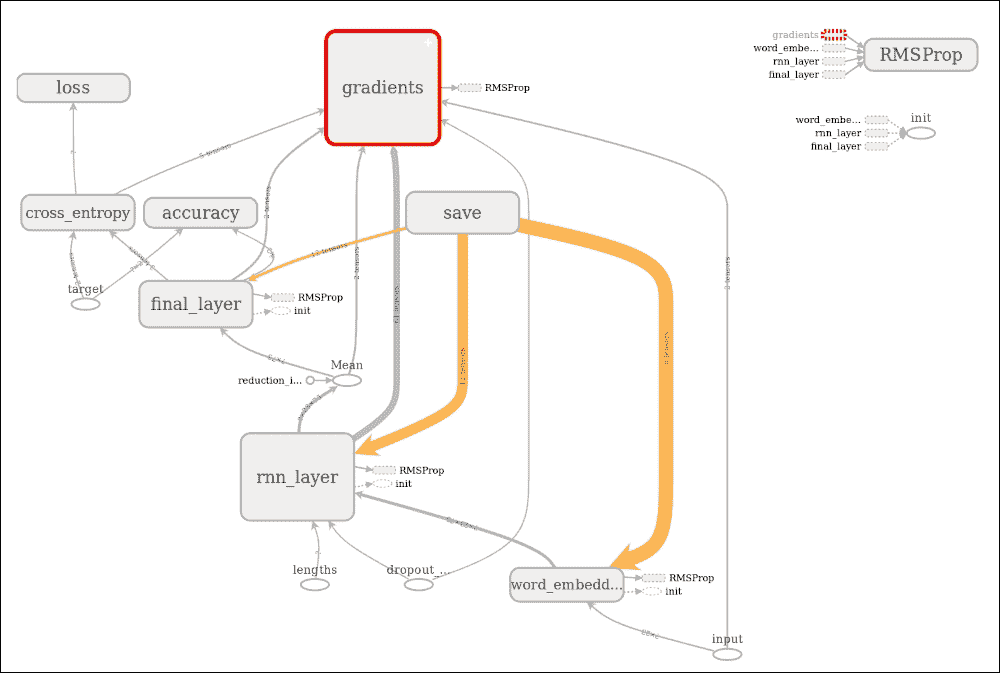
图 22:TensorBoard 上的执行图
执行图显示,我们为这种基于 LSTM 的分类器进行的情感分析计算是非常透明的。我们还可以观察层中的验证,训练损失,准确率和操作:
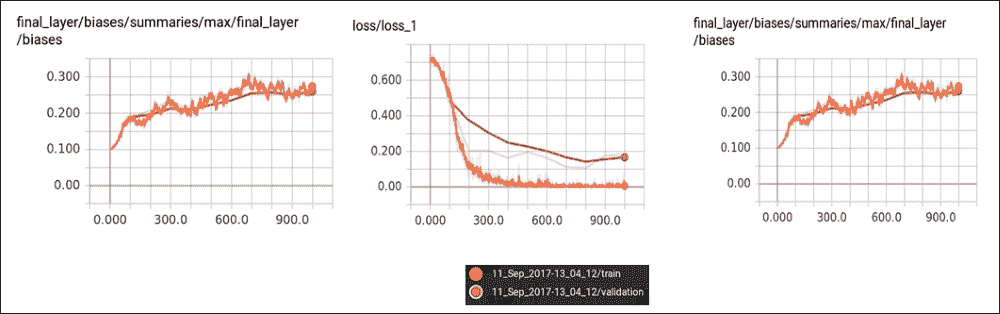
图 23:TensorBoard 层中的验证,训练损失,准确率和操作
LSTM 模型评估
我们已经训练了并保存了我们的 LSTM 模型。我们可以轻松恢复训练模型并进行一些评估。我们需要准备测试集并使用先前训练的 TensorFlow 模型对其进行预测。我们马上做吧。首先,我们加载所需的模型:
import tensorflow as tf
from data_preparation import Preprocessing
import pickle
Then we load to show the checkpoint directory where the model was saved. For our case, it was checkpoints/1505148083.
注意
对于此步骤,使用以下命令执行predict.py脚本:
$ python3 predict.py --checkpoints_dir checkpoints/1517781236
# Change this path based on output by 'python3 train.py'
checkpoints_dir = 'checkpoints/1517781236'
ifcheckpoints_dir is None:
raise ValueError('Please, a valid checkpoints directory is required (--checkpoints_dir <file name>)')
现在加载测试数据集并准备它以评估模型:
data_lstm = Preprocessing(data_dir=data_dir,
stopwords_file=stopwords_file,
sequence_len=sequence_len,
n_samples=n_samples,
test_size=test_size,
val_samples=batch_size,
random_state=random_state,
ensure_preprocessed=True)
在上面的代码中,完全按照我们在训练步骤中的操作使用以下参数:
data_dir = 'data/' # Data directory containing 'data.csv'
stopwords_file = 'data/stopwords.txt' # Path to stopwords file.
sequence_len = None # Maximum sequence length
n_samples= None # Set n_samples=None to use the whole dataset
test_size = 0.2
batch_size = 100 #Batch size
random_state = 0 # Random state used for data splitting. Default is 0
此评估方法的工作流程如下:
- 首先,导入元图并使用测试数据评估模型
- 为计算创建 TensorFlow 会话
- 导入图并恢复其权重
- 恢复输入/输出张量
- 执行预测
- 最后,我们在简单的测试集上打印精度和结果
步骤 1 之前已经完成 。此代码执行步骤 2 到 5:
original_text, x_test, y_test, test_seq_len = data_lstm.get_test_data(original_text=True)
graph = tf.Graph()
with graph.as_default():
sess = tf.Session()
print('Restoring graph ...')
saver = tf.train.import_meta_graph("{}/model.ckpt.meta".format(FLAGS.checkpoints_dir))
saver.restore(sess, ("{}/model.ckpt".format(checkpoints_dir)))
input = graph.get_operation_by_name('input').outputs[0]
target = graph.get_operation_by_name('target').outputs[0]
seq_len = graph.get_operation_by_name('lengths').outputs[0]
dropout_keep_prob = graph.get_operation_by_name('dropout_keep_prob').outputs[0]
predict = graph.get_operation_by_name('final_layer/softmax/predictions').outputs[0]
accuracy = graph.get_operation_by_name('accuracy/accuracy').outputs[0]
pred, acc = sess.run([predict, accuracy],
feed_dict={input: x_test,
target: y_test,
seq_len: test_seq_len,
dropout_keep_prob: 1})
print("Evaluation done.")
以下是上述代码的输出:
>>>
Restoring graph ...
The evaluation was done.
做得好!训练结束了,让我们打印结果:
print('\nAccuracy: {0:.4f}\n'.format(acc))
for i in range(100):
print('Sample: {0}'.format(original_text[i]))
print('Predicted sentiment: [{0:.4f}, {1:.4f}]'.format(pred[i, 0], pred[i, 1]))
print('Real sentiment: {0}\n'.format(y_test[i]))
以下是上述代码的输出:
>>>
Accuracy: 0.9858
Sample: I loved the Da Vinci code, but it raises many theological questions most of which are very absurd...
Predicted sentiment: [0.0000, 1.0000]
Real sentiment: [0\. 1.]
…
Sample: I'm sorry I hate to read Harry Potter, but I love the movies!
Predicted sentiment: [1.0000, 0.0000]
Real sentiment: [1\. 0.]
…
Sample: I LOVE Brokeback Mountain...
Predicted sentiment: [0.0002, 0.9998]
Real sentiment: [0\. 1.]
…
Sample: We also went to see Brokeback Mountain which totally SUCKED!!!
Predicted sentiment: [1.0000, 0.0000]
Real sentiment: [1\. 0.]
精度高于 98%。这太棒了!但是,您可以尝试使用调整的超参数迭代训练以获得更高的迭代次数,您可能会获得更高的准确率。我把它留给读者。
在下一节中,我们将看到如何使用 LSTM 开发更高级的 ML 项目,这被称为使用智能手机数据集的人类活动识别。简而言之,我们的 ML 模型将能够将人类运动分为六类:走路,走楼上,走楼下,坐,站立和铺设。
LSTM 模型和人类活动识别
人类活动识别(HAR)数据库是通过对携带带有嵌入式惯性传感器的腰部智能手机的 30 名参加日常生活活动(ADL)的参与者进行测量而建立的。目标是将他们的活动分类为前面提到的六个类别之一。
数据集描述
实验在一组 30 名志愿者中进行,年龄范围为 19-48 岁。每个人都在腰上戴着三星 Galaxy S II 智能手机,完成了六项活动(步行,走楼上,走楼下,坐着,站着,躺着)。使用加速度计和陀螺仪,作者以 50 Hz 的恒定速率捕获了 3 轴线性加速度和 3 轴角速度。
仅使用两个传感器,加速度计和陀螺仪。通过应用噪声滤波器对传感器信号进行预处理,然后在 2.56 秒的固定宽度滑动窗口中采样,重叠 50%。这样每个窗口提供 128 个读数。来自传感器加速度信号的重力和身体运动分量通过巴特沃斯低通滤波器分离成身体加速度和重力。
欲了解更多信息,请参阅本文:Davide Anguita,Alessandro Ghio,Luca Oneto,Xavier Parra 和 Jorge L. Reyes-Ortiz,使用智能手机进行人类活动识别的公共领域数据集和第 21 届关于人工神经网络的欧洲研讨会,计算智能和机器学习,ESANN 2013.比利时布鲁日 24-26,2013 年 4 月。
为简单起见,假设重力仅具有少量低频分量。因此,使用 0.3Hz 截止频率的滤波器。从每个窗口,通过计算来自时域和频域的变量找到特征向量。
已经对实验进行了视频记录以便于手动标记数据。数据集已被随机分为两组,其中 70% 的志愿者被选中用于训练数据,30% 用于测试数据。当我浏览数据集时,训练集和测试集都具有以下文件结构:
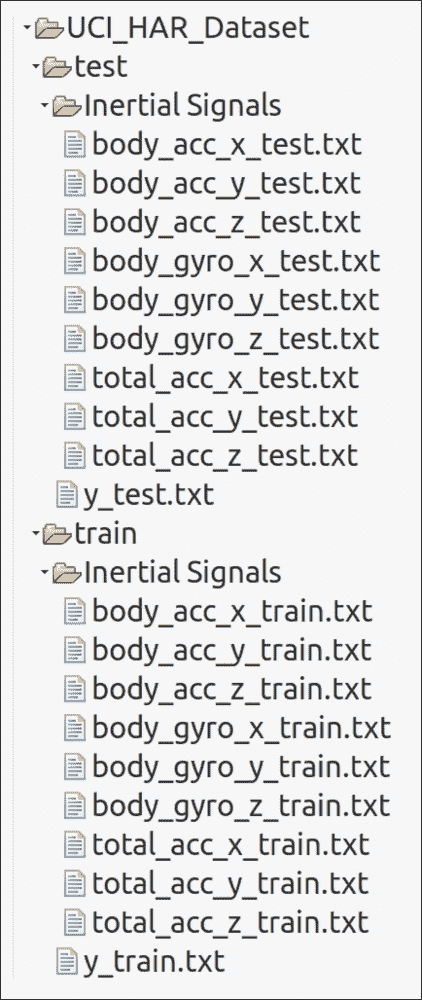
图 24:HAR 数据集文件结构
对于数据集中的每条记录,提供以下内容:
- 来自加速度计的三轴加速度和估计的车身加速度
- 来自陀螺仪传感器的三轴角速度
- 具有时域和频域变量的 561 特征向量
- 它的活动标签
- 进行实验的受试者的标识符
因此,我们知道需要解决的问题。现在是探索技术和相关挑战的时候了。
用于 HAR 的 LSTM 模型的工作流程
整个算法有以下工作流程:
- 加载数据。
- 定义超参数。
- 使用命令式编程和超参数设置 LSTM 模型。
- 应用批量训练。也就是说,选择一批数据,将其提供给模型,然后在一些迭代之后,评估模型并打印批次损失和准确率。
- 输出图的训练和测试误差。
可以遵循上述步骤并构建一个管道:
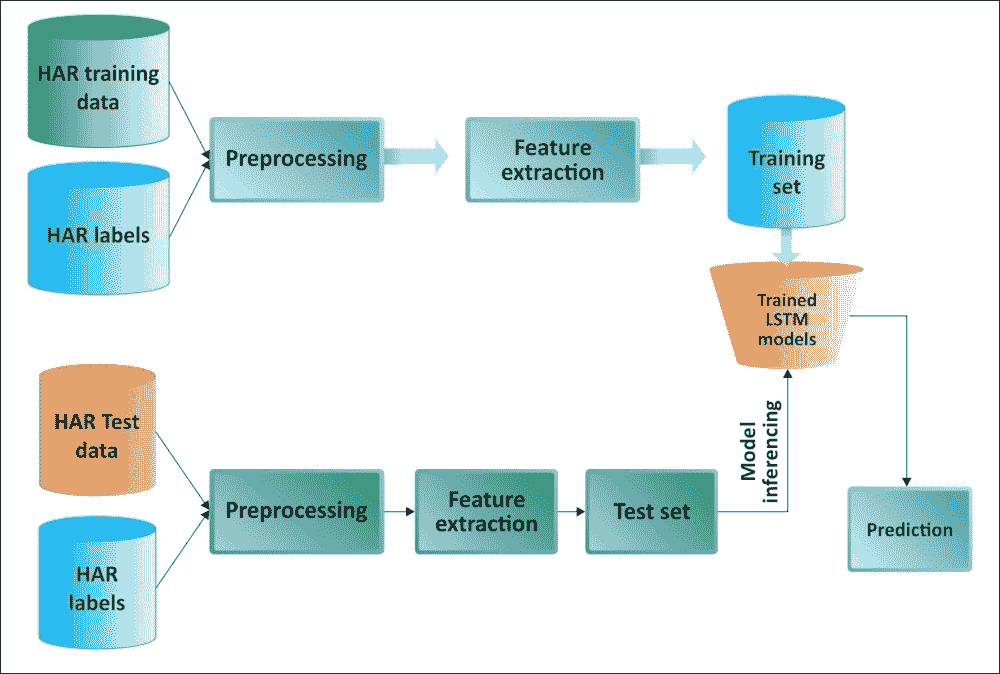
图 25:用于 HAR 的基于 LSTM 的管道
为 HAR 实现 LSTM 模型
首先,我们导入所需的包和模块:
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn import metrics
from tensorflow.python.framework import ops
import warnings
import random
warnings.filterwarnings("ignore")
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
如前所述,INPUT_SIGNAL_TYPES包含一些有用的常量。它们是神经网络的单独标准化输入特征:
INPUT_SIGNAL_TYPES = [
"body_acc_x_",
"body_acc_y_",
"body_acc_z_",
"body_gyro_x_",
"body_gyro_y_",
"body_gyro_z_",
"total_acc_x_",
"total_acc_y_",
"total_acc_z_"
]
标签在另一个数组中定义 - 这是用于学习如何分类的输出类:
LABELS = [
"WALKING",
"WALKING_UPSTAIRS",
"WALKING_DOWNSTAIRS",
"SITTING",
"STANDING",
"LAYING"
]
我们现在假设您已经从[此链接](https://archive.ics.uci.edu/ml/machine-learning-databases/00240/UCI HAR Dataset.zip)下载了 HAR 数据集并输入了名为UCIHARDataset的文件夹(或者您可以选择听起来更合适的合适名称)。此外,我们需要提供训练和测试集的路径:
DATASET_PATH = "UCIHARDataset/"
print("\n" + "Dataset is now located at: " + DATASET_PATH)
TRAIN = "train/"
TEST = "test/"
然后我们加载并根据由[Array [Array [Float]]]格式的INPUT_SIGNAL_TYPES数组定义的输入信号类型,映射每个.txt文件的数据。X表示神经网络的训练和测试输入:
def load_X(X_signals_paths):
X_signals = []
for signal_type_path in X_signals_paths:
file = open(signal_type_path, 'r')
# Read dataset from disk, dealing with text files' syntax
X_signals.append(
[np.array(serie, dtype=np.float32) for serie in [
row.replace(' ', ' ').strip().split(' ') for row in file
]]
)
file.close()
return np.transpose(np.array(X_signals), (1, 2, 0))
X_train_signals_paths = [DATASET_PATH + TRAIN + "Inertial Signals/" + signal + "train.txt" for signal in INPUT_SIGNAL_TYPES]
X_test_signals_paths = [DATASET_PATH + TEST + "Inertial Signals/" + signal + "test.txt" for signal in INPUT_SIGNAL_TYPES]
X_train = load_X(X_train_signals_paths)
X_test = load_X(X_test_signals_paths)
然后我们加载y,神经网络的训练和测试输出的标签:
def load_y(y_path):
file = open(y_path, 'r')
# Read dataset from disk, dealing with text file's syntax
y_ = np.array(
[elem for elem in [
row.replace(' ', ' ').strip().split(' ') for row in file
]],
dtype=np.int32
)
file.close()
# We subtract 1 to each output class for 0-based indexing
return y_ - 1
y_train_path = DATASET_PATH + TRAIN + "y_train.txt"
y_test_path = DATASET_PATH + TEST + "y_test.txt"
y_train = load_y(y_train_path)
y_test = load_y(y_test_path)
让我们看看一些数据集的统计数据,例如训练系列的数量(如前所述,每个系列之间有 50% 的重叠),测试系列的数量,每个系列的时间步数,以及每个时间步输入参数:
training_data_count = len(X_train)
test_data_count = len(X_test)
n_steps = len(X_train[0])
n_input = len(X_train[0][0])
print("Number of training series: "+ trainingDataCount)
print("Number of test series: "+ testDataCount)
print("Number of timestep per series: "+ nSteps)
print("Number of input parameters per timestep: "+ nInput)
以下是上述代码的输出:
>>>
Number of training series: 7352
Number of test series: 2947
Number of timestep per series: 128
Number of input parameters per timestep: 9
现在让我们为训练定义一些核心参数定义。整个神经网络的结构可以通过枚举这些参数和使用 LSTM 这一事实来概括:
n_hidden = 32 # Hidden layer num of features
n_classes = 6 # Total classes (should go up, or should go down)
learning_rate = 0.0025
lambda_loss_amount = 0.0015
training_iters = training_data_count * 300 #Iterate 300 times
batch_size = 1500
display_iter = 30000 # to show test set accuracy during training
我们已经定义了所有核心参数和网络参数。这些是随机选择。我没有进行超参数调整,但仍然运行良好。因此,我建议使用网格搜索技术调整这些超参数。有许多在线资料可供使用。
然而,在构建 LSTM 网络并开始训练之前,让我们打印一些调试信息,以确保执行不会中途停止:
print("Some useful info to get an insight on dataset's shape and normalization:")
print("(X shape, y shape, every X's mean, every X's standard deviation)")
print(X_test.shape, y_test.shape, np.mean(X_test), np.std(X_test))
print("The dataset is therefore properly normalized, as expected, but not yet one-hot encoded.")
以下是上述代码的输出:
>>>
Some useful info to get an insight on dataset's shape and normalization:
(X shape, y shape, every X's mean, every X's standard deviation)
(2947, 128, 9) (2947, 1) 0.0991399 0.395671
数据集是 ,因此按预期正确标准化,但尚未进行单热编码。
现在训练数据集处于校正和标准化顺序,现在是构建 LSTM 网络的时候了。以下函数从给定参数返回 TensorFlow LSTM 网络。此外,两个 LSTM 单元堆叠在一起,这增加了神经网络的深度:
def LSTM_RNN(_X, _weights, _biases):
_X = tf.transpose(_X, [1,0,2])# permute n_steps & batch_size
_X = tf.reshape(_X, [-1, n_input])
_X = tf.nn.relu(tf.matmul(_X, _weights['hidden']) + _biases['hidden'])
_X = tf.split(_X, n_steps, 0)
lstm_cell_1 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0, state_is_tuple=True)
lstm_cell_2 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0, state_is_tuple=True)
lstm_cells = tf.nn.rnn_cell.MultiRNNCell([lstm_cell_1, lstm_cell_2], state_is_tuple=True)
outputs, states = tf.contrib.rnn.static_rnn(lstm_cells, _X, dtype=tf.float32)
lstm_last_output = outputs[-1]
return tf.matmul(lstm_last_output, _weights['out']) + _biases['out']
如果我们仔细查看前面的代码片段,我们可以看到我们得到了“多对一”样式分类器的最后一步输出特征。现在,问题是什么是多对一 RNN 分类器?好吧,类似于图 5,我们接受特征向量的时间序列(每个时间步长一个向量)并将它们转换为输出中的概率向量以进行分类。
现在我们已经能够构建我们的 LSTM 网络,我们需要将训练数据集准备成批量。以下函数从(X|y)_train数据中获取batch_size数据量:
def extract_batch_size(_train, step, batch_size):
shape = list(_train.shape)
shape[0] = batch_size
batch_s = np.empty(shape)
for i in range(batch_size):
index = ((step-1)*batch_size + i) % len(_train)
batch_s[i] = _train[index]
return batch_s
之后,我们需要将数字索引的输出标签编码为二元类别。然后我们用batch_size执行训练步骤。例如,[[5], [0], [3]]需要转换为类似于[[0, 0, 0, 0, 0, 1], [1, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0]]的形状。好吧,我们可以用单热编码来做到这一点。以下方法执行完全相同的转换:
def one_hot(y_):
y_ = y_.reshape(len(y_))
n_values = int(np.max(y_)) + 1
return np.eye(n_values)[np.array(y_, dtype=np.int32)]
优秀的!我们的数据集准备就绪,因此我们可以开始构建网络。首先,我们为输入和标签创建两个单独的占位符:
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
然后我们创建所需的权重向量:
weights = {
'hidden': tf.Variable(tf.random_normal([n_input, n_hidden])),
'out': tf.Variable(tf.random_normal([n_hidden, n_classes], mean=1.0))
}
然后我们创建所需的偏向量:
biases = {
'hidden': tf.Variable(tf.random_normal([n_hidden])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
然后我们通过传递输入张量,权重向量和偏置向量来构建模型,如下所示:
pred = LSTM_RNN(x, weights, biases)
此外,我们还需要计算cost操作,正则化,优化器和评估。我们使用 L2 损失进行正则化,这可以防止这种过度杀伤神经网络过度适应训练中的问题:
l2 = lambda_loss_amount * sum(tf.nn.l2_loss(tf_var) for tf_var in tf.trainable_variables())
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y, logits=pred)) + l2
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
Great! So far, everything has been fine. Now we are ready to train the neural network. First, we create some lists to hold some training's performance:
test_losses = []
test_accuracies = []
train_losses = []
train_accuracies = []
然后我们创建一个 TensorFlow 会话,启动图并初始化全局变量:
sess = tf.InteractiveSession(config=tf.ConfigProto(log_device_placement=False))
init = tf.global_variables_initializer()
sess.run(init)
然后我们在每个循环中以batch_size数量的示例数据执行训练步骤。我们首先使用批量数据进行训练,然后我们仅在几个步骤评估网络以加快训练速度。另外,我们评估测试集(这里没有学习,只是诊断评估)。最后,我们打印结果:
step = 1
while step * batch_size <= training_iters:
batch_xs = extract_batch_size(X_train, step, batch_size)
batch_ys = one_hot(extract_batch_size(y_train, step, batch_size))
_, loss, acc = sess.run(
[optimizer, cost, accuracy],
feed_dict={
x: batch_xs,
y: batch_ys
}
)
train_losses.append(loss)
train_accuracies.append(acc)
if (step*batch_size % display_iter == 0) or (step == 1) or (step * batch_size > training_iters):
print("Training iter #" + str(step*batch_size) + \": Batch Loss = " + "{:.6f}".format(loss) + \", Accuracy = {}".format(acc))
loss, acc = sess.run(
[cost, accuracy],
feed_dict={
x: X_test,
y: one_hot(y_test)
}
)
test_losses.append(loss)
test_accuracies.append(acc)
print("PERFORMANCE ON TEST SET: " + \
"Batch Loss = {}".format(loss) + \
", Accuracy = {}".format(acc))
step += 1
print("Optimization Finished!")
one_hot_predictions, accuracy, final_loss = sess.run(
[pred, accuracy, cost],
feed_dict={
x: X_test,
y: one_hot(y_test)
})
test_losses.append(final_loss)
test_accuracies.append(accuracy)
print("FINAL RESULT: " + \
"Batch Loss = {}".format(final_loss) + \
", Accuracy = {}".format(accuracy))
以下是上述代码的输出:
>>>
Training iter #1500: Batch Loss = 3.266330, Accuracy = 0.15733332931995392
PERFORMANCE ON TEST SET: Batch Loss = 2.6498606204986572, Accuracy = 0.15473362803459167
Training iter #30000: Batch Loss = 1.538126, Accuracy = 0.6380000114440918
…PERFORMANCE ON TEST SET: Batch Loss = 0.5507552623748779, Accuracy = 0.8924329876899719
Optimization Finished!
FINAL RESULT: Batch Loss = 0.6077192425727844, Accuracy = 0.8686800003051758
做得好! 训练进展顺利。但是,视觉概述会更有用:
indep_train_axis = np.array(range(batch_size, (len(train_losses)+1)*batch_size, batch_size))
plt.plot(indep_train_axis, np.array(train_losses), "b--", label="Train losses")
plt.plot(indep_train_axis, np.array(train_accuracies), "g--", label="Train accuracies")
indep_test_axis = np.append(np.array(range(batch_size, len(test_losses)*display_iter, display_iter)[:-1]),
[training_iters])
plt.plot(indep_test_axis, np.array(test_losses), "b-", label="Test losses")
plt.plot(indep_test_axis, np.array(test_accuracies), "g-", label="Test accuracies")
plt.title("Training session's progress over iterations")
plt.legend(loc='upper right', shadow=True)
plt.ylabel('Training Progress (Loss or Accuracy values)')
plt.xlabel('Training iteration')
plt.show()
以下是上述代码的输出:
>>>
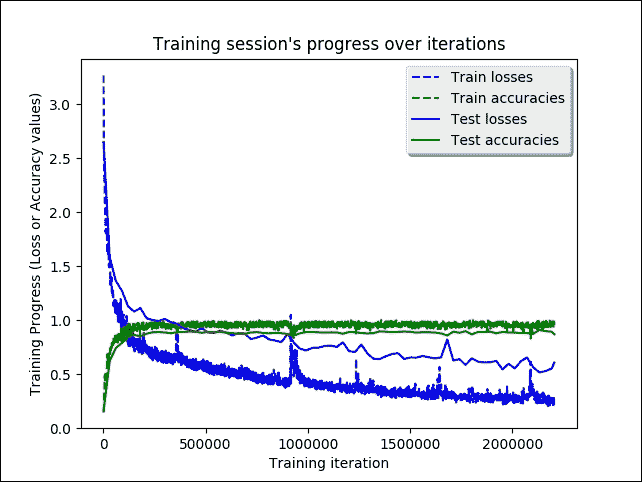
图 26:迭代时的 LSTM 训练过程
我们需要计算其他表现指标,例如accuracy,precision,recall和f1度量:
predictions = one_hot_predictions.argmax(1)
print("Testing Accuracy: {}%".format(100*accuracy))
print("")
print("Precision: {}%".format(100*metrics.precision_score(y_test, predictions, average="weighted")))
print("Recall: {}%".format(100*metrics.recall_score(y_test, predictions, average="weighted")))
print("f1_score: {}%".format(100*metrics.f1_score(y_test, predictions, average="weighted")))
以下是上述代码的输出:
>>>
Testing Accuracy: 89.51476216316223%
Precision: 89.65053428376297%
Recall: 89.51476077366813%
f1_score: 89.48593061935716%
由于我们正在接近的问题是多类分类,因此绘制混淆矩阵是有意义的:
print("")
print ("Showing Confusion Matrix")
cm = metrics.confusion_matrix(y_test, predictions)
df_cm = pd.DataFrame(cm, LABELS, LABELS)
plt.figure(figsize = (16,8))
plt.ylabel('True label')
plt.xlabel('Predicted label')
sn.heatmap(df_cm, annot=True, annot_kws={"size": 14}, fmt='g', linewidths=.5)
plt.show()
以下是上述代码的输出:
>>>

图 27:多类混淆矩阵(预测与实际)
在混淆矩阵中,训练和测试数据不是在类之间平均分配,因此正常情况下,超过六分之一的数据在最后一类中被正确分类。话虽如此,我们已经设法达到约 87% 的预测准确率。我们很快就会看到更多分析。它可能更高,但是训练是在 CPU 上进行的,因此它的精度很低,当然需要很长时间。因此,我建议你在 GPU 上训练,以获得更好的结果。此外,调整超参数可能是一个不错的选择。
总结
LSTM 网络配备了特殊的隐藏单元,称为存储单元,其目的是长时间记住先前的输入。这些单元在每个时刻采用先前状态和网络的当前输入作为输入。通过将它们与内存的当前内容相结合,并通过其他单元的门控机制决定保留什么以及从内存中删除什么,LSTM 已被证明是非常有用的并且是学习长期依赖性的有效方式。
在本章中,我们讨论了 RNN。我们看到了如何使用具有高时间依赖性的数据进行预测。我们看到了如何开发几种真实的预测模型,使用 RNN 和不同的架构变体使预测分析更容易。我们从 RNN 的理论背景开始。
然后我们看了几个例子,展示了一种实现图像分类预测模型,电影和产品情感分析以及 NLP 垃圾邮件预测的系统方法。然后我们看到了如何开发时间序列数据的预测模型。最后,我们看到了 RNN 用于人类活动识别的更高级应用,我们观察到分类准确率约为 87%。
DNN 以统一的方式构造,使得在网络的每一层,数千个相同的人工神经元执行相同的计算。因此,DNN 的架构非常适合 GPU 可以有效执行的计算类型。 GPU 具有优于 CPU 的额外优势;这些包括具有更多计算单元并具有更高的带宽用于存储器检索。
此外,在许多需要大量计算工作的深度学习应用中,可以利用 GPU 的图形特定功能来进一步加速计算。在下一章中,我们将看到如何使训练更快,更准确,甚至在节点之间分配。
七、TensorFlow GPU 配置
要将 TensorFlow 与 NVIDIA GPU 配合使用,第一步是安装 CUDA 工具包。
注意
要了解更多信息,请访问此链接。
安装 CUDA 工具包后,必须从此链接下载适用于 Linux 的 cuDNN v5.1 库。
cuDNN 是一个有助于加速深度学习框架的库,例如 TensorFlow 和 Theano。以下是 NVIDIA 网站的简要说明:
NVIDIACUDA®深度神经网络库(cuDNN)是用于深度神经网络的 GPU 加速原语库.cuDNN 为标准例程提供高度调整的实现,例如前向和后向卷积,池化,正则化和激活层。cuDNN 是 NVIDIA 深度学习 SDK 的一部分。
在安装之前,您需要在 NVIDIA 的加速计算开发人员计划中注册。注册后,登录并将 cuDNN 5.1 下载到本地计算机。
下载完成后,解压缩文件并将其复制到 CUDA 工具包目录中(我们假设目录为/usr/local/cuda/):
$ sudo tar -xvf cudnn-8.0-linux-x64-v5.1-rc.tgz -C /usr/local
更新 TensorFlow
我们假设您将使用 TensorFlow 来构建您的深度神经网络模型。只需通过 PIP 用upgrade标志更新 TensorFlow。
我们假设您当前正在使用 TensorFlow 0.11:
pip install — upgrade https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow-0.10.0rc0-cp27-none-linux_x86_64.whl
现在,您应该拥有使用 GPU 运行模型所需的一切。
GPU 表示
在 TensorFlow 中, 支持的设备表示为字符串:
"/cpu:0":您机器的 CPU"/gpu:0":机器的 GPU,如果你有的话"/gpu:1":你机器的第二个 GPU,依此类推
当将操作分配给 GPU 设备时, 执行流程给予优先级。
GPU 使用
要在 TensorFlow 程序中使用 GPU,只需键入以下内容:
with tf.device("/gpu:0"):
然后你需要进行设置操作。这行代码将创建一个新的上下文管理器,告诉 TensorFlow 在 GPU 上执行这些操作。
让我们考虑以下示例,其中我们要执行以下两个大矩阵的和:A^n + B^n。
定义基本导入:
import numpy as np
import tensorflow as tf
import datetime
我们可以配置 TensorFlow 程序,以找出您的操作和张量分配给哪些设备。为此,我们将创建一个会话,并将以下log_device_placement参数设置为True:
log_device_placement = True
然后我们设置n参数,这是要执行的乘法次数:
n=10
然后我们构建两个随机大矩阵。我们使用 NumPy rand函数来执行此操作:
A = np.random.rand(10000, 10000).astype('float32')
B = np.random.rand(10000, 10000).astype('float32')
A和B各自的大小为10000x10000。
以下数组将用于存储结果:
c1 = []
c2 = []
接下来,我们定义将由 GPU 执行的内核矩阵乘法函数:
def matpow(M, n):
if n == 1:
return M
else:
return tf.matmul(M, matpow(M, n-1))
正如我们之前解释的 ,我们必须配置 GPU 和 GPU 以执行以下操作:
GPU 将计算A^n和B^n操作并将结果存储在c1中:
with tf.device('/gpu:0'):
a = tf.placeholder(tf.float32, [10000, 10000])
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
c1.append(matpow(b, n))
c1(A^n + B^n)中所有元素的添加由 CPU 执行,因此我们定义以下内容:
with tf.device('/cpu:0'):
sum = tf.add_n(c1)
datetime类允许我们得到计算时间:
t1_1 = datetime.datetime.now()
with tf.Session(config=tf.ConfigProto\
(log_device_placement=log_device_placement)) as sess:
sess.run(sum, {a:A, b:B})
t2_1 = datetime.datetime.now()
然后显示计算时间:
print("GPU computation time: " + str(t2_1-t1_1))
在我的笔记本电脑上,使用 GeForce 840M 显卡,结果如下:
GPU computation time: 0:00:13.816644
GPU 内存管理
在一些情况下,希望该过程仅分配可用内存的子集,或者仅增加该过程所需的内存使用量。 TensorFlow 在会话中提供两个配置选项来控制它。
第一个是allow_growth选项,它尝试根据运行时分配仅分配尽可能多的 GPU 内存:它开始分配非常少的内存,并且随着会话运行并需要更多 GPU 内存,我们扩展 GPU 内存量 TensorFlow 流程需要。
请注意, 我们不释放内存,因为这可能导致更糟糕的内存碎片。要打开此选项,请在ConfigProto中设置选项,如下所示:
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config, ...)
第二种方法是per_process_gpu_memory_fraction选项,它确定应分配每个可见 GPU 的总内存量的分数。例如,您可以告诉 TensorFlow 仅分配每个 GPU 总内存的 40%,如下所示:
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
session = tf.Session(config=config, ...)
如果要真正限制 TensorFlow 进程可用的 GPU 内存量,这非常有用。
在多 GPU 系统上分配单个 GPU
如果系统中有多个 GPU,则默认情况下将选择 ID 最低的 GPU。如果您想在不同的 GPU 上运行会话,则需要明确指定首选项。
例如,我们可以尝试更改上一代码中的 GPU 分配:
with tf.device('/gpu:1'):
a = tf.placeholder(tf.float32, [10000, 10000])
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
c1.append(matpow(b, n))
这样,我们告诉gpu1执行内核函数。如果我们指定的设备不存在(如我的情况),您将获得InvalidArgumentError:
InvalidArgumentError (see above for traceback): Cannot assign a device to node 'Placeholder_1': Could not satisfy explicit device specification '/device:GPU:1' because no devices matching that specification are registered in this process; available devices: /job:localhost/replica:0/task:0/cpu:0
[[Node: Placeholder_1 = Placeholder[dtype=DT_FLOAT, shape=[100,100], _device="/device:GPU:1"]()]]
如果您希望 TensorFlow 自动选择现有且受支持的设备来运行操作(如果指定的设备不存在),则可以在创建会话时在配置选项中将allow_soft_placement设置为True。
我们再次为以下节点设置'/gpu:1':
with tf.device('/gpu:1'):
a = tf.placeholder(tf.float32, [10000, 10000])
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
c1.append(matpow(b, n))
然后我们构建一个Session,并将以下allow_soft_placement参数设置为True:
with tf.Session(config=tf.ConfigProto\
(allow_soft_placement=True,\
log_device_placement=log_device_placement))\
as sess:
这样,当我们运行会话时,不会显示InvalidArgumentError。在这种情况下,我们会得到一个正确的结果,但有一点延迟:
GPU computation time: 0:00:15.006644
具有软放置的 GPU 的源代码
这是完整源代码,仅为了清楚起见:
import numpy as np
import tensorflow as tf
import datetime
log_device_placement = True
n = 10
A = np.random.rand(10000, 10000).astype('float32')
B = np.random.rand(10000, 10000).astype('float32')
c1 = []
c2 = []
def matpow(M, n):
if n == 1:
return M
else:
return tf.matmul(M, matpow(M, n-1))
with tf.device('/gpu:0'):
a = tf.placeholder(tf.float32, [10000, 10000])
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
c1.append(matpow(b, n))
with tf.device('/cpu:0'):
sum = tf.add_n(c1)
t1_1 = datetime.datetime.now()
with tf.Session(config=tf.ConfigProto\
(allow_soft_placement=True,\
log_device_placement=log_device_placement))\
as sess:
sess.run(sum, {a:A, b:B})
t2_1 = datetime.datetime.now()
使用多个 GPU
如果您想在多个 GPU 上运行 TensorFlow,您可以通过为 GPU 分配特定的代码块来构建模型。例如,如果我们有两个 GPU,我们可以按如下方式拆分前面的代码,将第一个矩阵计算分配给第一个 GPU:
with tf.device('/gpu:0'):
a = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
第二个矩阵计算分配给第二个 GPU:
with tf.device('/gpu:1'):
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(b, n))
CPU 将管理结果。另请注意,我们使用共享c1数组来收集它们:
with tf.device('/cpu:0'):
sum = tf.add_n(c1)
在下面的代码片段中,我们提供了两个 GPU 管理的具体示例:
import numpy as np
import tensorflow as tf
import datetime
log_device_placement = True
n = 10
A = np.random.rand(10000, 10000).astype('float32')
B = np.random.rand(10000, 10000).astype('float32')
c1 = []
def matpow(M, n):
if n == 1:
return M
else:
return tf.matmul(M, matpow(M, n-1))
#FIRST GPU
with tf.device('/gpu:0'):
a = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
#SECOND GPU
with tf.device('/gpu:1'):
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(b, n))
with tf.device('/cpu:0'):
sum = tf.add_n(c1)
t1_1 = datetime.datetime.now()
with tf.Session(config=tf.ConfigProto\
(allow_soft_placement=True,\
log_device_placement=log_device_placement))\
as sess:
sess.run(sum, {a:A, b:B})
t2_1 = datetime.datetime.now()
分布式计算
DL 模型必须接受大量数据的训练,以提高其表现。但是,训练具有数百万参数的深度网络可能需要数天甚至数周。在大规模分布式深度网络中,Dean 等人。提出了两种范例,即模型并行性和数据并行性,它们允许我们在多个物理机器上训练和服务网络模型。在下一节中,我们引入了这些范例,重点关注分布式 TensorFlow 功能。
模型并行
模型并行性为每个处理器提供相同的数据,但对其应用不同的模型。如果网络模型太大而无法放入一台机器的内存中,则可以将模型的不同部分分配给不同的机器。可能的模型并行方法是在机器(节点 1)上具有第一层,在第二机器(节点 2)上具有第二层,等等。有时这不是最佳方法,因为最后一层必须等待在前进步骤期间完成第一层的计算,并且第一层必须在反向传播步骤期间等待最深层。只有模型可并行化(例如 GoogleNet)才能在不同的机器上实现,而不会遇到这样的瓶颈:
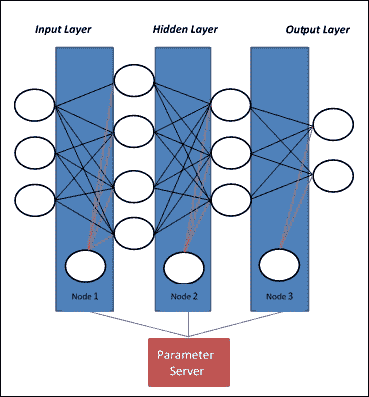
图 3:在模型并行性中,每个节点计算网络的不同部分
大约 20 年前, 训练神经网络的人可能是术语模型并行性的创始人,因为他们有不同的神经网络模型来训练和测试,并且网络中的多个层可以用相同的数据。
数据并行
数据并行性表示将单个指令应用于多个数据项。它是 SIMD(单指令,多数据)计算机架构的理想工作负载,是电子数字计算机上最古老,最简单的并行处理形式。
在这种方法中,网络模型适合于一台机器,称为参数服务器,而大多数计算工作由多台机器完成,称为工作器:
- 参数服务器:这是一个 CPU,您可以在其中存储工作器所需的变量。就我而言,这是我定义网络所需的权重变量的地方。
- 工作器:这是我们完成大部分计算密集型工作的地方。
每个工作器负责读取,计算和更新模型参数,并将它们发送到参数服务器:
-
在正向传播中,工作者从参数服务器获取变量,在我们的工作者上对它们执行某些操作。
-
在向后传递中,工作器将当前状态发送回参数服务器,参数服务器执行更新操作,并为我们提供新的权重以进行尝试:
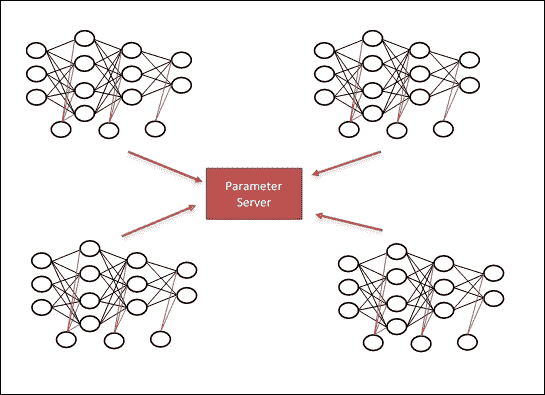
图 4:在数据并行模型中,每个节点计算所有参数
数据并行可能有两个主要的选项:
- 同步训练:所有工作器同时读取参数,计算训练操作,并等待所有其他人完成。然后将梯度平均,并将单个更新发送到参数服务器。因此,在任何时间点,工作器都将意识到图参数的相同值。
- 异步训练:工作器将异步读取参数服务器,计算训练操作,并发送异步更新。在任何时间点,两个不同的工作器可能会意识到图参数的不同值。
分布式 TensorFlow 配置
在本节中,我们将探索 TensorFlow 中的计算可以分布的机制。运行分布式 TensorFlow 的第一步是使用tf.train.ClusterSpec指定集群的架构:
import tensorflow as tf
cluster = tf.train.ClusterSpec({"ps": ["localhost:2222"],\
"worker": ["localhost:2223",\
"localhost:2224"]})
节点通常分为两个作业:主机变量的参数服务器(ps)和执行大量计算的工作器。在上面的代码中,我们有一个参数服务器和两个工作器,以及每个节点的 IP 地址和端口。
然后我们必须为之前定义的每个参数服务器和工作器构建一个tf.train.Server:
ps = tf.train.Server(cluster, job_name="ps", task_index=0)
worker0 = tf.train.Server(cluster,\
job_name="worker", task_index=0)
worker1 = tf.train.Server(cluster,\
job_name="worker", task_index=1)
tf.train.Server对象包含一组本地设备,一组与tf.train.ClusterSpec中其他任务的连接,以及一个可以使用它们执行分布式计算的tf.Session。创建它是为了允许设备之间的连接。
接下来,我们使用以下命令将模型变量分配给工作器:
tf.device :
with tf.device("/job:ps/task:0"):
a = tf.constant(3.0, dtype=tf.float32)
b = tf.constant(4.0)
将这些指令复制到名为main.py的文件中。
在两个单独的文件worker0.py和worker1.py中,我们必须定义工作器。在worker0.py中,将两个变量a和b相乘并打印出结果:
import tensorflow as tf
from main import *
with tf.Session(worker0.target) as sess:
init = tf.global_variables_initializer()
add_node = tf.multiply(a,b)
sess.run(init)
print(sess.run(add_node))
在worker1.py中,首先更改a的值,然后将两个变量a和b相乘:
import tensorflow as tf
from main import *
with tf.Session(worker1.target) as sess:
init = tf.global_variables_initializer()
a = tf.constant(10.0, dtype=tf.float32)
add_node = tf.multiply(a,b)
sess.run(init)
a = add_node
print(sess.run(add_node))
要执行此示例,首先从命令提示符运行main.py文件。
你应该得到这样的结果:
>python main.py
Found device 0 with properties:
name: GeForce 840M
major: 5 minor: 0 memoryClockRate (GHz) 1.124
pciBusID 0000:08:00.0
Total memory: 2.00GiB
Free memory: 1.66GiB
Started server with target: grpc://localhost:2222
然后我们可以运行工作器:
> python worker0.py
Found device 0 with properties:
name: GeForce 840M
major: 5 minor: 0 memoryClockRate (GHz) 1.124
pciBusID 0000:08:00.0
Total memory: 2.00GiB
Free memory: 1.66GiB
Start master session 83740f48d039c97d with config:
12.0
> python worker1.py
Found device 0 with properties:
name: GeForce 840M
major: 5 minor: 0 memoryClockRate (GHz) 1.124
pciBusID 0000:08:00.0
Total memory: 2.00GiB
Free memory: 1.66GiB
Start master session 3465f63a4d9feb85 with config:
40.0
总结
在本章中,我们快速了解了与优化 DNN 计算相关的两个基本主题。
第一个主题解释了如何使用 GPU 和 TensorFlow 来实现 DNN。它们以非常统一的方式构造,使得在网络的每一层,数千个相同的人工神经元执行相同的计算。因此,DNN 的架构非常适合 GPU 可以有效执行的计算类型。
第二个主题介绍了分布式计算。这最初用于执行非常复杂的计算,这些计算无法由单个机器完成。同样,在面对如此大的挑战时,通过在不同节点之间拆分此任务来快速分析大量数据似乎是最佳策略。
同时,可以使用分布式计算来利用 DL 问题。 DL 计算可以分为多个活动(任务);他们每个人都将获得一小部分数据,并返回一个结果,该结果必须与其他活动提供的结果重新组合。或者,在大多数复杂情况下,可以为每台机器分配不同的计算算法。
最后,在最后一个例子中,我们展示了如何分配 TensorFlow 中的计算。
八、TFLearn
TFLearn 是一个库,它使用漂亮且熟悉的 scikit-learn API 包装了许多新的 TensorFlow API。
TensorFlow 是关于构建和执行图的全部内容。这是一个非常强大的概念,但从一开始就很麻烦。
在 TFLearn 的引擎盖下,我们只使用了三个部分:
- 层:一组高级 TensorFlow 函数,允许我们轻松构建复杂的图,从完全连接的层,卷积和批量规范到损失和优化。
graph_actions:一组工具,用于对 TensorFlow 图进行训练,评估和运行推理。- 估计器:将所有内容打包成一个遵循 scikit-learn 接口的类,并提供了一种轻松构建和训练自定义 TensorFlow 模型的方法。
安装
要安装 TFLearn, 最简单的方法是运行以下命令:
pip install git+https://github.com/tflearn/tflearn.git
对于最新的稳定版本,请使用以下命令:
pip install tflearn
否则,您也可以通过运行以下命令(从源文件夹)从源安装它:
python setup.py install
泰坦尼克号生存预测器
在本教程中,我们将学习使用 TFLearn 和 TensorFlow,使用他们的个人信息(如性别和年龄)模拟泰坦尼克号乘客的生存机会。为了解决这个经典的 ML 任务,我们将构建一个 DNN 分类器。
我们来看看数据集(TFLearn 将自动为您下载)。
对于每位乘客,提供以下信息:
survived Survived (0 = No; 1 = Yes)
pclass Passenger Class (1 = st; 2 = nd; 3 = rd)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare
以下是数据集中的一些示例:
sibsp | parch | ticket | fare |
|---|---|---|---|
| 1 | 1 | Aubart, Mme. Leontine Pauline | female |
| 0 | 2 | Bowenur, Mr. Solomon | male |
| 1 | 3 | Baclini, Miss. Marie Catherine | female |
| 0 | 3 | Youseff, Mr. Gerious | male |
我们的任务有两个类:没有幸存(class = 0)和幸存(class = 1)。乘客数据有 8 个特征。泰坦尼克号数据集存储在 CSV 文件中,因此我们可以使用TFLearn load_csv()函数将文件中的数据加载到 Python 列表中。我们指定target_column参数以指示我们的标签(幸存与否)位于第一列(ID:0)。这些函数将返回一个元组:(数据,标签)。
让我们从导入 NumPy 和 TFLearn 库开始:
import numpy as np
import tflearn as tfl
下载泰坦尼克号数据集:
from tflearn.datasets import titanic
titanic.download_dataset('titanic_dataset.csv')
加载 CSV 文件,并指出第一列代表labels:
from tflearn.data_utils import load_csv
data, labels = load_csv('titanic_dataset.csv', target_column=0,
categorical_labels=True, n_classes=2)
在准备好在我们的 DNN 分类器中使用之前,数据需要一些预处理。我们必须删除无法帮助我们进行分析的列字段。我们丢弃名称和票据字段,因为我们估计乘客的姓名和票证与他们的幸存机会无关:
def preprocess(data, columns_to_ignore):
预处理阶段从降序 ID 和删除列开始:
for id in sorted(columns_to_ignore, reverse=True):
[r.pop(id) for r in data]
for i in range(len(data)):
性别场转换为浮动(待操纵):
data[i][1] = 1\. if data[i][1] == 'female' else 0.
return np.array(data, dtype=np.float32)
如前所述,分析将忽略名称和故障单字段:
to_ignore=[1, 6]
然后我们调用preprocess程序:
data = preprocess(data, to_ignore)
接下来,我们指定输入数据的形状。输入样本总共有6特征,我们将分批量样本以节省内存,因此我们的数据输入形状为[None, 6]。None参数表示未知维度,因此我们可以更改批量中处理的样本总数:
net = tfl.input_data(shape=[None, 6])
最后,我们用这个简单的语句序列构建了一个 3 层神经网络:
net = tfl.fully_connected(net, 32)
net = tfl.fully_connected(net, 32)
net = tfl.fully_connected(net, 2, activation='softmax')
net = tfl.regression(net)
TFLearn 提供了一个模型包装器DNN,它自动执行神经网络分类器任务:
model = tfl.DNN(net)
我们将为批量大小为16的10周期运行它:
model.fit(data, labels, n_epoch=10, batch_size=16, show_metric=True)
当我们运行模型时,我们应该得到以下输出:
Training samples: 1309
Validation samples: 0
--
Training Step: 82 | total loss: 0.64003
| Adam | epoch: 001 | loss: 0.64003 - acc: 0.6620 -- iter: 1309/1309
--
Training Step: 164 | total loss: 0.61915
| Adam | epoch: 002 | loss: 0.61915 - acc: 0.6614 -- iter: 1309/1309
--
Training Step: 246 | total loss: 0.56067
| Adam | epoch: 003 | loss: 0.56067 - acc: 0.7171 -- iter: 1309/1309
--
Training Step: 328 | total loss: 0.51807
| Adam | epoch: 004 | loss: 0.51807 - acc: 0.7799 -- iter: 1309/1309
--
Training Step: 410 | total loss: 0.47475
| Adam | epoch: 005 | loss: 0.47475 - acc: 0.7962 -- iter: 1309/1309
--
Training Step: 574 | total loss: 0.48988
| Adam | epoch: 007 | loss: 0.48988 - acc: 0.7891 -- iter: 1309/1309
--
Training Step: 656 | total loss: 0.55073
| Adam | epoch: 008 | loss: 0.55073 - acc: 0.7427 -- iter: 1309/1309
--
Training Step: 738 | total loss: 0.50242
| Adam | epoch: 009 | loss: 0.50242 - acc: 0.7854 -- iter: 1309/1309
--
Training Step: 820 | total loss: 0.41557
| Adam | epoch: 010 | loss: 0.41557 - acc: 0.8110 -- iter: 1309/1309
--
模型准确率约为 81%,这意味着它可以预测 81% 乘客的正确结果(即乘客是否幸存)。
PrettyTensor
PrettyTensor 允许开发人员包装 TensorFlow 操作,以快速链接任意数量的层来定义神经网络。即将推出的是 PrettyTensor 功能的简单示例:我们将一个标准的 TensorFlow 对象包装成一个与库兼容的对象;然后我们通过三个完全连接的层提供它,我们最终输出 softmax 分布:
pretty = tf.placeholder([None, 784], tf.float32)
softmax = (prettytensor.wrap(examples)
.fully_connected(256, tf.nn.relu)
.fully_connected(128, tf.sigmoid)
.fully_connected(64, tf.tanh)
.softmax(10))
PrettyTensor 安装非常简单。您只需使用pip安装程序:
sudo pip install prettytensor
链接层
PrettyTensor 具有三种操作模式,共享链式方法的能力。
正常模式
在正常模式下,每调用一次,就会创建一个新的 PrettyTensor。这样可以轻松链接,您仍然可以多次使用任何特定对象。这样可以轻松分支网络。
顺序模式
在顺序模式下, 内部变量 - 头部 - 跟踪最近的输出张量,从而允许将调用链分解为多个语句。
这是一个简单的例子:
seq = pretty_tensor.wrap(input_data).sequential()
seq.flatten()
seq.fully_connected(200, activation_fn=tf.nn.relu)
seq.fully_connected(10, activation_fn=None)
result = seq.softmax(labels, name=softmax_name))
分支和连接
可以使用一流branch和join方法构建复杂网络:
branch创建一个单独的 PrettyTensor 对象,该对象在调用时指向当前头部,这允许用户定义一个单独的塔,该塔以回归目标结束,以输出结束或重新连接网络。重新连接允许用户定义复合层,如初始。join用于连接多个输入或重新连接复合层。
数字分类器
在这个例子中,我们将定义和训练一个两层模型和一个 LeNet 5 风格的卷积模型:
import tensorflow as tf
import prettytensor as pt
from prettytensor.tutorial import data_utils
tf.app.flags.DEFINE_string('save_path',\
None, \
'Where to save the model checkpoints.')
FLAGS = tf.app.flags.FLAGS
BATCH_SIZE = 50
EPOCH_SIZE = 60000
TEST_SIZE = 10000
由于我们将数据作为 NumPy 数组提供,因此我们需要在图中创建占位符。这些然后必须使用进料dict语句馈送:
image_placeholder = tf.placeholder\
(tf.float32, [BATCH_SIZE, 28, 28, 1])
labels_placeholder = tf.placeholder\
(tf.float32, [BATCH_SIZE, 10])
接下来,我们创建multilayer_fully_connected函数。前两层是完全连接的(100神经元),最后一层是softmax结果层。如您所见,链接层是一个非常简单的操作:
def multilayer_fully_connected(images, labels):
images = pt.wrap(images)
with pt.defaults_scope\
(activation_fn=tf.nn.relu,l2loss=0.00001):
return (images.flatten().\
fully_connected(100).\
fully_connected(100).\
softmax_classifier(10, labels))
现在我们将构建一个多层卷积网络:该架构类似于 LeNet5。请更改此设置,以便您可以尝试其他架构:
def lenet5(images, labels):
images = pt.wrap(images)
with pt.defaults_scope\
(activation_fn=tf.nn.relu, l2loss=0.00001):
return (images.conv2d(5, 20).\
max_pool(2, 2).\
conv2d(5, 50).\
max_pool(2, 2).\
flatten().\
fully_connected(500).\
softmax_classifier(10, labels))
根据所选模型,我们可能有一个 2 层分类器(multilayer_fully_connected)或卷积分类器(lenet5):
def make_choice():
var = int(input('(1) = multy layer model (2) = LeNet5 '))
print(var)
if var == 1:
result = multilayer_fully_connected\
(image_placeholder,labels_placeholder)
run_model(result)
elif var == 2:
result = lenet5\
(image_placeholder,labels_placeholder)
run_model(result)
else:
print ('incorrect input value')
最后,我们将为所选模型定义accuracy:
def run_model(result):
accuracy = result.softmax.evaluate_classifier\
(labels_placeholder,phase=pt.Phase.test)
接下来,我们构建训练和测试集:
train_images, train_labels = data_utils.mnist(training=True)
test_images, test_labels = data_utils.mnist(training=False)
我们将使用梯度下降优化程序并将其应用于图。pt.apply_optimizer函数增加了正则化损失并设置了一个步进计数器:
optimizer = tf.train.GradientDescentOptimizer(0.01)
train_op = pt.apply_optimizer\
(optimizer,losses=[result.loss])
我们可以在正在运行的会话中设置save_path,以便每隔一段时间自动保存进度。否则,模型将在会话结束时丢失:
runner = pt.train.Runner(save_path=FLAGS.save_path)
with tf.Session():
for epoch in range(0,10)
随机展示训练数据:
train_images, train_labels = \
data_utils.permute_data\
((train_images, train_labels))
runner.train_model(train_op,result.\
loss,EPOCH_SIZE,\
feed_vars=(image_placeholder,\
labels_placeholder),\
feed_data=pt.train.\
feed_numpy(BATCH_SIZE,\
train_images,\
train_labels),\
print_every=100)
classification_accuracy = runner.evaluate_model\
(accuracy,\
TEST_SIZE,\
feed_vars=(image_placeholder,\
labels_placeholder),\
feed_data=pt.train.\
feed_numpy(BATCH_SIZE,\
test_images,\
test_labels))
print("epoch" , epoch + 1)
print("accuracy", classification_accuracy )
if __name__ == '__main__':
make_choice()
运行示例,我们必须选择要训练的模型:
(1) = multylayer model (2) = LeNet5
通过选择multylayer model,我们应该具有 95.5% 的准确率:
Extracting /tmp/data\train-images-idx3-ubyte.gz
Extracting /tmp/data\train-labels-idx1-ubyte.gz
Extracting /tmp/data\t10k-images-idx3-ubyte.gz
Extracting /tmp/data\t10k-labels-idx1-ubyte.gz
epoch 1
accuracy [0.8969]
epoch 2
accuracy [0.914]
epoch 3
accuracy [0.9188]
epoch 4
accuracy [0.9306]
epoch 5
accuracy [0.9353]
epoch 6
accuracy [0.9384]
epoch 7
accuracy [0.9445]
epoch 8
accuracy [0.9472]
epoch 9
accuracy [0.9531]
epoch 10
accuracy [0.9552]
而对于 Lenet5,我们应该具有 98.8% 的准确率:
Extracting /tmp/data\train-images-idx3-ubyte.gz
Extracting /tmp/data\train-labels-idx1-ubyte.gz
Extracting /tmp/data\t10k-images-idx3-ubyte.gz
Extracting /tmp/data\t10k-labels-idx1-ubyte.gz
epoch 1
accuracy [0.9686]
epoch 2
accuracy [0.9755]
epoch 3
accuracy [0.983]
epoch 4
accuracy [0.9841]
epoch 5
accuracy [0.9844]
epoch 6
accuracy [0.9863]
epoch 7
accuracy [0.9862]
epoch 8
accuracy [0.9877]
epoch 9
accuracy [0.9855]
epoch 10
accuracy [0.9886]
Keras
Keras 是一个用 Python 编写的开源神经网络库。它专注于最小化,模块化和可扩展性,旨在实现 DNN 的快速实验。
该库的主要作者和维护者是名为 FrançoisChollet 的 Google 工程师,该库是项目 ONEIROS(开放式神经电子智能机器人操作系统)研究工作的一部分。
Keras 是按照以下设计原则开发的:
- 模块化:模型被理解为独立,完全可配置的模块序列或图,可以通过尽可能少的限制插入到一起。神经层,成本函数,优化器,初始化方案和激活函数都是独立的模块,可以组合起来创建新模型。
- 极简主义:每个模块必须简短(几行代码)并且简单。在肮脏的读取之上,源代码应该是透明的。
- 可扩展性:新模块易于添加(如新类和函数),现有模块提供了基于新模块的示例。能够轻松创建新模块可以实现完全表现力,使 Keras 适合高级研究。
Keras 既可以作为 TensorFlow API 在嵌入式版本中使用,也可以作为库使用:
-
tf.keras来自此链接 -
Keras v2.1.4(更新和安装指南请参见此链接)
在以下部分中,我们将了解如何使用第一个和第二个实现。
Keras 编程模型
Keras 的核心数据结构是一个模型,它是一种组织层的方法。有两种类型的模型:
- 顺序:这只是用于实现简单模型的线性层叠
- 函数式 API:用于更复杂的架构,例如具有多个输出和有向无环图的模型
顺序模型
在本节中,我们将快速通过向您展示代码来解释顺序模型的工作原理。让我们首先使用 TensorFlow API 导入和构建 Keras Sequential模型:
import tensorflow as tf
from tensorflow.python.keras.models import Sequential
model = Sequential()
一旦我们定义了模型,我们就可以添加一个或多个层。堆叠操作由add()语句提供:
from keras.layers import Dense, Activation
例如,让我们添加第一个完全连接的神经网络层和激活函数:
model.add(Dense(output_dim=64, input_dim=100))
model.add(Activation("relu"))
然后我们添加第二个softmax层:
model.add(Dense(output_dim=10))
model.add(Activation("softmax"))
如果模型看起来很好,我们必须compile()模型,指定损失函数和要使用的优化器:
model.compile(loss='categorical_crossentropy',\
optimizer='sgd',\
metrics=['accuracy'])
我们现在可以配置我们的优化器。 Keras 尝试使编程变得相当简单,允许用户在需要时完全控制。
编译完成后,模型必须符合以下数据:
model.fit(X_train, Y_train, nb_epoch=5, batch_size=32)
或者,我们可以手动将批次提供给我们的模型:
model.train_on_batch(X_batch, Y_batch)
一旦训练完成,我们就可以使用我们的模型对新数据进行预测:
classes = model.predict_classes(X_test, batch_size=32)
proba = model.predict_proba(X_test, batch_size=32)
电影评论的情感分类
在这个例子中,我们将 Keras 序列模型应用于情感分析问题。情感分析是破译书面或口头文本中包含的观点的行为。这种技术的主要目的是识别词汇表达的情感(或极性),这可能具有中性,正面或负面的含义。我们想要解决的问题是 IMDB 电影评论情感分类问题:每个电影评论是一个可变的单词序列,每个电影评论的情感(正面或负面)必须分类。
问题非常复杂,因为序列的长度可能不同,并且包含大量的输入符号词汇。该解决方案要求模型学习输入序列中符号之间的长期依赖关系。
IMDB 数据集包含 25,000 个极地电影评论(好的或坏的)用于训练,并且相同的数量再次用于测试。这些数据由斯坦福大学的研究人员收集,并用于 2011 年的一篇论文中,其中五五开的数据被用于训练和测试。在本文中,实现了 88.89% 的准确率。
一旦我们定义了问题,我们就可以开发一个顺序 LSTM 模型来对电影评论的情感进行分类。我们可以快速开发用于 IMDB 问题的 LSTM 并获得良好的准确率。让我们首先导入此模型所需的类和函数,并将随机数生成器初始化为常量值,以确保我们可以轻松地重现结果。
在此示例中,我们在 TensorFlow API 中使用嵌入式 Keras:
import numpy
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.datasets import imdb
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import LSTM
from tensorflow.python.keras.layers import Embedding
from tensorflow.python.keras.preprocessing import sequence
numpy.random.seed(7)
我们加载 IMDB 数据集。我们将数据集限制为前 5,000 个单词。我们还将数据集分为训练(50%)和测试(50%)集。
Keras 提供对 IMDB 数据集的内置访问。imdb.load_data()函数允许您以准备好在神经网络和 DL 模型中使用的格式加载数据集。单词已被整数替换,这些整数表示数据集中每个单词的有序频率。因此,每个评论中的句子包括一系列整数。
这是代码:
top_words = 5000
(X_train, y_train), (X_test, y_test) = \
imdb.load_data(num_words=top_words)
接下来,我们需要截断并填充输入序列,以便它们具有相同的建模长度。该模型将学习不携带信息的零值,因此序列在内容方面的长度不同,但是向量需要在 Keras 中计算相同的长度。每个评论中的序列长度各不相同,因此我们将每个评论限制为500单词,截断长评论并用零值填充较短评论:
让我们来看看:
max_review_length = 500
X_train = sequence.pad_sequences\
(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences\
(X_test, maxlen=max_review_length)
我们现在可以定义,编译和调整我们的 LSTM 模型。
要解决情感分类问题,我们将使用单词嵌入技术。它包括在连续向量空间中表示单词,该向量空间是语义相似的单词被映射到相邻点的区域。单词嵌入基于分布式假设,该假设指出出现在给定上下文中的单词必须具有相同的语义含义。然后将每个电影评论映射到真实的向量域,其中在意义方面的单词之间的相似性转换为向量空间中的接近度。 Keras 提供了一种通过使用嵌入层将单词的正整数表示转换为单词嵌入的便捷方式。
在这里,我们定义嵌入向量和模型的长度:
embedding_vector_length = 32
model = Sequential()
第一层是嵌入层。它使用 32 个长度向量来表示每个单词:
model.add(Embedding(top_words, \
embedding_vector_length,\
input_length=max_review_length))
下一层是具有100存储单元的 LSTM 层。最后,因为这是一个分类问题,我们使用具有单个神经元的密集输出层和sigmoid激活函数来预测问题中的类(好的和坏的):
model.add(LSTM(100))
model.add(Dense(1, activation='sigmoid'))
因为它是二元分类问题,我们使用binary_crossentropy作为损失函数,而这里使用的优化器是adam优化算法(我们在之前的 TensorFlow 实现中遇到过它):
model.compile(loss='binary_crossentropy',\
optimizer='adam',\
metrics=['accuracy'])
print(model.summary())
我们只适合三个周期,因为模型很快就会适应。批量大小为 64 的评论用于分隔权重更新:
model.fit(X_train, y_train, \
validation_data=(X_test, y_test),\
num_epochs=3, \
batch_size=64)
然后,我们估计模型在看不见的评论中的表现:
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
运行此示例将生成以下输出:
Epoch 1/3
16750/16750 [==============================] - 107s - loss: 0.5570 - acc: 0.7149
Epoch 2/3
16750/16750 [==============================] - 107s - loss: 0.3530 - acc: 0.8577
Epoch 3/3
16750/16750 [==============================] - 107s - loss: 0.2559 - acc: 0.9019
Accuracy: 86.79%
您可以看到,这个简单的 LSTM 几乎没有调整,可以在 IMDB 问题上获得最接近最先进的结果。重要的是,这是一个模板,您可以使用该模板将 LSTM 网络应用于您自己的序列分类问题。
函数式 API
为了构建复杂的网络,我们将在这里描述的函数式方法非常有用。如第 4 章,卷积神经网络上的 TensorFlow 所示,最流行的神经网络(AlexNET,VGG 等)由一个或多个重复多次的神经迷你网络组成。函数式 API 包括将神经网络视为我们可以多次调用的函数。这种方法在计算上是有利的,因为为了构建神经网络,即使是复杂的神经网络,也只需要几行代码。
在以下示例中,我们使用来自此链接的 Keras v2.1.4 。
让我们看看它是如何工作的。首先,您需要导入Model模块:
from keras.models import Model
首先要做的是指定模型的输入。让我们使用Input()函数声明一个28×28×1的张量:
from keras.layers import Input
digit_input = Input(shape=(28, 28,1))
这是顺序模型和函数式 API 之间的显着差异之一。因此,使用Conv2D和MaxPooling2D API,我们构建卷积层:
x = Conv2D(64, (3, 3))(digit_input)
x = Conv2D(64, (3, 3))(x)
x = MaxPooling2D((2, 2))(x)
out = Flatten()(x)
请注意,变量x指定应用层的变量。最后,我们通过指定输入和输出来定义模型:
vision_model = Model(digit_input, out)
当然,我们还需要使用fit和compile方法指定损失,优化器等,就像我们对顺序模型一样。
SqueezeNet
在这个例子中,我们引入了一个名为 SqueezeNet 的小型 CNN 架构,它在 ImageNet 上实现了 AlexNet 级精度,参数减少了 50 倍。这个架构的灵感来自 GoogleNet 的初始模块,发表在论文中:SqueezeNet:AlexNet 级准确率,参数减少 50 倍,模型小于 1MB,可从此链接下载。
SqueezeNet 背后的想法是减少使用压缩方案处理的参数数量。此策略使用较少的过滤器减少参数数量。这是通过将挤压层送入它们所称的扩展层来完成的。这两层组成了所谓的 Fire Module,如下图所示:
图 2:SqueezeNet 消防模块
fire_module由1×1卷积滤波器组成,然后是 ReLU 操作:
x = Convolution2D(squeeze,(1,1),padding='valid', name='fire2/squeeze1x1')(x)
x = Activation('relu', name='fire2/relu_squeeze1x1')(x)
expand部分有两部分:left和right。
left部分使用1×1卷积,称为扩展1×1:
left = Conv2D(expand, (1, 1), padding='valid', name=s_id + exp1x1)(x)
left = Activation('relu', name=s_id + relu + exp1x1)(left)
right部分使用3×3卷积,称为expand3x3。这两个部分后面都是 ReLU 层:
right = Conv2D(expand, (3, 3), padding='same', name=s_id + exp3x3)(x)
right = Activation('relu', name=s_id + relu + exp3x3)(right)
消防模块的最终输出是左右连接:
x = concatenate([left, right], axis=channel_axis, name=s_id + 'concat')
然后,重复使用fire_module构建完整的网络,如下所示:
x = Convolution2D(64,(3,3),strides=(2,2), padding='valid',\
name='conv1')(img_input)
x = Activation('relu', name='relu_conv1')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool1')(x)
x = fire_module(x, fire_id=2, squeeze=16, expand=64)
x = fire_module(x, fire_id=3, squeeze=16, expand=64)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool3')(x)
x = fire_module(x, fire_id=4, squeeze=32, expand=128)
x = fire_module(x, fire_id=5, squeeze=32, expand=128)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool5')(x)
x = fire_module(x, fire_id=6, squeeze=48, expand=192)
x = fire_module(x, fire_id=7, squeeze=48, expand=192)
x = fire_module(x, fire_id=8, squeeze=64, expand=256)
x = fire_module(x, fire_id=9, squeeze=64, expand=256)
x = Dropout(0.5, name='drop9')(x)
x = Convolution2D(classes, (1, 1), padding='valid', name='conv10')(x)
x = Activation('relu', name='relu_conv10')(x)
x = GlobalAveragePooling2D()(x)
x = Activation('softmax', name='loss')(x)
model = Model(inputs, x, name='squeezenet')
下图显示了 SqueezeNet 架构:

图 3:SqueezeNet 架构
您可以从下面的链接执行 Keras 的 SqueezeNet(在squeezenet.py文件):
然后我们在以下squeeze_test.jpg(227×227)图像上测试模型:

图 4:SqueezeNet 测试图像
我们只需使用以下几行代码即可:
import os
import numpy as np
import squeezenet as sq
from keras.applications.imagenet_utils import preprocess_input
from keras.applications.imagenet_utils import preprocess_input, decode_predictions
from keras.preprocessing import image
model = sq.SqueezeNet()
img = image.load_img('squeeze_test.jpg', target_size=(227, 227))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
print('Predicted:', decode_predictions(preds))
如您所见,结果非常有趣:
Predicted: [[('n02504013', 'Indian_elephant', 0.64139527), ('n02504458', 'African_elephant', 0.22846894), ('n01871265', 'tusker', 0.12922771), ('n02397096', 'warthog', 0.00037213496), ('n02408429', 'water_buffalo', 0.00032306617)]]
总结
在本章中,我们研究了一些基于 TensorFlow 的 DL 研究和开发库。我们引入了tf.estimator,它是 DL/ML 的简化接口,现在是 TensorFlow 和高级 ML API 的一部分,可以轻松训练,配置和评估各种 ML 模型。我们使用估计器函数为鸢尾花数据集实现分类器。
我们还看了一下 TFLearn 库,它包含了很多 TensorFlow API。在这个例子中,我们使用 TFLearn 来估计泰坦尼克号上乘客的生存机会。为了解决这个问题,我们构建了一个 DNN 分类器。
然后,我们介绍了 PrettyTensor,它允许 TensorFlow 操作被包装以链接任意数量的层。我们以 LeNet 的风格实现了卷积模型,以快速解决手写分类模型。
然后我们快速浏览了 Keras,它设计用于极简主义和模块化,允许用户快速定义 DL 模型。使用 Keras,我们学习了如何为 IMDB 电影评论情感分类问题开发一个简单的单层 LSTM 模型。在最后一个例子中,我们使用 Keras 的函数从预训练的初始模型开始构建 SqueezeNet 神经网络。
下一章将介绍强化学习。我们将探讨强化学习的基本原理和算法。我们还将看到一些使用 TensorFlow 和 OpenAI Gym 框架的示例,这是一个用于开发和比较强化学习算法的强大工具包。
九、协同过滤和电影推荐
在这一部分,我们将看到如何利用协同过滤来开发推荐引擎。然而,在此之前让我们讨论偏好的效用矩阵。
效用矩阵
在基于协同过滤的推荐系统中,存在实体的维度:用户和项目(项目指的是诸如电影,游戏和歌曲的产品)。作为用户,您可能对某些项目有首选项。因此,必须从有关项目,用户或评级的数据中提取这些首选项。该数据通常表示为效用矩阵,例如用户 - 项目对。这种类型的值可以表示关于用户对特定项目的偏好程度的已知信息。
矩阵中的条目可以来自有序集。例如,整数 1-5 可用于表示用户在评价项目时给出的星数。我们已经提到用户可能不会经常评价项目,因此大多数条目都是未知的。因此,将 0 分配给未知项将失败,这也意味着矩阵可能是稀疏的。未知评级意味着我们没有关于用户对项目的偏好的明确信息。
表 1 显示示例效用矩阵。矩阵表示用户以 1-5 分为单位给予电影的评级,其中 5 为最高评级。空白条目表示特定用户未为该特定电影提供任何评级的事实。 HP1,HP2 和 HP3 是 Harry Potter I,II 和 III 的首字母缩略词,TW 代表 Twilight,SW1,SW2 和 SW3 代表星球大战的第 1,2 和 3 集。字母 A,B,C 和 D 代表用户:

表 1:效用矩阵(用户与电影矩阵)
用户电影对有许多空白条目。这意味着用户尚未对这些电影进行评级。在现实生活中,矩阵可能更稀疏,典型的用户评级只是所有可用电影的一小部分。使用此矩阵,目标是预测效用矩阵中的空白。现在,让我们看一个例子。假设我们很想知道用户 A 是否想要 SW2。很难解决这个问题,因为表 1 中的矩阵内没有太多数据可供使用。
因此,在实践中,我们可能会开发一个电影推荐引擎来考虑电影的其他属性,例如制片人,导演,主要演员,甚至是他们名字的相似性。这样,我们可以计算电影 SW1 和 SW2 的相似度。这种相似性会让我们得出结论,因为 A 不喜欢 SW1,所以他们也不太可能喜欢 SW2。
但是,这可能不适用于更大的数据集。因此,有了更多的数据,我们可能会发现,对 SW1 和 SW2 进行评级的人都倾向于给予他们相似的评级。最后,我们可以得出结论,A 也会给 SW2 一个低评级,类似于 A 的 SW1 评级。
在下一节中,我们将看到如何使用协同过滤方法开发电影推荐引擎。我们将看到如何利用这种类型的矩阵。
注意
如何使用代码库:此代码库中有八个 Python 脚本(即使用TensorFlow_09_Codes/CollaborativeFiltering进行深度学习)。首先,执行执行数据集探索性分析的eda.py。然后,调用train.py脚本执行训练。最后,Test.py可用于模型推理和评估。
以下是每个脚本的简要功能:
eda.py:这用于 MovieLens1M 数据集的探索性分析。train.py:它执行训练和验证。然后它打印验证误差。最后,它创建了用户项密集表。Test.py:恢复训练中生成的用户与项目表。然后评估所有模型。run.py:用于模型推理并进行预测。kmean.py:它集中了类似的电影。main.py:它计算前 K 个电影,创建用户评级,找到前 K 个相似项目,计算用户相似度,计算项目相关性并计算用户 Pearson 相关性。readers.py:它读取评级和电影数据并执行一些预处理。最后,它为批量训练准备数据集。model.py:它创建模型并计算训练/验证损失。
工作流程可以描述如下:
- 首先,我们将使用可用的评级来训练模型。
- 然后我们使用训练的模型来预测用户与电影矩阵中的缺失评级。
- 然后,利用所有预测的评级,将构建新用户与电影矩阵并以
.pkl文件的形式保存。 - 然后,我们使用此矩阵来预测特定用户的评级。
- 最后,我们将训练 K 均值模型来聚类相关电影。
数据集的描述
在我们开始实现电影 RE 之前,让我们看一下将要使用的数据集。 MovieLens1M 数据集从 MovieLens 网站下载。
我真诚地感谢 F. Maxwell Harper 和 Joseph A. Konstan 使数据集可供使用。数据集发布在 MovieLens 数据集:历史和上下文中。 ACM 交互式智能系统交易(TiiS)5,4,第 19 条(2015 年 12 月),共 19 页。
数据集中有三个文件,它们与电影,评级和用户有关。这些文件包含 1,000,209 个匿名评级,约有 3,900 部电影,由 2000 年加入 MovieLens 的 6,040 名 MovieLens 用户制作。
评级数据
所有评级都包含在ratings.dat文件中,格式如下 - UserID :: MovieID :: Rating :: Timestamp:
UserID的范围在 1 到 6,040 之间MovieID的范围在 1 到 3,952 之间Rating为五星级Timestamp以秒表示
请注意,每位用户至少评了 20 部电影。
电影数据
电影信息是movies.dat文件中的 ,格式如下 - MovieID :: Title :: Genres:
- 标题与 IMDb 提供的标题相同(发布年份)
- 流派是分开的,每部电影分为动作,冒险,动画,儿童,喜剧,犯罪,戏剧,战争,纪录片,幻想,电影黑色,恐怖,音乐,神秘,浪漫,科幻菲律宾,惊悚片和西部片
用户数据
用户信息位于users.dat文件中,格式如下:UserID :: Gender :: Age :: Occupation :: Zip-code。
所有人口统计信息均由用户自愿提供,不会检查其准确率。此数据集中仅包含已提供某些人口统计信息的用户。男性 M 和女性 F 表示性别。
年龄选自以下范围:
- 1:18 岁以下
- 18:18-24
- 25:25-34
- 35:35-44
- 45:45-49
- 50:50-55
- 56:56+
职业选自以下选项:
0:其他,或未指定
1:学术/教育者
2:艺术家
3:文员/管理员
4:大学/研究生
5:客户服务
6:医生/保健
7:执行/管理
8:农民
9:主妇
10:K-12 学生
11:律师
12:程序员
13:退休了
14:销售/营销
15:科学家
16:自雇人士
17:技师/工程师
18:匠人/工匠
19:失业
20:作家
对 MovieLens 数据集的探索性分析
在这里,在我们开始开发 RE 之前,我们将看到数据集的探索性描述。我假设读者已经从此链接下载了 MovieLens1m 数据集并将其解压缩到此代码库中的输入目录。现在,为此,在终端上执行$ python3 eda.py命令:
-
首先,让我们导入所需的库和包:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np -
现在让我们加载用户,评级和电影数据集并创建一个 pandas
DataFrame:ratings_list = [i.strip().split("::") for i in open('Input/ratings.dat', 'r').readlines()] users_list = [i.strip().split("::") for i in open('Input/users.dat', 'r').readlines()] movies_list = [i.strip().split("::") for i in open('Input/movies.dat', 'r',encoding='latin-1').readlines()] ratings_df = pd.DataFrame(ratings_list, columns = ['UserID', 'MovieID', 'Rating', 'Timestamp'], dtype = int) movies_df = pd.DataFrame(movies_list, columns = ['MovieID', 'Title', 'Genres']) user_df=pd.DataFrame(users_list, columns=['UserID','Gender','Age','Occupation','ZipCode']) -
接下来的任务是使用内置的
to_numeric()pandas 函数将分类列(如MovieID,UserID和Age)转换为数值:movies_df['MovieID'] = movies_df['MovieID'].apply(pd.to_numeric) user_df['UserID'] = user_df['UserID'].apply(pd.to_numeric) user_df['Age'] = user_df['Age'].apply(pd.to_numeric) -
让我们看一下用户表中的一些例子:
print("User table description:") print(user_df.head()) print(user_df.describe()) >>> User table description: UserID Gender Age Occupation ZipCode 1 F 1 10 48067 2 M 56 16 70072 3 M 25 15 55117 4 M 45 7 02460 5 M 25 20 55455 UserID Age count 6040.000000 6040.000000 mean 3020.500000 30.639238 std 1743.742145 12.895962 min 1.000000 1.000000 25% 1510.750000 25.000000 50% 3020.500000 25.000000 75% 4530.250000 35.000000 max 6040.000000 56.000000 -
让我们看一下来自评级数据集的一些信息:
print("Rating table description:") print(ratings_df.head()) print(ratings_df.describe()) >>> Rating table description: UserID MovieID Rating Timestamp 1 1193 5 978300760 1 661 3 978302109 1 914 3 978301968 1 3408 4 978300275 1 2355 5 978824291 UserID MovieID Rating Timestamp count 1.000209e+06 1.000209e+06 1.000209e+06 1.000209e+06 mean 3.024512e+03 1.865540e+03 3.581564e+00 9.722437e+08 std 1.728413e+03 1.096041e+03 1.117102e+00 1.215256e+07 min 1.000000e+00 1.000000e+00 1.000000e+00 9.567039e+08 25% 1.506000e+03 1.030000e+03 3.000000e+00 9.653026e+08 50% 3.070000e+03 1.835000e+03 4.000000e+00 9.730180e+08 75% 4.476000e+03 2.770000e+03 4.000000e+00 9.752209e+08 max 6.040000e+03 3.952000e+03 5.000000e+00 1.046455e+09 -
让我们看看电影数据集中的一些信息:
>>> print("Movies table description:") print(movies_df.head()) print(movies_df.describe()) >>> Movies table description: MovieID Title Genres 0 1 Toy Story (1995) Animation|Children's|Comedy 1 2 Jumanji (1995) Adventure|Children's|Fantasy 2 3 Grumpier Old Men (1995) Comedy|Romance 3 4 Waiting to Exhale (1995) Comedy|Drama 4 5 Father of the Bride Part II (1995) Comedy MovieID count 3883.000000 mean 1986.049446 std 1146.778349 min 1.000000 25% 982.500000 50% 2010.000000 75% 2980.500000 max 3952.000000 -
现在让我们看看评级最高的五部电影:
print("Top ten most rated movies:") print(ratings_df['MovieID'].value_counts().head()) >>> Top 10 most rated movies with title and rating count: American Beauty (1999) 3428 Star Wars: Episode IV - A New Hope (1977) 2991 Star Wars: Episode V - The Empire Strikes Back (1980) 2990 Star Wars: Episode VI - Return of the Jedi (1983) 2883 Jurassic Park (1993) 2672 Saving Private Ryan (1998) 2653 Terminator 2: Judgment Day (1991) 2649 Matrix, The (1999) 2590 Back to the Future (1985) 2583 Silence of the Lambs, The (1991) 2578 -
现在,让我们看一下电影评级分布。 为此,让我们使用直方图,该图演示了一个重要的模式,票数呈正态分布:
plt.hist(ratings_df.groupby(['MovieID'])['Rating'].mean().sort_values(axis=0, ascending=False)) plt.title("Movie rating Distribution") plt.ylabel('Count of movies') plt.xlabel('Rating'); plt.show() >>>
图 3:电影评级分布
-
让我们看看评级如何分布在不同年龄段:
user_df.Age.plot.hist() plt.title("Distribution of users (by ages)") plt.ylabel('Count of users') plt.xlabel('Age'); plt.show() >>>
图 4:按年龄分布的用户
-
现在让我们看看收视率最高的电影,评级至少为 150:
```py
movie_stats = df.groupby('Title').agg({'Rating': [np.size, np.mean]})
print("Highest rated movie with minimum 150 ratings")
print(movie_stats.Rating[movie_stats.Rating['size'] > 150].sort_values(['mean'],ascending=[0]).head())
>>>
Top 5 and a highest rated movie with a minimum of 150 ratings-----------------------------------------------------------
Title size mean
Seven Samurai (The Magnificent Seven) 628 4.560510
Shawshank Redemption, The (1994) 2227 4.554558
Godfather, The (1972) 2223 4.524966
Close Shave, A (1995) 657 4.520548
Usual Suspects, The (1995) 1783 4.517106
```
- 让我们看看在电影评级中的性别偏置,即电影评级如何按评论者的性别进行比较:
```py
>>>
pivoted = df.pivot_table(index=['MovieID', 'Title'], columns=['Gender'], values='Rating', fill_value=0)
print("Gender biasing towards movie rating")
print(pivoted.head())
```
- 我们现在可以看看电影收视率的性别偏置及它们之间的差异,即男性和女性对电影的评价方式不同:
```py
pivoted['diff'] = pivoted.M - pivoted.F
print(pivoted.head())
>>>
Gender F M diff
MovieID Title
1 Toy Story (1995) 4.87817 4.130552 -0.057265
2 Jumanji (1995) 3.278409 3.175238 -0.103171
3 Grumpier Old Men (1995) 3.073529 2.994152 -0.079377
4 Waiting to Exhale (1995) 2.976471 2.482353 -0.494118
5 Father of the Bride Part II (1995) 3.212963 2.888298 -0.324665
```
- 从前面的输出中可以清楚地看出,在大多数情况下,男性的收视率高于女性。现在我们已经看到了有关数据集的一些信息和统计数据,现在是构建我们的 TensorFlow 推荐模型的时候了。
实现电影 RE
在这个例子中,我们将看到如何推荐前 K 部电影(其中 K 是电影数量),预测用户评级并推荐前 K 个类似项目(其中 K 是项目数)。然后我们将看到如何计算用户相似度。
然后我们将使用 Pearson 的相关算法看到项目项相关性和用户 - 用户相关性。最后,我们将看到如何使用 K 均值算法对类似的电影进行聚类。
换句话说,我们将使用协同过滤方法制作电影推荐引擎,并使用 K 均值来聚类类似的电影。
距离计算:还有其他计算距离的方法。例如:
- 通过仅考虑最显着的尺寸,可以使用切比雪夫距离来测量距离。
- 汉明距离算法可以识别两个字符串之间的差异。
- 马哈拉诺比斯距离可用于归一化协方差矩阵。
- 曼哈顿距离用于通过仅考虑轴对齐方向来测量距离。
- Haversine 距离用于测量球体上两个点之间的大圆距离。
考虑到这些距离测量算法,很明显欧几里德距离算法最适合解决 K 均值算法中距离计算的目的。
总之,以下是用于开发此模型的工作流程:
- 首先,使用可用的评级来训练模型。
- 使用该训练模型来预测用户与电影矩阵中的缺失评级。
- 利用所有预测的评级,用户与电影矩阵成为受训用户与电影矩阵,我们以
.pkl文件的形式保存。 - 然后,我们使用用户与电影矩阵,或训练用户与电影矩阵的训练参数,进行进一步处理。
在训练模型之前,第一项工作是利用所有可用的数据集来准备训练集。
使用可用的评级训练模型
对于这一部分,请使用train.py脚本,该脚本依赖于其他脚本。我们将看到依赖项:
-
首先,让我们导入必要的包和模块:
from collections import deque from six import next import readers import os import tensorflow as tf import numpy as np import model as md import pandas as pd import time import matplotlib.pyplot as plt -
然后我们设置随机种子的复现性:
np.random.seed(12345) -
下一个任务是定义训练参数。让我们定义所需的数据参数,例如评级数据集的位置,批量大小,SVD 的维度,最大周期和检查点目录:
data_file ="Input/ratings.dat"# Input user-movie-rating information file batch_size = 100 #Batch Size (default: 100) dims =15 #Dimensions of SVD (default: 15) max_epochs = 50 # Maximum epoch (default: 25) checkpoint_dir ="save/" #Checkpoint directory from training run val = True #True if Folders with files and False if single file is_gpu = True # Want to train model with GPU -
我们还需要一些其他参数,例如允许软放置和日志设备放置:
allow_soft_placement = True #Allow device soft device placement log_device_placement=False #Log placement of ops on devices -
我们不想用旧的元数据或检查点和模型文件污染我们的新训练 ,所以如果有的话,让我们删除它们:
print("Start removing previous Files ...") if os.path.isfile("model/user_item_table.pkl"): os.remove("model/user_item_table.pkl") if os.path.isfile("model/user_item_table_train.pkl"): os.remove("model/user_item_table_train.pkl") if os.path.isfile("model/item_item_corr.pkl"): os.remove("model/item_item_corr.pkl") if os.path.isfile("model/item_item_corr_train.pkl"): os.remove("model/item_item_corr_train.pkl") if os.path.isfile("model/user_user_corr.pkl"): os.remove("model/user_user_corr.pkl") if os.path.isfile("model/user_user_corr_train.pkl"): os.remove("model/user_user_corr_train.pkl") if os.path.isfile("model/clusters.csv"): os.remove("model/clusters.csv") if os.path.isfile("model/val_error.pkl"): os.remove("model/val_error.pkl") print("Done ...") >>> Start removing previous Files... Done... -
然后让我们定义检查点目录。 TensorFlow 假设此目录已存在,因此我们需要创建它:
checkpoint_prefix = os.path.join(checkpoint_dir, "model") if not os.path.exists(checkpoint_dir): os.makedirs(checkpoint_dir) -
在进入数据之前,让我们设置每批的样本数量,数据的维度以及网络看到所有训练数据的次数 :
batch_size =batch_size dims =dims max_epochs =max_epochs -
现在让我们指定用于所有 TensorFlow 计算,CPU 或 GPU 的设备:
if is_gpu: place_device = "/gpu:0" else: place_device="/cpu:0" -
现在我们通过
get_data()函数读取带有分隔符::的评级文件。示例列包含用户 ID,项 ID,评级和时间戳,例如3 :: 1196 :: 4 :: 978297539。然后,上面的代码执行纯粹基于整数位置的索引,以便按位置进行选择。之后,它将数据分为训练和测试,75% 用于训练,25% 用于测试。最后,它使用索引来分离数据并返回用于训练的数据帧:def get_data(): print("Inside get data ...") df = readers.read_file(data_file, sep="::") rows = len(df) df = df.iloc[np.random.permutation(rows)].reset_index(drop=True) split_index = int(rows * 0.75) df_train = df[0:split_index] df_test = df[split_index:].reset_index(drop=True) print("Done !!!") print(df.shape) return df_train, df_test,df['user'].max(),df['item'].max() -
然后,我们在数组中剪切值的限制:给定一个间隔,将间隔外的值剪切到间隔的边缘。例如,如果指定
[0,1]间隔,则小于 0 的值变为 0,大于 1 的值变为 1:
```py
def clip(x):
return np.clip(x, 1.0, 5.0)
```
然后,我们调用read_data()方法从评级文件中读取数据以构建 TensorFlow 模型:
df_train, df_test,u_num,i_num = get_data()
>>>
Inside get data...
Done!!!
-
然后,我们定义数据集中评级电影的用户数量,以及数据集中的电影数量:
u_num = 6040 # Number of users in the dataset i_num = 3952 # Number of movies in the dataset -
现在让我们生成每批样本数量:
samples_per_batch = len(df_train) // batch_size print("Number of train samples %d, test samples %d, samples per batch %d" % (len(df_train), len(df_test), samples_per_batch)) >>> Number of train samples 750156, test samples 250053, samples per batch 7501 -
现在,使用
ShuffleIterator,我们生成随机批次。在训练中,这有助于防止偏差结果以及过拟合:iter_train = readers.ShuffleIterator([df_train["user"], df_train["item"],df_train["rate"]], batch_size=batch_size) -
有关此类的更多信息,请参阅
readers.py脚本。为方便起见,以下是此类的来源:class ShuffleIterator(object): def __init__(self, inputs, batch_size=10): self.inputs = inputs self.batch_size = batch_size self.num_cols = len(self.inputs) self.len = len(self.inputs[0]) self.inputs = np.transpose(np.vstack([np.array(self.inputs[i]) for i in range(self.num_cols)])) def __len__(self): return self.len def __iter__(self): return self def __next__(self): return self.next() def next(self): ids = np.random.randint(0, self.len, (self.batch_size,)) out = self.inputs[ids, :] return [out[:, i] for i in range(self.num_cols)] -
然后我们依次生成一个周期的批次进行测试(参见
train.py):iter_test = readers.OneEpochIterator([df_test["user"], df_test["item"], df_test["rate"]], batch_size=-1) -
有关此类的更多信息,请参阅
readers.py脚本。为了方便,这里是这个类的源码:class OneEpochIterator(ShuffleIterator): def __init__(self, inputs, batch_size=10): super(OneEpochIterator, self).__init__(inputs, batch_size=batch_size) if batch_size > 0: self.idx_group = np.array_split(np.arange(self.len), np.ceil(self.len / batch_size)) else: self.idx_group = [np.arange(self.len)] self.group_id = 0 def next(self): if self.group_id >= len(self.idx_group): self.group_id = 0 raise StopIteration out = self.inputs[self.idx_group[self.group_id], :] self.group_id += 1 return [out[:, i] for i in range(self.num_cols)] -
现在是创建 TensorFlow 占位符的时间:
user_batch = tf.placeholder(tf.int32, shape=[None], name="id_user") item_batch = tf.placeholder(tf.int32, shape=[None], name="id_item") rate_batch = tf.placeholder(tf.float32, shape=[None]) -
现在我们的训练集和占位符已准备好容纳训练值的批次,现在该实例化模型了。 为此,我们使用
model()方法并使用 l2 正则化来避免过拟合(请参见model.py脚本):infer, regularizer = md.model(user_batch, item_batch, user_num=u_num, item_num=i_num, dim=dims, device=place_device)model()方法如下:def model(user_batch, item_batch, user_num, item_num, dim=5, device="/cpu:0"): with tf.device("/cpu:0"): # Using a global bias term bias_global = tf.get_variable("bias_global", shape=[]) # User and item bias variables: get_variable: Prefixes the name with the current variable # scope and performs reuse checks. w_bias_user = tf.get_variable("embd_bias_user", shape=[user_num]) w_bias_item = tf.get_variable("embd_bias_item", shape=[item_num]) # embedding_lookup: Looks up 'ids' in a list of embedding tensors # Bias embeddings for user and items, given a batch bias_user = tf.nn.embedding_lookup(w_bias_user, user_batch, name="bias_user") bias_item = tf.nn.embedding_lookup(w_bias_item, item_batch, name="bias_item") # User and item weight variables w_user = tf.get_variable("embd_user", shape=[user_num, dim], initializer=tf.truncated_normal_initializer(stddev=0.02)) w_item = tf.get_variable("embd_item", shape=[item_num, dim], initializer=tf.truncated_normal_initializer(stddev=0.02)) # Weight embeddings for user and items, given a batch embd_user = tf.nn.embedding_lookup(w_user, user_batch, name="embedding_user") embd_item = tf.nn.embedding_lookup(w_item, item_batch, name="embedding_item") # reduce_sum: Computes the sum of elements across dimensions of a tensor infer = tf.reduce_sum(tf.multiply(embd_user, embd_item), 1) infer = tf.add(infer, bias_global) infer = tf.add(infer, bias_user) infer = tf.add(infer, bias_item, name="svd_inference") # l2_loss: Computes half the L2 norm of a tensor without the sqrt regularizer = tf.add(tf.nn.l2_loss(embd_user), tf.nn.l2_loss(embd_item), name="svd_regularizer") return infer, regularizer -
现在让我们定义训练操作(参见
models.py脚本中的更多内容):_, train_op = md.loss(infer, regularizer, rate_batch, learning_rate=0.001, reg=0.05, device=place_device)
loss()方法如下:
def loss(infer, regularizer, rate_batch, learning_rate=0.1, reg=0.1, device="/cpu:0"):
with tf.device(device):
cost_l2 = tf.nn.l2_loss(tf.subtract(infer, rate_batch))
penalty = tf.constant(reg, dtype=tf.float32, shape=[], name="l2")
cost = tf.add(cost_l2, tf.multiply(regularizer, penalty))
train_op = tf.train.FtrlOptimizer(learning_rate).minimize(cost)
return cost, train_op
-
一旦我们实例化了模型和训练操作,我们就可以保存模型以备将来使用:
saver = tf.train.Saver() init_op = tf.global_variables_initializer() session_conf = tf.ConfigProto( allow_soft_placement=allow_soft_placement, log_device_placement=log_device_placement) -
现在我们开始训练模型:
with tf.Session(config = session_conf) as sess: sess.run(init_op) print("%s\t%s\t%s\t%s" % ("Epoch", "Train err", "Validation err", "Elapsed Time")) errors = deque(maxlen=samples_per_batch) train_error=[] val_error=[] start = time.time() for i in range(max_epochs * samples_per_batch): users, items, rates = next(iter_train) _, pred_batch = sess.run([train_op, infer], feed_dict={user_batch: users, item_batch: items, rate_batch: rates}) pred_batch = clip(pred_batch) errors.append(np.power(pred_batch - rates, 2)) if i % samples_per_batch == 0: train_err = np.sqrt(np.mean(errors)) test_err2 = np.array([]) for users, items, rates in iter_test: pred_batch = sess.run(infer, feed_dict={user_batch: users, item_batch: items}) pred_batch = clip(pred_batch) test_err2 = np.append(test_err2, np.power(pred_batch - rates, 2)) end = time.time() print("%02d\t%.3f\t\t%.3f\t\t%.3f secs" % (i // samples_per_batch, train_err, np.sqrt(np.mean(test_err2)), end - start)) train_error.append(train_err) val_error.append(np.sqrt(np.mean(test_err2))) start = end saver.save(sess, checkpoint_prefix) pd.DataFrame({'training error':train_error,'validation error':val_error}).to_pickle("val_error.pkl") print("Training Done !!!") sess.close() -
前面的代码执行训练并将误差保存在 PKL 文件中。最后,它打印了训练和验证误差以及所花费的时间:
>>> Epoch Train err Validation err Elapsed Time 00 2.816 2.812 0.118 secs 01 2.813 2.812 4.898 secs … … … … 48 2.770 2.767 1.618 secs 49 2.765 2.760 1.678 secs
完成训练!!!
结果是删节,只显示了几个步骤。现在让我们以图形方式看到这些误差:
error = pd.read_pickle("val_error.pkl")
error.plot(title="Training vs validation error (per epoch)")
plt.ylabel('Error/loss')
plt.xlabel('Epoch');
plt.show()
>>>
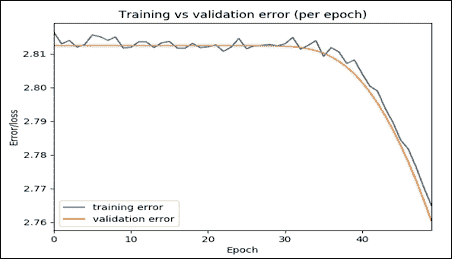
图 5:每个周期的训练与验证误差
该图表明,随着时间的推移,训练和验证误差都会减少,这意味着我们正朝着正确的方向行走。尽管如此,您仍然可以尝试增加步骤,看看这两个值是否可以进一步降低,这意味着更高的准确率。
使用已保存的模型执行推断
以下代码使用保存的模型执行模型推理,并打印整体验证误差:
if val:
print("Validation ...")
init_op = tf.global_variables_initializer()
session_conf = tf.ConfigProto(
allow_soft_placement=allow_soft_placement,
log_device_placement=log_device_placement)
with tf.Session(config = session_conf) as sess:
new_saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_prefix))
new_saver.restore(sess, tf.train.latest_checkpoint(checkpoint_dir))
test_err2 = np.array([])
for users, items, rates in iter_test:
pred_batch = sess.run(infer, feed_dict={user_batch: users, item_batch: items})
pred_batch = clip(pred_batch)
test_err2 = np.append(test_err2, np.power(pred_batch - rates, 2))
print("Validation Error: ",np.sqrt(np.mean(test_err2)))
print("Done !!!")
sess.close()
>>>
Validation Error: 2.14626890224
Done!!!
生成用户项表
以下方法创建用户项数据帧。它用于创建训练有素的DataFrame。使用 SVD 训练模型在此处填写用户项表中的所有缺失值。它采用评级数据帧并存储所有电影的所有用户评级。最后,它会生成一个填充的评级数据帧,其中行是用户,列是项:
def create_df(ratings_df=readers.read_file(data_file, sep="::")):
if os.path.isfile("model/user_item_table.pkl"):
df=pd.read_pickle("user_item_table.pkl")
else:
df = ratings_df.pivot(index = 'user', columns ='item', values = 'rate').fillna(0)
df.to_pickle("user_item_table.pkl")
df=df.T
users=[]
items=[]
start = time.time()
print("Start creating user-item dense table")
total_movies=list(ratings_df.item.unique())
for index in df.columns.tolist():
#rated_movies=ratings_df[ratings_df['user']==index].drop(['st', 'user'], axis=1)
rated_movie=[]
rated_movie=list(ratings_df[ratings_df['user']==index].drop(['st', 'user'], axis=1)['item'].values)
unseen_movies=[]
unseen_movies=list(set(total_movies) - set(rated_movie))
for movie in unseen_movies:
users.append(index)
items.append(movie)
end = time.time()
print(("Found in %.2f seconds" % (end-start)))
del df
rated_list = []
init_op = tf.global_variables_initializer()
session_conf = tf.ConfigProto(
allow_soft_placement=allow_soft_placement,
log_device_placement=log_device_placement)
with tf.Session(config = session_conf) as sess:
#sess.run(init_op)
print("prediction started ...")
new_saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_prefix))
new_saver.restore(sess, tf.train.latest_checkpoint(checkpoint_dir))
test_err2 = np.array([])
rated_list = sess.run(infer, feed_dict={user_batch: users, item_batch: items})
rated_list = clip(rated_list)
print("Done !!!")
sess.close()
df_dict={'user':users,'item':items,'rate':rated_list}
df = ratings_df.drop(['st'],axis=1).append(pd.DataFrame(df_dict)).pivot(index = 'user', columns ='item', values = 'rate').fillna(0)
df.to_pickle("user_item_table_train.pkl")
return df
现在让我们调用前面的方法来生成用户项表作为 pandas 数据帧:
create_df(ratings_df = readers.read_file(data_file, sep="::"))
此行将为训练集创建用户与项目表,并将数据帧保存为指定目录中的user_item_table_train.pkl文件。
聚类类似的电影
对于这一部分,请参阅kmean.py脚本。此脚本将评级数据文件作为输入,并返回电影及其各自的簇。
从技术上讲,本节的目的是找到类似的电影;例如,用户 1 喜欢电影 1,并且因为电影 1 和电影 2 相似,所以用户想要电影 2.让我们开始导入所需的包和模块:
import tensorflow as tf
import numpy as np
import pandas as pd
import time
import readers
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
现在让我们定义要使用的数据参数:评级数据文件的路径,簇的数量,K 和最大迭代次数。此外,我们还定义了是否要使用经过训练的用户与项目矩阵:
data_file = "Input/ratings.dat" #Data source for the positive data
K = 5 # Number of clusters
MAX_ITERS =1000 # Maximum number of iterations
TRAINED = False # Use TRAINED user vs item matrix
然后定义k_mean_clustering ()方法。它返回电影及其各自的群集。它采用评级数据集ratings_df,这是一个评级数据帧。然后它存储各个电影的所有用户评级,K是簇的数量,MAX_ITERS是推荐的最大数量,TRAINED是一种布尔类型,表示是否使用受过训练的用户与电影表或未经训练的人。
提示
如何找到最佳 K 值
在这里,我们朴素地设定 K 的值。但是,为了微调聚类表现,我们可以使用一种称为 Elbow 方法的启发式方法。我们从K = 2开始,然后,我们通过增加 K 来运行 K 均值算法并使用 WCSS 观察成本函数(CF)的值。在某些时候,CF 会大幅下降。然而,随着 K 值的增加,这种改善变得微不足道。总之,我们可以在 WCSS 的最后一次大跌之后选择 K 作为最佳值。
最后,k_mean_clustering()函数返回一个电影/项目列表和一个簇列表:
def k_mean_clustering(ratings_df,K,MAX_ITERS,TRAINED=False):
if TRAINED:
df=pd.read_pickle("user_item_table_train.pkl")
else:
df=pd.read_pickle("user_item_table.pkl")
df = df.T
start = time.time()
N=df.shape[0]
points = tf.Variable(df.as_matrix())
cluster_assignments = tf.Variable(tf.zeros([N], dtype=tf.int64))
centroids = tf.Variable(tf.slice(points.initialized_value(), [0,0], [K,df.shape[1]]))
rep_centroids = tf.reshape(tf.tile(centroids, [N, 1]), [N, K, df.shape[1]])
rep_points = tf.reshape(tf.tile(points, [1, K]), [N, K, df.shape[1]])
sum_squares = tf.reduce_sum(tf.square(rep_points - rep_centroids),reduction_indices=2)
best_centroids = tf.argmin(sum_squares, 1) did_assignments_change = tf.reduce_any(tf.not_equal(best_centroids, cluster_assignments))
means = bucket_mean(points, best_centroids, K)
with tf.control_dependencies([did_assignments_change]):
do_updates = tf.group(
centroids.assign(means),
cluster_assignments.assign(best_centroids))
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
changed = True
iters = 0
while changed and iters < MAX_ITERS:
iters += 1
[changed, _] = sess.run([did_assignments_change, do_updates])
[centers, assignments] = sess.run([centroids, cluster_assignments])
end = time.time()
print (("Found in %.2f seconds" % (end-start)), iters, "iterations")
cluster_df=pd.DataFrame({'movies':df.index.values,'clusters':assignments})
cluster_df.to_csv("clusters.csv",index=True)
return assignments,df.index.values
在前面的代码中,我们有一个愚蠢的初始化,在某种意义上我们使用前 K 个点作为起始质心。在现实世界中,它可以进一步改进。
在前面的代码块中,我们复制每个质心的 N 个副本和每个数据点的 K 个副本。然后我们减去并计算平方距离的总和。然后我们使用argmin选择最低距离点。但是,在计算分配是否已更改之前,我们不会编写已分配的群集变量,因此具有依赖性。
如果仔细查看前面的代码,有一个名为bucket_mean()的函数。它获取数据点,最佳质心和暂定簇的数量 K,并计算在簇计算中使用的平均值:
def bucket_mean(data, bucket_ids, num_buckets):
total = tf.unsorted_segment_sum(data, bucket_ids, num_buckets)
count = tf.unsorted_segment_sum(tf.ones_like(data), bucket_ids, num_buckets)
return total / count
一旦我们训练了我们的 K 均值模型,下一个任务就是可视化代表类似电影的那些簇。为此,我们有一个名为showClusters()的函数,它接受用户项表,CSV 文件(clusters.csv)中写入的聚簇数据,主成分数(默认为 2)和 SVD 求解器(可能的值是随机的和完整的)。
问题是,在 2D 空间中,很难绘制代表电影簇的所有数据点。出于这个原因,我们应用主成分分析(PCA)来降低维数而不会牺牲质量:
user_item=pd.read_pickle(user_item_table)
cluster=pd.read_csv(clustered_data, index_col=False)
user_item=user_item.T
pcs = PCA(number_of_PCA_components, svd_solver)
cluster['x']=pcs.fit_transform(user_item)[:,0]
cluster['y']=pcs.fit_transform(user_item)[:,1]
fig = plt.figure()
ax = plt.subplot(111)
ax.scatter(cluster[cluster['clusters']==0]['x'].values,cluster[cluster['clusters']==0]['y'].values,color="r", label='cluster 0')
ax.scatter(cluster[cluster['clusters']==1]['x'].values,cluster[cluster['clusters']==1]['y'].values,color="g", label='cluster 1')
ax.scatter(cluster[cluster['clusters']==2]['x'].values,cluster[cluster['clusters']==2]['y'].values,color="b", label='cluster 2')
ax.scatter(cluster[cluster['clusters']==3]['x'].values,cluster[cluster['clusters']==3]['y'].values,color="k", label='cluster 3')
ax.scatter(cluster[cluster['clusters']==4]['x'].values,cluster[cluster['clusters']==4]['y'].values,color="c", label='cluster 4')
ax.legend()
plt.title("Clusters of similar movies using K-means")
plt.ylabel('PC2')
plt.xlabel('PC1');
plt.show()
做得好。我们将评估我们的模型并在评估步骤中绘制簇。
预测用户的电影评级
为此,我编写了一个名为prediction()的函数。它采用有关用户和项目(在本例中为电影)的示例输入,并按名称从图创建 TensorFlow 占位符。然后它求值这些张量。在以下代码中,需要注意的是 TensorFlow 假定检查点目录已存在,因此请确保它已存在。有关此步骤的详细信息,请参阅run.py文件。请注意,此脚本不显示任何结果,但在main.py脚本中进一步调用此脚本中名为prediction的函数进行预测:
def prediction(users=predicted_user, items=predicted_item, allow_soft_placement=allow_soft_placement,\
log_device_placement=log_device_placement, checkpoint_dir=checkpoint_dir):
rating_prediction=[]
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
graph = tf.Graph()
with graph.as_default():
session_conf = tf.ConfigProto(allow_soft_placement=allow_soft_placement,log_device_placement=log_device_placement)
with tf.Session(config = session_conf) as sess:
new_saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_prefix))
new_saver.restore(sess, tf.train.latest_checkpoint(checkpoint_dir))
user_batch = graph.get_operation_by_name("id_user").outputs[0]
item_batch = graph.get_operation_by_name("id_item").outputs[0]
predictions = graph.get_operation_by_name("svd_inference").outputs[0]
pred = sess.run(predictions, feed_dict={user_batch: users, item_batch: items})
pred = clip(pred)
sess.close()
return pred
我们将看到如何使用此方法来预测电影的前 K 部电影和用户评级。在前面的代码段中,clip()是一个用户定义的函数,用于限制数组中的值。这是实现:
def clip(x):
return np.clip(x, 1.0, 5.0) # rating 1 to 5
现在让我们看看,我们如何使用prediction()方法来制作用户的一组电影评级预测:
def user_rating(users,movies):
if type(users) is not list: users=np.array([users])
if type(movies) is not list:
movies=np.array([movies])
return prediction(users,movies)
上述函数返回各个用户的用户评级。它采用一个或多个数字的列表,一个或多个用户 ID 的列表,以及一个或多个数字的列表以及一个或多个电影 ID 的列表。最后,它返回预测电影列表。
寻找前 K 部电影
以下方法提取用户未见过的前 K 个电影,其中 K 是任意整数,例如 10.函数的名称是top_k_movies()。它返回特定用户的前 K 部电影。它需要一个用户 ID 列表和评级数据帧。然后它存储这些电影的所有用户评级。输出是包含用户 ID 作为键的字典,以及该用户的前 K 电影列表作为值:
def top_k_movies(users,ratings_df,k):
dicts={}
if type(users) is not list:
users = [users]
for user in users:
rated_movies = ratings_df[ratings_df['user']==user].drop(['st', 'user'], axis=1)
rated_movie = list(rated_movies['item'].values)
total_movies = list(ratings_df.item.unique())
unseen_movies = list(set(total_movies) - set(rated_movie))
rated_list = []
rated_list = prediction(np.full(len(unseen_movies),user),np.array(unseen_movies))
useen_movies_df = pd.DataFrame({'item': unseen_movies,'rate':rated_list})
top_k = list(useen_movies_df.sort_values(['rate','item'], ascending=[0, 0])['item'].head(k).values)
dicts.update({user:top_k})
result = pd.DataFrame(dicts)
result.to_csv("user_top_k.csv")
return dicts
在前面的代码段中,prediction()是我们之前描述的用户定义函数。我们将看到一个如何预测前 K 部电影的例子(更多或见后面的部分见Test.py)。
预测前 K 类似的电影
我编写了一个名为top_k_similar_items()的函数,它计算并返回与特定电影类似的 K 个电影。它需要一个数字列表,数字,电影 ID 列表和评级数据帧。它存储这些电影的所有用户评级。它还将 K 作为自然数。
TRAINED的值可以是TRUE或FALSE,它指定是使用受过训练的用户还是使用电影表或未经训练的用户。最后,它返回一个 K 电影列表,类似于作为输入传递的电影:
def top_k_similar_items(movies,ratings_df,k,TRAINED=False):
if TRAINED:
df=pd.read_pickle("user_item_table_train.pkl")
else:
df=pd.read_pickle("user_item_table.pkl")
corr_matrix=item_item_correlation(df,TRAINED)
if type(movies) is not list:
return corr_matrix[movies].sort_values(ascending=False).drop(movies).index.values[0:k]
else:
dict={}
for movie in movies: dict.update({movie:corr_matrix[movie].sort_values(ascending=False).drop(movie).index.values[0:k]})
pd.DataFrame(dict).to_csv("movie_top_k.csv")
return dict
在前面的代码中,item_item_correlation()函数是一个用户定义的函数,它计算在预测前 K 个类似电影时使用的电影 - 电影相关性。方法如下:
def item_item_correlation(df,TRAINED):
if TRAINED:
if os.path.isfile("model/item_item_corr_train.pkl"):
df_corr=pd.read_pickle("item_item_corr_train.pkl")
else:
df_corr=df.corr()
df_corr.to_pickle("item_item_corr_train.pkl")
else:
if os.path.isfile("model/item_item_corr.pkl"):
df_corr=pd.read_pickle("item_item_corr.pkl")
else:
df_corr=df.corr()
df_corr.to_pickle("item_item_corr.pkl")
return df_corr
计算用户 - 用户相似度
为了计算用户 - 用户相似度,我编写了user_similarity()函数,它返回两个用户之间的相似度。它需要三个参数:用户 1,用户 2;评级数据帧;并且TRAINED的值可以是TRUE或FALSE,并且指的是是否应该使用受过训练的用户与电影表或未经训练的用户。最后,它计算用户之间的 Pearson 系数(介于 -1 和 1 之间的值):
def user_similarity(user_1,user_2,ratings_df,TRAINED=False):
corr_matrix=user_user_pearson_corr(ratings_df,TRAINED)
return corr_matrix[user_1][user_2]
在前面的函数中,user_user_pearson_corr()是一个计算用户 - 用户 Pearson 相关性的函数:
def user_user_pearson_corr(ratings_df,TRAINED):
if TRAINED:
if os.path.isfile("model/user_user_corr_train.pkl"):
df_corr=pd.read_pickle("user_user_corr_train.pkl")
else:
df =pd.read_pickle("user_item_table_train.pkl")
df=df.T
df_corr=df.corr()
df_corr.to_pickle("user_user_corr_train.pkl")
else:
if os.path.isfile("model/user_user_corr.pkl"):
df_corr=pd.read_pickle("user_user_corr.pkl")
else:
df = pd.read_pickle("user_item_table.pkl")
df=df.T
df_corr=df.corr()
df_corr.to_pickle("user_user_corr.pkl")
return df_corr
评估推荐系统
在这个小节中,我们将通过绘制它们以评估电影如何在不同的簇中传播来评估簇。
然后,我们将看到前 K 部电影,并查看我们之前讨论过的用户 - 用户相似度和其他指标。现在让我们开始导入所需的库:
import tensorflow as tf
import pandas as pd
import readers
import main
import kmean as km
import numpy as np
接下来,让我们定义用于评估的数据参数:
DATA_FILE = "Input/ratings.dat" # Data source for the positive data.
K = 5 #Number of clusters
MAX_ITERS = 1000 #Maximum number of iterations
TRAINED = False # Use TRAINED user vs item matrix
USER_ITEM_TABLE = "user_item_table.pkl"
COMPUTED_CLUSTER_CSV = "clusters.csv"
NO_OF_PCA_COMPONENTS = 2 #number of pca components
SVD_SOLVER = "randomized" #svd solver -e.g. randomized, full etc.
让我们看看加载将在k_mean_clustering()方法的调用调用中使用的评级数据集:
ratings_df = readers.read_file("Input/ratings.dat", sep="::")
clusters,movies = km.k_mean_clustering(ratings_df, K, MAX_ITERS, TRAINED = False)
cluster_df=pd.DataFrame({'movies':movies,'clusters':clusters})
做得好!现在让我们看一些简单的输入簇(电影和各自的簇):
print(cluster_df.head(10))
>>>
clusters movies
0 0 0
1 4 1
2 4 2
3 3 3
4 4 4
5 2 5
6 4 6
7 3 7
8 3 8
9 2 9
print(cluster_df[cluster_df['movies']==1721])
>>>
clusters movies
1575 2 1721
print(cluster_df[cluster_df['movies']==647])
>>>
clusters movies
627 2 647
让我们看看电影是如何分散在群集中的:
km.showClusters(USER_ITEM_TABLE, COMPUTED_CLUSTER_CSV, NO_OF_PCA_COMPONENTS, SVD_SOLVER)
>>>

图 6:类似电影的簇
如果我们查看该图,很明显数据点更准确地聚集在簇 3 和 4 上。但是,簇 0,1 和 2 更分散并且不能很好地聚类。
在这里,我们没有计算任何准确率指标,因为训练数据没有标签。现在让我们为给定的相应电影名称计算前 K 个类似的电影并打印出来:
ratings_df = readers.read_file("Input/ratings.dat", sep="::")
topK = main.top_k_similar_items(9,ratings_df = ratings_df,k = 10,TRAINED = False)
print(topK)
>>>
[1721, 1369, 164, 3081, 732, 348, 647, 2005, 379, 3255]
上述结果为电影9 ::Sudden Death (1995)::Action计算了 Top-K 类似的电影。现在,如果您观察movies.dat文件,您将看到以下电影与此类似:
1721::Titanic (1997)::Drama|Romance
1369::I Can't Sleep (J'ai pas sommeil) (1994)::Drama|Thriller
164::Devil in a Blue Dress (1995)::Crime|Film-Noir|Mystery|Thriller
3081::Sleepy Hollow (1999)::Horror|Romance
732::Original Gangstas (1996)::Crime
348::Bullets Over Broadway (1994)::Comedy
647::Courage Under Fire (1996)::Drama|War
2005::Goonies, The (1985)::Adventure|Children's|Fantasy
379::Timecop (1994)::Action|Sci-Fi
3255::League of Their Own, A (1992)::Comedy|Drama
现在让我们计算用户 - 用户 Pearson 相关性。当运行此用户相似度函数时,在第一次运行时需要时间来提供输出但在此之后,其响应是实时的:
print(main.user_similarity(1,345,ratings_df))
>>>
0.15045477803357316
Now let's compute the aspect rating given by a user for a movie:
print(main.user_rating(0,1192))
>>>
4.25545645
print(main.user_rating(0,660))
>>>
3.20203304
让我们看一下用户的 K 电影推荐:
print(main.top_k_movies([768],ratings_df,10))
>>>
{768: [2857, 2570, 607, 109, 1209, 2027, 592, 588, 2761, 479]}
print(main.top_k_movies(1198,ratings_df,10))
>>>
{1198: [2857, 1195, 259, 607, 109, 2027, 592, 857, 295, 479]}
到目前为止,我们已经看到如何使用电影和评级数据集开发简单的 RE。但是,大多数推荐问题都假设我们有一个由(用户,项目,评级)元组集合形成的消费/评级数据集。这是协同过滤算法的大多数变体的起点,并且已经证明它们可以产生良好的结果;但是,在许多应用中,我们有大量的项目元数据(标签,类别和流派)可用于做出更好的预测。
这是将 FM 用于特征丰富的数据集的好处之一,因为有一种自然的方式可以在模型中包含额外的特征,并且可以使用维度参数 d 对高阶交互进行建模(参见下面的图 7)更多细节)。
最近的一些类型的研究表明,特征丰富的数据集可以提供更好的预测:i)Xiangnan He 和 Tat-Seng Chua,用于稀疏预测分析的神经分解机。在 SIGIR '17 的论文集中,2017 年 8 月 7 日至 11 日,日本东京新宿。ii)Jun Xiao,Hao Ye,Xiantian He,Hanwang Zhang,Fei Wu 和 Tat-Seng Chua(2017)Attentional Factorization Machines:Learning the Learning 通过注意网络的特征交互的权重 IJCAI,墨尔本,澳大利亚,2017 年 8 月 19 - 25 日。
这些论文解释了如何将现有数据转换为特征丰富的数据集,以及如何在数据集上实现 FM。因此,研究人员正在尝试使用 FM 来开发更准确和更强大的 RE。在下一节中,我们将看到一些使用 FM 和一些变体的示例。
分解机和推荐系统
在本节中,我们将看到两个使用 FM 开发更强大的推荐系统的示例 。我们将首先简要介绍 FM 及其在冷启动推荐问题中的应用。
然后我们将看到使用 FM 开发真实推荐系统的简短示例。之后,我们将看到一个使用称为神经分解机(NFM)的 FM 算法的改进版本的示例。
分解机
基于 FM 的技术处于个性化的前沿。它们已经被证明是非常强大的,具有足够的表达能力来推广现有模型,例如矩阵/张量分解和多项式核回归。换句话说,这种类型的算法是监督学习方法,其通过结合矩阵分解算法中不存在的二阶特征交互来增强线性模型的表现。
现有的推荐算法需要(用户,项目和评级)元组中的消费(产品)或评级(电影)数据集。这些类型的数据集主要用于协同过滤(CF)算法的变体。 CF 算法已得到广泛采用,并已证明可以产生良好的结果。但是,在许多情况下,我们有大量的项目元数据(标签,类别和流派),可以用来做出更好的预测。不幸的是,CF 算法不使用这些类型的元数据。
FM 可以使用这些特征丰富的(元)数据集。 FM 可以使用这些额外的特征来模拟指定维度参数 d 的高阶交互。最重要的是,FM 还针对处理大规模稀疏数据集进行了优化。因此,二阶 FM 模型就足够了,因为没有足够的信息来估计更复杂的交互:

图 7:表示具有特征向量 x 和目标 y 的个性化问题的示例训练数据集。这里的行指的是导演,演员和流派信息的电影和专栏
假设预测问题的数据集由设计矩阵X ∈ R^nxp描述,如图 7 所示。在图 1 中,X的第i行X ∈ R^p描述了一种情况,其中p是实数估值变量。另一方面,y[i]是第i个情况的预测目标。或者,我们可以将此集合描述为元组(x, y)的集合S,其中(同样)x ∈ R^p是特征向量,y是其对应的目标或标签。
换句话说,在图 7 中,每行表示特征向量x[i]与其相应的目标y[i]。为了便于解释,这些特征分为活跃用户(蓝色),活动项目(红色),同一用户评级的其他电影(橙色),月份时间(绿色)和最后一部电影评级指标(棕色)。然后,FM 算法使用以下分解的交互参数来模拟x中p输入变量之间的所有嵌套交互(直到d阶):
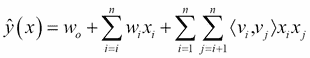
在等式中,v表示与每个变量(用户和项目)相关联的 K 维潜在向量,并且括号运算符表示内积。具有数据矩阵和特征向量的这种表示在许多机器学习方法中是常见的,例如,在线性回归或支持向量机(SVM)中。
但是,如果您熟悉矩阵分解(MF)模型,则前面的等式应该看起来很熟悉:它包含全局偏差以及用户/项目特定的偏差,并包括用户项目交互。现在,如果我们假设每个x(j)向量在位置u和i处仅为非零,我们得到经典的 MF 模型:
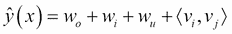
然而,用于推荐系统的 MF 模型经常遭受冷启动问题。我们将在下一节讨论这个问题。
冷启动问题和协同过滤方法
冷启动这个问题听起来很有趣,但顾名思义,它源于汽车。假设你住在阿拉斯加状态。由于寒冷,您的汽车发动机可能无法顺利启动,但一旦达到最佳工作温度,它将启动,运行并正常运行。
在推荐引擎的领域中,术语冷启动仅仅意味着对于引擎来说还不是最佳的环境以提供最佳结果。在电子商务中,冷启动有两个不同的类别:产品冷启动和用户冷启动。
冷启动是基于计算机的信息系统中的潜在问题,涉及一定程度的自动数据建模。具体而言,它涉及的问题是系统无法对尚未收集到足够信息的用户或项目进行任何推断。
冷启动问题在推荐系统中最为普遍。在协同过滤方法中,推荐系统将识别与活动用户共享偏好的用户,并提出志同道合的用户喜欢的项目(并且活跃用户尚未看到)。由于冷启动问题,这种方法将无法考虑社区中没有人评定的项目。
通过在基于内容的匹配和协同过滤之间采用混合方法,通常可以减少冷启动问题。尚未收到用户评级的新项目将根据社区分配给其他类似项目的评级自动分配评级。项目相似性将根据项目的基于内容的特征来确定。
使用基于 CF 的方法的推荐引擎根据用户操作推荐每个项目。项目具有的用户操作越多,就越容易分辨哪个用户对其感兴趣以及其他项目与之类似。随着时间的推移,系统将能够提供越来越准确的建议。在某个阶段,当新项目或用户添加到用户项目矩阵时,会出现此问题:
图 8:用户与项目矩阵有时会导致冷启动问题
在这种情况下,RE 还没有足够的知识来了解这个新用户或这个新项目。类似于 FM 的基于内容的过滤方法是可以结合以减轻冷启动问题的方法。
前两个方程之间的主要区别在于,FM 在潜在向量方面引入了高阶相互作用,潜在向量也受分类或标签数据的影响。这意味着模型超越了共现,以便在每个特征的潜在表示之间找到更强的关系。
问题的定义和制定
给定用户在电子商务网站上的典型会话期间执行的点击事件的序列 ,目标是预测用户是否购买或不购买,如果他们正在购买,他们会买什么物品。因此,这项任务可分为两个子目标:
- 用户是否会在此会话中购买物品?
- 如果是,那么将要购买的物品是什么?
为了预测在会话中购买的项目的数量,强大的分类器可以帮助预测用户是否将购买该项目的 。在最初实现 FM 后,训练数据的结构应如下:

图 9:用户与项目/类别/历史表可用于训练推荐模型
为了准备这样的训练集,我们可以使用 pandas 中的get_dummies()方法将所有列转换为分类数据,因为 FM 模型使用表示为整数的分类数据。
我们使用两个函数TFFMClassifier和TFFMRegressor来进行预测(参见items.py)并分别计算 MSE(参见来自tffm库的quantity.py脚本(在 MIT 许可下))。tffm是基于 TensorFlow 的 FM 和 pandas 实现,用于预处理和结构化数据。这个基于 TensorFlow 的实现提供了一个任意顺序(>= 2)分解机,它支持:
- 密集和稀疏的输入
- 不同的(基于梯度的)优化方法
- 通过不同的损失函数进行分类/回归(logistic 和 mse 实现)
- 通过 TensorBoard 记录
另一个好处是推理时间相对于特征数量是线性的。
我们要感谢作者并引用他们的工作如下:Mikhail Trofimov,Alexander Novikov,TFFM:TensorFlow 实现任意顺序分解机,GitHub 仓库,2016。
要使用此库,只需在终端上发出以下命令:
$ sudo pip3 install tffm # For Python3.x
$ sudo pip install tffm # For Python 2.7.x
在开始实现之前,让我们看一下我们将在本例中使用的数据集。
数据集描述
例如,我将使用 RecSys 2015 挑战数据集来说明如何拟合 FM 模型以获得个性化推荐。该数据包含电子商务网站的点击和购买事件,以及其他项目类别数据。数据集的大小约为 275MB,可以从此链接下载。
有三个文件和一个自述文件;但是,我们将使用youchoose-buys.dat(购买活动)和youchoose-clicks.dat(点击活动):
youchoose-clicks.dat:文件中的每条记录/行都包含以下字段:- 会话 ID:一个会话中的一次或多次点击
- 时间戳:发生点击的时间
- 项目 ID:项目的唯一标识符
- 类别:项目的类别
youchoose-buys.dat:文件中的每条记录/行都包含以下字段:- 会话 ID:会话 ID:会话中的一个或多个购买事件
- 时间戳:购买发生的时间
- 物料 ID:物品的唯一标识符
- 价格:商品的价格
- 数量:购买了多少件商品
youchoose-buys.dat中的会话 ID 也存在于youchoose-clicks.dat文件中。这意味着具有相同会话 ID 的记录一起形成会话期间某个用户的点击事件序列。
会话可能很短(几分钟)或很长(几个小时),可能只需点击一下或点击几百次。这一切都取决于用户的活动。
实现工作流程
让我们开发一个预测并生成solution.data文件的推荐模型。这是一个简短的工作流程:
-
下载并加载 RecSys 2015 挑战数据集,并复制到本章代码库的
data文件夹中 -
购买数据包含会话 ID,时间戳,项目 ID,类别和数量。此外,
youchoose-clicks.dat包含会话 ID,时间戳,项目 ID 和类别。我们不会在这里使用时间戳。我们删除时间戳,对所有列进行单热编码, 合并买入和点击数据集以使数据集特征丰富。在预处理之后,数据看起来类似于图 11 中所示的数据。 -
为简化起见,我们仅考虑前 10,000 个会话,并将数据集拆分为训练(75%)和测试(25%)集。
-
然后,我们将测试分为正常(保留历史数据)和冷启动(通过删除历史数据),以区分具有历史记录或没有历史记录的用户/项目的模型。
-
然后我们使用
tffm训练我们的 FM 模型,这是 TensorFlow 中 FM 的实现,并使用训练数据训练模型。 -
最后,我们在正常和冷启动数据集上评估模型。
图 10:使用 FM 预测会话中已购买项目列表的工作流程
预处理
如果我们想充分利用类别和扩展的历史数据,我们需要加载数据并将其转换为正确的格式。因此,在准备训练集之前,必须进行一些预处理。让我们从加载包和模块开始:
import tensorflow as tf
import pandas as pd
from collections import Counter
from tffm import TFFMClassifier
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.metrics import accuracy_score
import os
我是 ,假设您已经从前面提到的链接下载了数据集。现在让我们加载数据集:
buys = open('data/yoochoose-buys.dat', 'r')
clicks = open('data/yoochoose-clicks.dat', 'r')
现在为点击创建 pandas 数据帧并购买数据集:
initial_buys_df = pd.read_csv(buys, names=['Session ID', 'Timestamp', 'Item ID', 'Category', 'Quantity'], dtype={'Session ID': 'float32', 'Timestamp': 'str', 'Item ID': 'float32','Category': 'str'})
initial_buys_df.set_index('Session ID', inplace=True)
initial_clicks_df = pd.read_csv(clicks, names=['Session ID', 'Timestamp', 'Item ID', 'Category'],dtype={'Category': 'str'})
initial_clicks_df.set_index('Session ID', inplace=True)
我们不需要在这个例子中使用时间戳,所以让我们从数据帧中删除它们:
initial_buys_df = initial_buys_df.drop('Timestamp', 1)
print(initial_buys_df.head()) # first five records
print(initial_buys_df.shape) # shape of the dataframe
>>>

initial_clicks_df = initial_clicks_df.drop('Timestamp', 1)
print(initial_clicks_df.head())
print(initial_clicks_df.shape)
>>>

由于在此示例中我们不使用时间戳,因此从数据帧(df)中删除Timestamp列:
initial_buys_df = initial_buys_df.drop('Timestamp', 1)
print(initial_buys_df.head(n=5))
print(initial_buys_df.shape)
>>>

initial_clicks_df = initial_clicks_df.drop('Timestamp', 1)
print(initial_clicks_df.head(n=5))
print(initial_clicks_df.shape)
>>>

让我们选取前 10,000 名购买用户:
x = Counter(initial_buys_df.index).most_common(10000)
top_k = dict(x).keys()
initial_buys_df = initial_buys_df[initial_buys_df.index.isin(top_k)]
print(initial_buys_df.head())
print(initial_buys_df.shape)
>>>

initial_clicks_df = initial_clicks_df[initial_clicks_df.index.isin(top_k)]
print(initial_clicks_df.head())
print(initial_clicks_df.shape)
>>>
现在让我们创建索引的副本,因为我们还将对其应用单热编码:
initial_buys_df['_Session ID'] = initial_buys_df.index
print(initial_buys_df.head())
print(initial_buys_df.shape)
>>>
正如我们之前提到的 ,我们可以将历史参与数据引入我们的 FM 模型。我们将使用一些group_by魔法生成整个用户参与的历史记录。首先,我们对所有列进行单热编码以获得点击和购买:
transformed_buys = pd.get_dummies(initial_buys_df)
print(transformed_buys.shape)
>>>
(106956, 356)
transformed_clicks = pd.get_dummies(initial_clicks_df)print(transformed_clicks.shape)
>>>
(209024, 56)
现在是时候汇总项目和类别的历史数据了:
filtered_buys = transformed_buys.filter(regex="Item.*|Category.*")
print(filtered_buys.shape)
>>>
(106956, 354)
filtered_clicks = transformed_clicks.filter(regex="Item.*|Category.*")
print(filtered_clicks.shape)
>>>
(209024, 56)
historical_buy_data = filtered_buys.groupby(filtered_buys.index).sum()
print(historical_buy_data.shape)
>>>
(10000, 354)
historical_buy_data = historical_buy_data.rename(columns=lambda column_name: 'buy history:' + column_name)
print(historical_buy_data.shape)
>>>
(10000, 354)
historical_click_data = filtered_clicks.groupby(filtered_clicks.index).sum()
print(historical_click_data.shape)
>>>
(10000, 56)
historical_click_data = historical_click_data.rename(columns=lambda column_name: 'click history:' + column_name)
然后我们合并每个user_id的历史数据:
merged1 = pd.merge(transformed_buys, historical_buy_data, left_index=True, right_index=True)
print(merged1.shape)
merged2 = pd.merge(merged1, historical_click_data, left_index=True, right_index=True)
print(merged2.shape)
>>>
(106956, 710)
(106956, 766)
然后我们将数量作为目标并将其转换为二元:
y = np.array(merged2['Quantity'].as_matrix())
现在让我们将y转换为二元:如果购买发生,为1;否则为0:
for i in range(y.shape[0]):
if y[i]!=0:
y[i]=1
else:
y[i]=0
print(y.shape)
print(y[0:100])
print(y, y.shape[0])
print(y[0])
print(y[0:100])
print(y, y.shape)
>>>

训练 FM 模型
由于我们准备了数据集,下一个任务是创建 MF 模型。首先,让我们将数据分成训练和测试集:
X_tr, X_te, y_tr, y_te = train_test_split(merged2, y, test_size=0.25)
然后我们将测试数据分成一半,一个用于正常测试,一个用于冷启动测试:
X_te, X_te_cs, y_te, y_te_cs = train_test_split(X_te, y_te, test_size=0.5)
现在让我们在数据帧中包含会话 ID 和项目 ID:
test_x = pd.DataFrame(X_te, columns = ['Item ID'])
print(test_x.head())
>>>

test_x_cs = pd.DataFrame(X_te_cs, columns = ['Item ID'])
print(test_x_cs.head())
>>>

然后我们从数据集中删除不需要的特征:
X_tr.drop(['Item ID', '_Session ID', 'click history:Item ID', 'buy history:Item ID', 'Quantity'], 1, inplace=True)
X_te.drop(['Item ID', '_Session ID', 'click history:Item ID', 'buy history:Item ID', 'Quantity'], 1, inplace=True)
X_te_cs.drop(['Item ID', '_Session ID', 'click history:Item ID', 'buy history:Item ID', 'Quantity'], 1, inplace=True)
然后我们需要将DataFrame转换为数组:
ax_tr = np.array(X_tr)
ax_te = np.array(X_te)
ax_te_cs = np.array(X_te_cs)
既然 pandas DataFrame已经转换为 NumPy 数组,我们需要做一些null处理。我们简单地用零替换 NaN:
ax_tr = np.nan_to_num(ax_tr)
ax_te = np.nan_to_num(ax_te)
ax_te_cs = np.nan_to_num(ax_te_cs)
然后我们用优化的超参数实例化 TF 模型进行分类:
model = TFFMClassifier(
order=2,
rank=7,
optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
n_epochs=100,
batch_size=1024,
init_std=0.001,
reg=0.01,
input_type='dense',
log_dir = ' logs/',
verbose=1,
seed=12345
)
在我们开始训练模型之前,我们必须为冷启动准备数据:
cold_start = pd.DataFrame(ax_te_cs, columns=X_tr.columns)
和前面提到的一样,如果我们只能访问类别而没有历史点击/购买数据,我们也有兴趣了解会发生什么。让我们删除cold_start测试集的历史点击和购买数据:
for column in cold_start.columns:
if ('buy' in column or 'click' in column) and ('Category' not in column):
cold_start[column] = 0
现在让我们训练模型:
model.fit(ax_tr, y_tr, show_progress=True)
其中一项最重要的任务是预测会议中的购买事件:
predictions = model.predict(ax_te)
print('accuracy: {}'.format(accuracy_score(y_te, predictions)))
print("predictions:",predictions[:10])
print("actual value:",y_te[:10])
>>>
accuracy: 1.0
predictions: [0 0 1 0 0 1 0 1 1 0]
actual value: [0 0 1 0 0 1 0 1 1 0]
cold_start_predictions = model.predict(ax_te_cs)
print('Cold-start accuracy: {}'.format(accuracy_score(y_te_cs, cold_start_predictions)))
print("cold start predictions:",cold_start_predictions[:10])
print("actual value:",y_te_cs[:10])
>>>
Cold-start accuracy: 1.0
cold start predictions: [1 1 1 1 1 0 1 0 0 1]
actual value: [1 1 1 1 1 0 1 0 0 1]
然后让我们将预测值添加到测试数据中:
test_x["Predicted"] = predictions
test_x_cs["Predicted"] = cold_start_predictions
现在是时候找到测试数据中每个session_id的所有买入事件并检索相应的项目 ID:
sess = list(set(test_x.index))
fout = open("solution.dat", "w")
print("writing the results into .dat file....")
for i in sess:
if test_x.loc[i]["Predicted"].any()!= 0:
fout.write(str(i)+";"+','.join(s for s in str(test_x.loc[i]["Item ID"].tolist()).strip('[]').split(','))+'\n')
fout.close()
>>>
writing the results into .dat file....
然后我们对冷启动测试数据做同样的事情:
sess_cs = list(set(test_x_cs.index))
fout = open("solution_cs.dat", "w")
print("writing the cold start results into .dat file....")
for i in sess_cs:
if test_x_cs.loc[i]["Predicted"].any()!= 0:
fout.write(str(i)+";"+','.join(s for s in str(test_x_cs.loc[i]["Item ID"].tolist()).strip('[]').split(','))+'\n')
fout.close()
>>>
writing the cold start results into .dat file....
print("completed..!!")
>>>
completed!!
最后,我们销毁模型以释放内存:
model.destroy()
另外,我们可以看到文件的示例内容:
11009963;214853767
10846132;214854343, 214851590
8486841;214848315
10256314;214854125
8912828;214853085
11304897;214567215
9928686;214854300, 214819577
10125303;214567215, 214853852
10223609;214854358
考虑到我们使用相对较小的数据集来拟合我们的模型, 实验结果很好。正如预期的那样,如果我们可以通过项目购买和点击访问所有信息集,则更容易生成预测,但我们仍然只使用汇总类别数据获得冷启动建议的预测。
既然我们已经看到客户将在每个会话中购买,那么计算两个测试集的均方误差将会很棒。TFFMRegressor方法可以帮助我们解决这个问题。为此,请使用quantity.py脚本。
首先,问题是如果我们只能访问类别而没有历史点击/购买数据会发生什么。让我们删除cold_start测试集的历史点击和购买数据:
for column in cold_start.columns:
if ('buy' in column or 'click' in column) and ('Category' not in column):
cold_start[column] = 0
让我们创建 MF 模型。您可以使用超参数:
reg_model = TFFMRegressor(
order=2,
rank=7,
optimizer=tf.train.AdamOptimizer(learning_rate=0.1),
n_epochs=100,
batch_size=-1,
init_std=0.001,
input_type='dense',
log_dir = ' logs/',
verbose=1
)
在前面的代码块中,随意放入您自己的日志记录路径。现在是时候使用正常和冷启动训练集训练回归模型:
reg_model.fit(X_tr, y_tr, show_progress=True)
然后我们计算两个测试集的均方误差:
predictions = reg_model.predict(X_te)
print('MSE: {}'.format(mean_squared_error(y_te, predictions)))
print("predictions:",predictions[:10])
print("actual value:",y_te[:10])
cold_start_predictions = reg_model.predict(X_te_cs)
print('Cold-start MSE: {}'.format(mean_squared_error(y_te_cs, cold_start_predictions)))
print("cold start predictions:",cold_start_predictions[:10])
print("actual value:",y_te_cs[:10])
print("Regression completed..!!")
>>>MSE: 0.4897467853668941
predictions: [ 1.35086 0.03489107 1.0565269 -0.17359206 -0.01603088 0.03424695
2.29936886 1.65422797 0.01069662 0.02166392]
actual value: [1 0 1 0 0 0 1 1 0 0]
Cold-start MSE: 0.5663486183636738
cold start predictions: [-0.0112379 1.21811676 1.29267406 0.02357371 -0.39662406 1.06616664
-0.10646269 0.00861482 1.22619736 0.09728943]
actual value: [0 1 1 0 1 1 0 0 1 0]
Regression completed..!!
最后,我们销毁模型以释放内存:
reg_model.destroy()
因此,从训练数据集中删除类别列会使 MSE 更小,但这样做意味着我们无法解决冷启动建议问题。考虑到我们使用相对较小的数据集的条件,实验结果很好。
正如预期的那样,如果我们可以通过项目购买和点击访问完整的信息设置,则更容易生成预测,但我们仍然只使用汇总的类别数据获得冷启动建议的预测。
改进的分解机
Web 应用的许多预测任务需要对分类变量(例如用户 ID)和人口统计信息(例如性别和职业)进行建模。为了应用标准 ML 技术,需要通过单热编码(或任何其他技术)将这些分类预测变换器转换为一组二元特征。这使得得到的特征向量高度稀疏。要从这种稀疏数据中有效地学习,考虑特征之间的相互作用是很重要的。
在上一节中,我们看到 FM 可以有效地应用于模型二阶特征交互。但是,FM 模型以线性方式进行交互,如果您想捕获真实世界数据的非线性和固有复杂结构,则这种方式是不够的。
Xiangnan He 和 Jun Xiao 等。为了克服这一局限,我们提出了一些研究计划,如神经因子分解机(NFM)和注意因子分解机(AFM)。
有关更多信息,请参阅以下文章:
- Xiangnan He 和 Tat-Seng Chua,用于稀疏预测分析的神经分解机。在 SIGIR '17,新宿,东京,日本,2017 年 8 月 7 日至 11 日的会议录。
- Jun Xiao,Hao Ye,Xiantian He,Hanwang Zhang,Fei Wu 和 Tat-Seng Chua(2017),注意分解机:通过注意网络学习特征交互的权重 IJCAI,墨尔本,澳大利亚,2017 年 8 月 19 - 25 日。
通过在建模二阶特征相互作用中无缝地组合 FM 的线性度和在建模高阶特征相互作用中神经网络的非线性,NFM 可用于在稀疏设置下进行预测。
另一方面,即使所有特征交互具有相同的权重,AFM 也可用于对数据建模,因为并非所有特征交互都同样有用且具有预测性。
在下一节中,我们将看到使用 NFM 进行电影推荐的示例。
神经分解机
使用原始 FM 算法,其表现可能受到建模方式阻碍,它使用相同权重建模所有特征交互,因为并非所有特征交互都同样有用且具有预测性。例如,与无用特征的交互甚至可能引入噪声并对表现产生不利影响。
最近,Xiangnan H.等。提出了一种称为神经分解机(NFM)的 FM 算法的改进版本。 NFM 在建模二阶特征相互作用中无缝地结合了 FM 的线性度,在建模高阶特征相互作用时无缝地结合了神经网络的非线性。从概念上讲,NFM 比 FM 更具表现力,因为 FM 可以被看作是没有隐藏层的 NFM 的特例。
数据集描述
我们使用 MovieLens 数据进行个性化标签推荐。它包含电影上 668,953 个用户的标签应用。使用单热编码将每个标签应用(用户 ID,电影 ID 和标签)转换为特征向量。这留下了 90,445 个二元特征,称为ml-tag数据集。
我使用 Perl 脚本将其从.dat转换为.libfm格式。转换程序在此链接(第 2.2.1 节)中描述。转换后的数据集包含用于训练,验证和测试的文件,如下所示:
ml-tag.train.libfmml-tag.validation.libfmml-tag.test.libfm
有关此文件格式的更多信息,请参阅此链接。
NFM 和电影推荐
我们使用 TensorFlow 并复用来自这个 GitHub 的扩展 NFM 实现。这是 FM 的深度版本,与常规 FM 相比更具表现力。仓库有三个文件,即NeuralFM.py,FM.py和LoadData.py:
FM.py用于训练数据集。这是 FM 的原始实现。NeuralFM.py用于训练数据集。这是 NFM 的原始实现,但有一些改进和扩展。LoadData.py用于以 libfm 格式预处理和加载数据集。
模型训练
首先,我们使用以下命令训练 FM 模型。该命令还包括执行训练所需的参数:
$ python3 FM.py --dataset ml-tag --epoch 20 --pretrain -1 --batch_size 4096 --lr 0.01 --keep 0.7
>>>
FM: dataset=ml-tag, factors=16, #epoch=20, batch=4096, lr=0.0100, lambda=0.0e+00, keep=0.70, optimizer=AdagradOptimizer, batch_norm=1
#params: 1537566
Init: train=1.0000, validation=1.0000 [5.7 s]
Epoch 1 [13.9 s] train=0.5413, validation=0.6005 [7.8 s]
Epoch 2 [14.2 s] train=0.4927, validation=0.5779 [8.3 s]
…
Epoch 19 [15.4 s] train=0.3272, validation=0.5429 [8.1 s]
Epoch 20 [16.6 s] train=0.3242, validation=0.5425 [7.8 s]
训练结束后,训练好的模型将保存在主目录的pretrain文件夹中:
将模型保存为预训练文件。
此外,我已尝试使用以下代码进行验证和训练损失的训练和验证误差:
# Plot loss over time
plt.plot(epoch_list, train_err_list, 'r--', label='FM training loss per epoch', linewidth=4)
plt.title('FM training loss per epoch')
plt.xlabel('Epoch')
plt.ylabel('Training loss')
plt.legend(loc='upper right')
plt.show()
# Plot accuracy over time
plt.plot(epoch_list, valid_err_list, 'r--', label='FM validation loss per epoch', linewidth=4)
plt.title('FM validation loss per epoch')
plt.xlabel('Epoch')
plt.ylabel('Validation loss')
plt.legend(loc='upper left')
plt.show()
前面的代码生成绘图,显示 FM 模型中每次迭代的训练与验证损失:
图 11:FM 模型中每次迭代的训练与验证损失
如果查看前面的输出日志,最佳训练(即验证和训练)将在第 20 次和最后一次迭代时进行。但是,您可以进行更多迭代以改进训练,这意味着评估步骤中的 RMSE 值较低:
Best Iter(validation)= 20 train = 0.3242, valid = 0.5425 [490.9 s]
现在让我们使用以下命令训练 NFM 模型(但也使用参数):
$ python3 NeuralFM.py --dataset ml-tag --hidden_factor 64 --layers [64] --keep_prob [0.8,0.5] --loss_type square_loss --activation relu --pretrain 0 --optimizer AdagradOptimizer --lr 0.01 --batch_norm 1 --verbose 1 --early_stop 1 --epoch 20
>>>
Neural FM: dataset=ml-tag, hidden_factor=64, dropout_keep=[0.8,0.5], layers=[64], loss_type=square_loss, pretrain=0, #epoch=20, batch=128, lr=0.0100, lambda=0.0000, optimizer=AdagradOptimizer, batch_norm=1, activation=relu, early_stop=1
#params: 5883150
Init: train=0.9911, validation=0.9916, test=0.9920 [25.8 s]
Epoch 1 [60.0 s] train=0.6297, validation=0.6739, test=0.6721 [28.7 s]
Epoch 2 [60.4 s] train=0.5646, validation=0.6390, test=0.6373 [28.5 s]
…
Epoch 19 [53.4 s] train=0.3504, validation=0.5607, test=0.5587 [25.7 s]
Epoch 20 [55.1 s] train=0.3432, validation=0.5577, test=0.5556 [27.5 s]
此外,我尝试使用以下代码使验证和训练损失的训练和验证误差可见:
# Plot test accuracy over time
plt.plot(epoch_list, test_err_list, 'r--', label='NFM test loss per epoch', linewidth=4)
plt.title('NFM test loss per epoch')
plt.xlabel('Epoch')
plt.ylabel('Test loss')
plt.legend(loc='upper left')
plt.show()
前面的代码在 NFM 模型中产生每次迭代的训练与验证损失:
图 12:NFM 模型中每次迭代的训练与验证损失
对于 NFM 模型,最佳训练(用于验证和训练)发生在第 20 次和最后一次迭代。但是,您可以进行更多迭代以改进训练,这意味着评估步骤中的 RMSE 值较低:
Best Iter (validation) = 20 train = 0.3432, valid = 0.5577, test = 0.5556 [1702.5 s]
模型评估
现在,要评估原始 FM 模型,请执行以下命令:
$ python3 FM.py --dataset ml-tag --epoch 20 --batch_size 4096 --lr 0.01 --keep 0.7 --process evaluate
Test RMSE: 0.5427
注意
对于 TensorFlow 上的 Attentional Factorization Machines 实现,感兴趣的读者可以参考此链接中的 GitHub 仓库。但请注意,某些代码可能无效。我将它们更新为兼容 TensorFlow v1.6。因此,我强烈建议您使用本书提供的代码。
要评估 NFM 模型,只需将以下行添加到NeuralFM.py脚本中的main()方法,如下所示:
# Model evaluation
print("RMSE: ")
print(model.evaluate(data.Test_data)) #evaluate on test set
>>>
RMSE: 0.5578330373003925
因此,RMSE 几乎与 FM 模型相同。现在让我们看看每次迭代的测试误差:
# Plot test accuracy over time
plt.plot(epoch_list, test_err_list, 'r--', label='NFM test loss per epoch', linewidth=4)
plt.title('NFM test loss per epoch')
plt.xlabel('Epoch')
plt.ylabel('Test loss')
plt.legend(loc='upper left')
plt.show()
前面的代码绘制了 NFM 模型中每次迭代的测试损失:
图 13:NFM 模型中每次迭代的测试损失
总结
在本章中,我们讨论了如何使用 TensorFlow 开发可扩展的推荐系统。我们已经看到推荐系统的一些理论背景,并在开发推荐系统时使用协同过滤方法。在本章后面,我们看到了如何使用 SVD 和 K 均值来开发电影推荐系统。
最后,我们了解了如何使用 FM 和一种称为 NFM 的变体来开发更准确的推荐系统,以便处理大规模稀疏矩阵。我们已经看到处理冷启动问题的最佳方法是使用 FM 协同过滤方法。
下一章是关于设计由批评和奖励驱动的 ML 系统。我们将看到如何应用 RL 算法为现实数据集制作预测模型。
十、OpenAI Gym
OpenAI Gym 是一个开源 Python 框架,由非营利性 AI 研究公司 OpenAI 开发,作为开发和评估 RL 算法的工具包。它给我们提供了一组测试问题,称为环境,我们可以编写 RL 算法来解决。这使我们能够将更多的时间用于实现和改进学习算法,而不是花费大量时间来模拟环境。此外,它为人们提供了一种比较和审查其他算法的媒介。
OpenAI 环境
OpenAI Gym 拥有一系列环境。在编写本书时,可以使用以下环境:
- 经典控制和玩具文本:来自 RL 文献的小规模任务。
- 算法:执行计算,例如添加多位数和反转序列。这些任务中的大多数都需要记忆,并且可以通过改变序列长度来改变它们的难度。
- Atari:经典 Atari 游戏,使用街机学习环境,屏幕图像或 RAM 作为输入。
- 棋盘游戏:目前,我们已经将围棋游戏包括在
9x9和19x19板上,而 Pachi 引擎则作为对手。 - 2D 和 3D 机器人:允许在模拟中控制机器人。这些任务使用 MuJoCo 物理引擎,该引擎专为快速准确的机器人仿真而设计。一些任务改编自 RLLab。
env类
OpenAI Gym 允许使用env类,它封装了环境和任何内部动态。此类具有不同的方法和属性,使您可以实现创建新环境。最重要的方法名为reset,step和render:
reset方法的任务是通过将环境初始化为初始状态来重置环境。在重置方法中,必须包含构成环境的元素的定义(在这种情况下,机械臂的定义,要抓取的对象及其支持)。step方法是用于在时间上推进环境的 。它需要输入操作并将新观察结果返回给智能体。在该方法中,必须定义运动动态管理,状态和奖励计算以及剧集完成控制。- 最后一种方法是
render, 用于显示当前状态。
使用框架提出的env类作为新环境的基础,它采用工具包提供的通用接口。
这样,构建的环境可以集成到工具包的库中,并且可以从 OpenAI Gym 社区的用户所做的算法中学习它们的动态。
安装并运行 OpenAI Gym
有关如何使用和运行 OpenAI Gym 的更多详细说明,请参阅(此链接)的官方文档页面。使用以下命令可以实现 OpenApp Gym 的最小安装:
git clone https://github.com/openai/gym
cd gym
pip install -e
安装 OpenAI Gym 之后,您可以在 Python 代码中实例化并运行环境:
import gym
env = gym.make('CartPole-v0')
obs = env.reset()
for step_idx in range(500):
env.render()
obs, reward, done, _ = env.step(env.action_space.sample())
此代码段将首先导入gym库。然后它创建了 Cart-Pole 环境的实例 ,这是 RL 中的经典问题。 Cart-Pole 环境模拟安装在推车上的倒立摆。钟摆最初是垂直的,你的目标是保持其垂直平衡。控制摆锤的唯一方法是选择水平方向让推车移动(向左或向右)。
上面的代码运行500时间步的环境,并选择随机操作在每一步执行。因此,您在下面的视频中看到,杆不能长时间保持稳定。奖励是通过在杆距垂直方向超过 15 度之前经过的时间步数来衡量的。您保持在此范围内的时间越长,您的总奖励就越高。
Q-Learning 算法
解决 RL 问题需要在学习过程中估计评估函数。该函数必须能够通过奖励的总和来评估策略的成功。
Q-Learning 的基本思想是算法学习整个状态和动作空间的最优评估函数(S×A)。这种所谓的Q函数以Q: S×A -> R的形式提供匹配,其中R是在状态s ∈ S中执行的动作a ∈ A的未来奖励的期望值。一旦智能体学会了最佳函数Q,它就能够识别哪种行为将导致某种状态下最高的未来奖励。
实现 Q-Learning 算法的最常用示例之一涉及使用表。该表的每个单元格是值Q(s; a) = R并且它被初始化为 0.由智能体执行的动作a ∈ A是使用相对于Qε的贪婪策略来选择的。
Q-Learning 算法的基本思想是训练规则,它更新表格元素Q(s; a) = R。
该算法遵循以下基本步骤:
- 任意初始化
Q(s; a) = R。 - 对每个剧集重复以下:
-
初始化
s。 -
重复(对于剧集的每一步):
-
使用从
Q派生的策略从s ∈ S中选择一个动作a ∈ A。 -
选取动作
a,观察r,s':Q(s; a) <= Q(s; a) + a · (r + γ · max Q(s'; a) - Q(s; a)) s': s <- s' -
继续直到
s的终点。
-
我们在下图中描述了算法:
图 2:Q-Learning 算法
让我们总结一下 Q 值更新过程中使用的参数:
α是学习率,设置在 0 和 1 之间。将其设置为 0 意味着 Q 值永远不会更新,因此不会学习任何内容。设置较高的值(如 0.9)意味着可以快速进行学习。γ是折扣因子,设置在 0 和 1 之间。这模拟了未来奖励的值低于直接奖励的事实。在数学上,需要将折扣因子设置为小于 1 以使算法收敛。max Q(s'; a)是在当前状态之后的状态下可获得的最大奖励,即之后采取最佳行动的奖励。
FrozenLake 环境
智能体控制角色在4×4网格世界中的移动。网格的一些瓷砖是可行走的,而其他瓷砖则导致落入水中。另外,智能体的移动方向是不确定的,并且仅部分地取决于所选择的方向。智能体因找到目标图块的可行走路径而获得奖励:

图 3:Frozen-Lake v0 网格字的表示
使用如下网格描述上面所示的表面:
SFFF (S: starting point, safe)
FHFH (F: frozensurface, safe)
FFFH (H: hole, fall to yourdoom)
HFFG (G: goal, where the frisbee islocated)
当我们到达目标或陷入一个洞时,这一集结束。如果达到目标,我们会收到1的奖励,否则会收到0。
针对 FrozenLake 问题的 Q-Learning
在为高度结构化数据提供良好功能方面,神经网络非常强大。
为了解决 FrozenLake 问题,我们将构建一个单层网络,该网络采用1×16向量中编码的状态并学习最佳移动(动作),在向量中映射可能的动作长度为四。
以下实现基于 TensorFlow:
首先,我们需要导入所有库:
import gym
import numpy as np
import random
import tensorflow as tf
import matplotlib.pyplot as plt
然后我们加载并设置环境以进行测试:
env = gym.make('FrozenLake-v0')
输入网络是一种状态,以张量形状[1,16]编码。因此,我们定义了input1占位符:
inputs1 = tf.placeholder(shape=[1,16],dtype=tf.float32)
网络权重最初由tf.random_uniform函数随机选择:
W = tf.Variable(tf.random_uniform([16,4],0,0.01))
网络输出由inputs1占位符和权重的乘积给出:
Qout = tf.matmul(inputs1,W)
在Qout上计算的argmax将给出预测值:
predict = tf.argmax(Qout,1)
最佳动作(nextQ)以张量形状编码[1,4]:
nextQ = tf.placeholder(shape=[1,4],dtype=tf.float32)
接下来,我们定义一个损失函数来实现反向传播过程。
损失函数是loss = ∑(Q - target - Q),其中计算当前预测的 Q 值和目标值之间的差异,并且梯度通过网络传递:
loss = tf.reduce_sum(tf.square(nextQ - Qout))
优化函数是众所周知的GradientDescentOptimizer:
trainer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
updateModel = trainer.minimize(loss)
重置并初始化计算图:
tf.reset_default_graph()
init = tf.global_variables_initializer()
然后我们设置 Q-Learning 训练过程的参数:
y = .99
e = 0.1
num_episodes = 6000
jList = []
rList = []
我们定义会话sess,其中网络必须学习最佳的移动顺序:
with tf.Session() as sess:
sess.run(init)
for i in range(num_episodes):
s = env.reset()
rAll = 0
d = False
j = 0
while j < 99:
j+=1
输入状态用于为网络提供信息:
a,allQ = sess.run([predict,Qout],\
feed_dict=\
{inputs1:np.identity(16)[s:s+1]})
从输出张量a中选择一个随机状态:
if np.random.rand(1) < e:
a[0] = env.action_space.sample()
使用env.step()函数执行a[0]动作,获得奖励,r和状态,s1:
s1,r,d,_ = env.step(a[0])
新状态s1用于更新Q张量:
Q1 = sess.run(Qout,feed_dict=\
{inputs1:np.identity(16)[s1:s1+1]})
maxQ1 = np.max(Q1)
targetQ = allQ
targetQ[0,a[0]] = r + y*maxQ1
当然,必须为反向传播过程更新权重:
_,W1 = sess.run([updateModel,W],\
feed_dict=\
{inputs1:np.identity(16)[s:s+1],nextQ:targetQ})
rAll这里定义了会话期间获得的总奖励。让我们回想一下,RL 智能体的目标是最大化它从长远来看所获得的总奖励:
rAll += r
更新下一步的环境状态:
s = s1
if d == True:
e = 1./((i/50) + 10)
break
jList.append(j)
rList.append(rAll)
计算结束时,将显示成功剧集的百分比:
print ("Percent of successfulepisodes: " +\
str(sum(rList)/num_episodes) + "%")
如果我们运行模型,我们应该得到这样的结果,可以通过调整网络参数来改进:
>>>[2017-01-15 16:56:01,048] Making new env: FrozenLake-v0
Percentage of successful episodes: 0.558%
深度 Q 学习
多亏了 DeepMind 在 2013 年和 2016 年取得的近期成就,它成功地在 Atari 游戏中达到了所谓的超人级别,并击败了围棋世界冠军,RL 在机器学习社区中变得非常有趣。这种新的兴趣也是由于深度神经网络(DNN)表现为近似函数,使这种算法的潜在价值达到了更高的水平。最近获得最多兴趣的算法肯定是深度 Q-Learning。以下部分介绍深度 Q-Learning 算法,并讨论一些优化技术以最大化其表现。
深度 Q 神经网络
当状态数和可能的动作增加并且从矩阵的角度来看变得难以管理时,Q 学习基础算法会引起巨大的问题。想想谷歌使用的结构输入配置,以达到 Atari 游戏的表现水平。状态空间是离散的,但国家的数量是巨大的。这就是深度学习的步骤。神经网络非常擅长为高度结构化的数据提供良好的功能。事实上,我们可以用神经网络识别 Q 函数,它将状态和动作作为输入并输出相应的 Q 值:
Q(state; action) = value
深度神经网络最常见的实现如下图所示:
图 4:深度 Q 神经网络的通用实现
或者, 可以将状态作为输入,并为每个可能的动作生成相应的值:
Q(state) = 每个可能的操作值
这个优化的实现可以在下图中看到:
图 5:深度 Q 神经网络的优化实现
最后的方法在计算上是有利的,因为要更新 Q 值(或选择最高的 Q 值),我们只需要通过网络向前迈出一步,我们将立即获得所有可用操作的所有 Q 值。
Cart-Pole 问题
我们将建立一个深度神经网络,可以学习通过 RL 玩游戏。更具体地说,我们将使用深度 Q 学习训练智能体玩 Cart-Pole 游戏。
在这个游戏中, 自由摆动杆连接到推车。推车可以向左和向右移动,目标是尽可能长时间保持杆直立:
图 6:Cart-Pole
我们使用 OpenAI Gym 模拟这个游戏。我们需要导入所需的库:
import gym
import tensorflow as tf
import numpy as np
import time
让我们创建 Cart-Pole 游戏环境:
env = gym.make('CartPole-v0')
初始化环境,奖励列表和开始时间:
env.reset()
rewards = []
tic = time.time()
这里使用env.render()语句来显示运行模拟的窗口:
for _ in range(1000):
env.render()
env.action_space.sample()被传递给env.step()语句以构建模拟的下一步:
state, reward, done, info = \
env.step\
(env.action_space.sample())
在 Cart-Pole 游戏中,有两种可能的动作:向左或向右移动。因此,我们可以采取两种操作,编码为 0 和 1。
在这里,我们采取随机行动:
rewards.append(reward)
if done:
rewards = []
env.reset()
toc = time.time()
10 秒后,模拟结束:
if toc-tic > 10:
env.close()
要关闭显示模拟的窗口,请使用env.close()。
当我们运行模拟时,我们有一个奖励列表,如下所示:
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
在极点超过一定角度后,游戏重置。对于正在运行的每个帧,模拟返回 1.0 的奖励。游戏运行的时间越长,获得的奖励就越多。因此,我们的网络的目标是通过保持杆垂直来最大化奖励。它将通过向左和向右移动推车来完成此操作。
针对 Cart-Pole 问题的深度 Q 网络
我们使用 Bellman 方程再次训练我们的 Q 学习智能体:
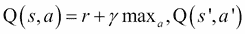
这里,s是状态,a是动作,s'是状态s和动作a的下一个状态。
之前,我们使用这个等式来学习 Q 表的值。但是,这个游戏有很多状态可供使用。状态有四个值:推车的位置和速度,以及杆的位置和速度。这些都是实数值,所以如果我们忽略浮点精度,我们实际上有无限状态。然后,我们将用一个近似于 Q 表查找功能的神经网络替换它,而不是使用表格。
通过将状态传递到网络来计算 Q 值,而输出将是每个可用动作的 Q 值,具有完全连接的隐藏层:
图 7:深度 Q-Learning
在这个 Cart-Pole 游戏中,我们有四个输入,一个用于状态中的每个值;和两个输出,每个动作一个。网络权重更新将通过选择动作并使用所选动作模拟游戏来进行。这将把我们带到下一个状态然后再到奖励。
以下是用于解决 Cart-Pole 问题的神经网络的简短代码片段:
import tensorflow as tf
class DQNetwork:
def __init__(self,\
learning_rate=0.01, \
state_size=4,\
action_size=2, \
hidden_size=10,\
name='DQNetwork'):
隐藏层由两个完全连接的层组成,具有 ReLU 激活:
self.fc1 =tf.contrib.layers.fully_connected\
(self.inputs_,\
hidden_size)
self.fc2 = tf.contrib.layers.fully_connected\
(self.fc1,\
hidden_size)
输出层是线性输出层:
self.output = tf.contrib.layers.fully_connected\
(self.fc2,\
action_size,activation_fn=None)
经验重放方法
近似函数可能会受到非独立且相同分布和非平稳数据(状态之间的相关性)的影响。
使用经验重放方法可以克服这种问题。
在智能体和环境之间的交互过程中,所有经验(state,action,reward和next_state)都保存在重放内存中,这是固定大小的内存并以先进先出(FIFO)的方式运行。
这是重放内存类的实现:
from collections import deque
import numpy as np
class replayMemory():
def __init__(self, max_size = 1000):
self.buffer = \
deque(maxlen=max_size)
def build(self, experience):
self.buffer.append(experience)
def sample(self, batch_size):
idx = np.random.choice\
(np.arange(len(self.buffer)),
size=batch_size,
replace=False)
return [self.buffer[ii] for ii in idx]
这将允许在网络训练期间使用在重放存储器中随机获取的小批量经验,而不是一个接一个地使用最近的经验。
使用经验重放方法有助于缓解顺序训练数据的问题,这可能导致算法保持在局部最小值,从而使其无法获得最佳解决方案。
利用和探索
每当智能体必须选择要采取的行动时,它基本上有两种方式可以执行其策略。第一种模式称为利用,包括根据目前获得的信息,即过去和存储的经验,做出最佳决策。此信息始终作为值函数提供,该函数表示哪个操作为每个状态 - 操作对提供最大的最终累积回报。
第二种模式称为探索,它是一种决策策略,不同于目前认为最优的策略。
探索阶段非常重要,因为它用于收集未探测状态的信息。实际上,只有执行最佳操作的智能体才有可能始终遵循相同的操作顺序,而没有机会探索并发现可能存在从长远来看可能导致的策略更好的结果,即使这意味着立即获得的收益更低。
最常用于在利用和探索之间达成正确妥协的策略是贪婪的策略。它代表了一种选择动作的方法,基于使用均匀概率分布来选择随机动作的可能性。
深度 Q-Learning 训练算法
让我们看看如何构建一个深度 Q-Learning 算法来解决 Cart-Pole 问题。
该项目相当复杂。为此原因。它已被细分为几个文件模块:
DQNetwork.py:实现深度神经网络memory.py:实现经验重放方法start_simulation.py:创建我们想要解决的 Cart-Pole 环境solve_cart_pole.py:用经过训练的神经网络解决 Cart-Pole 环境plot_result_DQN.py:绘制最后的奖励与剧集deepQlearning.py:主程序
以下命令提供了deepQlearning.py文件实现的简要说明:
import tensorflow as tf
import gym
import numpy as np
import time
import os
from create_cart_pole_env import *
from DQNetwork import *
from memory import *
from solve_cart_pole import *
from plot_result_DQN import *
接下来要做的是定义用于此实现的超参数,因此我们需要定义要学习的最大剧集数,一集中的最大步数以及未来的奖励折扣:
train_episodes = 1000
max_steps = 200
gamma = 0.99
探索参数是探索开始时的探索概率,最小探索概率和探索概率的指数衰减率:
explore_start = 1.0
explore_stop = 0.01
decay_rate = 0.0001
网络参数是每个隐藏 Q 网络层中的单元数和 Q 网络学习率:
hidden_size = 64
learning_rate = 0.0001
定义以下内存参数:
memory_size = 10000
batch_size = 20
然后我们有大量的经验来预先记录内存:
pretrain_length = batch_size
现在我们可以创建环境并启动 Cart-Pole 模拟:
env = gym.make('CartPole-v0')
start_simulation(env)
接下来,我们使用hidden_size和learning_rate超参数实例化 DNN:
tf.reset_default_graph()
deepQN = DQNetwork(name='main', hidden_size=64, \
learning_rate=0.0001)
最后,我们重新初始化模拟:
env.reset()
让我们采取随机步骤,从中我们可以获得状态和奖励:
state, rew, done, _ = env.step(env.action_space.sample())
实例化replayMemory对象以实现经验重放方法:
memory = replayMemory(max_size=10000)
使用memory.build方法获取随机动作的块,来存储相对经验,状态和动作:
pretrain_length= 20
for j in range(pretrain_length):
action = env.action_space.sample()
next_state, rew, done, _ = \
env.step(env.action_space.sample())
if done:
env.reset()
memory.build((state,\
action,\
rew,\
np.zeros(state.shape)))
state, rew, done, _ = \
env.step(env.action_space.sample())
else:
memory.build((state, action, rew, next_state))
state = next_state
通过获得的新经验,我们可以进行神经网络的训练:
rew_list = []
train_episodes = 100
max_steps=200
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
step = 0
for ep in range(1, train_episodes):
tot_rew = 0
t = 0
while t < max_steps:
step += 1
explore_p = stop_exp + (start_exp - stop_exp)*\
np.exp(-decay_rate*step)
if explore_p > np.random.rand():
action = env.action_space.sample()
else:
然后我们计算 Q 状态:
Qs = sess.run(deepQN.output, \
feed_dict={deepQN.inputs_: \
state.reshape\
((1, *state.shape))})
我们现在可以获得动作:
action = np.argmax(Qs)
next_state, rew, done, _ = env.step(action)
tot_rew += rew
if done:
next_state = np.zeros(state.shape)
t = max_steps
print('Episode: {}'.format(ep),
'Total rew: {}'.format(tot_rew),
'Training loss: {:.4f}'.format(loss),
'Explore P: {:.4f}'.format(explore_p))
rew_list.append((ep, tot_rew))
memory.build((state, action, rew, next_state))
env.reset()
state, rew, done, _ = env.step\
(env.action_space.sample())
else:
memory.build((state, action, rew, next_state))
state = next_state
t += 1
batch_size = pretrain_length
states = np.array([item[0] for item \
in memory.sample(batch_size)])
actions = np.array([item[1] for item \
in memory.sample(batch_size)])
rews = np.array([item[2] for item in \
memory.sample(batch_size)])
next_states = np.array([item[3] for item\
in memory.sample(batch_size)])
最后,我们开始训练智能体。训练很慢,因为它渲染的帧比网络可以训练的慢:
target_Qs = sess.run(deepQN.output, \
feed_dict=\
{deepQN.inputs_: next_states})
target_Qs[(next_states == \
np.zeros(states[0].shape))\
.all(axis=1)] = (0, 0)
targets = rews + 0.99 * np.max(target_Qs, axis=1)
loss, _ = sess.run([deepQN.loss, deepQN.opt],
feed_dict={deepQN.inputs_: states,
deepQN.targetQs_: targets,
deepQN.actions_: actions})
env = gym.make('CartPole-v0')
要测试模型,我们调用以下函数:
solve_cart_pole(env,deepQN,state,sess)
plot_result(rew_list)
这里是用于测试购物车杆问题的神经网络实现:
import numpy as np
def solve_cart_pole(env,dQN,state,sess):
test_episodes = 10
test_max_steps = 400
env.reset()
for ep in range(1, test_episodes):
t = 0
while t < test_max_steps:
env.render()
Qs = sess.run(dQN.output, \
feed_dict={dQN.inputs_: state.reshape\
((1, *state.shape))})
action = np.argmax(Qs)
next_state, reward, done, _ = env.step(action)
if done:
t = test_max_steps
env.reset()
state, reward, done, _ =
env.step(env.action_space.sample())
else:
state = next_state
t += 1
最后,如果我们运行deepQlearning.py脚本,我们应该得到这样的结果:
[2017-12-03 10:20:43,915] Making new env: CartPole-v0
[]
Episode: 1 Total reward: 7.0 Training loss: 1.1949 Explore P: 0.9993
Episode: 2 Total reward: 21.0 Training loss: 1.1786 Explore P: 0.9972
Episode: 3 Total reward: 38.0 Training loss: 1.1868 Explore P: 0.9935
Episode: 4 Total reward: 8.0 Training loss: 1.3752 Explore P: 0.9927
Episode: 5 Total reward: 9.0 Training loss: 1.6286 Explore P: 0.9918
Episode: 6 Total reward: 32.0 Training loss: 1.4313 Explore P: 0.9887
Episode: 7 Total reward: 19.0 Training loss: 1.2806 Explore P: 0.9868
……
Episode: 581 Total reward: 47.0 Training loss: 0.9959 Explore P: 0.1844
Episode: 582 Total reward: 133.0 Training loss: 21.3187 Explore P: 0.1821
Episode: 583 Total reward: 54.0 Training loss: 42.5041 Explore P: 0.1812
Episode: 584 Total reward: 95.0 Training loss: 1.5211 Explore P: 0.1795
Episode: 585 Total reward: 52.0 Training loss: 1.3615 Explore P: 0.1787
Episode: 586 Total reward: 78.0 Training loss: 1.1606 Explore P: 0.1774
…….
Episode: 984 Total reward: 199.0 Training loss: 0.2630 Explore P: 0.0103
Episode: 985 Total reward: 199.0 Training loss: 0.3037 Explore P: 0.0103
Episode: 986 Total reward: 199.0 Training loss: 256.8498 Explore P: 0.0103
Episode: 987 Total reward: 199.0 Training loss: 0.2177 Explore P: 0.0103
Episode: 988 Total reward: 199.0 Training loss: 0.3051 Explore P: 0.0103
Episode: 989 Total reward: 199.0 Training loss: 218.1568 Explore P: 0.0103
Episode: 990 Total reward: 199.0 Training loss: 0.1679 Explore P: 0.0103
Episode: 991 Total reward: 199.0 Training loss: 0.2048 Explore P: 0.0103
Episode: 992 Total reward: 199.0 Training loss: 0.4215 Explore P: 0.0102
Episode: 993 Total reward: 199.0 Training loss: 0.2133 Explore P: 0.0102
Episode: 994 Total reward: 199.0 Training loss: 0.1836 Explore P: 0.0102
Episode: 995 Total reward: 199.0 Training loss: 0.1656 Explore P: 0.0102
Episode: 996 Total reward: 199.0 Training loss: 0.2620 Explore P: 0.0102
Episode: 997 Total reward: 199.0 Training loss: 0.2358 Explore P: 0.0102
Episode: 998 Total reward: 199.0 Training loss: 0.4601 Explore P: 0.0102
Episode: 999 Total reward: 199.0 Training loss: 0.2845 Explore P: 0.0102
[2017-12-03 10:23:43,770] Making new env: CartPole-v0
>>>
随着训练损失减少,总奖励增加。
在测试期间,推车杆完美平衡:
图 8:解决了 Cart-Pole 问题
为了可视化训练,我们使用了plot_result()函数(它在plot_result_DQN.py函数中定义)。
plot_result()函数绘制每集的总奖励:
def plot_result(rew_list):
eps, rews = np.array(rew_list).T
smoothed_rews = running_mean(rews, 10)
smoothed_rews = running_mean(rews, 10)
plt.plot(eps[-len(smoothed_rews):], smoothed_rews)
plt.plot(eps, rews, color='grey', alpha=0.3)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.show()
以下绘图显示,每个事件的总奖励随着智能体改进其对值函数的估计而增加:

总结
许多研究人员认为,RL 是我们创造人工智能的最好方法。这是一个令人兴奋的领域,有许多未解决的挑战和巨大的潜力。虽然一开始看起来很有挑战性,但开始使用 RL 并不是那么困难。在本章中,我们描述了 RL 的一些基本原理。
我们讨论的主要内容是 Q-Learning 算法。它的显着特点是能够在即时奖励和延迟奖励之间做出选择。最简单的 Q-learning 使用表来存储数据。当监视/控制的系统的状态/动作空间的大小增加时,这很快就失去了可行性。
我们可以使用神经网络作为函数逼近器来克服这个问题,该函数逼近器将状态和动作作为输入并输出相应的 Q 值。
按照这个想法,我们使用 TensorFlow 框架和 OpenAI Gym 工具包实现了一个 Q 学习神经网络,以赢得 FrozenLake 游戏。
在本章的最后一部分,我们介绍了深度强化学习。在传统的 RL 中,问题空间非常有限,并且环境中只有少数可能的状态。这是传统方法的主要局限之一。多年来,已经有一些相对成功的方法能够通过近似状态来处理更大的状态空间。
深度学习算法的进步已经在 RL 中引入了新的成功应用浪潮,因为它提供了有效处理高维输入数据(例如图像)的机会。在这种情况下,训练有素的 DNN 可以被视为一种端到端的 RL 方法,其中智能体可以直接从其输入数据中学习状态抽象和策略近似。按照这种方法,我们实现了 DNN 来解决 Cart-Pole 问题。
我们的 TensorFlow 深度学习之旅将在此结束。深度学习是一个非常有成效的研究领域;有许多书籍,课程和在线资源可以帮助读者深入理论和编程。此外,TensorFlow 还提供了丰富的工具来处理深度学习模型。我希望本书的读者成为 TensorFlow 社区的一部分,该社区非常活跃,并希望热心人士尽快加入。