Java 正则表达式
🍓 简介:java系列技术分享(👉持续更新中…🔥)
🍓 初衷:一起学习、一起进步、坚持不懈
🍓 如果文章内容有误与您的想法不一致,欢迎大家在评论区指正🙏
🍓 希望这篇文章对你有所帮助,欢迎点赞 👍 收藏 ⭐留言 📝🍓 更多文章请点击

文章目录
- 前言
- 一、概述
- 二、基础正则表达式速查表
- 2.1 字符
- 2.2 分组与引用
- 2.3 锚点/边界
- 2.4 数量表示
- 2.5 预查断言
- 2.6 特殊标志
- 2.7 反义
- 三、正则表达式可视化界面
- 四、java正则表达式
- 4.1 注意事项
- 4.2 使用示例
- 五、贪婪和非贪婪
- 5.1 贪婪匹配
- 5.2 懒惰匹配

)
前言
我们可能有如下的需求:
从一个文章里找到所有的邮箱看看输入的手机号是不是符合手机号的规则检查输入的是不是身份证号
对于这种需要,都要求对字符串进行特定【模式或规则】的匹配
一、概述
正则表达式,又称规则表达式(Regular Expression,在代码中常简写为regex、regexp或RE),是一种【文本模式(Pattern)】。正则表达式使用单个字符串来描述、匹配具有相同规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式的核心功能就是处理文本。正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别。
二、基础正则表达式速查表
借鉴文档:https://www.r2coding.com
2.1 字符
| 表达式 | 描述 |
|---|---|
[abc] | 字符集。匹配集合中所含的任一字符。 |
[^abc] | 否定字符集。匹配任何不在集合中的字符。 |
[a-z] | 字符范围。匹配指定范围内的任意字符。 |
. | 匹配除换行符以外的任何单个字符。 |
\ | 转义字符。 |
\w | 匹配任何字母数字,包括下划线(等价于[A-Za-z0-9_])。 |
\W | 匹配任何非字母数字(等价于[^A-Za-z0-9_])。 |
\d | 数字。匹配任何数字。 |
\D | 非数字。匹配任何非数字字符。 |
\s | 空白。匹配任何空白字符,包括空格、制表符等。 |
\S | 非空白。匹配任何非空白字符。 |
2.2 分组与引用
| 表达式 | 描述 |
|---|---|
(expression) | 分组。匹配括号里的整个表达式。 |
(?:expression) | 非捕获分组。匹配括号里的整个字符串但不获取匹配结果,拿不到分组引用。 |
\num | 对前面所匹配分组的引用。比如(\d)\1可以匹配两个相同的数字,(Code)(Sheep)\1\2则可以匹配CodeSheepCodeSheep |
2.3 锚点/边界
| 表达式 | 描述 |
|---|---|
^ | 匹配字符串或行开头。 |
$ | 匹配字符串或行结尾。 |
\b | 匹配单词边界。比如Sheep\b可以匹配CodeSheep末尾的Sheep,不能匹配CodeSheepCode中的Sheep |
\B | 匹配非单词边界。比如Code\B可以匹配HelloCodeSheep中的Code,不能匹配HelloCode中的Code。 |
2.4 数量表示
| 表达式 | 描述 |
|---|---|
? | 匹配前面的表达式0个或1个。即表示可选项。 |
+ | 匹配前面的表达式至少1个。 |
* | 匹配前面的表达式0个或多个。 |
| ` | ` |
{m} | 匹配前面的表达式m个。 |
{m,} | 匹配前面的表达式最少m个。 |
{m,n} | 匹配前面的表达式最少m个,最多n个。 |
2.5 预查断言
| 表达式 | 描述 |
|---|---|
(?=) | 正向预查。比如Code(?=Sheep)能匹配CodeSheep中的Code,但不能匹配CodePig中的Code。 |
(?!) | 正向否定预查。比如Code(?!Sheep)不能匹配CodeSheep中的Code,但能匹配CodePig中的Code。 |
(?<=) | 反向预查。比如(?<=Code)Sheep能匹配CodeSheep中的Sheep,但不能匹配ReadSheep中的Sheep。 |
(?<!) | 反向否定预查。比如(?<!Code)Sheep不能匹配CodeSheep中的Sheep,但能匹配ReadSheep中的Sheep。 |
2.6 特殊标志
| 表达式 | 描述 |
|---|---|
/.../i | 忽略大小写。 |
/.../g | 全局匹配。 |
/.../m | 多行修饰符。用于多行匹配。 |
2.7 反义
| 表达式 | 描述 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
三、正则表达式可视化界面
界面地址1: https://jex.im/regulex/#!flags=&re=%5E(a%7Cb)*%3F%24
界面地址2: http://tools.jb51.net/regex/create_reg
四、java正则表达式
4.1 注意事项
-
有些语言中,\ 表示:我就是一个普通的【反斜杠】,请不要给我任何特殊的意义。
-
在 Java 中,\ 表示:我不是一个普通的【反斜杠】,我必须对紧随其后的字符进行转义,如果想将我视为普通反斜杠,请转义我。
执行流程
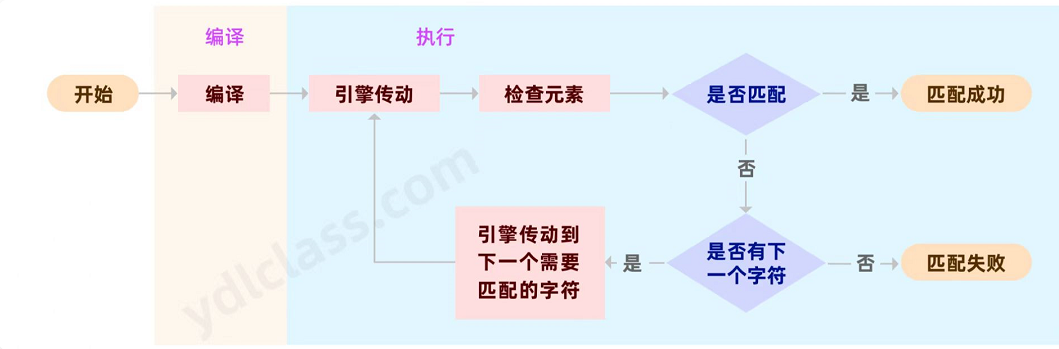
java.util.regex包主要包括以下三个类:
Pattern 类:正则表达式的编译表示形式。若要使用正则表达式必须将其【编译到此类】的实例中。然后,可以使用生成的模式对象创建 Matcher 对象。
Matcher 类:Matcher 对象是对输入字符串进行【解释和匹配】操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
4.2 使用示例
/**
*
* 正则表达式
*/
public class TestRegex {
@Test
public void testRegex1(){
String content = "I am itnanls,I'm from ydlclass.";
String pattern = ".*itnanls.*";
boolean isMatch = Pattern.matches(pattern, content);
System.out.println("字符串中是否包含了 'itnanls' 子字符串? " + isMatch);
}
@Test
public void testRegex2(){
String context = "i am itnanls,i com from ydl.";
String regex = ".*itnanls.*";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
System.out.println(matcher.matches());
}
@Test
public void testRegex3(){
String regex = "cat";
String content = "cat cat dog dog cat";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(content); // 获取 matcher 对象
int count = 0;
while (m.find()) {
count++;
System.out.println("Match number " + count);
System.out.println("start(): " + m.start());
System.out.println("end(): " + m.end());
}
}
@Test
public void testRegex4() {
String regex = "itnanls";
String content1 = "itnanls";
String content2 = "itnanls is very handsome !";
String content3 = "My name is itnanls.";
Pattern pattern = Pattern.compile(regex);
Matcher matcher1 = pattern.matcher(content1);
Matcher matcher2 = pattern.matcher(content2);
Matcher matcher3 = pattern.matcher(content3);
System.out.println("matches1(): " + matcher1.matches());
System.out.println("lookingAt1(): " + matcher1.lookingAt());
System.out.println("matches2(): " + matcher2.matches());
System.out.println("lookingAt2(): " + matcher2.lookingAt());
System.out.println("matches3(): " + matcher3.matches());
System.out.println("lookingAt3(): " + matcher3.lookingAt());
}
@Test
public void testReplace(){
String regex = "itnanls";
String context = "My name is itnanls, itnanls is very handsome. ";
String replacement = "itlils";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(context);
String result1 = m.replaceAll(replacement);
System.out.println(result1);
String result2 = m.replaceFirst(replacement);
System.out.println(result2);
}
@Test
public void testAppend() {
String REGEX = "a*b";
String INPUT = "aabfooaabfooabfooabkkk";
String REPLACE = "-";
Pattern p = Pattern.compile(REGEX);
// 获取 matcher 对象
Matcher m = p.matcher(INPUT);
StringBuffer sb = new StringBuffer();
m.find();
m.appendReplacement(sb, REPLACE);
System.out.println(sb);
m.find();
m.appendReplacement(sb, REPLACE);
System.out.println(sb);
m.appendTail(sb);
System.out.println(sb);
}
@Test
public void testAppend2() {
String regex = "a*b";
String context = "aabfooaabfooabfoobkkk";
String replacement = "-";
Pattern pattern = Pattern.compile(regex);
// 获取 matcher 对象
Matcher matcher = pattern.matcher(context);
StringBuffer sb = new StringBuffer();
while (matcher.find()){
matcher.appendReplacement(sb, replacement);
}
matcher.appendTail(sb);
System.out.println(sb);
}
@Test
public void testRegex5() {
String test = "020-85653333";
String reg="(0\\d{2})-(\\d{8})";
Pattern pattern = Pattern.compile(reg);
Matcher mc= pattern.matcher(test);
if(mc.find()){
System.out.println("分组的个数有:"+mc.groupCount());
for(int i=0;i<=mc.groupCount();i++){
System.out.println("第"+i+"个分组为:"+mc.group(i));
}
}
}
@Test
public void testRegex6() {
String test = "020-85653333";
String reg = "(?<quhao>0\\d{2})-(?<haoma>\\d{8})";
Pattern pattern = Pattern.compile(reg);
Matcher mc = pattern.matcher(test);
if (mc.find()) {
System.out.println("分组的个数有:" + mc.groupCount());
System.out.println(mc.group("quhao"));
System.out.println(mc.group("haoma"));
}
}
/**
* aa bb cc 成对的都匹配出来
*/
@Test
public void testRegex7() {
String context = "aaabbxxccdddsksdhfhshh";
String regex = "(\\w)\\1";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while (matcher.find()){
System.out.println(matcher.group());
}
}
@Test
public void testRegex8() {
String regex = "\\d{3,6}";
String context ="61762828 176 2991 871";
System.out.println("文本:" + context);
System.out.println("贪婪模式:"+ regex);
Pattern pattern =Pattern.compile(regex);
Matcher matcher = pattern.matcher(context);
while(matcher.find()){
System.out.println("匹配结果:" + matcher.group(0));
}
}
@Test
public void testRegex9() {
String reg="(\\d{1,2}?)(\\d{3,4})";
String test="61762828 176 2991 87321";
System.out.println("文本:"+test);
System.out.println("贪婪模式:"+reg);
Pattern p1 =Pattern.compile(reg);
Matcher m1 = p1.matcher(test);
while(m1.find()){
System.out.println("匹配结果:"+m1.group(0));
}
}
@Test
public void testRegex10() {
}
@Test
public void findEmail() throws IOException {
StringBuilder sb = new StringBuilder();
// 1、将文件的内容读取到内存
InputStream in = new FileInputStream("D:\\user.txt");
byte[] buf = new byte[1024];
int len;
while ((len = in.read(buf)) > 0){
sb.append(new String(buf,0,len));
}
// 2、进行正则匹配
String regex = "[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(sb.toString());
while (matcher.find()){
System.out.println(matcher.group());
}
}
@Test
public void hidePhoneNumber() throws IOException {
StringBuilder sb = new StringBuilder();
// 1、将文件的内容读取到内存
InputStream in = new FileInputStream("D:\\user.txt");
byte[] buf = new byte[1024];
int len;
while ((len = in.read(buf)) > 0){
sb.append(new String(buf,0,len));
}
// 2、进行正则匹配
String regex = "(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])(\\d{4})(\\d{4})";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(sb.toString());
String result = matcher.replaceAll("$1xxxx$3");
System.out.println(result);
}
@Test
public void hidePhoneNumber2() throws IOException {
StringBuilder sb = new StringBuilder();
// 1、将文件的内容读取到内存
InputStream in = new FileInputStream("D:\\user.txt");
byte[] buf = new byte[1024];
int len;
while ((len = in.read(buf)) > 0){
sb.append(new String(buf,0,len));
}
String result = sb.toString().replaceAll("(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])(\\d{4})(\\d{4})", "$1xxxx$3");
System.out.println(result);
}
}
五、贪婪和非贪婪
5.1 贪婪匹配
贪婪匹配: 当正则表达式中包含能接受重复的限定符时,该方式会匹配尽可能多的字符,这匹配方式叫做贪婪匹配。
.*:表示匹配换行符\n之外的任何单字符,*表示零次或多次,所以.*在一起就表示任意字符出现零次或多次。没有?就是贪婪模式。- 比如表达式:\d{3,6}。用来匹配3到6位数字,在这种情况下,它是一种贪婪模式的匹配,也就是假如字符串里有6个数字可以匹配,那它就是全部匹配到。
5.2 懒惰匹配
懒惰匹配:当正则表达式中包含能接受重复的限定符时,会匹配尽可能少的字符,这匹配方式叫做懒惰匹配。
| 代码 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
![]()
