Spark SQL概述与基本操作
目录
一、Spark SQL概述
(1)概念
(2)特点
(3)Spark SQL与Hive异同
(4)Spark的数据抽象
二、Spark Session对象执行环境构建
(1)Spark Session对象
(2)代码演示
三、DataFrame创建
(1)DataFrame组成
(2)DataFrame创建方式(转换)
(3)DataFrame创建方式(标准API读取)
四、DataFrame编程
(1)DSL语法风格
(2)SQL语法风格
五、Spark SQL——wordcount代码示例
(1)pyspark.sql.functions包
(2)代码示例
一、Spark SQL概述
(1)概念
Spark SQL是Apache Spark的一个模块,它用于处理结构化和半结构化的数据。Spark SQL允许用户使用SQL查询和操作数据,这种操作可以直接在Spark的DataFrame/Dataset API中进行。此外,Spark SQL还支持多种语言,包括Scala、Java、Python和R。
(2)特点
①融合性:SQL可以无缝集成在代码中,随时用SQL处理数据。
②统一数据访问:一套标准API可读写不同的数据源。
③Hive兼容:可以使用Spark SQL直接计算生成Hive数据表。
④标准化连接:支持标准化JDBC \ ODBC连接,方便和各种数据库进行数据交互。
(3)Spark SQL与Hive异同
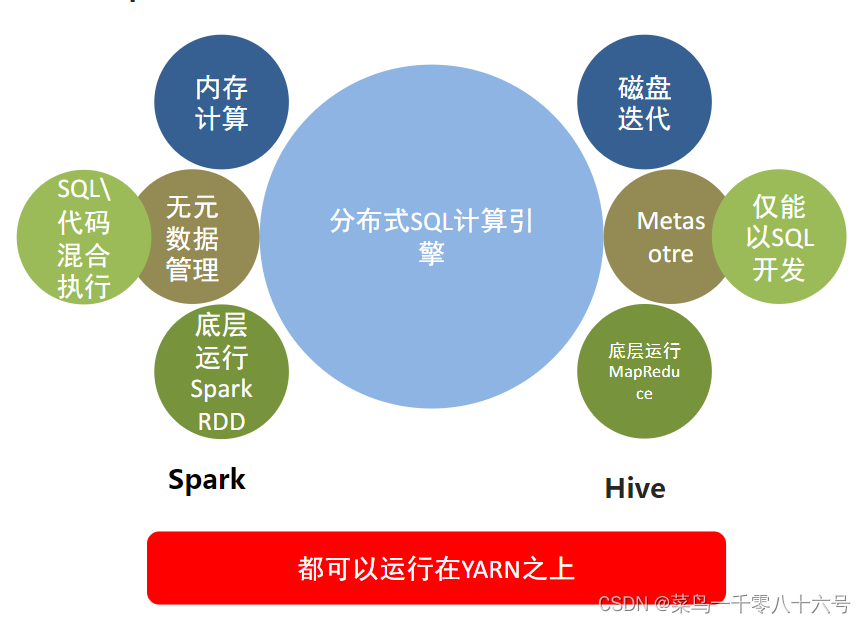
共同点:Hive和Spark均是:“分布式SQL计算引擎”,均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。
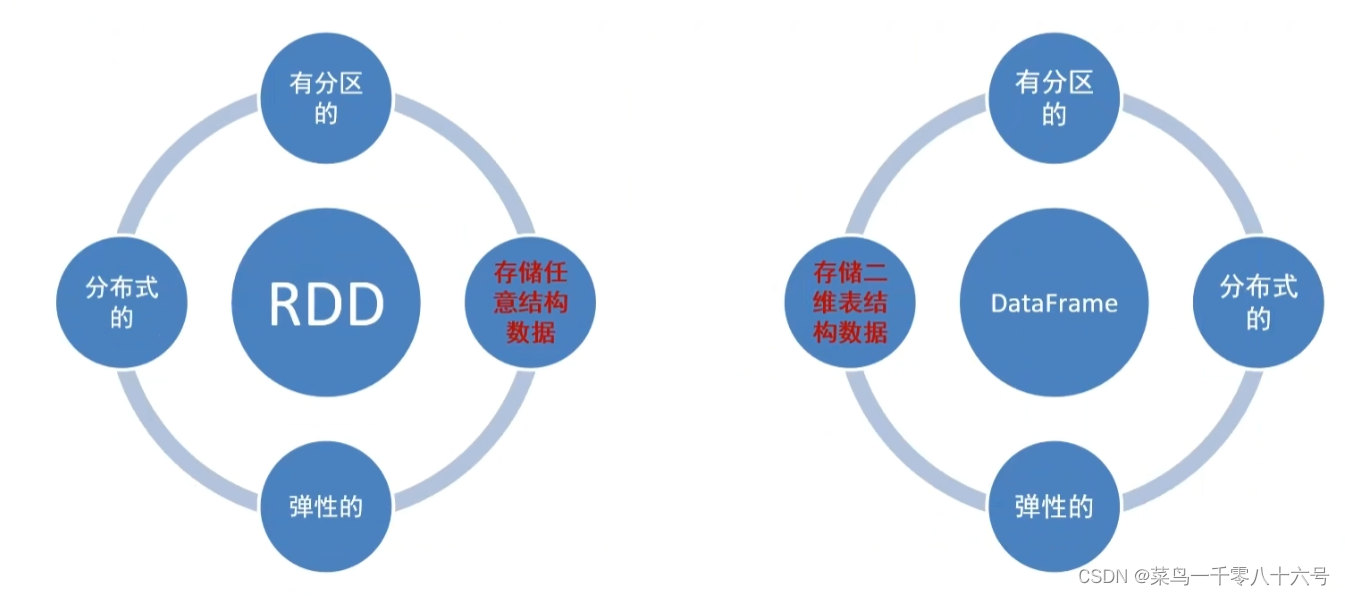
(4)Spark的数据抽象

Spark SQL的数据抽象:

Data Frame与RDD:
二、Spark Session对象执行环境构建
(1)Spark Session对象
在RDD阶段,程序的执行入口对象是:SparkContext。在Spark 2.0后,推出了SparkSession对象,作为Spark编码的统一入口对象。
Spark Session对象作用:
①用于SparkSQL编程作为入口对象。
②用于SparkCore编程,可以通过Spark Session对象中获取到Spark Context。
(2)代码演示
# cording:utf8
# Spark Session对象的导包,对象是来自于pyspark.sql包中
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 构建Spark Session执行环境入口对象
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
# 通过Spark Session对象 获取SparkContext对象
sc = spark.sparkContext
# SparkSQL测试
df = spark.read.csv('../input/stu_score.txt', sep=',', header=False)
df2 = df.toDF('id', 'name', 'score')
# 打印表结构
# df2.printSchema()
# 打印数据内容
# df2.show()
df2.createTempView('score')
# SQL风格
spark.sql("""SELECT * FROM score WHERE name='语文' LIMIT 5
""").show()
# DSL 风格
df2.where("name='语文'").limit(5).show()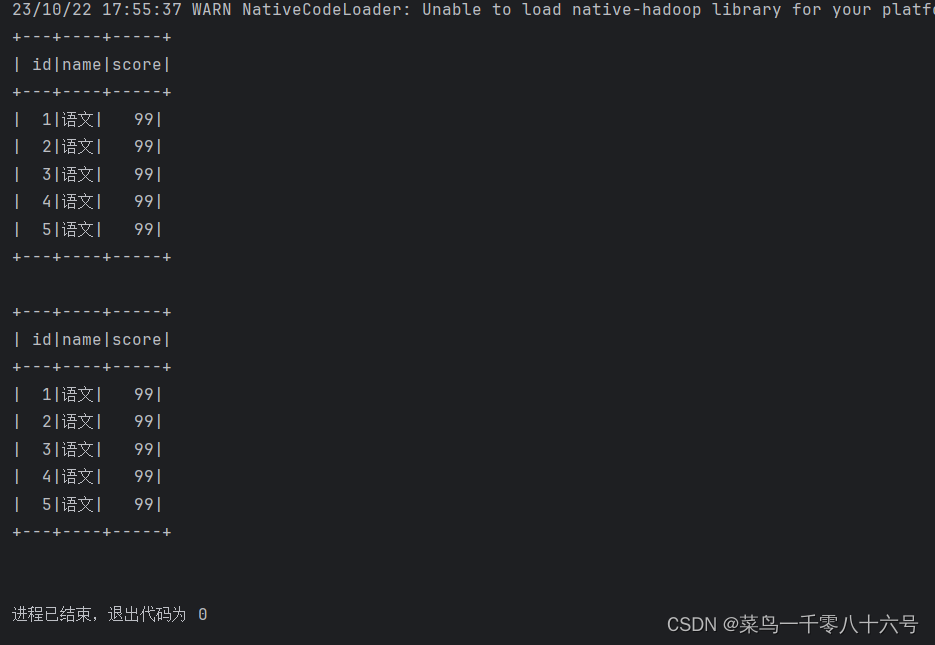
三、DataFrame创建
(1)DataFrame组成
DataFrame是一个二维表结构,表格结构的组成:
①行
②列
③表结构描述
比如,在MySQL中的一个表:
①有许多列组成
②数据也被分为多个列
③表也有表结构信息(列、列名、列类型、列约束等)
基于这个前提下,DataFrame的组成如下:
在结构层面:
①StructType对象描述整个DataFrame的表结构
②StructField对象描述一个列的信息
在数据层面:
①Row对象记录一行数据
②Column对象记录一列数据并包含列的信息

(2)DataFrame创建方式(转换)
①基于RDD方式
# cording:utf8
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 构建执行环境对象Spark Session
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
# 构建SparkContext
sc = spark.sparkContext
# 基于RDD转换为DataFrame
rdd = sc.textFile('../input/people.txt').\
map(lambda x: x.split(',')).\
map(lambda x: (x[0], int(x[1])))
# 构建DataFrame对象
# 参数1,被转换的RDD
# 参数2,指定列名,通过list的形式指定,按照顺序依次提供字符串名称即可
df = spark.createDataFrame(rdd,schema=['name', 'age'])
# 打印Data Frame的表结构
df.printSchema()
# 打印df中的数据
# 参数1,表示 展示出多少条数据,默认不传的话是20
# 参数2,表示是否对列进行截断,如果列的数据长度超过20个字符串长度,厚旬欸日不显示,以....代替
# 如果给False 表示不截断全部显示,默认是True
df.show(20,False)
# 将DF对象转换成临时视图表,可供sql语句查询
df.createOrReplaceTempView('people')
spark.sql('SELECT * FROM people WHERE age < 30').show()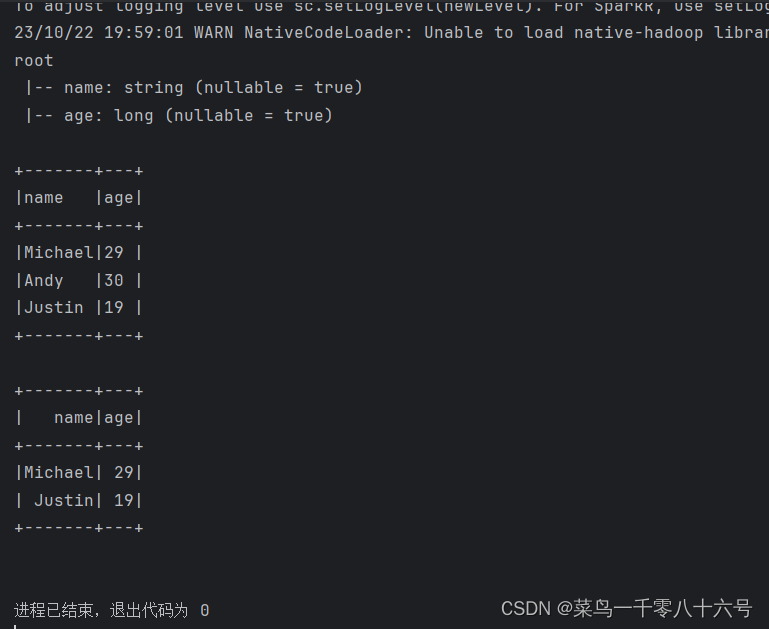
②通过StructType对象来定义DataFrame的 ‘ 表结构 ’ 转换RDD
# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType
if __name__ == '__main__':
# 构建执行环境对象Spark Session
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
# 构建SparkContext
sc = spark.sparkContext
# 基于RDD转换为DataFrame
rdd = sc.textFile('../input/people.txt').\
map(lambda x: x.split(',')).\
map(lambda x: (x[0], int(x[1])))
# 构建表结构的描述对象:StructType 对象
# 参数1,列名
# 参数2,列数据类型
# 参数3,是否允许为空
schema = StructType().add('name', StringType(), nullable=True).\
add('age', IntegerType(), nullable=False)
# 构建DataFrame对象
# 参数1,被转换的RDD
# 参数2,指定列名,通过list的形式指定,按照顺序依次提供字符串名称即可
df = spark.createDataFrame(rdd, schema=schema)
df.printSchema()
df.show()

③通过RDD的toDF方法创建RDD
# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType
if __name__ == '__main__':
# 构建执行环境对象Spark Session
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
# 构建SparkContext
sc = spark.sparkContext
# 基于RDD转换为DataFrame
rdd = sc.textFile('../input/people.txt').\
map(lambda x: x.split(',')).\
map(lambda x: (x[0], int(x[1])))
# toDF构建DataFrame
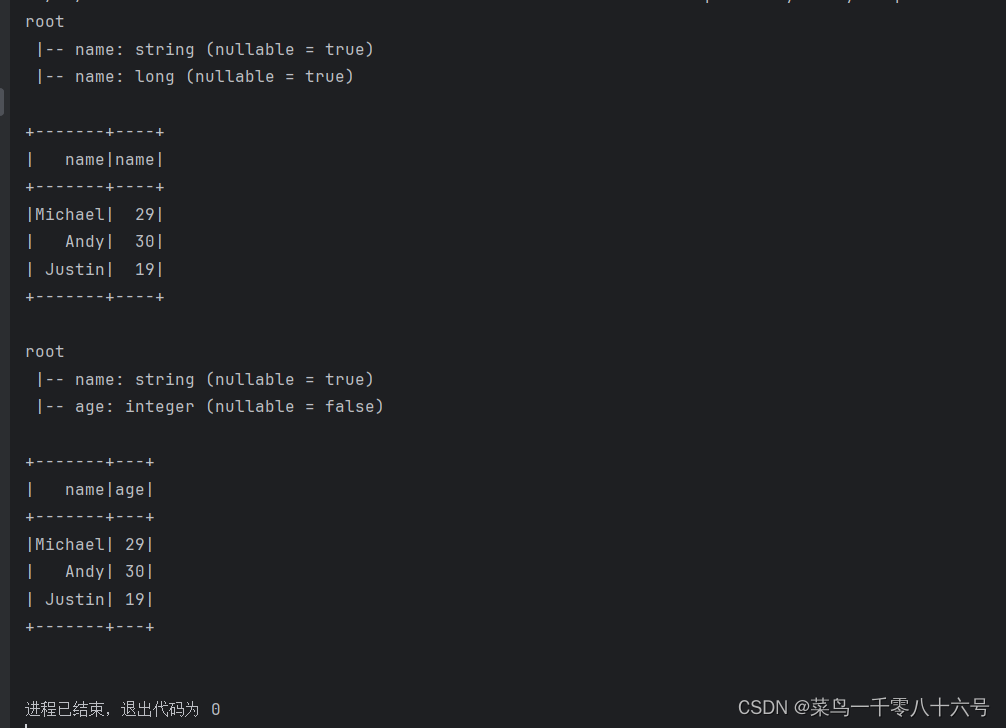
# 第一种构建方式,只能设置列名,列类型靠RDD推断,默认允许为空
df1 = rdd.toDF(['name', 'name'])
df1.printSchema()
df1.show()
# toDF方式2:通过StructType来构造
# 设置全面,能设置列名、列数据类型、是否为空
# 构建表结构的描述对象:StructType 对象
# 参数1,列名
# 参数2,列数据类型
# 参数3,是否允许为空
schema = StructType().add('name', StringType(), nullable=True).\
add('age', IntegerType(), nullable=False)
df2 = rdd.toDF(schema=schema)
df2.printSchema()
df2.show()
④基于Pandas的DataFrame创建DataFrame
# cording:utf8
from pyspark.sql import SparkSession
import pandas as pd
if __name__ == '__main__':
# 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
# 基于pandas的DataFrame构建SparkSQL的DataFrame对象
pdf = pd.DataFrame(
{
'id': [1, 2, 3],
'name': ['张大仙', '王晓晓', '吕不韦'],
'age': [1, 2, 3]
}
)
df = spark.createDataFrame(pdf)
df.printSchema()
df.show()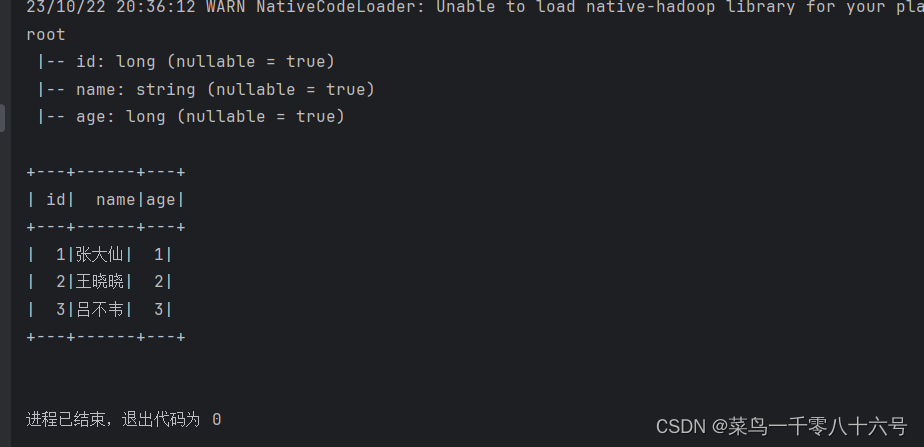
(3)DataFrame创建方式(标准API读取)
统一API示例代码:

①读取本地text文件
# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType
if __name__ == '__main__':
# 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
# 构建StructType,text数据源,
# text读取数据的特点是:将一整行只作为一个列读取,默认列名是value 类型是String
schema = StructType().add('data', StringType(),nullable=True)
df = spark.read.format('text').\
schema(schema=schema).\
load('../input/people.txt')
df.printSchema()
df.show()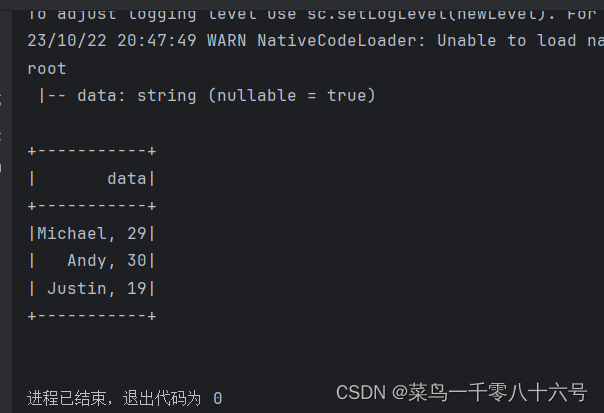
②读取json文件
# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType
if __name__ == '__main__':
# 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
# json文件类型自带Schema信息
df = spark.read.format('json').load('../input/people.json')
df.printSchema()
df.show()
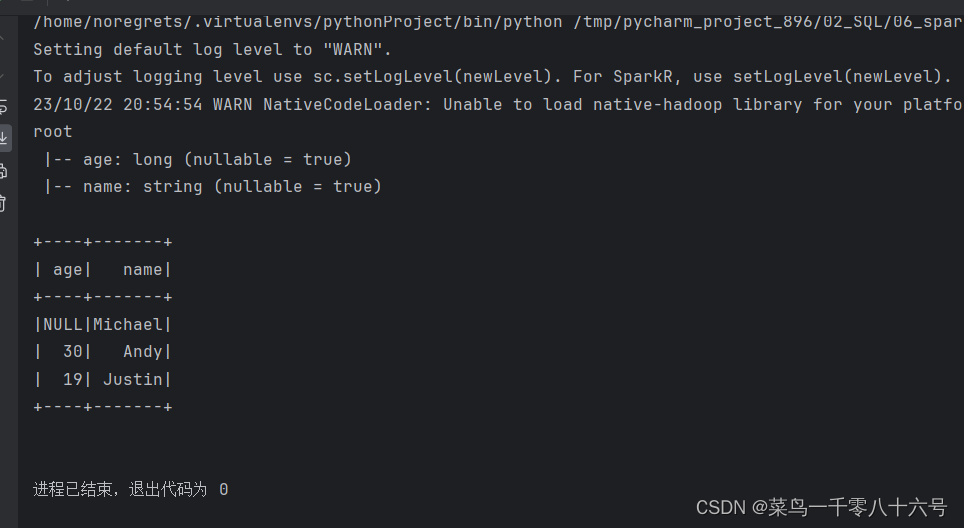
③读取csv文件

# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType
if __name__ == '__main__':
# 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
# 读取csv文件
df = spark.read.format('csv').\
option('sep', ';').\
option('header', True).\
option('encoding', 'utf-8').\
schema('name STRING, age INT, job STRING').\
load('../input/people.csv')
df.printSchema()
df.show()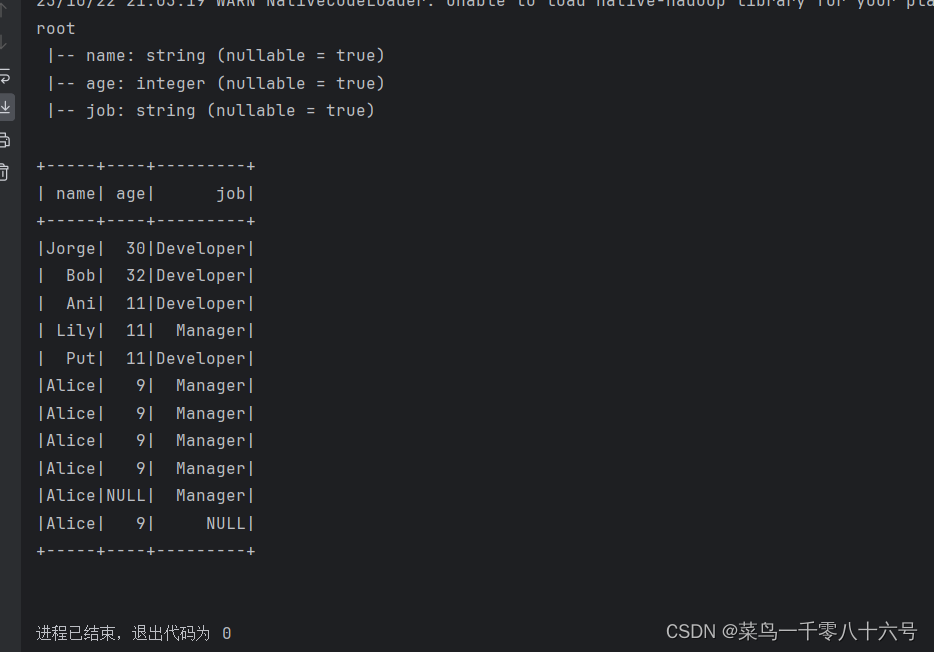
④读取parquet文件
parquet文件:是Spark中常用的一种列式存储文件格式,和Hive中的ORC差不多,他们都是列存储格式。
parquet对比普通的文本文件的区别:
①parquet内置schema(列名、列类型、是否为空)
②存储是以列作为存储格式
③存储是序列化存储在文件中的(有压缩属性体积小)
# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType
if __name__ == '__main__':
# 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
# 读取parquet文件
df = spark.read.format('parquet').load('../input/users.parquet')
df.printSchema()
df.show()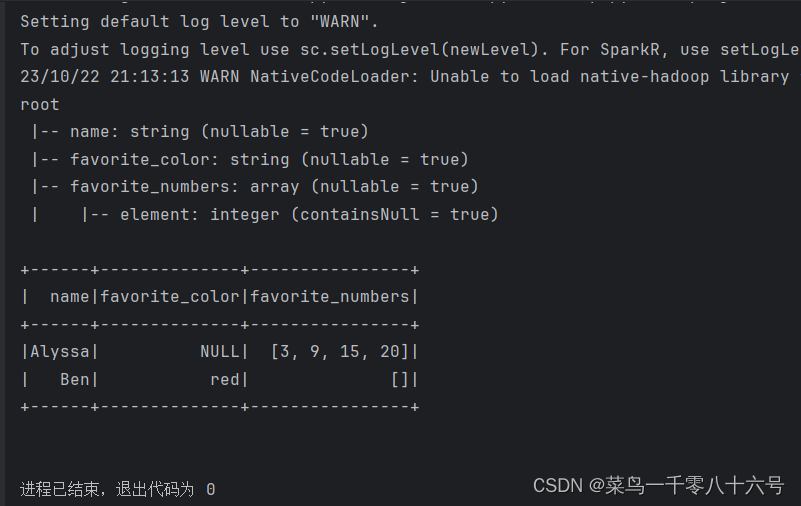
四、DataFrame编程
(1)DSL语法风格
# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType
if __name__ == '__main__':
# 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
df = spark.read.format('csv').\
schema('id INT, subject STRING, score INT').\
load('../input/stu_score.txt')
# Column对象的获取
id_column = df['id']
subject_column = df['subject']
# DLS风格
df.select(['id', 'subject']).show()
df.select('id', 'subject').show()
df.select(id_column, subject_column).show()
# filter API
df.filter('score < 99').show()
df.filter(df['score'] < 99).show()
# where API
df.where('score < 99').show()
df.where(df['score'] < 99).show()
# group By API
# df.groupBy API的返回值为 GroupedData类型1
# GroupedData对象不是DataFrame
# 它是一个 有分组关系的数据结构,有一些API供我们对分组做聚合
# SQL:group by 后接上聚合: sum avg count min max
# GroupedData 类似于SQL分组后的数据结构,同样由上述5中聚合方法
# GroupedData 调用聚合方法后,返回值依旧是DayaFrame
# GroupedData 只是一个中转的对象,最终还是会获得DataFrame的结果
df.groupBy('subject').count().show()
df.groupBy(df['subject']).count().show()(2)SQL语法风格
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sql()来执行SQL语句查询,结果返回一个DataFrame。
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:
df.createTempView( "score") #注册一个临时视图(表)
df.create0rReplaceTempView("score") #注册一个临时表,如果存在进行替换。
df.createGlobalTempView( "score") #注册一个全局表 全局表:跨SparkSession对象使用,在一个程序内的多个SparkSession中均可调用,查询前带上前缀:
global_temp.
临时表:只在当前SparkSession中可用
# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType
if __name__ == '__main__':
# 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName('test').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
df = spark.read.format('csv').\
schema('id INT, subject STRING, score INT').\
load('../input/stu_score.txt')
# 注册成临时表
df.createTempView('score') # 注册临时视图(表)
df.createOrReplaceTempView('score_2') # 注册或者替换为临时视图
df.createGlobalTempView('score_3') # 注册全局临时视图 全局临时视图使用的时候 需要在前面带上global_temp. 前缀
# 可以通过SparkSession对象的sql api来完成sql语句的执行
spark.sql("SELECT subject, COUNT(*) AS cnt FROM score GROUP BY subject").show()
spark.sql("SELECT subject, COUNT(*) AS cnt FROM score_2 GROUP BY subject").show()
spark.sql("SELECT subject, COUNT(*) AS cnt FROM global_temp.score_3 GROUP BY subject").show()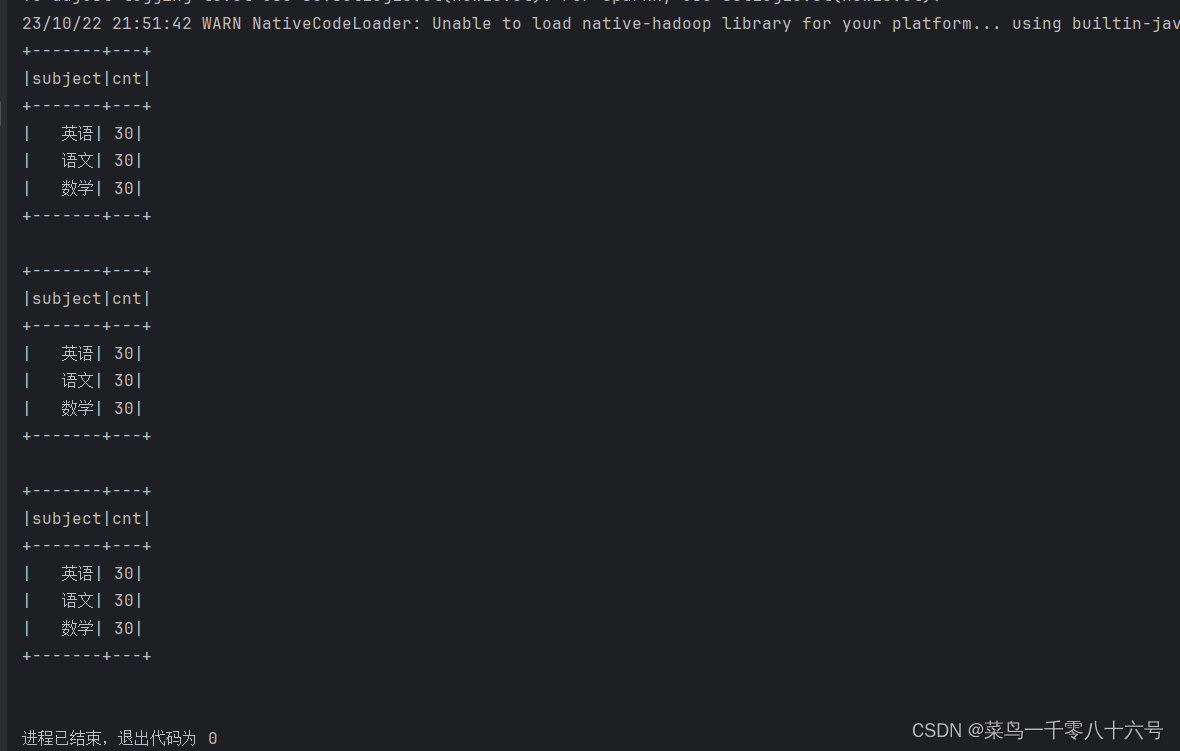
五、Spark SQL——wordcount代码示例
(1)pyspark.sql.functions包
这个包里面提供了一系列的计算函数供SparkSQL使用
导包:from pyspark.sql import functions as F
这些函数返回值多数都是Column对象。

(2)代码示例
# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
if __name__ == '__main__':
spark = SparkSession.builder.appName('wordcount').master('local[*]').getOrCreate()
sc = spark.sparkContext
# TODO 1:SQL风格进行处理
rdd = sc.textFile('../input/words.txt').\
flatMap(lambda x: x.split(' ')).\
map(lambda x: [x])
df = rdd.toDF(['word'])
# 注册DF为表格
df.createTempView('words')
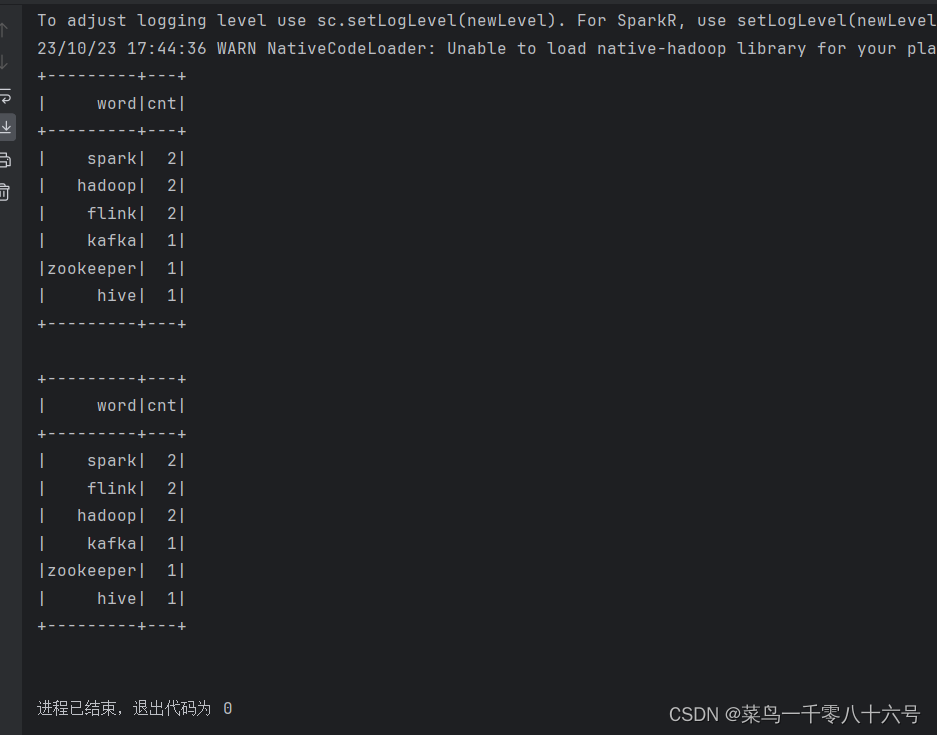
spark.sql('SELECT word,COUNT(*) AS cnt FROM words GROUP BY word ORDER BY cnt DESC').show()
# TODO 2:DSL 风格处理
df = spark.read.format('text').load('../input/words.txt')
# withColumn 方法
# 方法功能:对已存在的列进行操作,返回一个新的列,如果名字和老列相同,那么替换,否则作为新列存在
df2 = df.withColumn('value', F.explode(F.split(df['value'], ' ')))
df2.groupBy('value').\
count().\
withColumnRenamed('value', 'word').\
withColumnRenamed('count', 'cnt').\
orderBy('cnt', ascending=False).show()
# withColumnRenamed() 对列名进行重命名
# orderBy() 排序