python实现批量pdf转txt和word
文章目录
- 背景需求
- 环境安装
- 完整代码
- 效果
背景需求
已经获取到了大量的pdf在download文件夹中,但是我需要的是txt文件和word文件~
环境安装
pip install pdf2docx pdfminer.six
完整代码
# pip install pdf2docx pdfminer.six
import os
from pdf2docx import Converter
from pdfminer.high_level import extract_text
# 忽略警告
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="pdf2docx")
# pdf转txt
def pdf_to_txt(pdf_path, txt_path):
text = extract_text(pdf_path)
with open(txt_path, 'w', encoding='utf-8') as f:
f.write(text)
# pdf转word
def pdf_to_docx(pdf_path, docx_path):
cv = Converter(pdf_path)
cv.convert(docx_path, start=0, end=None)
cv.close()
# 分批转换,文件格式检测
def batch_convert(download_folder, data_folder, output_format='txt'):
# 确保输出文件夹存在
if not os.path.exists(data_folder):
os.makedirs(data_folder)
# 遍历download文件夹中的所有PDF文件
for filename in os.listdir(download_folder):
if filename.endswith('.pdf'):
pdf_path = os.path.join(download_folder, filename)
if output_format == 'txt':
txt_filename = os.path.splitext(filename)[0] + '.txt'
txt_path = os.path.join(data_folder, txt_filename)
pdf_to_txt(pdf_path, txt_path)
elif output_format == 'docx':
docx_filename = os.path.splitext(filename)[0] + '.docx'
docx_path = os.path.join(data_folder, docx_filename)
pdf_to_docx(pdf_path, docx_path)
# 转换txt
batch_convert('download', 'data_txt', output_format='txt')
# 转换word文件
batch_convert('download', 'data_docx', output_format='docx')
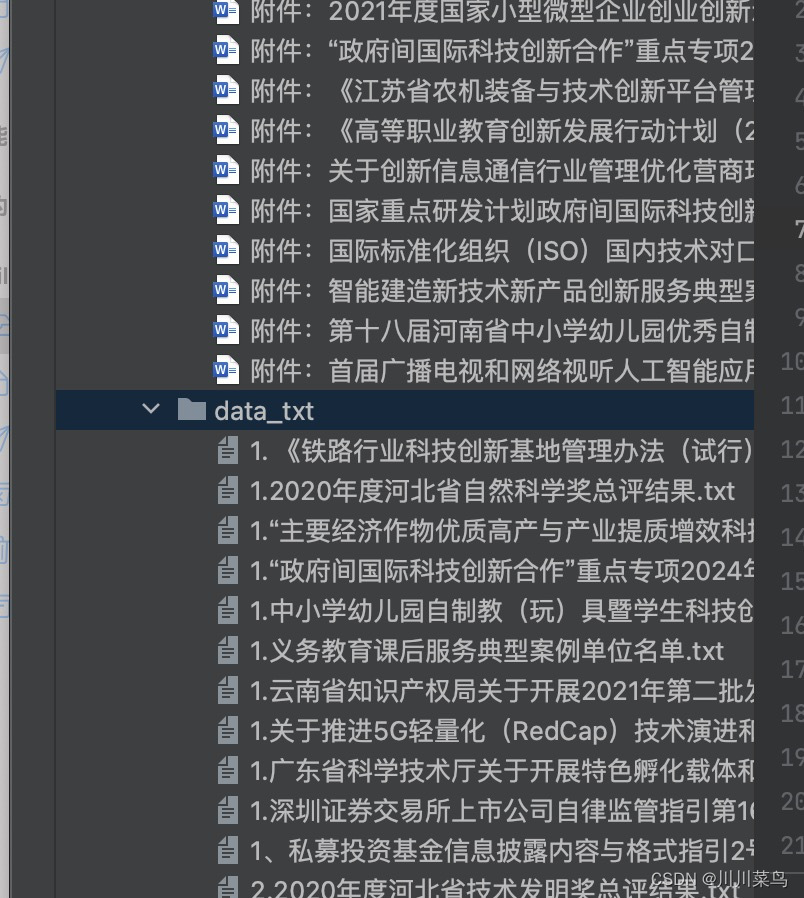
效果