MongoDB 的集群架构与设计
一、前言
MongoDB 有三种集群架构模式,分别为主从复制(Master-Slaver)、副本集(Replica Set)和分片(Sharding)模式。
- Master-Slaver 是一种主从复制的模式,目前已经不推荐使用。
- Replica Set 模式取代了 Master-Slaver 模式,是一种互为主从的关系。Replica Set 将数据复制多份保存,不同服务器保存同一份数据,在出现故障时自动切换,实现故障转移,在实际生产中非常实用。
- Sharding 模式适合处理大量数据,它将数据分开存储,不同服务器保存不同的数据,所有服务器数据的总和即为整个数据集。
二、主从复制模式
MongoDB 提供的第一种冗余策略就是 Master-Slave 策略,这个也是分布式系统最开始的冗余策略,这种是一种热备策略。
Master-Slave 架构一般用于备份或者做读写分离,一般是一主一从设计和一主多从设计。
Master-Slave 由主从角色构成:
Master ( 主 )
可读可写,当数据有修改的时候,会将 Oplog 同步到所有连接的 Salve 上去。
Slave ( 从 )
只读,所有的 Slave 从 Master 同步数据,从节点与从节点之间不感知。
如图: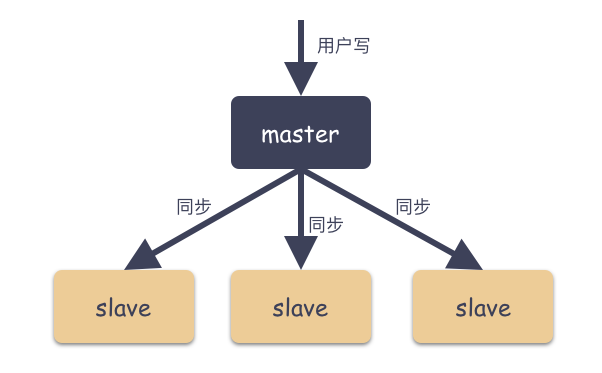
2.1 主从复制对读写分离的思考
主从复制老生常谈的问题:数据不一致的问题。
根本原因在于只有 Master 节点可以写,Slave 节点只能同步 Master 数据并对外提供读服务,当你查询 Slave 节点的数据时,由于网络延迟等其它因素导致 Slave 节点还没有完全同步 Master 节点的数据,这就会导致主从不一致,跟 MySQL 的主从复制如出一辙,只不过 MySQL 时 binlog 同步,而 MongoDB 是 oplog 同步。
所以,总结来说:读写分离的架构只适合特定场景,对于必须需要数据强一致的场景是不合适这种读写分离的。
2.2 主从复制对容灾的思考
当 Master 节点出现故障的时候,由于 Slave 节点有备份数据,可以通过人为 Check 和操作,手动把 Slave 节点指定为 Master 节点,这样又能对外提供服务了。
- Master-Slave 只区分两种角色:Master 节点,Slave 节点;
- Master-Slave 的角色是静态配置的,不能自动切换角色,必须人为指定;
- 用户只能写 Master 节点,Slave 节点只能从 Master 拉数据;
- 还有一个关键点:Slave 节点只和 Master 通信,Slave 之间相互不感知,这种好处对于 Master 来说优点是非常轻量,缺点是:系统明显存在单点,那么多 Slave 只能从 Master 拉数据,而无法提供自己的判断;
MongoDB 3.6 起已不推荐使用主从模式,自 MongoDB 3.2 起,分片群集组件已弃用主从复制。因为 Master-Slave 其中 Master 宕机后不能自动恢复,只能靠人为操作,可靠性也差,操作不当就存在丢数据的风险。
三、副本集模式
3.1 副本集模式角色
副本集(Replica Set)是 mongod 的实例集合,包含三类节点角色:
Primary( 主节点 )
只有 Primary 是可读可写的,Primary 接收所有的写请求,然后把数据同步到所有 Secondary 。一个 Replica Set 只有一个 Primary 节点,当 Primary 挂掉后,其他 Secondary 或者 Arbiter 节点会重新选举出来一个 Primary 节点,这样就又可以提供服务了。
读请求默认是发到 Primary 节点处理,如果需要故意转发到 Secondary 需要客户端修改一下配置(注意:是客户端配置,决策权在客户端)。
那有人又会想了,这里也存在 Primary 和 Secondary 节点角色的分类,岂不是也存在单点问题?
这里和 Master-Slave 模式的最大区别在于,Primary 角色是通过整个集群共同选举出来的,人人都可能成为 Primary ,人人最开始只是 Secondary ,而这个选举过程完全自动,不需要人为参与。
Secondary( 副本节点 )
数据副本节点,当主节点挂掉的时候,参与选主。
思考一个问题:Secondary 和 Master-Slave 模式的 Slave 角色有什么区别?
最根本的一个不同在于:Secondary 相互有心跳,Secondary 可以作为数据源,Replica 可以是一种链式的复制模式。
Arbiter( 仲裁者 )
不存数据,不会被选为主,只进行选主投票。使用 Arbiter 可以减轻在减少数据的冗余备份,又能提供高可用的能力。
如下图:
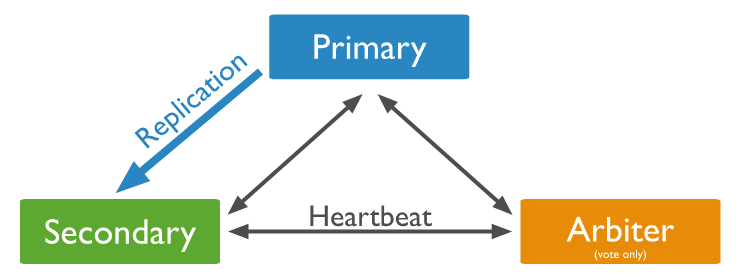
3.2 为什么要使用副本集?
3.2.1 高可用
- 防止设备(服务器、网络)故障
- 提供自动 failover 功能
- 技术来保证高可用
3.2.2 灾难恢复
- 当发生故障时,可以从其他节点恢复,用于备份。
3.2.3 功能隔离
- 我们可以在备节点上执行读操作,减少主节点的压力
- 比如:用于分析、报表,数据挖掘,系统任务等。
3.3 副本集集群架构原理
一个副本集中Primary节点上能够完成读写操作,Secondary节点仅能用于读操作。Primary节点需要记录所有改变数据库状态的操作,这些记录保存在 oplog 中,这个文件存储在 local 数据库,各个Secondary 节点通过此 oplog 来复制数据并应用于本地,保持本地的数据与主节点的一致。oplog 具有幂等性,即无论执行几次其结果一致,这个比 mysql 的二进制日志更好用。
oplog的组成结构
{
"ts" : Timestamp(1446011584, 2),
"h" : NumberLong("1687359108795812092"),
"v" : 2,
"op" : "i",
"ns" : "test.nosql",
"o" : { "_id" : ObjectId("563062c0b085733f34ab4129"), "name" : "mongodb", "score" : "10"}
}
ts:操作时间,当前timestamp + 计数器,计数器每秒都被重置
h:操作的全局唯一标识
v:oplog版本信息
op:操作类型
i:插入操作
u:更新操作
d:删除操作
c:执行命令(如createDatabase,dropDatabase)
n:空操作,特殊用途
ns:操作针对的集合
o:操作内容
o2:更新查询条件,仅update操作包含该字段
副本集数据同步分为初始化同步和keep复制同步。初始化同步指全量从主节点同步数据,如果Primary 节点数据量比较大同步时间会比较长。而keep复制指初始化同步过后,节点之间的实时同步一般是增量同步。
初始化同步有以下两种情况会触发:
- Secondary 第一次加入。
- Secondary 落后的数据量超过了 oplog 的大小,这样也会被全量复制。
MongoDB的Primary节点选举基于心跳触发。一个复制集N个节点中的任意两个节点维持心跳,每个节点维护其他N-1个节点的状态。
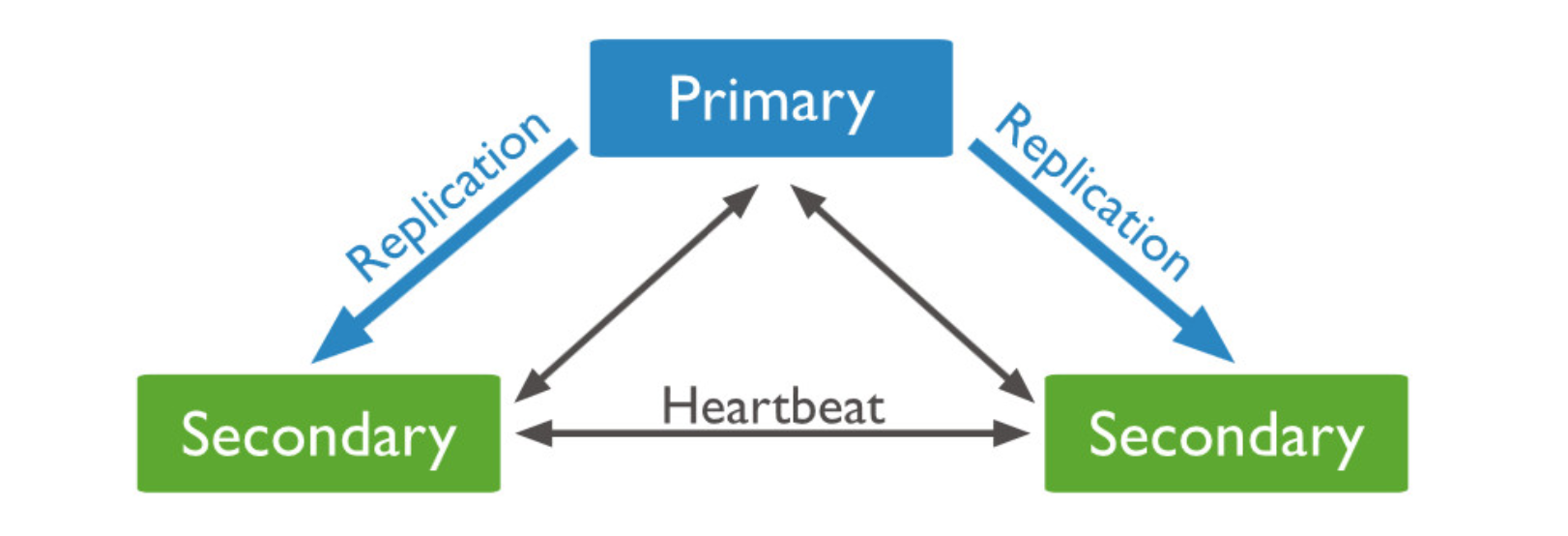
心跳检测:
整个集群需要保持一定的通信才能知道哪些节点活着哪些节点挂掉。mongodb节点会向副本集中的其他节点每2秒就会发送一次pings包,如果其他节点在10秒钟之内没有返回就标示为不能访问。每个节点内部都会维护一个状态映射表,表明当前每个节点是什么角色、日志时间戳等关键信息。如果主节点发现自己无法与大部分节点通讯则把自己降级为secondary只读节点。
主节点选举触发的时机:
第一次初始化一个副本集
Secondary节点权重比Primary节点高时,发起替换选举Secondary节点发现集群中没有Primary时,发起选举Primary节点不能访问到大部分(Majority)成员时主动降级
当触发选举时,Secondary节点尝试将自身选举为Primary。主节点选举是一个二阶段过程+多数派协议。
第一阶段:
检测自身是否有被选举的资格,如果符合资格会向其它节点发起本节点是否有选举资格的 FreshnessCheck,进行同僚仲裁。
第二阶段:
发起者向集群中存活节点发送Elect(选举)请求,仲裁者收到请求的节点会执行一系列合法性检查,如果检查通过,则仲裁者(一个复制集中最多50个节点,其中只有7个具有投票权)给发起者投一票。
pv0通过30秒选举锁防止一次选举中两次投票。
pv1使用了terms(一个单调递增的选举计数器)来防止在一次选举中投两次票的情况。
多数派协议:
发起者如果获得超过半数的投票,则选举通过,自身成为Primary节点。获得低于半数选票的原因,除了常见的网络问题外,相同优先级的节点同时通过第一阶段的同僚仲裁并进入第二阶段也是一个原因。因此,当选票不足时,会sleep[0,1]秒内的随机时间,之后再次尝试选举。
四、分片模式
4.1 什么是分片
分片 (sharding) 是MongoDB用来将大型集合水平分割到不同服务器(或者副本集)上所采用的方法。 不需要功能强大的大型计算机就可以存储更多的数据,处理更大的负载。
4.2 为什么要分片
- 存储容量需求超出单机磁盘容量。
- 活跃的数据集超出单机内存容量,导致很多请求都要从磁盘读取数据,影响性能。
IOPS超出单个MongoDB节点的服务能力,随着数据的增长,单机实例的瓶颈会越来越明显。- 副本集具有节点数量限制。
垂直扩展:增加更多的CPU和存储资源来扩展容量。水平扩展:将数据集分布在多个服务器上,水平扩展即分片。
4.3 分片的工作原理
整体架构图: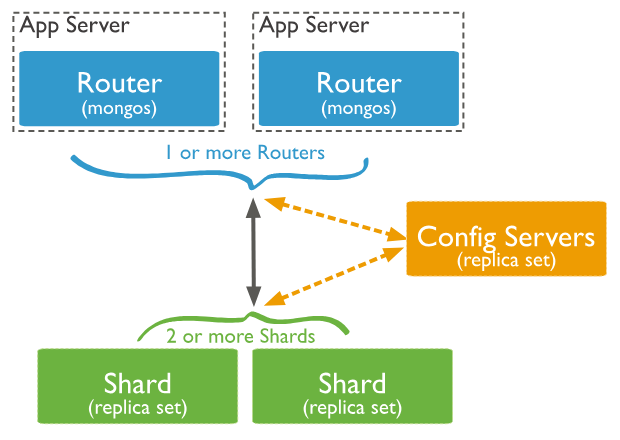
详细架构图: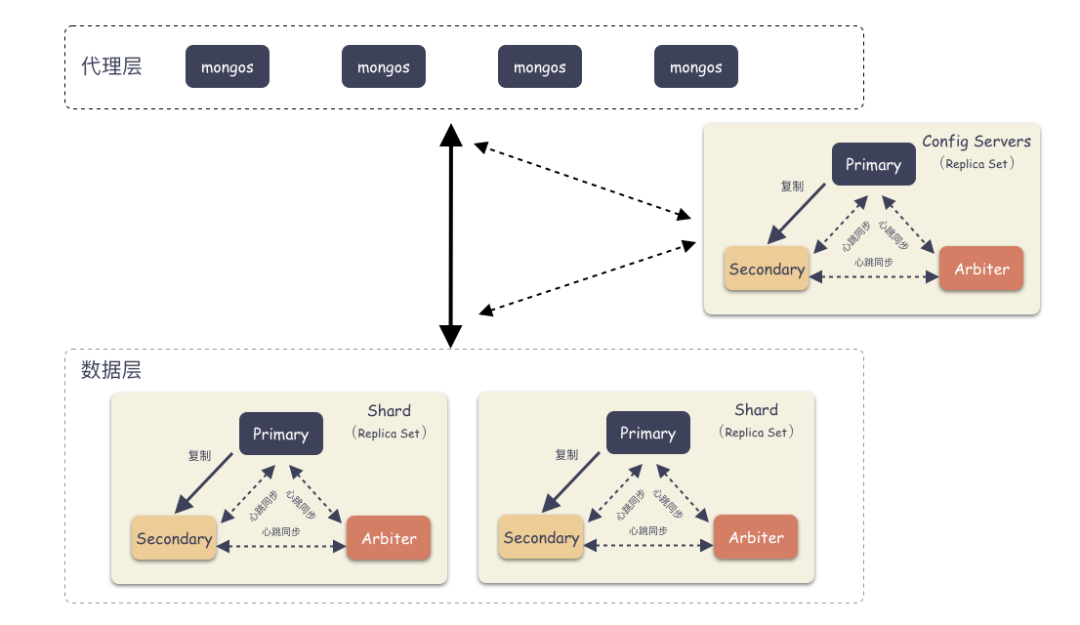
分片集群由以下3个服务组成:
Router Server: 数据库集群的请求入口,所有请求都通过Router(mongos)进行协调,不需要在应用程序添加一个路由选择器,Router(mongos)就是一个请求分发中心它负责把应用程序的请求转发到对应的Shard服务器上。Shards Server: 每个shard由一个或多个mongod进程组成,用于存储数据。Config Server: 配置服务器。存储所有数据库元信息(路由、分片)的配置。
4.3.1 片键(shard key)
为了在数据集合中分配文档,MongoDB使用分片主键分割集合。
4.3.2 区块(chunk)
在一个shard server内部,MongoDB还是会把数据分为chunks,每个chunk代表这个shard server内部一部分数据。MongoDB分割分片数据到区块,每一个区块包含基于分片主键的左闭右开的区间范围。
4.3.3 分片策略
4.3.3.1 hash分片(Hashed Sharding)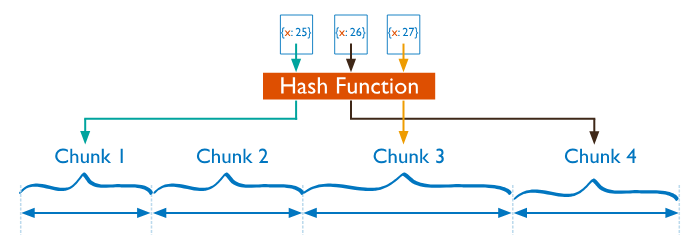
把 Key 作为输入,输入到一个 Hash 函数中,计算出一个整数值,值的集合形成了一个值域,我们按照固定步长去切分这个值域,每一个片叫做 Chunk ,这里的 Chunk 则就是整数的一段范围而已。
优点:
- 计算速度快
- 均衡性好,纯随机
缺点:
- 正因为纯随机,排序列举的性能极差,比如你如果按照 name 这个字段去列举数据,你会发现几乎所有的 Shard 都要参与进来;
4.3.3.2 范围分片(Ranged Sharding)
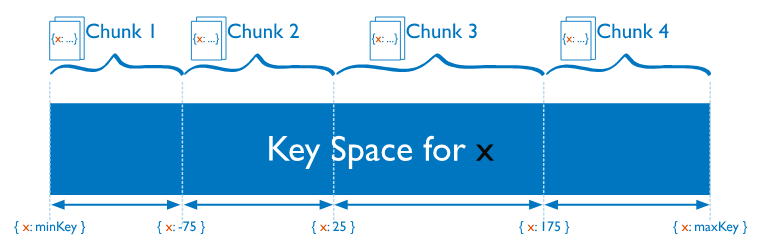
优点:
- 对排序列举场景非常友好,因为数据本来就是按照顺序依次放在 Shard 上的,排序列举的时候,顺序读即可,非常快速;
缺点:
- 容易导致热点,举个例子,如果 Sharding Key 都有相同前缀,那么大概率会分配到同一个 Shard 上,就盯着这个 Shard 写,其他 Shard 空闲的很,却帮不上忙;
4.3.3.3 zone 分片(Zones in Sharded Clusters)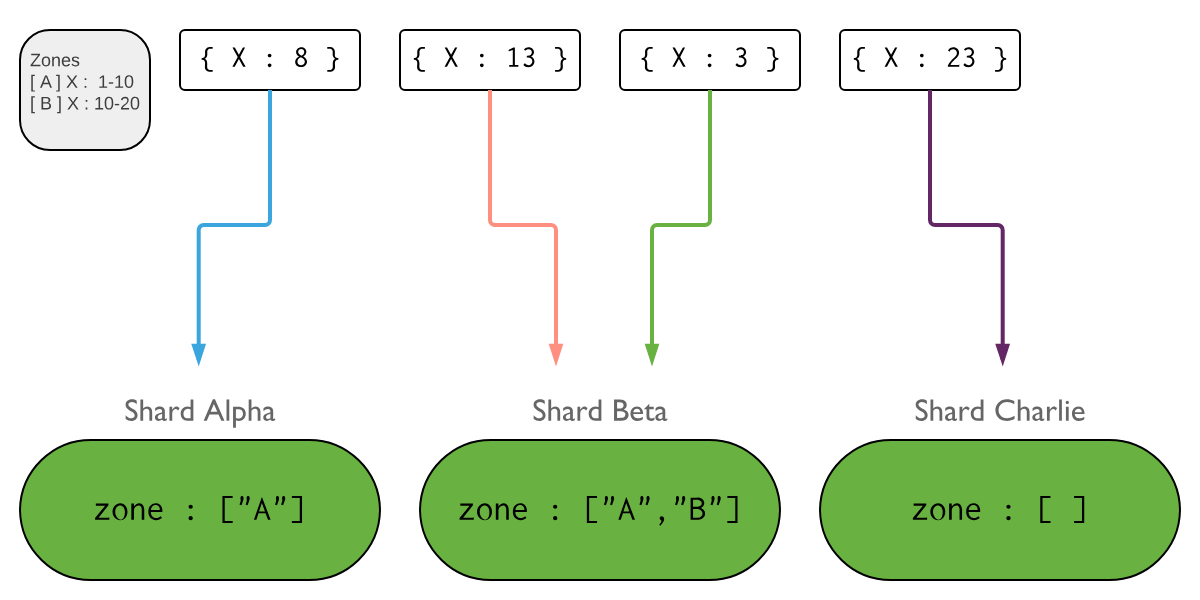
简单来说 Zone 实际上像是范围分片的另一个版本,你为一定范围内的片键制定一个 Zone,然后再将一些分片加入到这个 Zone 中,于是这一范围内的数据最终就将存储在这个 Zone 中的分片上。
五、总结
本文介绍了 3 种 MongoDB 的高可用架构,Master-Slave 模式,Replica Set 模式,Sharding 模式,这也是常见的架构演进的过程,是不是有点恍惚,Redis 也是类似这种架构的演进。
- MongoDB Master-Slave 已经不推荐,甚至新版已经不支持这种冗余模式;
- Replica Set 通过数据多副本,组件冗余提高了可靠性,并且通过分布式自动选主算法,减少了停服时间窗,提高了可用性;
- Sharding 模式通过横向扩容的方式,为用户提供了近乎无限的空间;
- MongoDB 客户端掌握了很大的配置权限,通过指定写多数策略和 strong 模式(只从主节点读数据)能保证数据的高可靠和强一致性;