【C++初探:简单易懂的入门指南】一
【C++初探:简单易懂的入门指南】一
- 1. 命名空间
- 1.1 命名空间的定义
- 1.2 命名空间的使用方法
- 2. C++的输入、输出
- 2.1 为什么使用输入、输出要引用一个<iostream>的头文件?
- 2.2 为什么代码里面开放了一个叫std的命名空间
- 2.3 代码中出现的<<和>>还有endl是什么?
- 3.缺省参数
- 3.1 全缺省参数
- 3.2 半缺省参数
- 4.函数重载
- 4.1 函数重载的例子
- 4.2 为什么C++支持函数重载?

❤️博客主页: 小镇敲码人
🍏 欢迎关注:👍点赞 👂🏽留言 😍收藏
🌞任尔江湖满血骨,我自踏雪寻梅香。 万千浮云遮碧月,独傲天下百坚强。 男儿应有龙腾志,盖世一意转洪荒。 莫使此生无痕度,终归人间一捧黄。🍎🍎🍎
❤️ 什么?你问我答案,少年你看,下一个十年又来了 💞 💞 💞

1. 命名空间
因为C/C++里面有很多的变量、函数、类,他们都是有相应的名称的,为了让它们之间的命名不互相起冲突,或者是不和库里面定义的变量、函数、类的名称起冲突,C++的祖师爷就引出了命名空间这个概念,它就像围墙一样把你要写的变量或者类或者函数围在里面,要使用特殊的方式才能使用它们。
1.1 命名空间的定义
定义命名空间需要使用namespace这个关键词,看下面的一段代码:
namespace Date
{
int year = 2023;
int month = 10;
int day = 27;
void Print()
{
printf("今天是美好的一天\n");
}
struct student
{
int val;
char name[];
}Stu;
}
这里就是定义了一个叫Date的命名空间,里面放着3个临时变量和一个函数,一个struct类型。
1.2 命名空间的使用方法
那么如果我们想要使用上述命名空间里的东西,应该怎么办呢,通常有如下三种办法:
- 使用
using namespace + 命名空间的方式将这个空间开放,这样编译器就可以访问了。
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string.h>
namespace Date
{
int year = 2023;
int month = 10;
int day = 27;
void Print()
{
printf("今天是美好的一天\n");
}
struct student
{
int score;
char name[];
}Stu;
}
using namespace Date;
int main()
{
printf("%d/%d/%d:", year, month, day);
Print();
strcpy(Stu.name, "wwj");
Stu.score = 100;
printf("%s %d", Stu.name, Stu.score);
return 0;
}
运行截图:
如果你不信,可以尝试删掉这行代码,就变成这样:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string.h>
namespace Date
{
int year = 2023;
int month = 10;
int day = 27;
void Print()
{
printf("今天是美好的一天\n");
}
struct student
{
int score;
char name[];
}Stu;
}
int main()
{
printf("%d/%d/%d:", year, month, day);
Print();
strcpy(Stu.name, "wwj");
Stu.score = 100;
printf("%s %d", Stu.name, Stu.score);
return 0;
}
再次编译,运行编译器是这样告诉我们的:
可以看出,没有using namespace + 命名空间名称这段话,Date命名空间里面的内容是不对外开放的,编译器无法找到。
- 使用
using + 命名空间名称 + :: + 某个成员名
这种方法的应用场景是我只想用这个命名空间里的某个成员。
- 注意这里新出现了一个操作符
::,它叫作用域限定符,用于连接命名空间和它的成员,这个符号相当于一个传送门,通过这个符号我们可以从命名空间里直接找到相应的成员。
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string.h>
namespace Date
{
int year = 2023;
int month = 10;
int day = 27;
void Print()
{
printf("今天是美好的一天\n");
}
struct student
{
int score;
char name[];
}Stu;
}
using Date::Stu;
int main()
{
strcpy(Stu.name, "wwj");
Stu.score = 100;
printf("%s %d", Stu.name, Stu.score);
return 0;
}
运行截图:
3. 在使用的地方直接用命名空间名称+::+成员名
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string.h>
namespace Date
{
int year = 2023;
int month = 10;
int day = 27;
void Print()
{
printf("今天是美好的一天\n");
}
struct student
{
int score;
char name[];
}Stu;
}
int main()
{
strcpy(Date::Stu.name, "wwj");
Date::Stu.score = 100;
printf("%s %d", Date::Stu.name,Date::Stu.score);
return 0;
}
运行截图:
- 注意:这里对上面三种使用命名空间的方法做一下总结,首先最方便的肯定还是第一种方法,直接把整个空间完全开放,但是这样做一旦工程大了之后就难免会不安全,出现命名冲突的情况,第三种虽然能保证安全,但是一个成员要用很多次,每次都要
命名空间名称+::+成员名这样去使用对于程序员来说还是会有点麻烦,所以个人觉得第二种才是最佳的,把一个需要重复命名空间的成员给开放出来,当然具体情况具体分析,要保证不会出现重名的情况。
2. C++的输入、输出
C++在进行输入输出时,使用
cout(标准输出对象->控制台),cin(标准输入对象->键盘),并且与C语言不同的是,我们不需要手动的控制变量的格式了,C++的cout和cin可以自动帮你识别。
看下面一段代码,帮你完全掌握输入、输出的使用:
#include<iostream>
using namespace std;
int main()
{
int n = 0;
cin >> n;
cout << n << endl;
return 0;
}
运行结果:
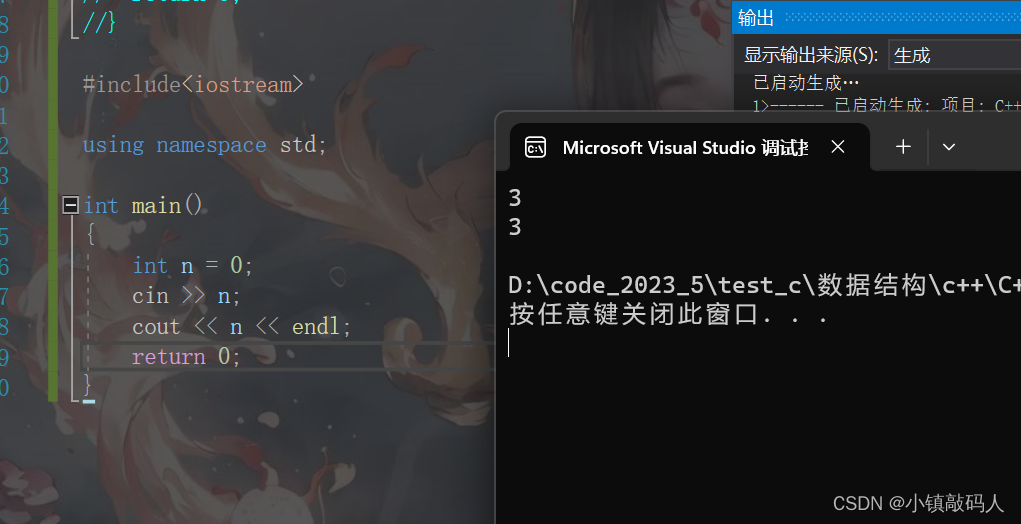
上面的代码是输入一个int类型的变量n的值,并且打印它们。
但是你可能还是会有以下疑问,我来一一为你解答
2.1 为什么使用输入、输出要引用一个的头文件?
是因为输入、输出函数放在这个库文件里面,类比于C语言的printf函数放在<stdio.h>文件里面去理解。
2.2 为什么代码里面开放了一个叫std的命名空间
这是因为cout与cin这两个输入、输出函数就放在<iostreaam>文件的std这个命名空间里面,想要使用这个命名空间里的成员就得用我们上面说过的关于命名空间的使用的三种方法之一。
- 虽然本代码采用了第一种方法,直接把
std这个命名空间都开放了,但在大型的工程中还是以第二种和第三种方法为主,因为第一种方法的安全性太低了,容易引起重名冲突。
2.3 代码中出现的<<和>>还有endl是什么?
<<是流插入运算符与cout打印函数是一同出现,表示将变量的内容插入到控制台中,>>是流提取运算符与cin输入函数一同出现,表示将从键盘中的内容提取到变量中去。endl是特殊的C++符号,表示换行,它也在命名空间std中。
- 注意:如果你想学习用
cout函数实现像double类型的精度控制,整形输出进制格式,是比较复杂的,虽然可以实现,但是性价比不高,由于C++是兼容C语言的,所以如果你遇到这种情况,仍然可以使用printf来解决问题。
3.缺省参数
缺省参数就是在函数传参时给形参一个缺省值,如果给这个函数传了实参那这个缺省值就不用管了,实参和形参的值相等,如果不传编译器就会默认给那个形参赋缺省值,那个有缺省值的参数就叫缺省参数。
- 缺省参数只在C++里面支持,在C语言里面是不支持。
请看下面代码,帮你更好的理解缺省参数。
#include<iostream>
using namespace std;
void Fun(int a = 10)
{
cout << a << endl;
}
int main()
{
Fun();
Fun(100);
return 0;
}
运行结果为:
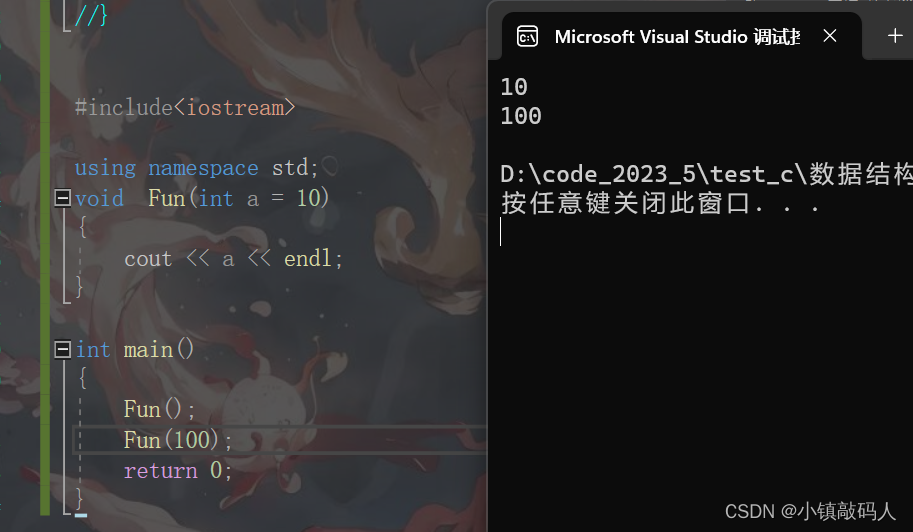
上面代码中的形参a就是一个缺省参数,我们可以知道,如果一个函数,它的形参全是缺省参数的话,那么它是可以不传参的。
3.1 全缺省参数
#include<iostream>
using namespace std;
void Fun(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main()
{
Fun();
Fun(100,200);
return 0;
}
运行结果:
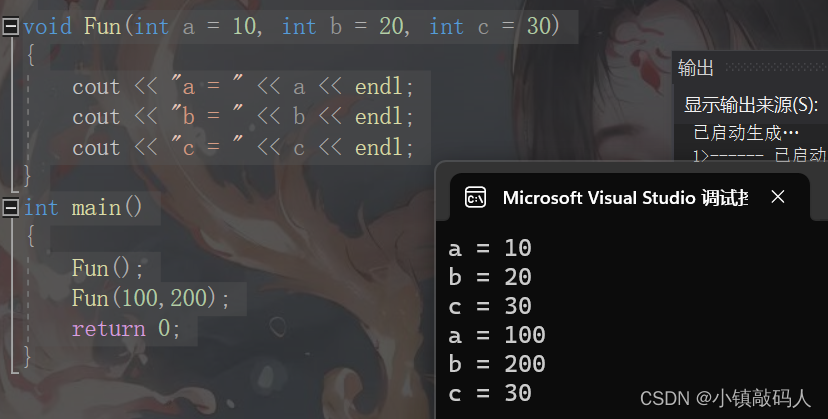
可以看到全缺省参数如果要传参的话,是从左到右按照顺序给的,如果只传两个值,那这里的三个参数就要默认为缺省值了。
3.2 半缺省参数
#include<iostream>
using namespace std;
void Fun(int a , int b = 20,int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main()
{
Fun(20);
Fun(100,200);
return 0;
}
运行结果:
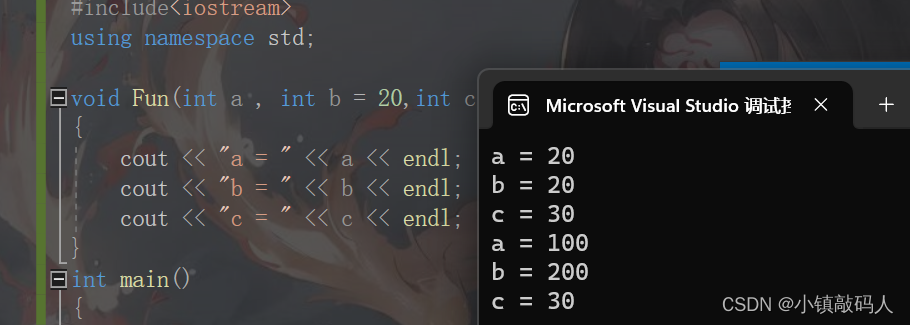
可以看到,当函数的参数为半缺省参数时,是既有缺省参数,又有正常的形参的,这个时候C++规定,半缺省参数中的缺省参数只能从左到右依次给,不能间隔着给,否则就会报错,譬如如下代码:
#include<iostream>
using namespace std;
void Fun(int a = 10, int b = 20,int c)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main()
{
Fun(20);
Fun(100,200);
return 0;
}
- 这个代码就有歧义了,
main函数中调用的第一个Fun函数传了一个参数,这个参数应该传给没有缺省值的c呢,还是传给前面两个缺省参数a和b呢,就算你说这个参数默认传给c,那调用第二个Fun函数的时候,传了两个参数这第一个值你是应该a,还是应该传给b呢,这样就难免有点麻烦了,所以C++祖师爷规定,半缺省参数中的缺省参数只能从右往左依次给,这样在传参的时候就不存在歧义,和全缺省一样,给正常形参传完之后,如果还传的有参数,那就按照从左到右的顺序依次传给缺省参数。
关于缺省参数,还有几点值得强调的地方:
- 有缺省参数的函数在进行定义和声明分离的时候,缺省值不能同时出现在声明和定义里面。(因为如果恰好你这两个地方给的值不同,编译器就无法确定用哪个地方的缺省值了)。
- 缺省参数的缺省值只能给常量或者全局变量。
下面一张代码的截图,希望可以帮助你来理解它们:
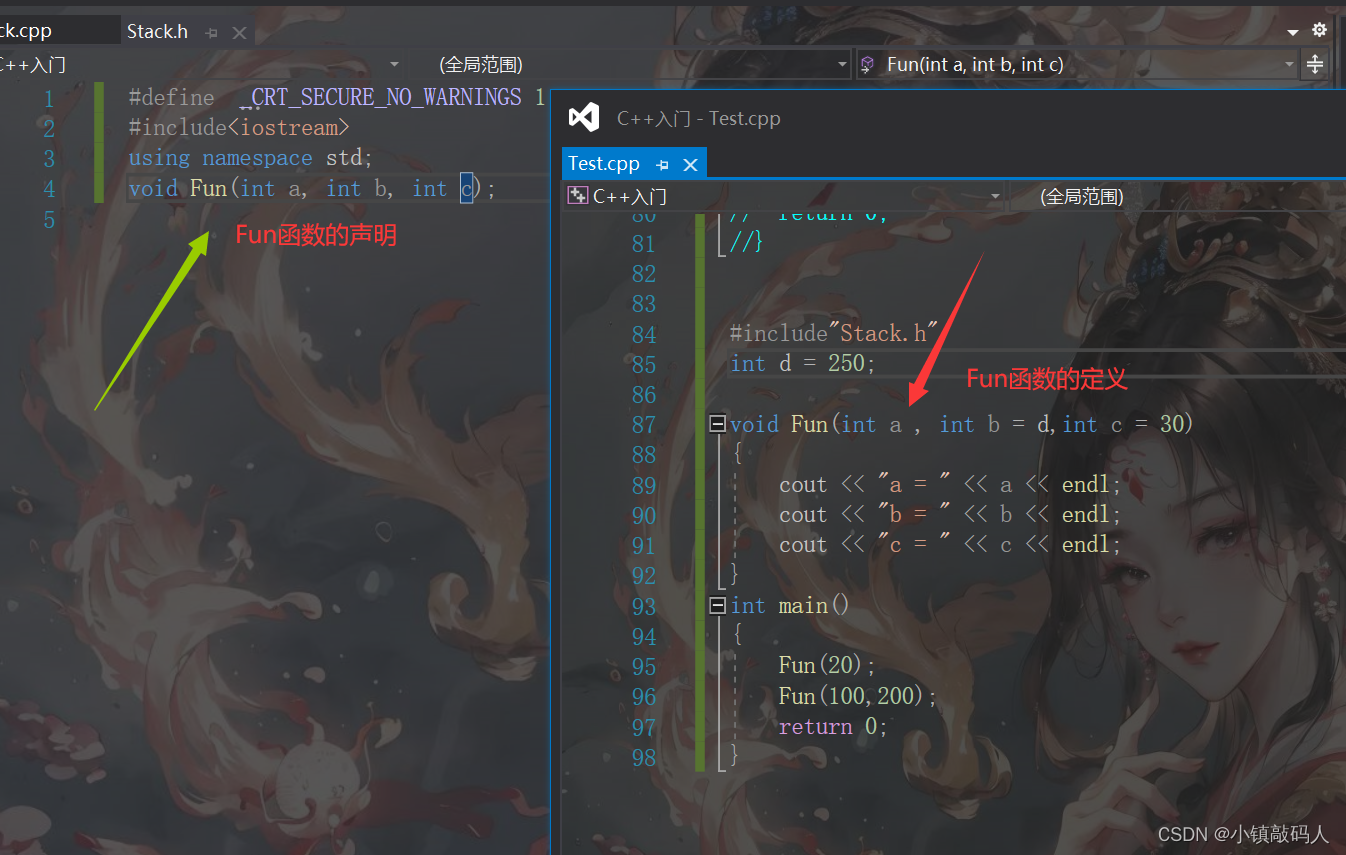
我们给函数Fun的缺省参数的值给的是全局变量d,编译器是能通过的,并且只要声明和定义不同时给缺省值,编译器就不会报错。
4.函数重载
函数重载的意思就是同一个作用域里面,C++支持一些功能相似的函数,它的函数名一样,但是参数列表(参数类型/参数个数/类型顺序),有一个不同就可以了,同样的C语言里面也不支持函数重载。
4.1 函数重载的例子
同样的下面一段代码,帮助你很好的理解什么是函数重载:
#include<iostream>
using namespace std;
int Add(int a, int b)
{
return a + b;
}
double Add(double a, double b)
{
return a + b;
}
int main()
{
int c = Add(1, 2);
double d = Add(3.4, 4.0);
cout << "c: " << c << endl;
cout << "d: " << d << endl;
return 0;
}
运行截图:
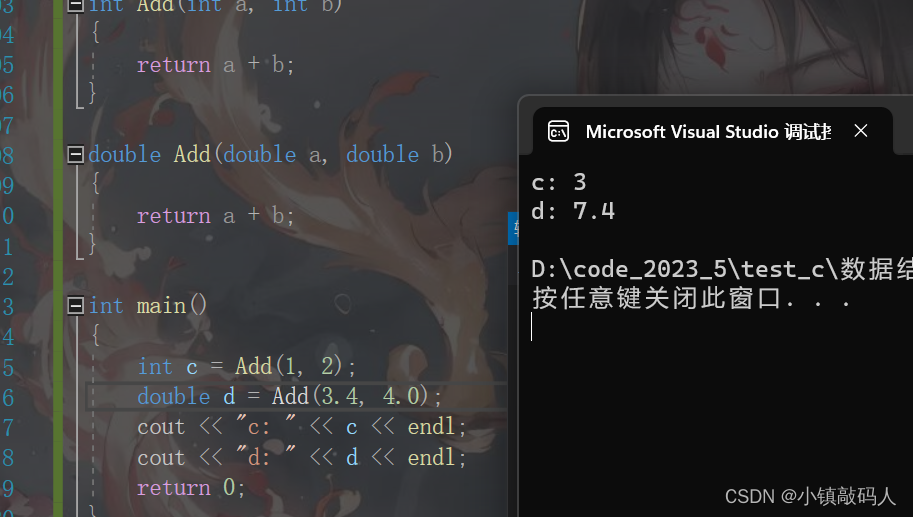
可以看到,虽然这两个函数的函数名是一样的,但是编译器却能够辨别,根据传参的不同,调用了不同的Add函数,那么编译器是如何区分这两个函数的呢,我们下面慢慢探讨。
4.2 为什么C++支持函数重载?
- 函数名的修饰起到了关键的作用,这是C语言编译链接的知识,我们不做过多阐述。
但是我们可以通过下面代码做一个简单的验证:
#include"Stack.h"
int main()
{
int c = Add(1, 2);
double d = Add(3.4, 4.0);
cout << "c: " << c << endl;
cout << "d: " << d << endl;
return 0;
}
而Stack.h文件中的代码是这样的
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int Add(int a, int b);
double Add(double a, double b);
我们只声明了这两个函数,相当于造了一个图纸,但是没有真正的去定义它们,按理来说,编译器在链接过程中是找不到这两个函数的地址的。
报错截图:
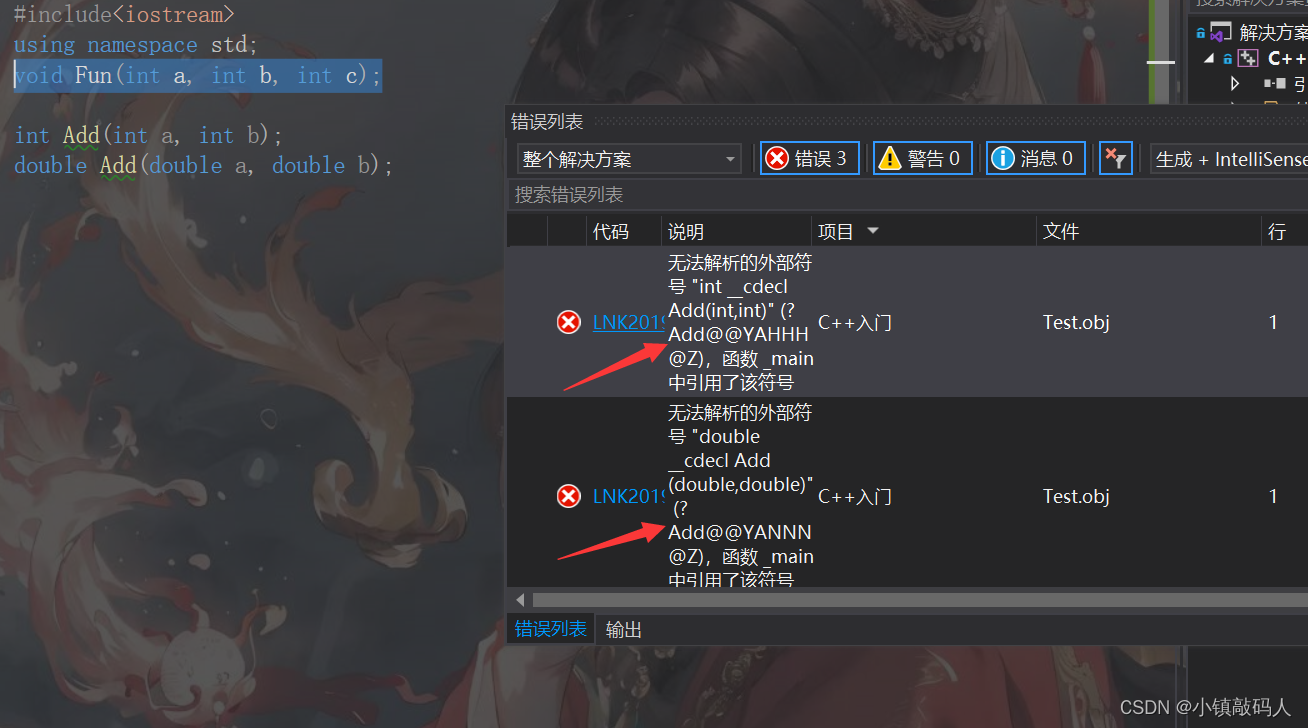
箭头所指的括号里面的内容就是编译器给这两个Add函数所取的新名字,我们不需要知道它具体的修饰规则,当然感兴趣的可以去了解一下,因为每个编译器都是不一样的,我这里用的是VS2019,所以我们可以知道编译器通过修饰函数名来实现函数重载。
- C++规定函数重载不能通过返回值的类型不同来区分。
因为如果这个函数除了返回值不同,其它的都一样,在调用的时候,编译器是无法区分的,编译器怎么知道你要调用哪个函数呢?如下代码希望能帮助你理解:
#include<iostream>
using namespace std;
int Add(int a, int b)
{
return a + b;
}
double Add(int a, int b)
{
return a + b;
}
int main()
{
int a = Add(2, 3);
double b = Add(2, 3);
return 0;
}
所以我们可以猜测,C/C++函数在开始调用的时候,也就是还在上述代码main函数还在执行调用那一行的时候,调用函数这一步是与它的返回值类型无关的,只与它的函数名和参数有关。
