【psychopy】【脑与认知科学】认知过程中的面孔识别加工
目录
实验描述
实验思路
python实现
实验描述
现有的文献认为,人们对倒置的面孔、模糊的面孔等可能会出现加工时长增加、准确率下降的问题,现请你设计一个相关实验,判断不同的面孔是否会出现上述现象。请按照认知科学要求,画出对应的实验流程图,并叙述实验的对照组如何设置,并分析实验结果。
熟悉程度判断实验举例:可以显示大家都认识的名人。也可以是陌生人,让被试先通过照片打乱顺序看几遍,再进入判断阶段,判断该照片是否看过。然后通过正确率、反应时等指标进行比较。
实验思路
我们首先准备好一个包含128个人的人脸照片,如图1所示,其中64张为男生,64张为女生。
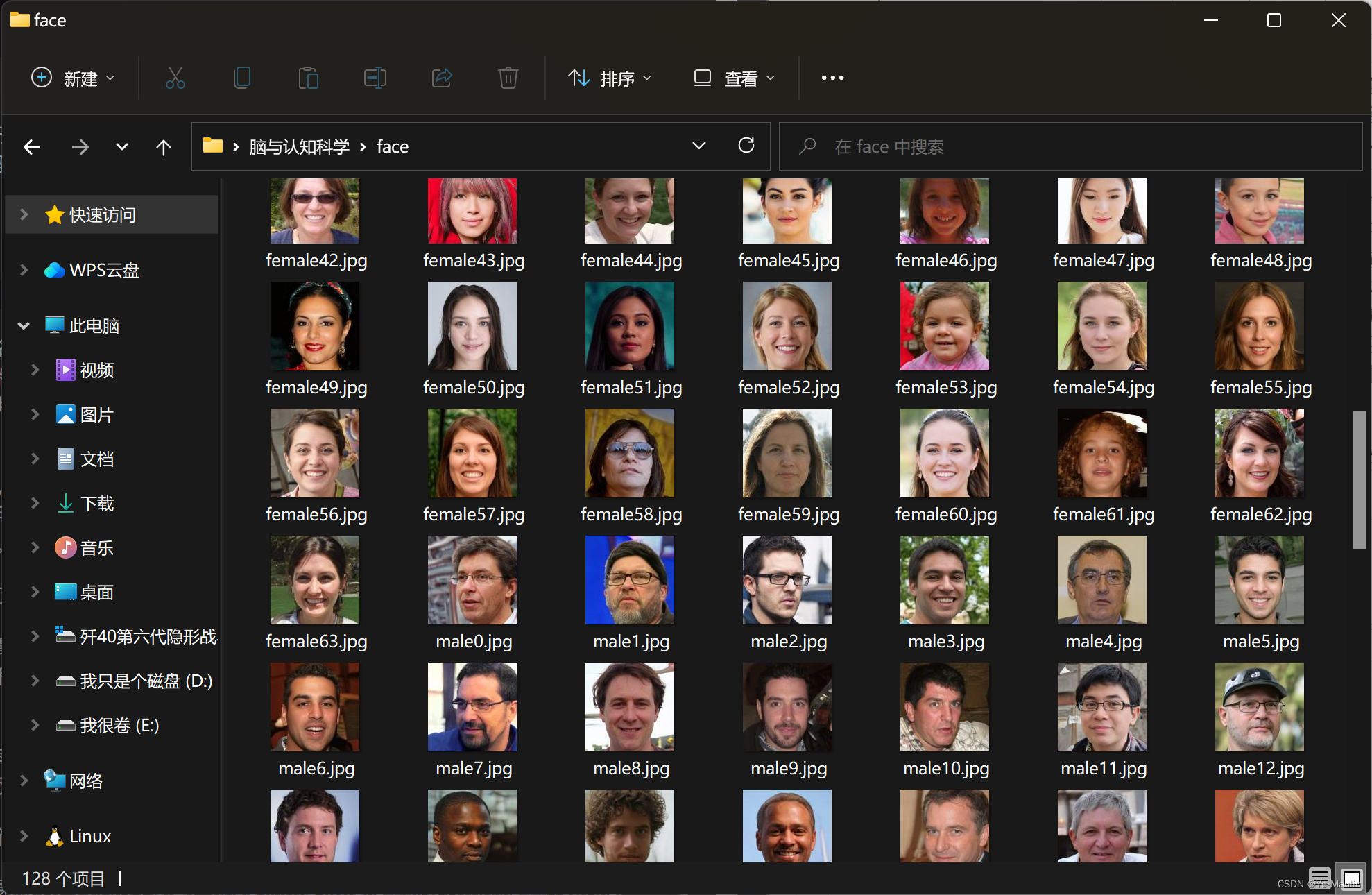
图1
我们实验的设计思路是,先从这128张照片中随机选出15张照片,然后向被试者展示这15张照片的前10张照片,并提示被试者尝试记住它们,然后从展示过的照片中随机选出5张和刚刚选取的15照片中未展示的后5张照片组成10张照片,打乱这10张照片的顺序,再次展示给被试者,被试者需要判断该图片是否展示过,记录过程中的正确率和反应时间。
实验流程图如图2所示。
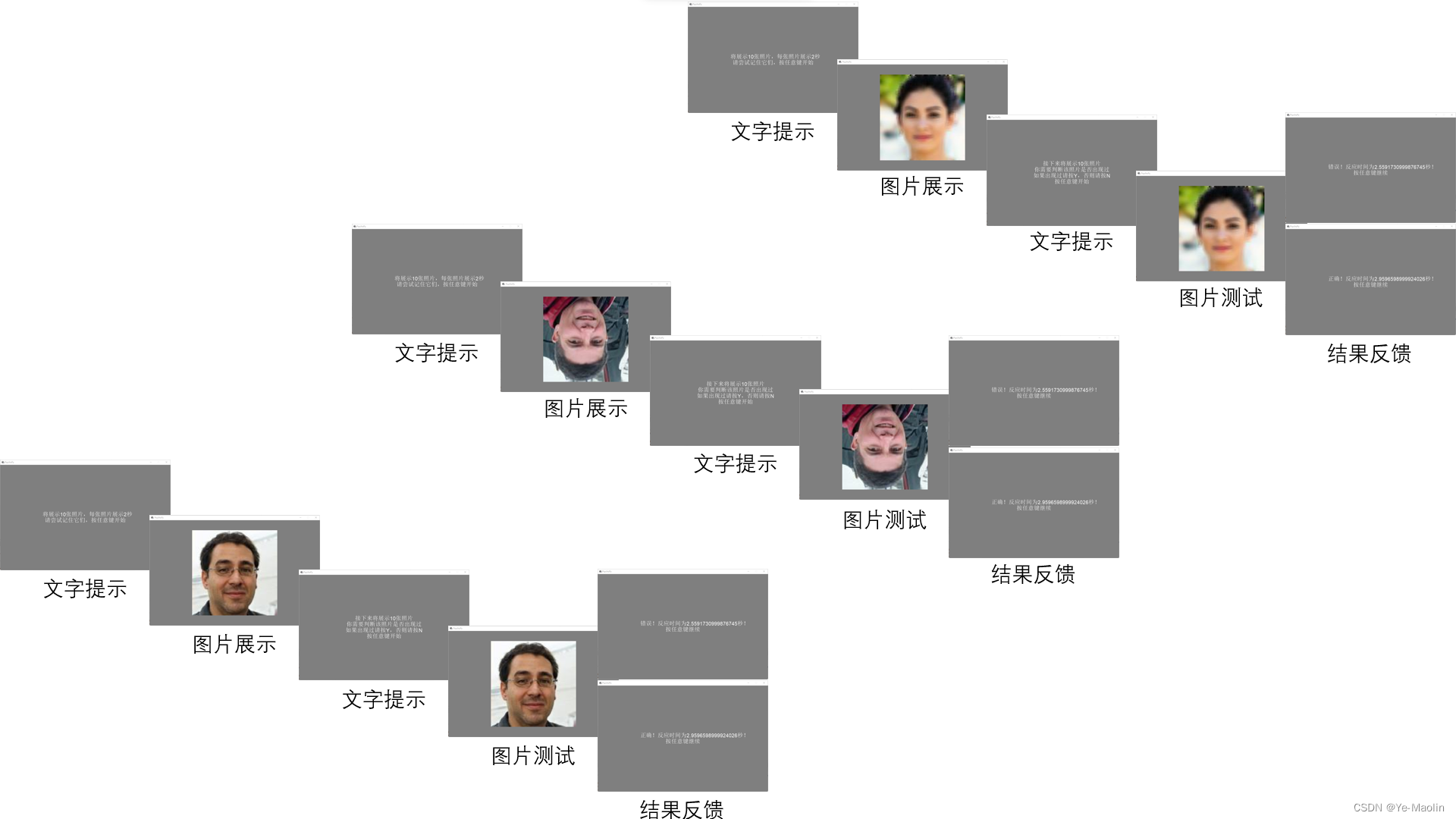
图2
我们设置了三个对照组。
- 原始照片对照组:这是基准对照组,接受未经过任何处理的原始照片。这个对照组的目的是确定参与者在没有任何外部干扰的情况下的表现,从而提供一个基准水平。
- 倒置照片对照组:这个对照组接受倒置的照片,以比较参与者在处理倒置图像时的表现。这个对照组可以帮助确定倒置图像对认知能力的影响。
- 模糊照片对照组:这个对照组接受模糊的照片,以比较参与者在处理模糊图像时的表现。这个对照组可以帮助确定模糊图像对认知能力的影响。
我们全程使用python的psychopy库完成实验的设计。
我们首先写一个函数,用于展示提示文字,被试者可以按任意键结束提示,如图3所示。

图3
然后从我们的人脸数据库中随机选出15张照片,然后向被试者展示这15张照片的前10张照片,并提示被试者尝试记住它们,每张照片展示2秒,如图4所示。

图4
然后从展示过的照片中随机选出5张和刚刚选取的15照片中未展示的后5张照片组成10张照片,打乱这10张照片的顺序,再次展示给被试者,被试者需要判断该图片是否展示过,如果展示过则输入Y,没有展示过则输入N,如图5所示。
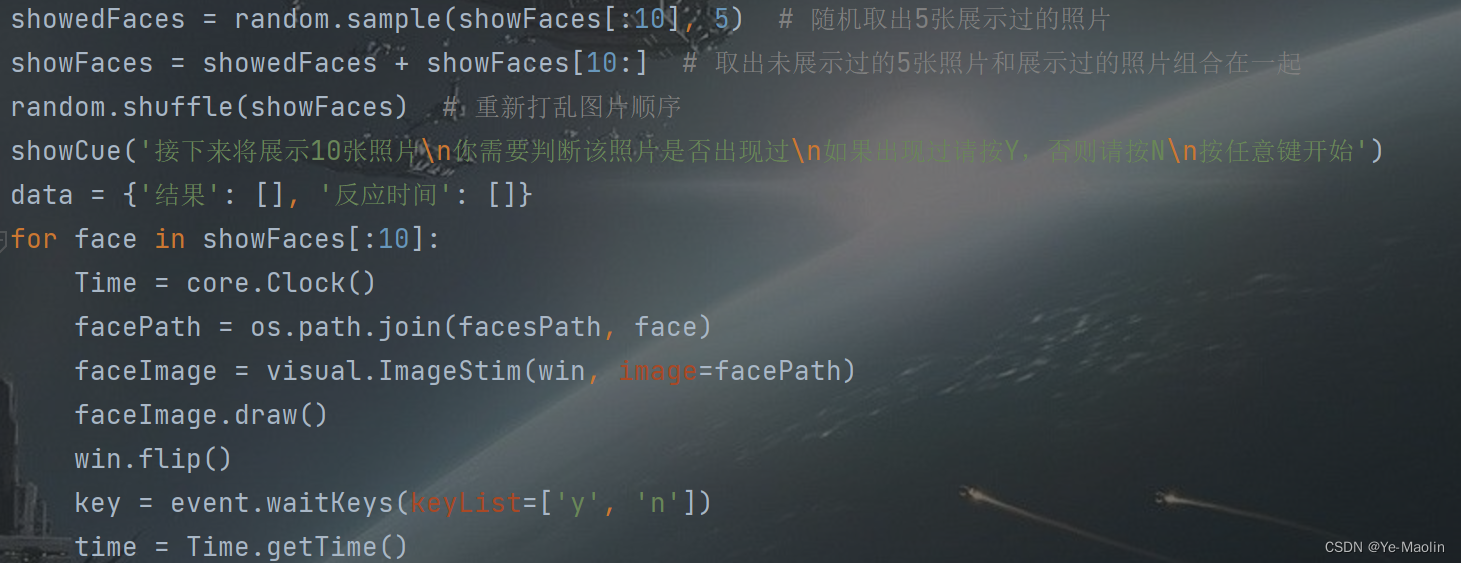
图5
记录过程中判断的正确率与被试者的反应时间,并输出反馈结果到窗口中,如图6所示。
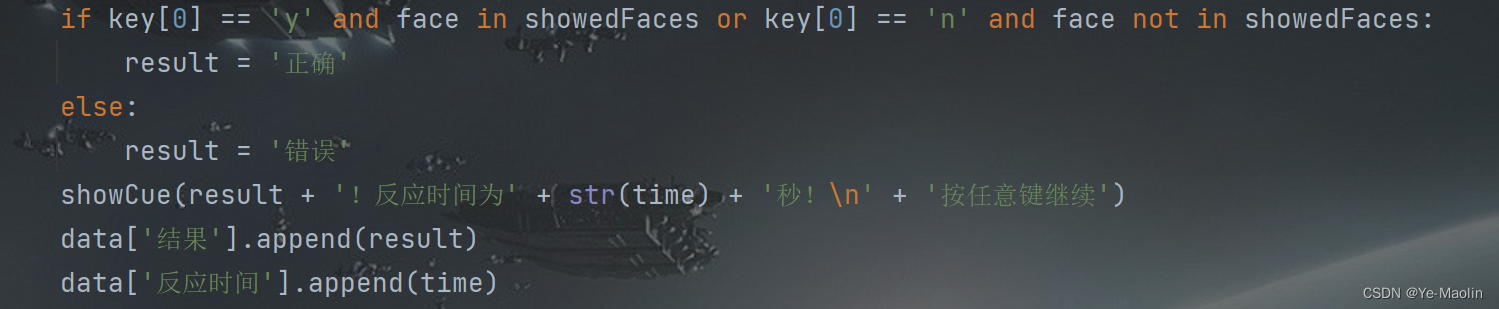
图6
最后将数据写入excel文件,如图7所示。

图7
对于图片的倒置处理,我们可以设置图片展示的旋转度为180度,如图8所示。
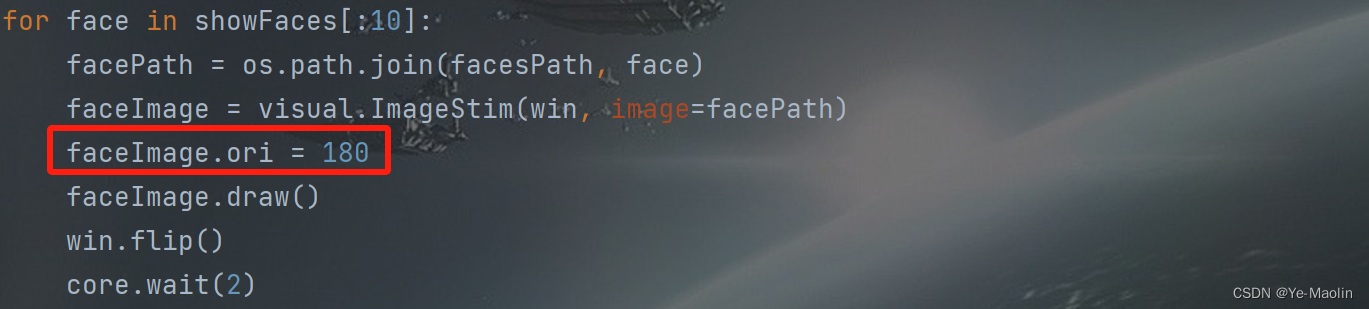
图8
对于图片的模糊处理,我们使用python的模糊滤波器库函数进行对图片模糊处理,如图9所示。
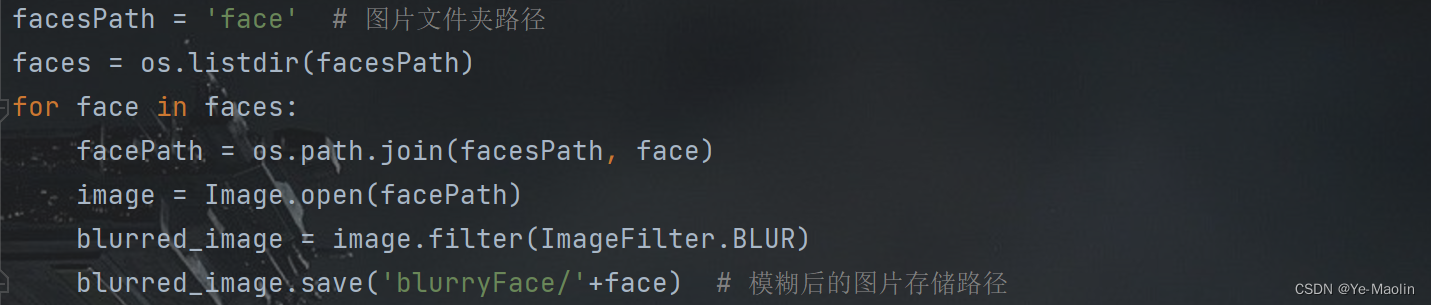
图9
然后我们开始运行程序,首先展示的是提示文字,如图10所示。

图10
原始图片组实验展示的图片如图11所示。

图11
倒置图片对照组展示的倒置图片如图12所示。

图12
模糊图片对照组展示的模糊图片如图13所示。

图13
然后显示提示文字,如图14所示。

图14
然后被试者判断展示的图片是否出现过,会给出判断结果和反应时间,如图15所示,为判断正确的结果。

图15
判断错误的结果如图16所示。

图16
经过多次实验,我们可以得到三组实验每组30次的记录数据,如图17所示。
图17
我们将数据进行整理,计算出每组实验的正确率,如图18所示。
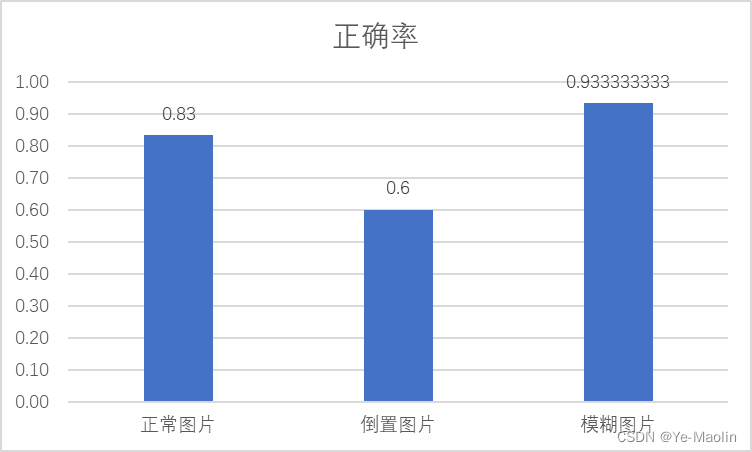
图18
每组实验记录的平均反应时间如图19所示。
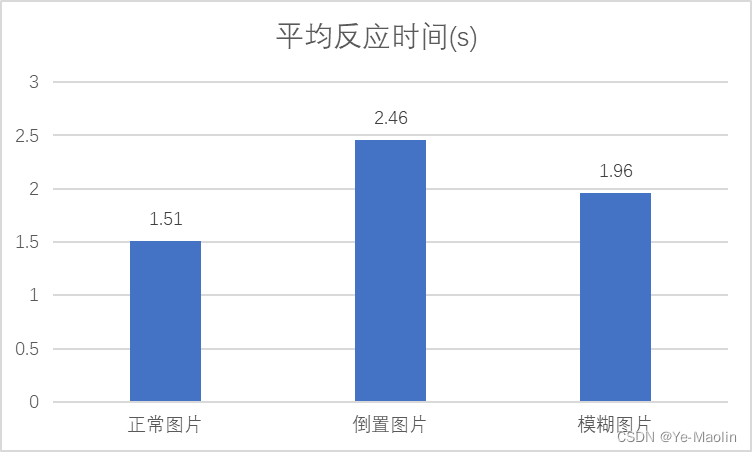
图19
由实验结果可以知道,人脸对于经过倒置和模糊处理的图像存在反应时间加长的情况,而且倒置处理比模糊处理的时长增加的更加明显。而对于正确率,实验结果显示,正确率最高的是模糊图片,其次是正常图片和倒置图片。
倒置图片的正确率比较低是因为人们在日常生活中接触到的大多数视觉信息都是正常方向的,我们对正常方向的物体和场景有更多的经验和熟悉度。当图片被倒置时,它与我们通常的观察经验不符,这可能导致我们处理图像时出现困惑或错误,也使得我们处理图像以及提取特征更加困难。
而模糊图片的正确率比较高可能是因为模糊图像可能会引起被试者更多的注意力,因为被试者需要更加集中精力去解释和理解图像,模糊图像通过简化和平滑图像,降低被试者的认知负荷,不需要处理过多的细节和复杂性,可以使被试者更容易理解和处理图像,当然也有可能是实验测试次数较少的原因。
python实现
import os
import random
import pandas
from psychopy import visual, event, core
# 展示提示文字
def showCue(text):
cue = visual.TextStim(win, text=text, pos=(0, 0))
cue.draw()
win.flip()
event.waitKeys()
facesPath = 'face'
faces = os.listdir(facesPath)
showFaces = random.sample(faces, 15)
win = visual.Window(size=(1000, 618))
showCue('将展示10张照片,每张照片展示2秒\n请尝试记住它们,按任意键开始')
for face in showFaces[:10]:
facePath = os.path.join(facesPath, face)
faceImage = visual.ImageStim(win, image=facePath)
faceImage.draw()
win.flip()
core.wait(2)
showedFaces = random.sample(showFaces[:10], 5) # 随机取出5张展示过的照片
showFaces = showedFaces + showFaces[10:] # 取出未展示过的5张照片和展示过的照片组合在一起
random.shuffle(showFaces) # 重新打乱图片顺序
showCue('接下来将展示10张照片\n你需要判断该照片是否出现过\n如果出现过请按Y,否则请按N\n按任意键开始')
data = {'结果': [], '反应时间': []}
for face in showFaces[:10]:
Time = core.Clock()
facePath = os.path.join(facesPath, face)
faceImage = visual.ImageStim(win, image=facePath)
faceImage.draw()
win.flip()
key = event.waitKeys(keyList=['y', 'n'])
time = Time.getTime()
if key[0] == 'y' and face in showedFaces or key[0] == 'n' and face not in showedFaces:
result = '正确'
else:
result = '错误'
showCue(result + '!反应时间为' + str(time) + '秒!\n' + '按任意键继续')
data['结果'].append(result)
data['反应时间'].append(time)
win.close()
# 将数据写入excel
excel = 'normalData.xlsx'
df = pandas.DataFrame(data)
try:
DF = pandas.read_excel(excel) # 该execl文件已经存在则追加数据
DF = pandas.concat([DF, df], ignore_index=True)
DF.to_excel(excel, index=False)
except FileNotFoundError: # 没有该excel文件将创建一个新的
df.to_excel(excel, index=False)