大模型的全面回顾,看透大模型 | A Comprehensive Overview of Large Language Models
大模型的全面回顾:A Comprehensive Overview of Large Language Models
返回论文和资料目录
论文地址
1.导读
相比今年4月的中国人民大学发表的大模型综述,这篇综述角度更侧重于大模型的实现,更加硬核,更适合深入了解大模型的一些细节。
2.介绍
下图给出了近几年开源或闭源的大模型趋势图。可以看到除了2023年闭源的大模型工作下降了,这些年的大模型不管开源,闭源,还是总量都是稳步提升。不过这篇论文还有很多大模型工作没有考虑到,例如,百川大模型、ChatGLM3和浦育大模型等等。今年以来,真实场景是百模大战!

下图给出了作者看到近几年代表性大模型的时间轴。

下图是大模型的全面回顾结构图,包括1. 训练 2. 推理 3. 评估 4. 应用 5. 挑战。

3.相关基础
1.Tokenization(词元编码)
Tokenization做的事情是把正常的文本转化为输入大模型的id列表list,是一个必要的预处理步骤。读者可以参考这个博客进行学习。
2. Attentions(注意力机制)
Self-Attention:原Transformer的注意力机制。
Cross Attention:Cross-attention的输入来自不同的序列,Self-attention的输入来自同序列。例如,可以讲图片编码后信息得到Q,文本编码后得到K,V。然后和Self-attention一样的方式计算得到结果。
Full Attention:原Transformer的注意力机制,与Self-attention一样。
Sparse Attention:原本self-attention中会得到一个full-attentions的score矩阵,表示了每个词与其他词之间的关系。在Sparse Attention中会把一些词与词之间的score置为0,通过这种方式可以扩展模型的上下文长度。例如可以进行下面这种方式处理。

其中
Flash Attention:注意力机制原理和Self-Attention一样,没有变化。改变的是Attention在gpu中的计算方式,可以减少访问内存的数据量。计算结果是一样的。
3. Encoding Positions(位置编码)
在tokenization后模型给输入文本加入位置编码,这步是必需要的(虽然最近也有研究说不重要)。有两种思路:
- 绝对的:这是添加序列顺序信息的最直接的方法,通过在将其传递给注意模块之前,为序列的每个位置分配一个唯一的标识符。例如Alibi
- 相对编码:为了传递在序列中不同位置出现的不同标记的相对依赖性信息,通过某种学习来计算相对位置编码。两种著名的相对编码类型是RoPE
4.Activation Functions(激活函数)
常见的激活函数如下:
- ReLU:ReLU(x) = max(0, x)
- GeLU:是ReLU, Dropout和Zoneout的组合,是在LLM中最广泛使用的。
- GLU:LLM会使用GLU(x, W, V, b, c) = (xW + b) ⊗ σ(xV + c) 的变体,包括 1. ReGLU(x, W, V, b, c) = max(0, xW + b)⊗, 2. GEGLU(x, W, V, b, c) = GELU(xW + b) ⊗ (xV + c) , 3. SwiGLU(x, W, V, b, c, β) = Swishβ(xW + b) ⊗ (xV + c)
5.Layer Normalization(正则化)
-
LayerNorm:和BatchNorm不同的维度。其中 n n n是 l l l层中神经元的数量, a i l a^l_i ail是 l l l层中 i i i个神经元的输入之和。
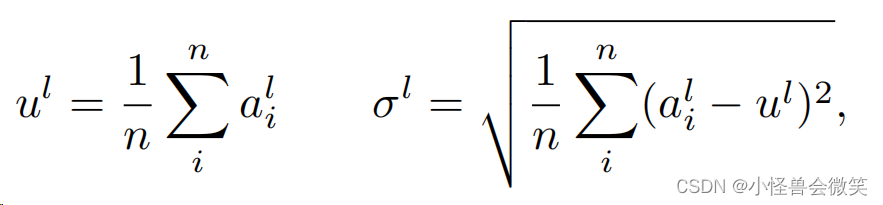
-
RMSNorm:基于LayerNorm变化而来,提出通过使用一种计算效率高的快速交换重定中心不变性的标准化技术,可以获得与LayerNorm相同的性能效益。
LayerNorm给出了对第 l l l层的归一化求和输入,如下所述

其中 g i l g^l_i gil是增益参数。RMSNorm将一个 l i l_i li修改为

-
Pre-Norm and Post-Norm:注意这两个不是一个Normalization技术,而是指在残差连接前还是连接后进行Normalization。通常称原本在Transformer中提出的在res后的叫Post-Norm: x t + 1 = N o r m ( x t + F t ( x t ) ) x_{t+1}=Norm(x_t+F_t(x_t)) xt+1=Norm(xt+Ft(xt)),顺序如下图所示。

最近发现在顺序变为Pre-Norm: x t + 1 = x t + F t ( N o r m ( x t ) ) x_{t+1}=x_t+F_t(Norm(x_t)) xt+1=xt+Ft(Norm(xt)),可以训练更稳定,顺序如下图所示,需要注意的是这里res连接的是LN前的输出和attention的输出。

-
DeepNorm:解决早期的层比底部有更大的梯度的问题。
6. Distributed LLM Training(LLM分布式训练)
在多机多卡上训练过大模型的应该了解,如何分布式并行训练是门学问!
假设我们有8个gpu,一个batch为16条数据,模型主要有8层decoder结构,decoder的隐藏层维度是512。
-
数据并行(Data Parallelism)
在数据并行中,我们将整个训练数据划分成多个小批次,每个GPU负责计算其中一部分数据的梯度。具体来说,对于8个GPU和一个batch size为16的情况,每个GPU将处理2条数据。在计算完成后,梯度将被汇总,模型参数将被更新。这样一来,整个batch的计算过程被分散到各个GPU上,加速了训练过程。 -
张量并行(Tensor Parallelism)
张量并行是一种将模型的权重划分到不同的GPU上进行计算的策略。在我们的例子中,8层decoder结构中的权重可以被分割到不同的GPU上。每个GPU负责计算其中一部分权重对应的梯度。这样的划分可以在较小的GPU上运行大型模型。 -
管道并行(Pipeline Parallelism)
管道并行将模型的不同部分分配给不同的GPU,每个GPU负责处理整个模型中的一部分。在我们的例子中,每个GPU计算一个decoder层的结果,然后将其传递给下一个GPU。这样的流水线处理可以减小每个GPU上的模型规模,从而使得更大的模型能够适应有限的GPU内存。 -
模型并行(Model Parallelism)
模型并行是张量和管道并行的结合。在这种策略中,模型被分解成多个部分,每个部分分配给不同的设备进行计算。这种策略通常用于较大的模型,其中一个GPU无法容纳整个模型。 -
3D并行(3D Parallelism)
3D并行是一种结合数据并行、模型并行以及时间并行(通常用于处理序列数据)的综合并行策略。在我们的例子中,可以考虑在时间维度上(例如,序列的不同时间步)进行并行化,进一步提高训练速度。 -
优化器并行(Optimizer Parallelism)
优化器并行,也称为零冗余优化器,实现了优化器状态、梯度和参数在设备之间的划分,以降低内存消耗,同时尽可能地降低通信成本。这种策略在处理大型模型时尤为有用。
7.常用库
训练
- Transformers
Transformers 是Hugging Face开发的一款强大的自然语言处理(NLP)库。它提供了各种预训练的模型,涵盖了从文本生成到情感分析等多个任务,为NLP社区提供了丰富的资源。
- DeepSpeed
DeepSpeed 是由Microsoft Research开发的深度学习训练库,旨在提高大规模模型的训练速度和效率。其特点包括混合精度训练、模型并行化和数据并行化等。
- Megatron-LM
Megatron-LM 是NVIDIA Research开发的一个大规模深度学习库,专注于大型语言模型的训练。它支持模型并行和数据并行,并针对多GPU系统进行了优化。
- JAX
JAX 是由Google Research推出的一个数值计算库,它能够自动求导并进行高性能的GPU/TPU加速。JAX的特点在于其简洁的API和对函数式编程的支持。
- Colossal-AI
Colossal-AI 是一款面向大规模模型的深度学习训练库。它支持分布式训练、模型并行和数据并行,旨在解决训练大型模型时的性能瓶颈。
- BMTrain
BMTrain 是一个用于医学图像分割任务的深度学习训练库。它提供了一套专门设计的工具,以应对医学领域中数据复杂性和任务特殊性。
- FastMoE
FastMoE 是慕尼黑大学的研究团队推出的深度学习库,专注于快速的深度模型训练。它使用了Mixture-of-Experts(MoE)结构,以提高训练速度。
框架
- MindSpore
MindSpore 是华为开发的深度学习框架,支持数据并行和模型并行,同时提供了易用的Python API和图模式训练。
- PyTorch
PyTorch 是由Facebook开发的深度学习框架,以其动态计算图和直观的API而闻名。PyTorch广泛应用于学术界和工业界,支持动态图和静态图。
- TensorFlow
TensorFlow 是由Google开发的深度学习框架,支持静态图和动态图,广泛用于深度学习研究和实际应用。
- MXNet
MXNet 是一个开源的深度学习框架,具有动态图和静态图的优势。MXNet支持多种编程语言,并在训练大型模型时表现出色。
8.Data PreProcessing(数据预处理)
- 质量过滤:方法①基于分类的,训练一个模型判断质量好坏②基于启发的,人工确定一些规则进行过滤,比如语言、指标、统计数据和关键字。
- 重复数据删除
- 隐私减少
9. Architectures(架构)
- Encoder Decoder:transformer
- Causal Decoder:decoder-only
- Prefix Decoder:先encoder,再decoder
10.模型微调
模型微调框架如下图所示:

对齐微调
在大规模语言模型(LLMs)的生成过程中,存在生成错误、有偏见和有害文本的问题。为了使这些模型更加有益、真实和无害,研究人员通过人类反馈来进行模型对齐。对齐包括让LLMs生成意外的响应,然后通过更新它们的参数来避免这些响应,从而确保模型生成的文本符合人类的意图和价值观。
Criteria for Aligned Models: HHH - Helpful, Honest, Harmless:一个被定义为“对齐”的模型必须符合三个标准,即有帮助(Helpful)、真实(Honest)和无害(Harmless),或者称之为“HHH”标准。这确保了LLMs的操作符合人类的意图和价值观。
Reinforcement Learning with Human Feedback (RLHF) for Alignment:研究人员采用强化学习与人类反馈(RLHF)来进行模型对齐。在RLHF中,通过对演示进行微调的模型进一步通过奖励建模(RM)和强化学习(RL)进行训练。下面我们简要讨论RLHF中的RM和RL流程。
Reward Modeling (RM):奖励建模训练一个模型,根据人类的偏好使用分类目标对生成的响应进行排名。为了训练分类器,人类根据HHH标准对LLMs生成的响应进行注释。
Reinforcement Learning (RL):结合奖励模型,RL在下一个阶段用于对齐。之前训练过的奖励模型将LLMs生成的响应分为首选和不首选,然后使用近端策略优化(PPO)将模型与之对齐。这个过程迭代重复直到收敛。
通过RLHF,研究人员可以有效地对齐LLMs,确保其生成的文本更符合人类期望,同时保持帮助性、真实性和无害性。这一对齐过程对于确保大型语言模型的实际应用中不会产生潜在的问题至关重要。
高效参数微调方法
在训练大型语言模型(LLMs)时,需要庞大的内存和计算资源。为了在使用更少资源的情况下进行训练,研究人员提出了各种参数高效微调技术,通过更新少量参数来实现微调,可以是添加新参数到模型或更新现有参数。以下是一些常用的方法:
Prompt Tuning
Prompt Tuning是一种引入可训练的提示token嵌入的技术。通过将提示token嵌入作为前缀或自由样式添加到输入token嵌入中,仅对这些嵌入参数进行微调,而保持其余权重冻结。在下游任务的微调过程中,只有这些嵌入参数被训练,其余权重保持不变。这种方法有助于在使用有限资源的情况下更有效地微调语言模型。
Prefix Tuning
Prefix Tuning是另一种参数高效微调方法,它引入了任务特定的可训练前缀向量到Transformer层中。在这种方法中,只有前缀参数被微调,而模型的其余部分保持冻结。输入序列的token可以关注这些前缀,充当虚拟令牌。这样一来,在微调中只需要训练前缀参数,从而实现了对资源的更有效利用。
Adapter Tuning
Adapter Tuning引入了一个编码器-解码器结构,被放置在Transformer块中的注意力和前馈层之后,或并行注意力和前馈层。在这种方法中,只有这些层被微调,而模型的其余部分被保持冻结。通过保持大部分模型参数冻结,
这些参数高效微调方法在资源受限的情况下变得尤为重要。通过针对模型的特定部分进行微调,研究人员能够最大限度地提高性能而不牺牲资源效率。
3.大模型
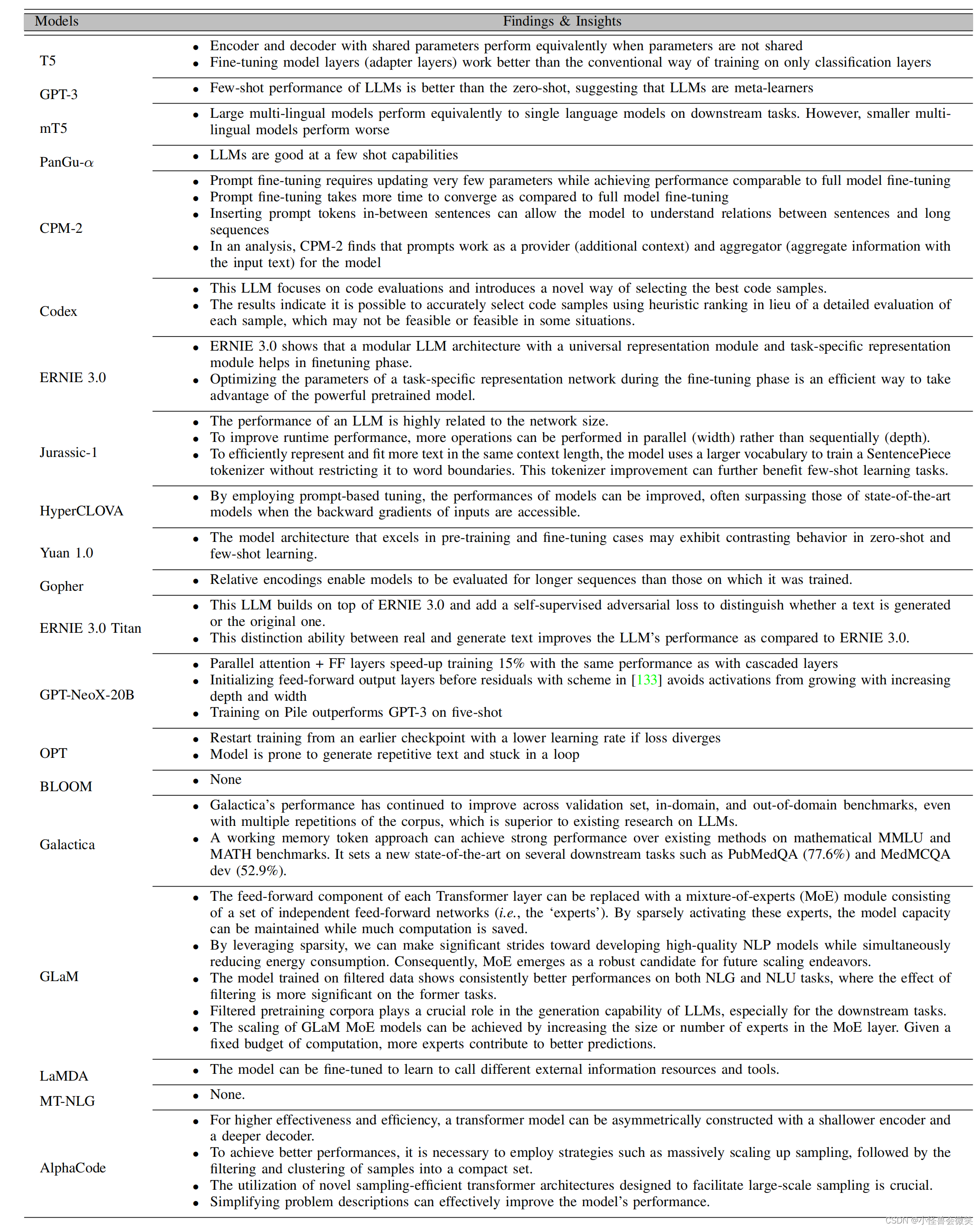
1.常见预训练模型

2.大模型微调
- 人工制作数据集微调
- LLM生成数据集微调
- 对齐人类偏好:RLHF,RLAIF(RL from AI feedback)
- 持续地预训练
3.增加上下文窗口
- 插入位置编码
- 使用高效注意机制
- 不训练进行扩展:参考 LM-Infinite 和 PCW。
4.机器人
被用于计划/规划、操作/行动和导航/走路。
5.多模态
MLLM可以参考另外一篇多模态综述。
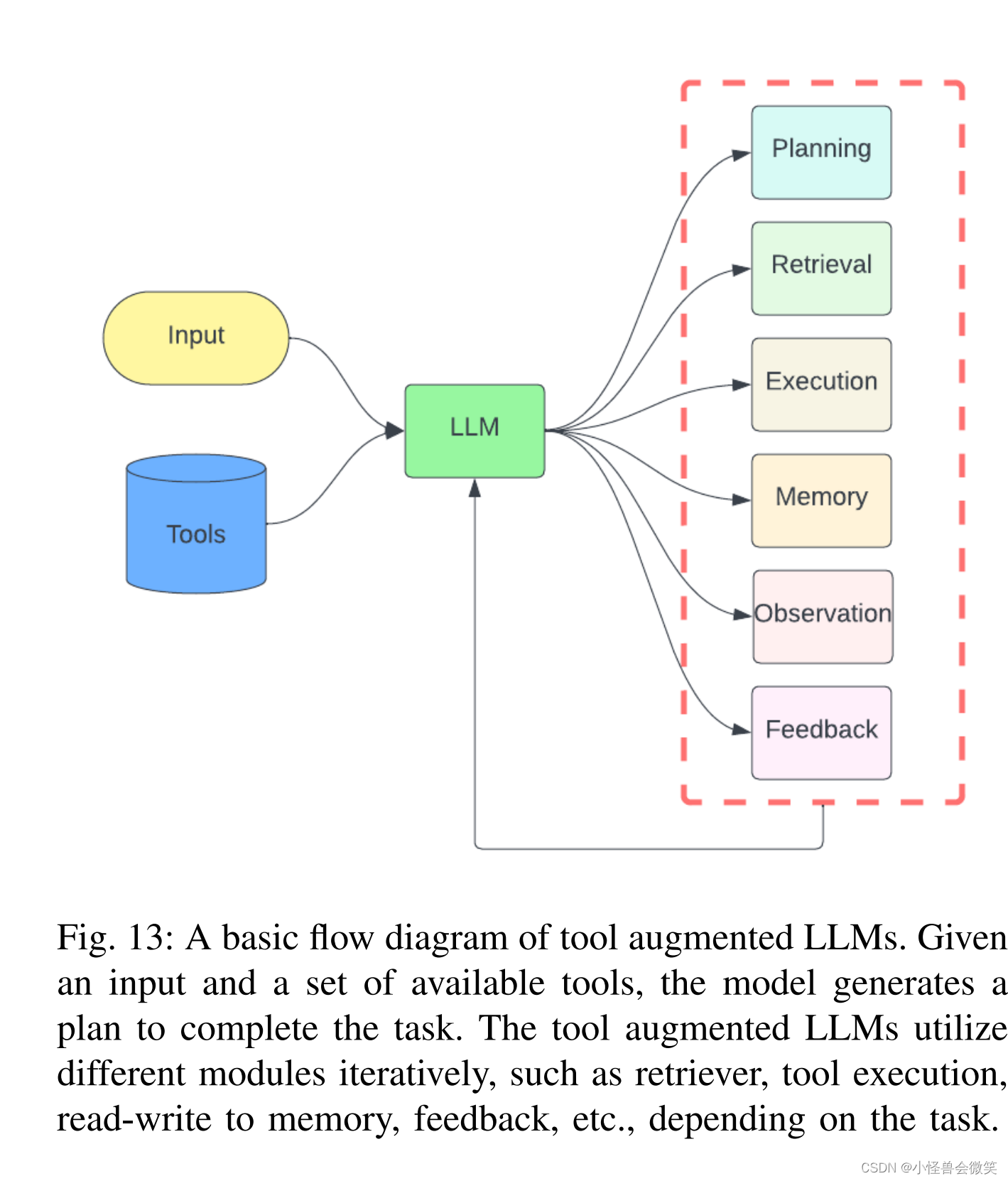
6.工具增强的LLM
- 检索增强:基于数据库等工具,增强LLM的能力。因为这个比较重要,单独列了个小点。
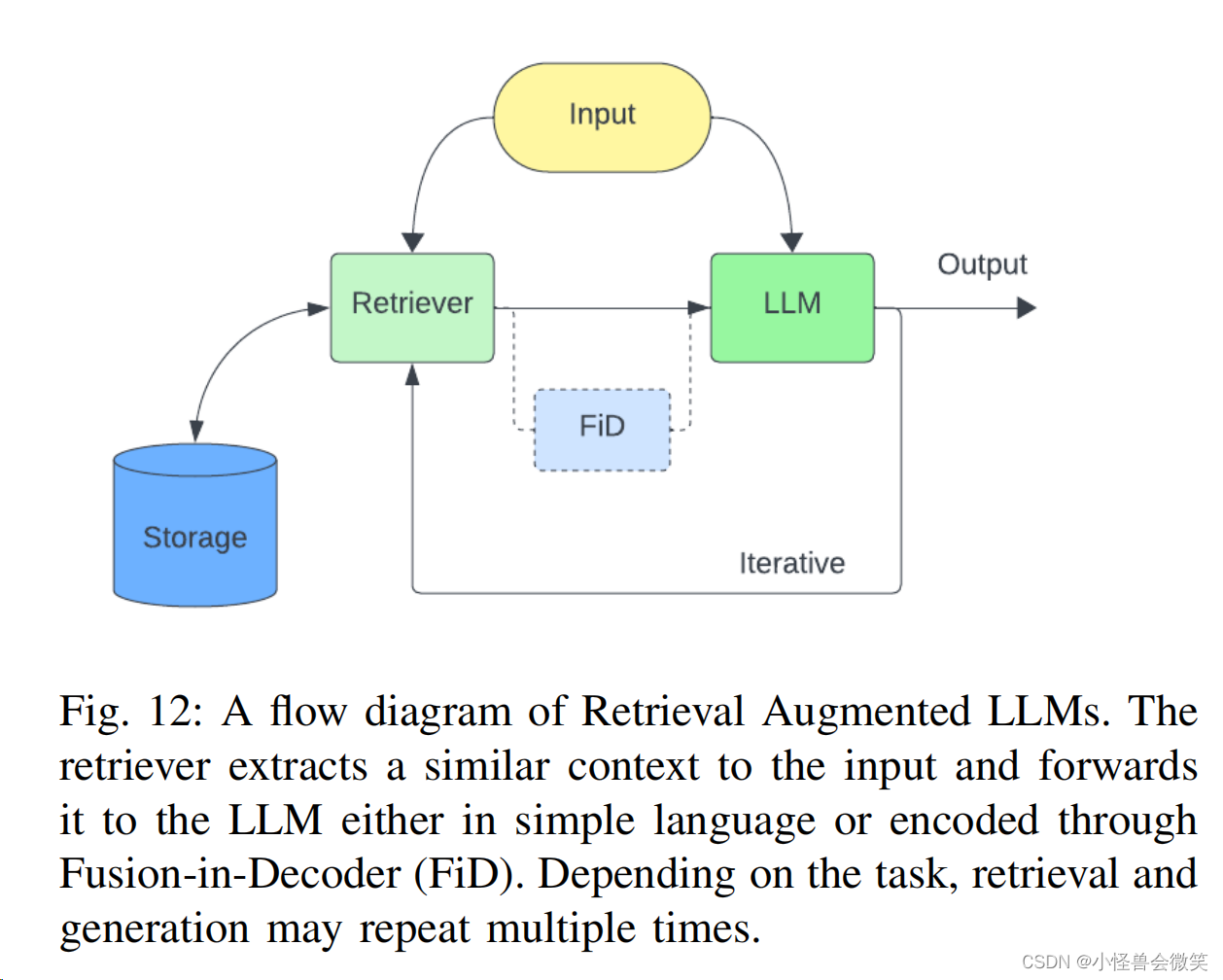
2. 工具增强: 借助外部工具增强。这部分很多花活了。
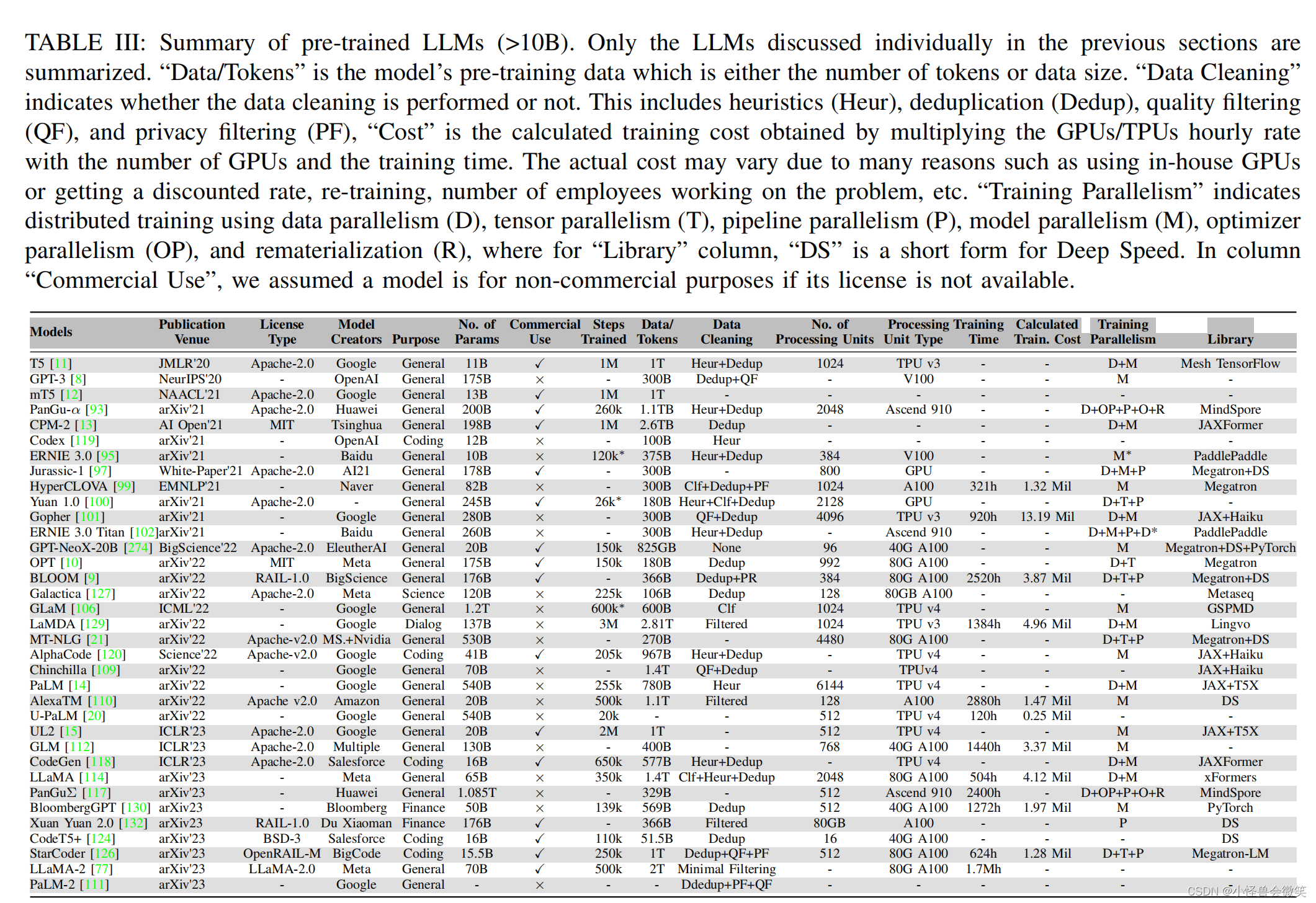
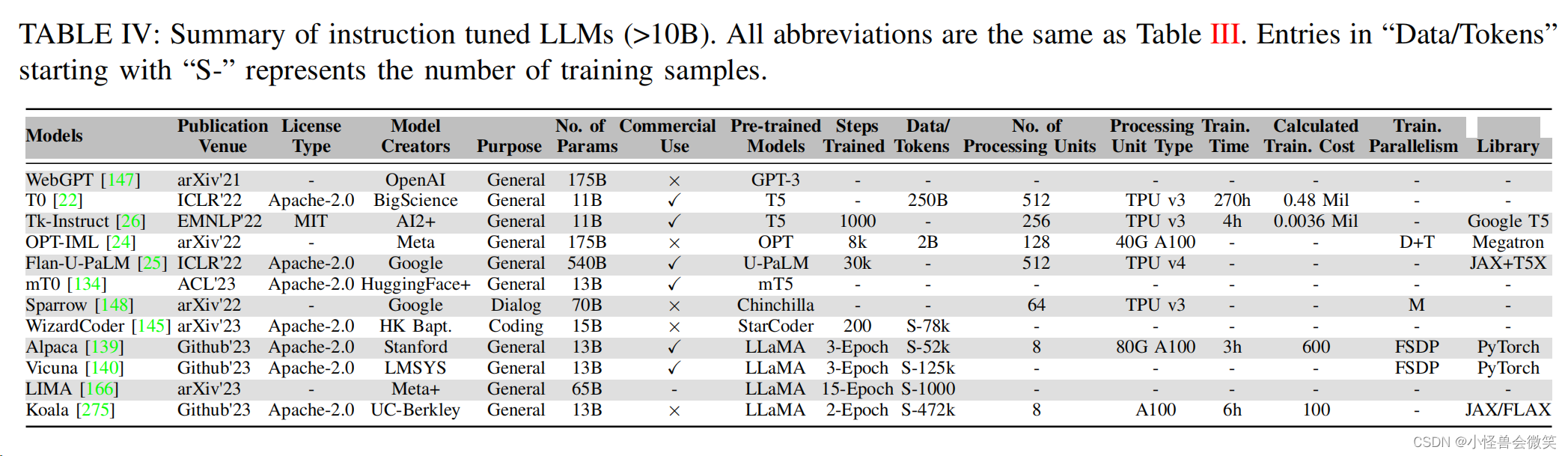
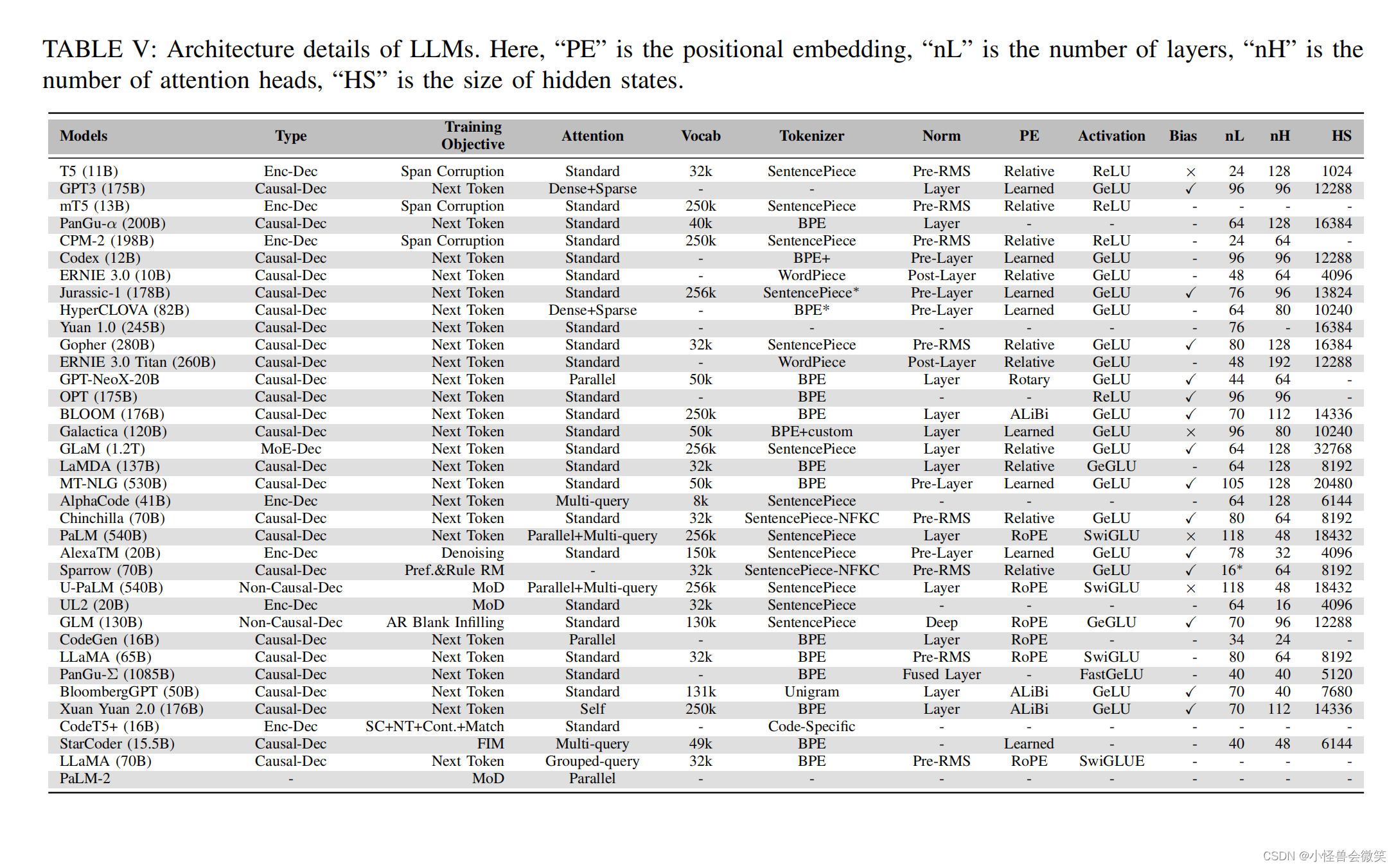
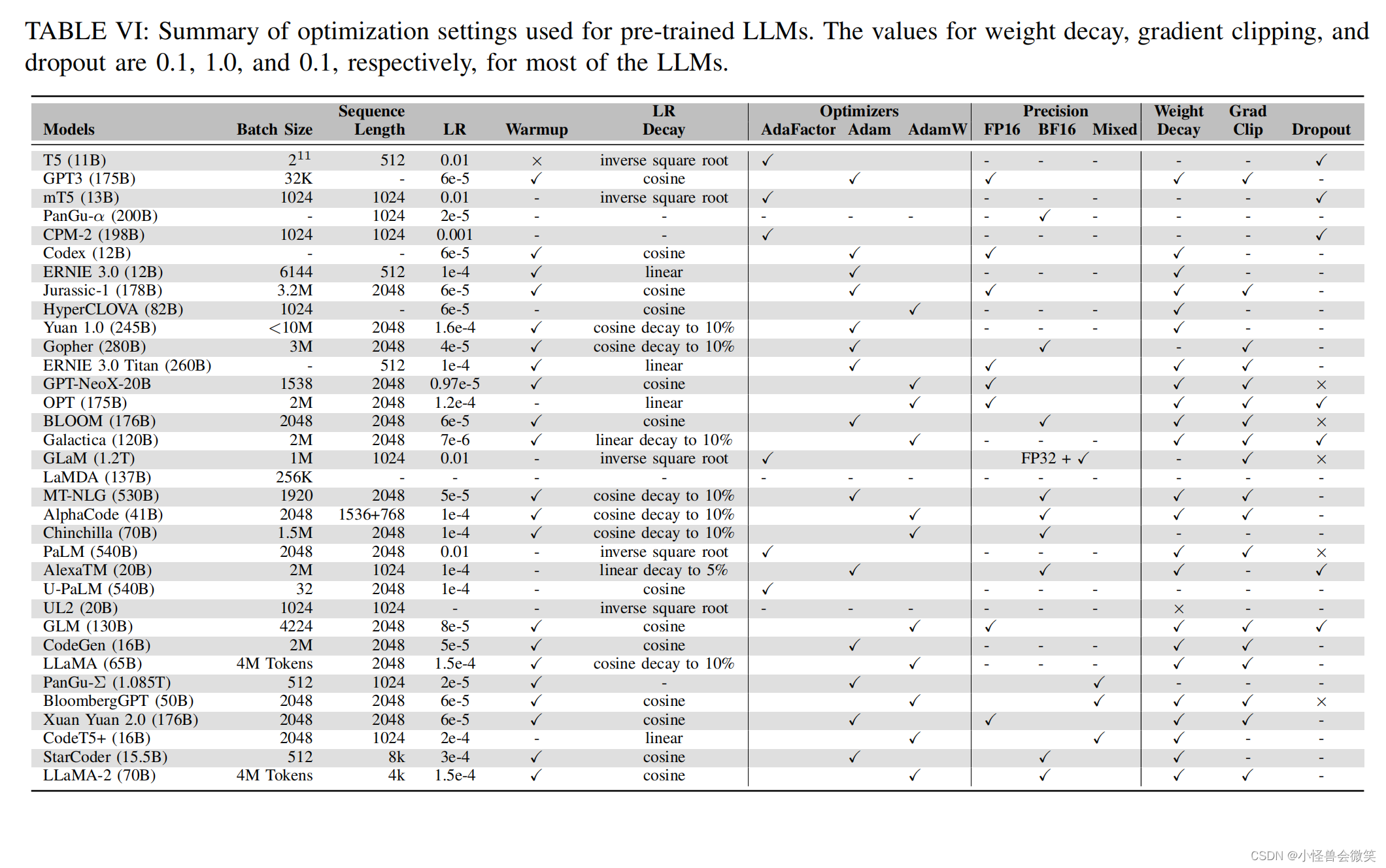
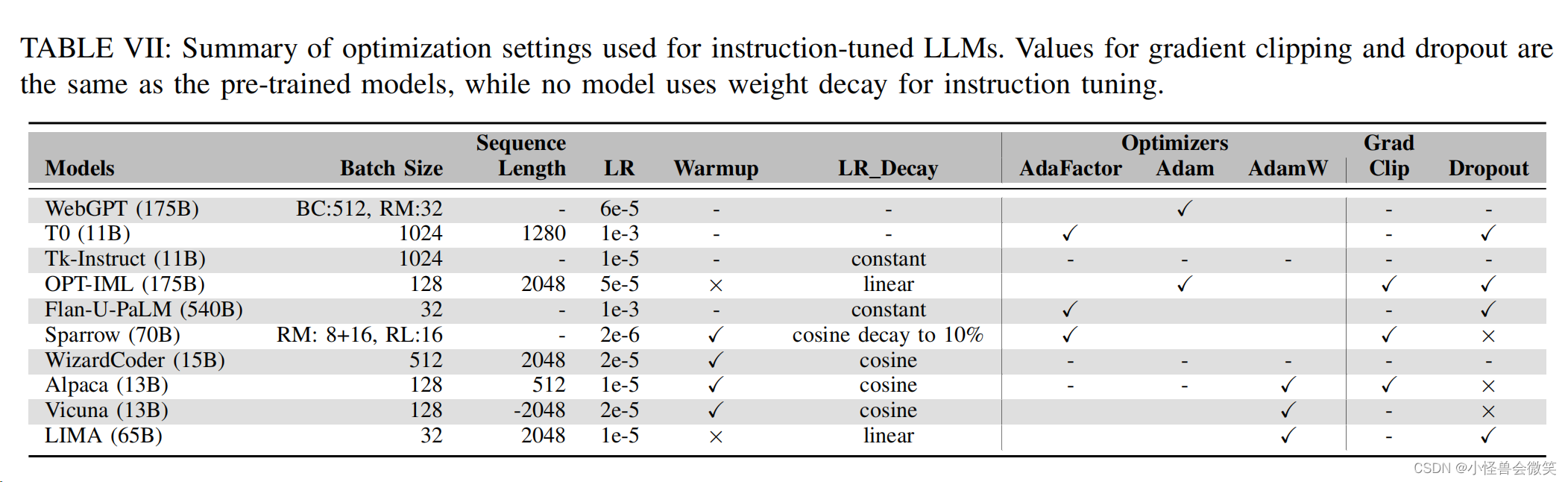
4.模型配置
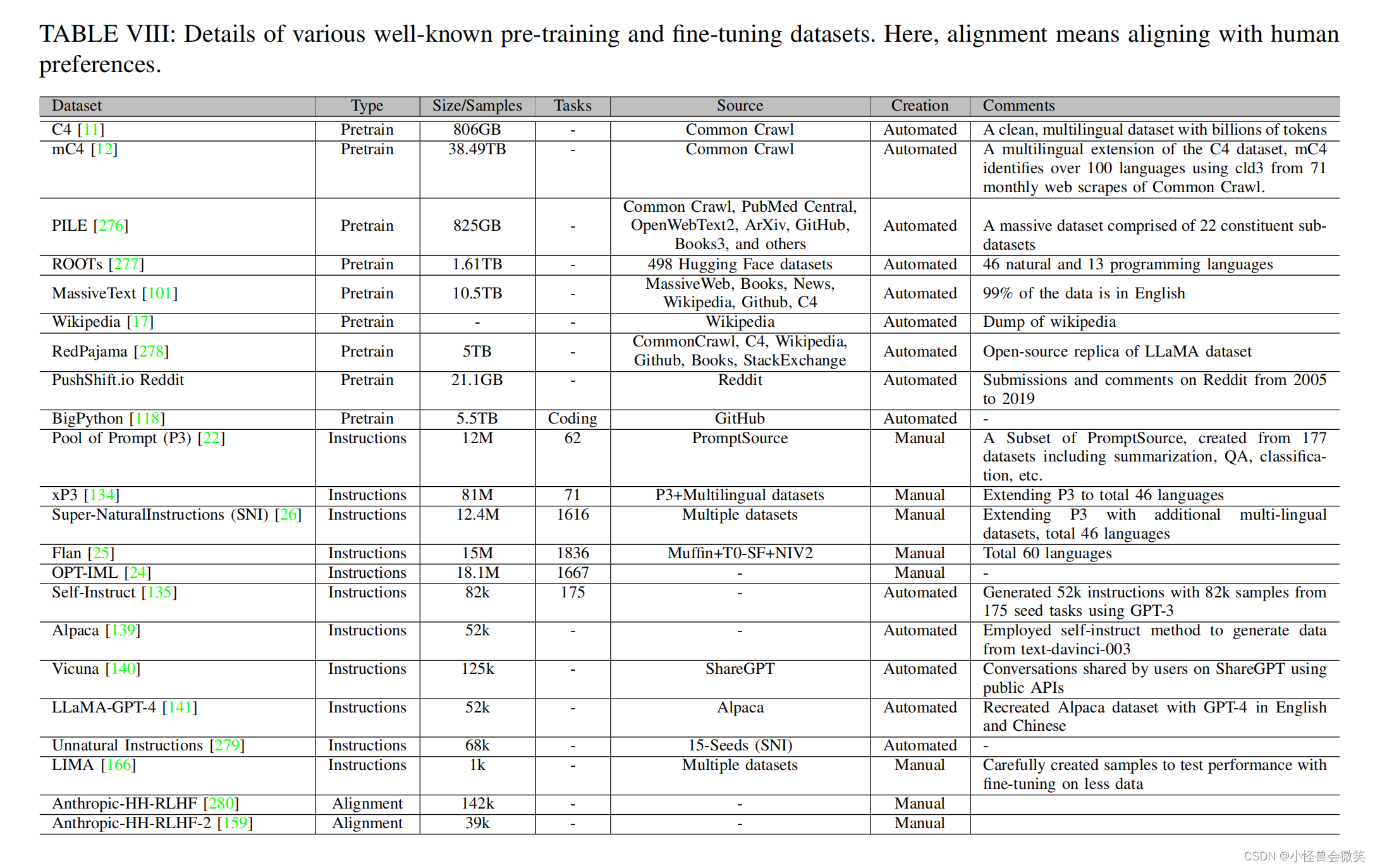
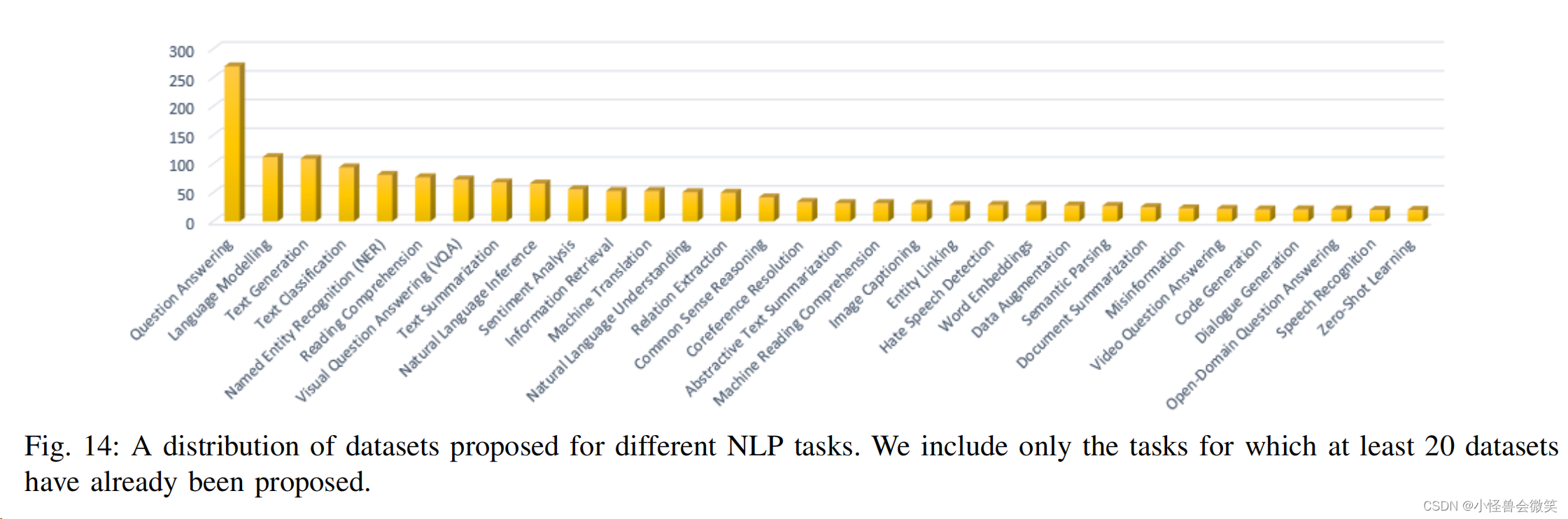
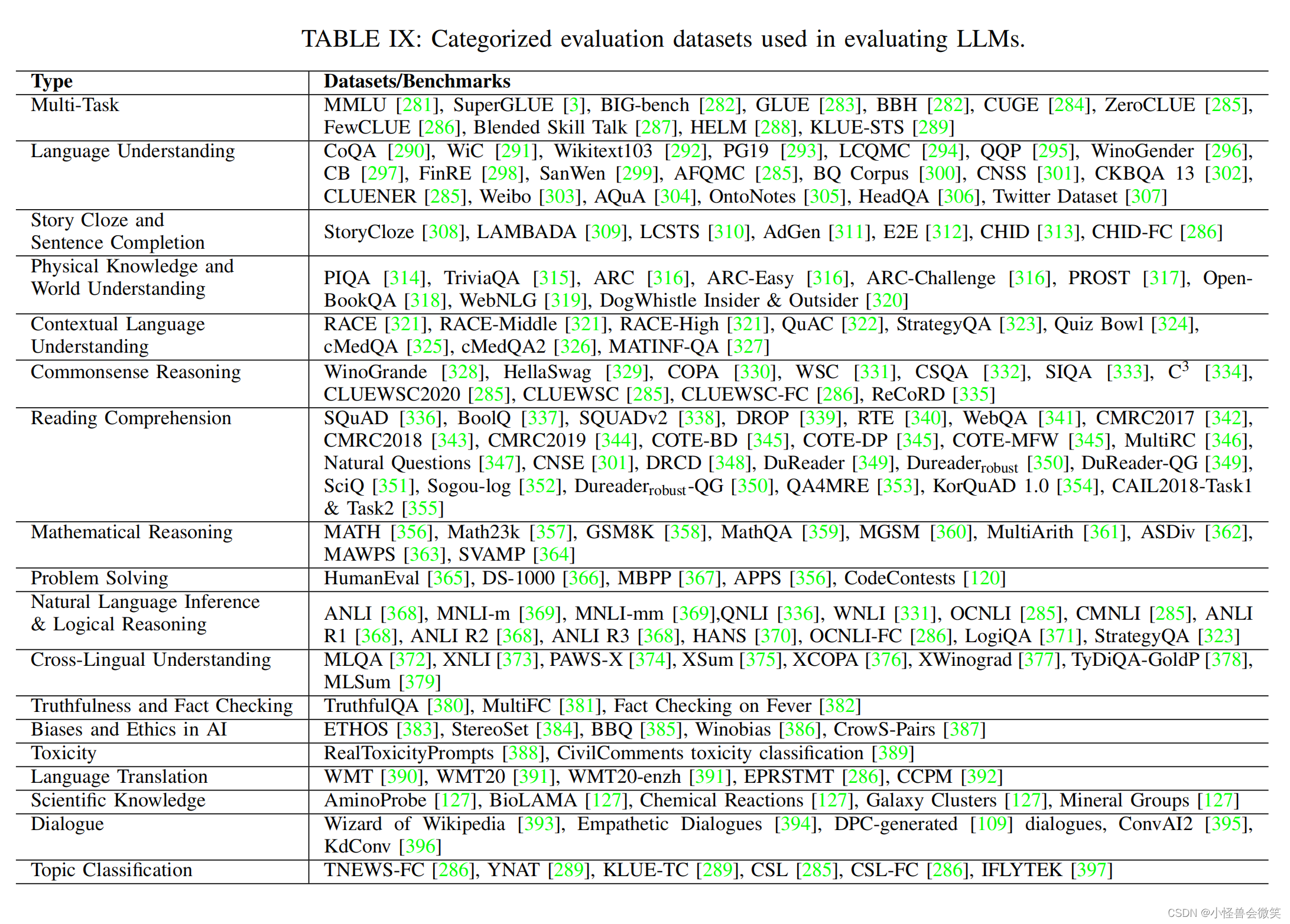
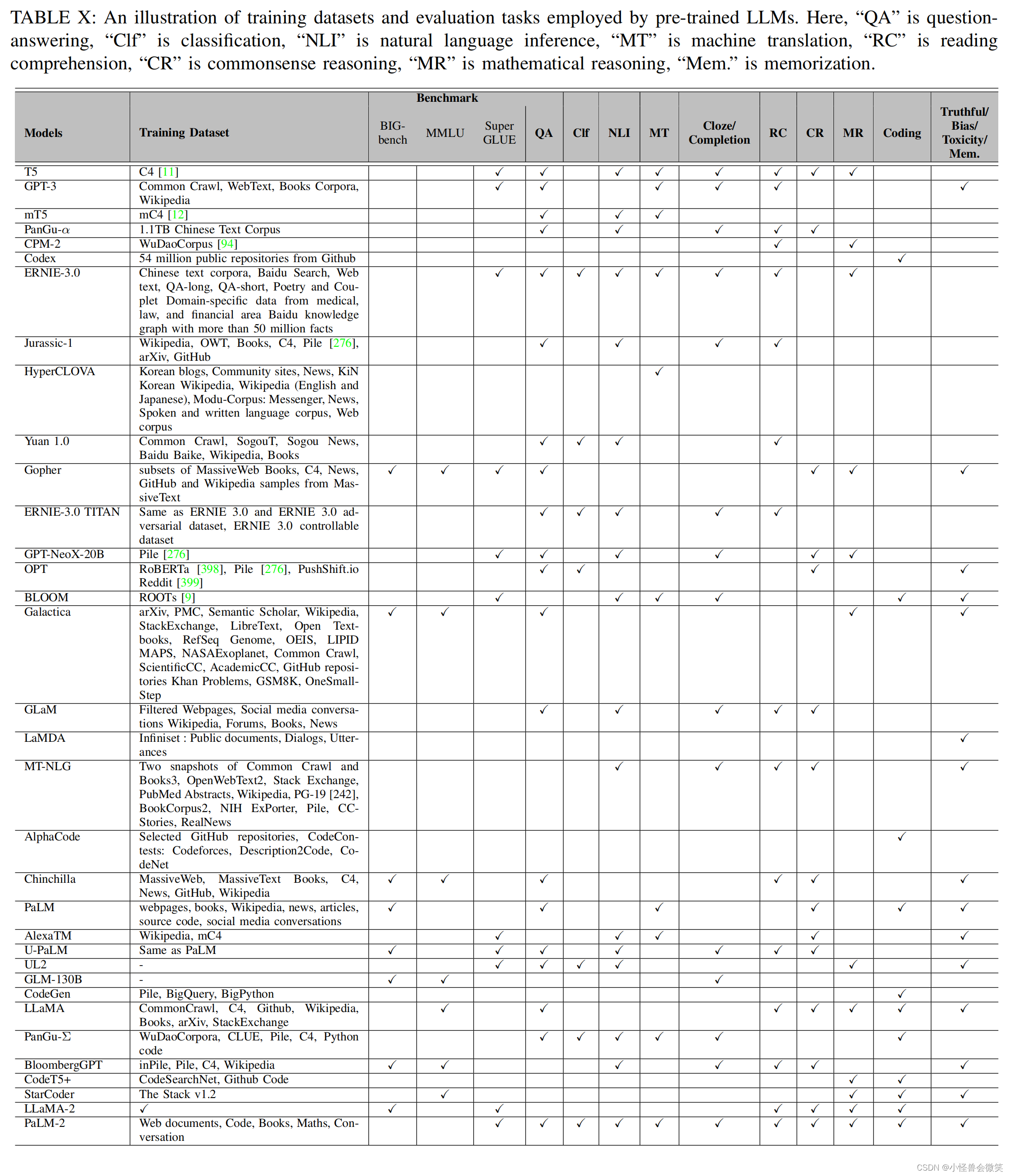
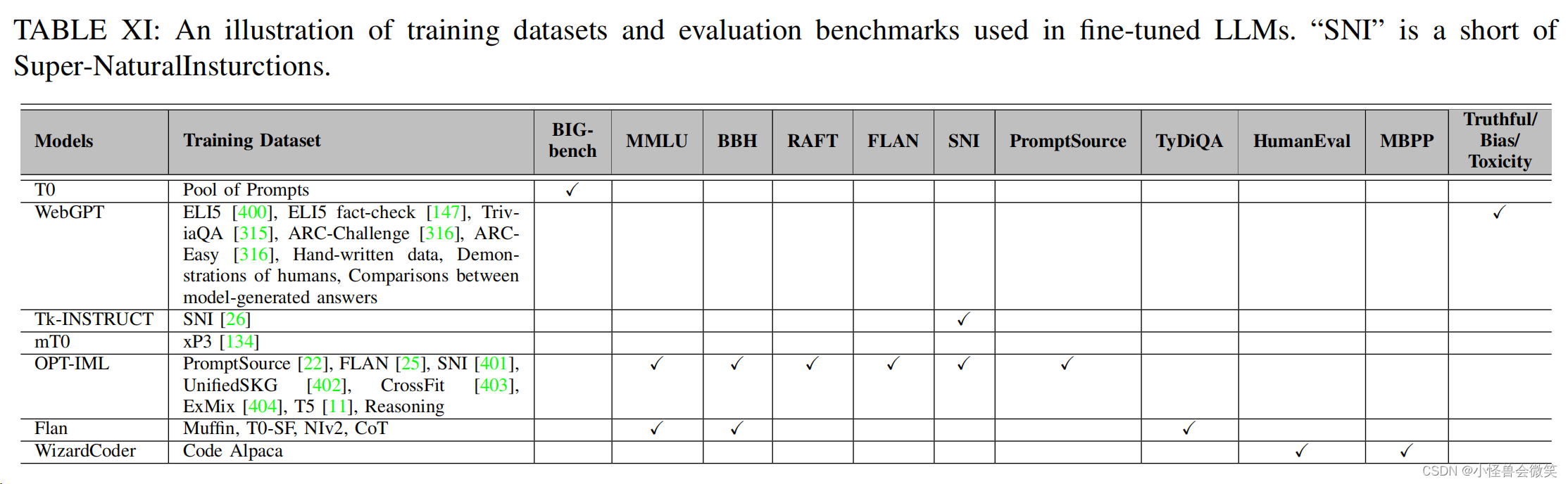
5.数据集和评估
6.总结