【论文阅读】A Survey on Video Diffusion Models
视频扩散模型(Video Diffusion Model)最新综述+GitHub 论文汇总-A Survey on Video Diffusion Models。
paper:[2310.10647] A Survey on Video Diffusion Models (arxiv.org)
0. Abstract
本文介绍了AIGC时代视频扩散模型的全面回顾。简要介绍了扩散模型的基本原理和演变过程。总结了视频领域的扩散模型研究,将这些工作分为三个关键领域:视频生成、视频编辑和其他视频理解任务。我们对这三个关键领域的文献进行了彻底的回顾,包括领域内的进一步分类和实际贡献。
模型合集:GitHub - ChenHsing/Awesome-Video-Diffusion-Models: [Arxiv] A Survey on Video Diffusion Models
1. Introduction
以扩散模型为代表的方法取代了基于生成对抗网络(GANs)和自回归变换器的方法,成为图像生成的主导方法。由于其强大的可控性、逼真的生成和出色的多样性,基于扩散的方法也在广泛的计算机视觉任务中蓬勃发展,包括图像编辑、密集预测以及视频合成和3D生成等各种领域。
自2022年以来,基于扩散模型的视频研究论文数量显著增加,可以分为三个主要类别:视频生成、视频编辑和视频理解。

贡献:这份综述系统地跟踪和总结了有关视频扩散模型的最新文献,包括视频生成、编辑以及视频理解的各个领域。
对视频生成的基准数据集和设置进行了全面的分析和比较。
综述流程:在第2节中,介绍背景知识,包括问题定义、数据集、评估指标以及相关研究领域。随后,在第3节中,介绍视频生成领域的方法概述。在第4节中,研究了与视频编辑任务相关的主要研究。在第5节中,阐明了利用扩散模型进行视频理解的各种方向。在第6节中,强调了现有的研究挑战和潜在的未来方向,在第7节中总结。
2. Preliminaries
介绍扩散模型的基础知识,相关的研究领域,常用的数据集和评估指标。
2.1 Diffusion Model
扩散模型是一类概率生成模型,学习逆转一个逐渐破坏训练数据结构的过程。目前,有关扩散模型的研究主要基于三种主要的表达方式:去噪扩散概率模型(DDPMs)、基于分数的生成模型(SGMs)和随机微分方程(Score SDEs)。
2.1.1 Denoising Diffusion Probabilistic Models (DDPMs)
去噪扩散概率模型(DDPM)涉及两个马尔可夫链:一个前向链,将数据转化成噪声,和一个反向链,将噪声转化回数据。前者旨在将任何数据转化为简单的先验分布,而后者学习了反转前者过程的转移核。新的数据点可以通过首先从先验分布中抽样一个随机向量,然后通过反向马尔可夫链进行衍生抽样来生成。这个抽样过程的关键在于训练反向马尔可夫链以匹配前向马尔可夫链的实际时间反转。

2.1.2 Score-Based Generative Models (SGMs)

2.1.3 Stochastic Differential Equations (Score SDEs)
用多个噪声尺度扰动数据对于上述方法的成功至关重要。Score SDEs 将这一思想进一步推广到无限数量的噪声尺度。扩散过程可以被建模为以下随机微分方程(SDE)的解:

2.2 Related Tasks
主要关注的任务包括文本到视频生成、无条件视频生成以及文本引导的视频编辑等。
文本到视频生成旨在基于文本描述自动生成相应的视频。通常涉及理解文本描述中的场景、物体和动作,将其翻译成一系列连贯的视觉帧,从而生成一个在逻辑和视觉上一致的视频。文本到视频生成具有广泛的应用,包括自动生成电影、动画、虚拟现实内容、教育演示视频等。
无条件视频生成是一个生成建模任务,其目标是从随机噪声或固定的初始状态开始生成一系列连续而视觉一致的视频,而无需依赖特定的输入条件。与有条件视频生成不同,无条件视频生成不需要任何外部指导或先验信息。生成模型需要自主学习如何在没有明确输入的情况下捕捉时间动态、行动和视觉一致性,以产生既真实又多样的视频内容。这对于探索生成模型从无监督数据中学习视频内容的能力和展示多样性至关重要。
文本引导视频编辑是一种利用文本描述来引导视频内容编辑过程的技术。在这个任务中,将自然语言描述作为输入,描述对视频要应用的期望更改或修改。然后,系统分析文本输入,提取相关信息,如对象、动作或场景,并使用这些信息来指导编辑过程。文本引导视频编辑通过允许编辑者使用自然语言传达其意图,为实现高效和直观的编辑提供了一种方式,潜在地减少了逐帧手动和耗时的编辑需求。
2.3 Datasets and Metrics
2.3.1 Data
视频理解任务的演进通常与视频数据集的发展保持一致,对视频生成任务也是如此。在视频生成的早期阶段,任务局限于在低分辨率、小规模数据集和特定领域上进行训练,导致相对单调的视频生成。随着大规模视频文本配对数据集的出现,一般的文本到视频生成任务开始崭露头角。因此,视频生成的数据集主要可分为标题级别(caption-level)和类别级别(category-level),将分别讨论。
标题级别(caption-level)数据集包括与描述性文本标题配对的视频,为训练模型基于文本描述生成视频提供了必要的数据。
表1中列出了几个常见的标题级别数据集。早期的标题级别视频数据集主要用于视频文本检索任务,规模较小(不超过12万)且主要关注特定领域(如电影、动作、烹饪)。随着通用领域 WebVid-10M 数据集的引入,文本到视频(T2V)生成任务获得了动力,研究人员开始关注通用领域的 T2V 生成任务。尽管它是 T2V 任务的主要基准数据集,但仍存在分辨率较低(360P)和带有水印内容等问题。随后,为增强通用文本到视频(T2V)任务中视频的分辨率和广泛覆盖,VideoFactory和 InternVid引入了更大规模(130M 和 234M)和高清晰度(720P)的通用领域数据集。
类别级别(category-level)数据集 包括根据特定类别分组的视频,每个视频都带有其类别标签。这些数据集通常用于无条件视频生成或类别条件视频生成任务。我们在表2中总结了常用的类别级别视频数据集。
UCF101、Kinetics 和 Something-Something 是动作识别的典型基准数据集。DAVIS 最初是为视频对象分割任务提出的,后来成为视频编辑的常用基准数据集。在这些数据集中,UCF-101 最为广泛用于视频生成,作为无条件视频生成、基于类别的有条件生成和视频预测的基准。它包含来自 YouTube 的样本,包括101个动作类别,包括人类运动、乐器演奏和互动动作。与 UCF 类似,Kinetics-400和 Kinetics-600 是两个包含更复杂的动作类别和更大数据规模的数据集,但仍保持与 UCF-101 相同的应用范围。另一方面,Something-Something 数据集既具有类别级别标签,也具有标题级别标签,因此特别适用于文本条件视频预测任务。值得注意的是,这些最初在动作识别领域起到关键作用的大规模数据集具有较小的规模(不超过5万)和单一类别、单一领域属性(数字、驾驶风景、机器人 ),因此不足以生成高质量的视频。因此,近年来提出了专门为视频生成任务设计的数据集,通常具有独特属性,如高分辨率(1080P)或较长持续时间 。例如,Long Video GAN提出了马背数据集,其中包含 66 个视频,每个视频的平均持续时间为 30fps 的 6504 帧。Video LDM收集了包含 683,060 个 8 秒长度的真实驾驶视频,分辨率为 1080P 的 RDS 数据集.

2.3.2 Evaluation Metrics
视频生成的评估指标通常分为定量和定性度量。对于定性度量,一些研究中已经使用了人类主观评估,在这种情况下,评估者通常会被呈现两个或多个生成的视频,以与其他竞争性模型合成的视频进行比较。观察者通常进行基于投票的评估,评估视频的逼真程度、自然一致性以及文本对齐(T2V任务)。然而,人工评估既昂贵又有可能无法反映模型的全部能力。因此,接下来我们将主要探讨图像级别和视频级别评估的定量评估标准。
图像级别指标:视频由一系列图像帧组成,因此图像级别的评估指标可以提供对生成的视频帧质量的一定了解。常用的图像级别指标包括 Fréchet Inception Distance (FID) 、峰值信噪比 (PSNR) 、结构相似性指数 (SSIM) 和 CLIPSIM。FID 通过比较合成的视频帧与真实视频帧来评估生成视频的质量。它涉及将图像进行归一化以获得一致的尺度,利用 InceptionV3 从真实和合成视频中提取特征,并计算均值和协方差矩阵。然后将这些统计数据结合起来计算 FID 分数。SSIM 和 PSNR 都是像素级别的指标。SSIM 评估原始和生成图像的亮度、对比度和结构特征,而 PSNR 是代表峰值信号与均方误差(MSE)之比的系数。这两个指标通常用于评估重建图像帧的质量,并应用于超分辨率和修复等任务。CLIPSIM 是一种用于测量图像文本相关性的方法。基于 CLIP 模型,它提取图像和文本特征,然后计算它们之间的相似性。这个指标通常用于文本条件的视频生成或编辑任务。
视频级别指标:图像级别的评估指标主要关注单个帧,忽略了视频的时间一致性。另一方面,视频级别的指标会提供更全面的视频生成评估。Fréchet Video Distance (FVD) 是一种基于 FID 的视频质量评估指标。与图像级别方法不同,图像级别方法使用 Inception 网络从单帧图像中提取特征,FVD 利用在 Kinetics 上预训练的 Inflated-3D Convnets (I3D) 从视频片段中提取特征。随后,通过均值和协方差矩阵的组合来计算 FVD 分数。与 FVD 类似,Kernel Video Distance (KVD) 也基于 I3D 特征,但它通过利用基于核的方法最大均值差异 (MMD) 来评估生成视频的质量。Video IS (Inception Score) 使用由 3D-Convnets (C3D) 提取的特征来计算生成视频的 Inception 分数,通常用于 UCF-101 上的评估。高质量的视频具有低熵概率,表示为 �(�|�) ,而多样性是通过检查所有视频的边缘分布来评估,这应该表现出高水平的熵。Frame Consistency CLIP Score 通常用于视频编辑任务,用于测量编辑后视频的一致性。其计算包括为所有编辑后视频的帧计算 CLIP 图像嵌入,并报告所有视频帧对之间的平均余弦相似度。
3. Video Generation
将视频生成分为四个类别:通用文本到视频(T2V)生成(第 3.1 节),有条件的视频生成(第 3.2 节),无条件视频生成(第 3.3 节)以及视频补全(第 3.4 节)。最后,我们总结了实验设置和评估指标,并在第 3.5 节对各种模型进行了全面比较。视频生成的分类细节如图2所示。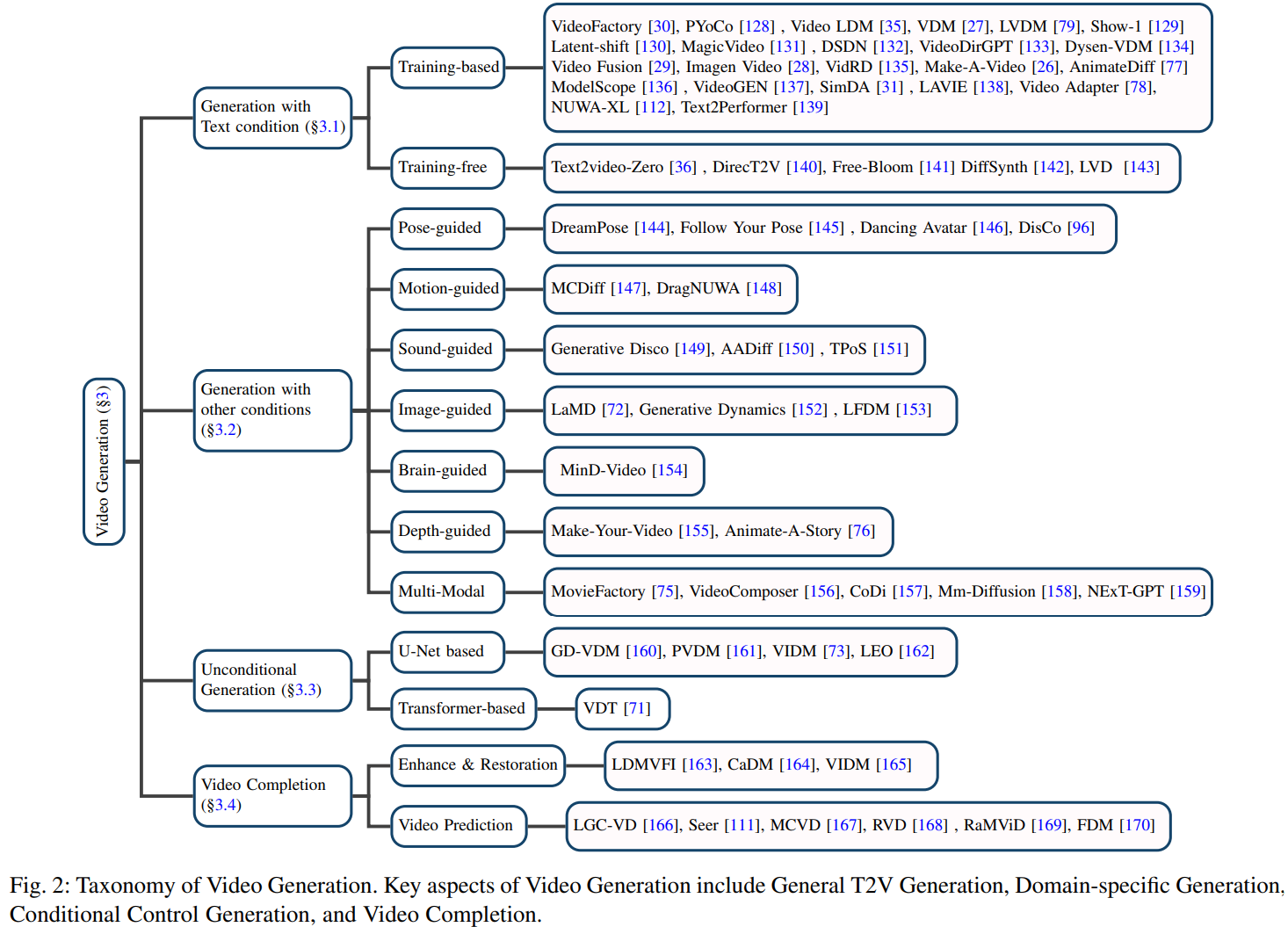
3.1 Video Generation with Text Condition
文本到视频(Text-to-Video,T2V)方法的发展仍处于早期阶段。在这个背景下,我们首先简要概述了一些非扩散方法,然后深入探讨了在基于训练和不基于训练的扩散技术上引入 T2V 模型的情况。

3.1.1 Non-diffusion T2V methods
在扩散模型出现之前,该领域的早期工作主要基于GANs、VQ-VAE 和自回归 Transformer 框架。
在这些工作中,GODIVA 是一个利用 VQ-VAE 进行通用 T2V 任务的代表性工作。它在 Howto100M 上进行了预训练,该数据集包含超过 100M 的视频文本对。所提出的模型在当时展示出了出色的零样本性能。不久之后,自回归 Transformer 方法由于其显式密度建模和相对于 GANs 的稳定训练优势,成为主流的 T2V 任务方法。其中,CogVideo 代表一种广泛的开源视频生成模型,创新地利用预训练的 CogView2 作为其视频生成任务的骨干。此外,它扩展到了使用 Swin Attention 进行自回归视频生成,有效减轻了长序列的时间和空间开销。除了上述工作之外,Phenaki 引入了一个新颖的 C-ViViT 骨干,用于可变长度的视频生成。NUWA 是一个基于自回归Transformer 的统一模型,用于 T2I、T2V 和视频预测任务。MMVG 提出了一种有效的掩码策略,用于多个视频生成任务(T2V、视频预测和视频填充)。
3.1.2 Training-based T2V Diffusion Methods
在前面的讨论中,我们简要回顾了一些不依赖于扩散模型的T2V方法。继续前进,我们主要介绍了目前在T2V任务领域最突出的扩散模型的应用。

早期 T2V 探索:在众多尝试中,VDM 是首个尝试设计用于视频生成的视频扩散模型的先驱。它将传统的图像扩散 U-Net 结构扩展为 3D U-Net 结构,并采用图像和视频的联合训练。它采用的条件采样技术使其能够生成质量更高且持续时间更长的视频。作为 T2V 扩散模型的首次尝试,它还支持无条件生成和视频预测等任务。与需要成对的视频文本数据集的 VDM 不同,Make-A-Video 引入了一种新颖的范式。网络从成对的图像文本数据中学习视觉文本相关性,并从无监督的视频数据中捕获视频运动信息。这种创新方法减少了对数据收集的依赖,从而实现了多样性和逼真性视频的生成。此外,通过使用多个超分辨率模型和插值网络,它实现了更高清晰度和帧率的生成视频。
时序建模探索:在之前的方法中,都是利用像素级的扩散,而 MagicVideo 则是最早采用潜在扩散模型(Latent Diffusion Model,LDM)来进行潜在空间的 T2V 生成的工作之一。通过在低维潜在空间中利用扩散模型,它显著降低了计算复杂性,从而加快了处理速度。引入的逐帧轻量级 adaptor 对齐了图像和视频的分布,使所提出的定向注意力(directed attention)能够更好地建模时间关系以确保视频的时序一致性。同时,LVDM 也将 LDM 作为其骨干,利用分层框架来建模潜在空间。通过采用掩码采样技术,该模型能够生成更长的视频。它还结合了条件潜在扰动(Conditional Latent Perturbation)和无条件引导(Unconditional Guidance)等技术,以减轻自回归生成任务后期性能下降的问题。采用这种训练方法,它可以应用于视频预测任务,甚至生成包含数千帧的长视频。ModelScope 将空间-时间卷积和注意力整合到 LDM 中,用于 T2V 任务。它采用了混合训练方法,使用LAION 和 WebVid,并作为一个开源基准方法。先前的方法主要依赖于 1D 卷积或时间注意力来建立时间关系。而 Latent-Shift 专注于轻量级的时序建模。从 TSM 获得灵感,它在卷积模块中在相邻帧之间移动通道以进行时间建模。此外,该模型在生成视频的同时保持了原始的 T2I 能力。
多阶段的 T2V 方法: Imagen Video 将成熟的 T2I 模型 Imagen 扩展到了视频生成任务。级联的视频扩散模型由七个子模型组成,其中一个专门用于基本视频生成,三个用于空间超分辨率,另外三个用于时间超分辨率。这些子模型一起构成了一个全面的三阶段训练流程。它验证了在 T2I 训练中采用的许多训练技术的有效性,如无分类器引导(classifier-free guidance)、条件增强(conditioning augmentation) 和 v-参数化。此外,作者还利用渐进蒸馏技术(progressive distillation techniques)来加速视频扩散模型的采样时间。其中介绍的多阶段训练技术已成为主流高清视频生成的有效策略。同时,Video LDM 训练了一个由三个训练阶段组成的 T2V 网络,包括关键帧 T2V 生成、视频帧插值和空间超分辨率模块。它在空间层上添加了时间注意力层和 3D 卷积层,以在第一阶段生成关键帧。随后,通过采用掩码采样方法,训练了一个帧插值模型,将短视频的关键帧扩展到更高的帧率。最后,采用视频超分辨率模型来增强分辨率。类似地,LAVIE 采用了一个由三个阶段组成的级联视频扩散模型:基本的 T2V 阶段、时间插值阶段和视频超分辨率阶段。此外,它验证了联合图像和视频微调的过程可以产生高质量和有创意的结果。Show-1 首次引入了基于像素(pixel-based)和基于潜在(latent-based)的扩散模型的融合,用于 T2V 生成。其框架包括四个不同的阶段,前三个在像素级低分辨率下运行:关键帧生成、帧插值和超分辨率。值得注意的是,像素级的阶段可以生成具有精确文本对齐的视频。第四阶段由一个潜在超分辨率模块组成,提供了一种成本有效的方式来增强视频分辨率。
噪声先验探索:尽管大多数提到的方法通过扩散模型独立去噪每一帧,但 VideoFusion 通过考虑不同帧之间的内容冗余和时间相关性而脱颖而出。具体来说,它使用每帧共享的基础噪声和沿时间轴的残差噪声来分解扩散过程。这种噪声分解是通过两个共同训练的网络实现的。这种方法旨在确保在生成帧运动时的一致性,尽管它可能导致多样性有限。此外,文章还表明,使用 T2I 骨干(如 DALLE-2)来训练 T2V 模型可以加速收敛,但其文本嵌入可能面临理解长时序文本序列的挑战。PYoCo 认为,在 T2V 任务中,直接扩展图像的噪声先验到视频可能会导致次优的结果。因此,它巧妙地设计了一个视频噪声先验并对 eDiff-I 模型进行微调,用于视频生成。所提出的噪声先验涉及在视频内的不同帧之间采样相关的噪声。作者验证了所提出的混合和渐进噪声模型更适用于 T2V 任务。
数据集贡献:VideoFactory 注意到先前广泛使用的 WebVid 数据集存在低分辨率和水印的问题。作为回应,它构建了一个大规模视频数据集,名为 HD-VG-130M,包括来自开放领域来源的 1.3 亿个视频文本对。这个数据集是通过 BLIP-2 字幕从 HD-VILA 中收集的,声称具有高分辨率并且没有水印。此外,VideoFactory 引入了一种交换的交叉注意力机制,以促进时间和空间模块之间的交互,从而提高了时间关系建模的效果。在这个高清数据集上进行训练,该论文中提出的方法能够生成分辨率为(1376×768)的高分辨率视频。VidRD 引入了"复用和扩散"(Reuse and Diffuse)框架,该框架通过迭代使用原始的潜在表示并遵循以前的扩散过程,生成额外的帧。此外,它在构建视频文本数据集时利用静态图像、长视频和短视频。对于静态图像,通过随机缩放或平移操作引入了动态方面。短视频使用 BLIP-2 标注进行分类,而长视频首先进行分割,然后根据 MiniGPT-4 进行标注以保留所需的视频片段。在视频文本数据集中构建多样的类别和分布被证明对提高视频生成的质量是有效的。
高效训练: ED-T2V 采用 LDM 作为其骨干,冻结了大部分参数以降低训练成本。它引入了身份注意力和时间交叉注意力以确保时间上的一致性。这篇论文提出的方法成功降低了训练成本,同时保持了可比较的 T2V 生成性能。SimDA 设计了一种参数高效的 T2V 任务训练方法,通过保持 T2I 模型的参数不变来实现。它引入了一个轻量级的空间 adapter,用于将视觉信息转移到 T2V 学习中。此外,它还引入了一个时间 adapter,用于在较低的特征维度中建模时间关系。提出的潜在位移注意力有助于保持视频的一致性。此外,轻量级的架构能够加速推断,并使其适用于视频编辑任务。
个性化视频生成:个性化视频生成通常指的是创建根据特定主题或风格定制的视频,解决了为了满足个人偏好或特征而生成定制视频的问题。AnimateDiff 注意到了 LoRA 和 Dreambooth 在个性化 T2I 模型方面的成功,并旨在将它们的有效性扩展到视频动画。此外,作者的目标是训练一个可以适应生成各种个性化视频的模型,而无需反复在视频数据集上重新训练。这包括使用 T2I 模型作为基础生成器,并添加一个运动模块来学习运动动态。在推理时,个性化 T2I 模型可以替代基础 T2I 权重,实现个性化视频生成。
伪影去除:为解决T2V生成的视频中出现的闪烁和伪像问题,DSDN 引入了一个双流扩散模型,一个用于视频内容,另一个用于运动。这样,它可以保持内容和运动之间的强对齐性。通过将视频生成过程分解为内容和运动组件,可以生成具有较少闪烁的连续视频。VideoGen 首次利用 T2I 模型基于文本提示生成图像,这些图像作为引导视频生成的参考图像。随后,引入了一个高效的级联潜在扩散模块,采用基于流的时间上采样步骤以提高时间分辨率。与以前的方法相比,引入参考图像提高了视觉保真度并减少了伪像,使模型能够更多地专注于学习视频动态。
复杂动力学建模:在生成文本到视频(T2V)的过程中,面临着对复杂动态的建模挑战,特别是涉及到动作连贯性的中断。为了解决这个问题,Dysen-VDM 提出了一种将文本信息转化为动态场景图的方法。通过利用大语言模型(LLM),Dysen-VDM 从输入文本中识别关键行动,并按时间顺序排列它们,丰富场景的相关描述细节。此外,该模型受益于对 LLM 的上下文学习,赋予其强大的时空建模能力。这种方法在合成复杂动作方面表现出卓越的优势。VideoDirGPT 也利用LLM来规划视频内容的生成。对于给定的文本输入,通过 GPT-4 将其扩展为视频计划,包括场景描述、实体及其布局,以及实体在背景中的分布。随后,该模型通过显式控制布局生成相应的视频。这种方法在复杂动态视频生成的布局和动作控制方面表现出明显的优势。
特定领域的 T2V 生成: Video-Adapter 引入了一种新颖的设置,将预训练的通用 T2V 模型转移到领域特定的 T2V 任务中。通过将领域特定的视频分布分解为预先训练的噪声和少量训练组件,它大大降低了转移训练的成本。这种方法在 Ego4D 和 Bridge Data 场景的 T2V 生成中的有效性得到了验证。NUWA-XL 采用了一种粗到细的生成范式,有助于并行视频生成。它首先采用全局扩散来生成关键帧,然后利用局部扩散模型在两帧之间进行插值。这种方法使得可以创建长达 3376 帧的视频,从而为动画生成设立了一个基准。这项工作专注于卡通视频生成领域,利用其技术来制作持续几分钟的卡通视频。Text2Performer 将以人为中心的视频分解为外观和动作表示。首先,它使用 VQVAE 的潜在空间对自然人类视频进行非监督训练,以解耦外观和姿势表示。随后,它使用连续的 VQ-diffuser 来采样连续的姿势嵌入。最后,作者在姿势嵌入的时空域上采用了一种动作感知的掩码策略,以增强时间相关性。
3.1.3 Training-free T2V Diffusion Methods
以前的方法都是基于训练的 T2V 方法,通常依赖于大规模数据集,如 WebVid 或其他视频数据集。而一些最近的研究旨在通过开发无需训练的 T2V 方法来减少昂贵的训练成本,下面将介绍这些方法。

Text2Video-Zero
利用了预训练的 T2I 模型 Stable Diffusion 来进行视频合成。为了保持不同帧之间的一致性,它在每一帧和第一帧之间执行交叉注意力机制。此外,它通过修改潜在码本的采样方法来丰富运动动态。此方法还可以与条件生成和编辑技术(如 ControlNet 和 InstructPix2Pix)结合使用,实现对视频的受控生成。
DirecT2V 和 Free-Bloom 引入了大型语言模型(LLM),以基于单个抽象用户提示生成逐帧描述。LLM 导演用于将用户输入分解为帧级别的描述。此外,为了保持帧之间的连续性,DirecT2V 使用了一种新颖的值映射和 dual-softmax 过滤方法。Free-Bloom 提出了一系列逆向过程增强方法,包括联合噪声采样、步骤感知的注意力转移和双通道插值。实验结果表明,这些修改增强了零样本视频生成能力。为了处理复杂的时空提示,LVD 首先利用大型语言模型(LLM)生成动态场景布局,然后使用这些布局来引导视频生成。它的方法无需训练,通过根据布局调整注意力图,来引导视频扩散模型,从而实现复杂动态视频的生成。
DiffSynth 提出了一种迭代内的潜在抑制闪烁框架和视频抑制闪烁算法,以减轻闪烁并生成连贯的视频。此外,它可以应用于各种领域,包括视频风格化和 3D 渲染。
3.2 Video Generation with other Conditions
先前介绍的大多数方法都涉及文本到视频生成。在这个小节中,我们关注基于其他模态条件(例如姿势、声音和深度)的视频生成。我们在图 3 中展示了条件控制的视频生成示例。


3.2.1 Pose-guided Video Generation
Follow Your Pose 提出了一个由姿势和文本控制驱动的视频生成模型。它采用了两阶段的训练过程,利用图像-姿势对和无姿势的视频。在第一阶段,使用(图像,姿势)对对 T2I (Text-to-Image) 模型进行微调,以实现姿势控制的生成。在第二阶段,模型利用未标记的视频来学习时间建模,通过整合时间注意力和跨帧注意力机制。这两阶段的训练使模型具备了姿势控制和时间建模的能力。DreamPose 构建了一个双路的 CLIP-VAE 图像编码器和 adapter 模块,以替代 LDM 中的原始 CLIP 文本编码器作为条件组件。在给定单个人类图像和一个姿势序列的情况下,该研究可以基于提供的姿势信息生成相应的人体姿势视频。Dancing Avatar 专注于合成人类舞蹈视频。它利用一个 T2I 模型以自回归方式生成视频的每一帧。为了确保整个视频的一致性,它使用了一个帧对齐模块,结合了来自 ChatGPT 的见解,以增强相邻帧之间的连贯性。此外,它还利用 OpenPose ControlNet 来实现根据姿势生成高质量人体视频的能力。Disco 解决了一个称为参考人类舞蹈生成的新颖问题设置。它利用了 ControlNet、Grounded-SAM 和 OpenPose 来进行背景控制、前景提取和姿势骨架提取。此外,还使用了大规模图像数据集进行人类属性的预训练。通过结合这些训练步骤,Disco 为人类特定的视频生成任务奠定了坚实的基础。
3.2.2 Motion-guided Video Generation
MCDiff 是首个考虑运动作为视频合成控制条件的先驱。该方法涉及提供视频的第一帧以及一系列笔画运动。首先,使用流补全模型基于稀疏笔画运动控制来预测稠密视频运动。随后,该模型采用自回归方法,利用稠密运动图来预测随后的帧,最终合成完整的视频。DragNUWA 同时引入文本、图像和轨迹信息,以从语义、空间和时间的角度提供对视频内容的精细控制。为了进一步解决以前工作中开放域轨迹控制的不足,作者提出了一个轨迹采样器 (Trajectory Sampler, TS),以实现对任意轨迹的开放领域控制,一个多尺度融合 (Multiscale Fusion, MF),以控制不同粒度的轨迹,以及一种自适应训练 (Adaptive Training, AT) 策略,以生成遵循轨迹的一致视频。
3.2.3 Sound-guided Video Generation
AADiff 引入了将音频和文本一起作为视频合成的条件的概念。该方法首先使用专用编码器分别对文本和音频进行编码。然后,计算文本和音频嵌入之间的相似度,并选择具有最高相似度的文本标记。所选的文本标记以 prompt2prompt 的方式用于编辑帧。这种方法可以实现生成与音频同步的视频,而无需额外的训练。Generative Disco 是一个针对音乐可视化的文本到视频生成的 AI 系统。该系统采用一个包括大语言模型和文本到图像模型的流程来实现其目标。TPoS 将具有可变时间语义和幅度的音频输入集成到其中,构建在 LDM 的基础上,以扩展生成模型中音频模态的应用。该方法在客观评估和用户研究中表现出色,超越了广泛使用的音频到视频基准,突显了其卓越性能。
3.2.4 Image-guided Video Generation
LaMD 首先训练一个自动编码器来分离视频中的运动信息。然后,基于扩散的运动生成器被训练用于生成视频运动。通过这种方法,在运动的指导下,模型实现了在给定第一帧的情况下生成高质量感知视频的能力。LFDM 利用条件图像和文本进行以人为中心的视频生成。在初始阶段,训练一个潜在流自动编码器来重构视频。此外,还可以在中间步骤中使用流运动预测器来预测流动作。随后,在第二阶段,使用图像、流动和文本提示作为条件来训练扩散模型以生成连贯的视频。Generative Dynamics 提出了一种在图像空间中建模场景动态的方法。它从展示自然运动的真实视频序列中提取运动轨迹。对于单个图像,扩散模型通过一个频率协调的扩散采样过程,为每个像素在傅立叶域中预测了长期的运动表示。这个表示可以转换为跨越整个视频的密集运动轨迹。当与图像渲染模块结合使用时,它可以将静态图像转换为连续循环的动态视频,促进用户与所描绘对象的真实互动。
3.2.5 Brain-guided Video Generation
MinD-Video 是首个尝试通过连续 fMRI 数据来探索视频生成的工作。该方法首先通过对比学习来将 MRI 数据与图像和文本对齐。接下来,一个经过训练的 MRI 编码器取代了 CLIP 文本编码器作为输入条件。通过设计一个时间注意力模块来模拟序列动态,进一步增强了模型的性能。最终的模型能够重建具有精确语义、运动和场景动态的视频,超越真实数据性能,为该领域树立了新的标杆。
3.2.6 Depth-guided Video Generation
Make-Your-Video 采用了一种新颖的方法进行文本深度条件的视频生成。它在训练过程中通过使用 MiDas 提取深度信息来将深度信息整合为一个条件因素。此外,该方法引入了因果关注掩码,以促进更长视频的合成。与最先进的技术进行比较表明,该方法在可控文本到视频生成方面表现出了卓越性能,展现出更好的定量和定性性能。在 Animate-A-Story 中,引入了一种创新的方法,将视频生成分为两个步骤。第一步,"Motion Structure Retrieval",涉及根据给定的文本提示从大型视频数据库中检索出最相关的视频。使用离线深度估计方法获取这些检索到的视频的深度图,然后用作运动引导。在第二步中,"Structure-Guided Text-to-Video Synthesis" 用于训练一个受深度图导出的结构运动引导的视频生成模型。这种两步法使得可以基于定制的文本描述创建个性化的视频。
3.2.7 Multi-modal guided Video Generation
VideoComposer 关注的是在多模态条件下进行视频生成,包括文本、空间和时间条件。具体来说,它引入了一个时空条件编码器,允许各种条件的灵活组合。这最终使得可以整合多个模态,如草图、遮罩、深度和运动矢量。通过利用多模态的控制,VideoComposer 实现了更高质量的视频和生成内容的更好细节。MM-Diffusion 是联合音视频生成的首次尝试。为了实现多模态内容的生成,它引入了一个分叉架构,包括两个子网络,分别用于视频和音频生成。为了确保这两个子网络的输出之间的连贯性,设计了一个基于随机位移的注意力模块来建立相互连接。除了无条件的音视频生成能力,MM-Diffusion 在实现视频到音频的转换方面也表现出明显的能力。 MovieFactory 致力于将扩散模型应用于电影风格视频的生成。它利用 ChatGPT 来详细阐述用户提供的文本,创建用于电影生成的综合顺序脚本。此外,还设计了一个音频检索系统,用于为视频提供旁白。通过上述技术,实现了生成多模态音频-视觉内容的目标。CoDi 提出了一种新颖的生成模型,具有从不同输入模态的不同组合生成语言、图像、视频或音频等多样输出模态的能力。这是通过构建一个共享的多模态空间来实现的,通过跨多种模态对输入和输出空间的对齐,从而促进生成任意模态组合。NExT-GPT 提出了一个端到端的、任何到任何的多模态大型语言模型系统。它将大语言模型 (LLM) 与多模态适配器和多样化的扩散解码器结合起来,使系统能够感知任意文本、图像、视频和音频的输入,生成相应的输出。在训练过程中,它只微调了一个小的参数子集。此外,它引入了模态切换指令调整 (MosIT) 机制,并手工策划了一个高质量的 MosIT 数据集。这个数据集有助于获取复杂的跨模态语义理解和内容生成能力。
3.3 Unconditional Video Generation
在这个部分,我们深入探讨无条件的视频生成。这指的是在没有额外条件的情况下生成属于特定领域的视频。这些研究的重点集中在视频表示的设计和扩散模型网络的架构上。

基于 U-Net 生成:在无条件视频扩散模型中,VIDM 是最早的工作之一,后来成为重要的基准方法之一。它使用了两个流:内容生成流用于生成视频帧内容,动作流定义了视频的运动。通过合并这两个流,生成了连贯的视频。此外,作者采用了位置组归一化 (PosGN) 来增强视频的连贯性,并探索了隐式运动条件 (IMC) 和 PosGN 的组合,以解决长视频的生成一致性问题。类似于 LDM,PVDM 首先训练一个自编码器,将像素映射到较低维度的潜在空间,然后在潜在空间中应用扩散去噪生成模型来合成视频。这种方法既降低了训练和推理成本,同时又能够保持令人满意的生成质量。主要专注于合成驾驶场景视频的 GD-VDM 首先生成深度图视频,其中场景和布局的生成被优先考虑,而精细细节和纹理则被抽象化。然后,生成的深度图作为条件信号提供,进一步生成视频的其余细节。这种方法保留了卓越的细节生成能力,特别适用于复杂的驾驶场景视频生成任务。LEO 通过一系列流图来表示生成过程中的运动,从而在外观和运动之间进行内在分离。它通过流图像动画生成器和潜在运动扩散模型的结合实现了人类视频的生成。前者学习了从流图到运动码本的重构,而后者捕获了运动先验以获取运动码本。这两种方法的协同作用使学习人类视频相关性变得有效。此外,这种方法还可以扩展到无限长度的人类视频合成和保留内容的视频编辑等任务。
基于 Transformer 生成:不同于大多数基于 U-Net 结构的方法,VDT 开创性地探索了基于 Transformer 架构的视频扩散模型。利用 Transformer 的多功能可扩展性,作者们研究了各种时间建模方法。此外,他们将 VDT 应用于多个任务,如无条件生成和视频预测。
3.4 Video Completion
视频补全是视频生成领域内的一个关键任务。在接下来的部分,我们将详细描述视频增强和恢复以及视频预测的不同方面。

3.4.1 Video Enhancement and Restoration
CaDM 提出了一种新颖的神经增强视频流传递范式,旨在大幅降低流传递比特率,同时与现有方法相比,保持明显提高的恢复能力。首先,CaDM 提出了通过同时降低视频流中帧分辨率和颜色位深度来提高编码器的压缩效率的方法。此外,CaDM 通过向去噪扩散恢复过程中灌输编码器规定的分辨率-颜色条件的意识,使解码器具有优越的增强能力。LDMVFI 是首个采用条件潜在扩散模型方法来解决视频帧插值 (VFI) 任务的尝试。为了利用潜在扩散模型进行 VFI,该工作引入了一系列创新概念。值得注意的是,它提出了一个专门用于视频帧插值的自编码网络,集成了高效的自注意模块,并采用 deformable kernel-based 的帧合成技术,从而大幅提高性能。VIDM 利用预训练的 LDM 来处理视频修补任务。通过为第一人称视角视频提供一个掩码,该方法利用 LDM 的图像补全先验生成修补后的视频。
3.4.2 Video Prediction
Seer 专注于文本引导的视频预测任务的探索。它以潜在扩散模型 (LDM) 作为其基础骨干网络。通过在自回归框架内整合时空注意力,以及实施帧顺序文本分解模块,Seer 将文本到图像 (T2I) 模型的知识先验巧妙地转移到视频预测领域。这一迁移导致了显著的性能提升,尤其是在基准测试中得到了证明。FDM 引入了一种新颖的分层采样方案,用于长视频预测任务。此外,提出了一个新的 CARLA 数据集。与自回归方法相比,所提出的方法不仅更高效,而且产生了更好的生成结果。MCVD 使用了一种基于概率条件得分的去噪扩散模型,用于无条件生成和插值任务。引入的掩码方法能够掩盖所有过去或未来的帧,从而使得可以从过去或未来预测帧。此外,它采用自回归方法以块状方式生成可变长度的视频。MCVD 的有效性已在各种基准测试中得到验证,包括预测和插值任务。鉴于自回归方法在生成长视频时倾向于产生不切实际的结果,LGC-VD 引入了一种局部-全局上下文(Local-Global Context)引导的视频扩散模型,旨在包括多样的感知条件。LGC-VD采用了两阶段的训练方法,并将预测错误视为一种数据增强形式。这种策略有效地解决了预测错误问题,特别是在长视频预测任务的背景下加强了稳定性。RVD(Residual Video Diffusion)采用了一种扩散模型,利用卷积循环神经网络的上下文向量作为条件生成残差信息,然后将其添加到确定性的下一帧预测中。作者证明,使用残差预测比直接预测未来帧更有效。这项工作在各种基准测试中与基于生成对抗网络(GANs)和变分自编码器(VAEs)的先前方法进行了广泛比较,为其有效性提供了充分的证据。RaMViD 使用 3D 卷积将图像扩散模型扩展到视频任务领域。它引入了一种新颖的条件训练技术,并利用掩码条件将其应用扩展到各种补全任务,包括视频预测、填充和上采样。
3.5 Benchmark Results
这一部分对视频生成任务的各种方法在两种不同设置下进行了系统比较,即零次学习(zero-shot)和微调(finetuned)。对于每种设置,我们首先介绍它们常用的数据集。接下来,我们说明每个数据集所使用的详细评估指标。最后,我们对各种方法的性能进行了全面的比较。
3.5.1 Zero-shot T2V Generation
数据集:通用的文本到视频 (T2V) 方法,比如 Make-A-Video 和 VideoLDM,通常是以零次学习方式在 MSRVTT 和 UCF-101 数据集上进行评估。MSRVTT 是一个视频检索数据集,其中每个视频片段都附带大约 20 个自然语句的描述。通常,用于测试集的 2,990 个视频片段对应的文本描述被用作提示来生成相应的生成视频。UCF-101 是一个包含 101 个动作类别的动作识别数据集。在 T2V 模型的背景下,视频通常是基于这些动作类别的类别名称或手动设置的提示来生成的。
评估指标:在零次学习设置下,通常会使用 MSRVTT 数据集上的 FVD 和 FID 指标来评估视频质量。使用CLIPSIM 来衡量文本和视频之间的对齐。对于 UCF-101 数据集,典型的评估指标包括 Inception Score、FVD 和FID,用于评估生成视频和其帧的质量。
结果比较:在表 3 中,我们展示了当前通用 T2V 方法在 MSRVTT 和 UCF-101 上的零次学习性能。我们还提供了有关它们的参数数量、训练数据、额外依赖项和分辨率的信息。可以看到,依赖 ChatGPT [134] 或其他输入条件[76, 155] 的方法在性能上明显优于其他方法,而使用额外数据 [26, 30, 99] 通常会导致性能改进。

3.5.2 Finetuned Video Generation
数据集:经微调的视频生成方法是指在特定数据集上进行微调后生成视频。这通常包括无条件视频生成和类别条件视频生成。主要关注三个特定的数据集:UCF101、Taichi-HD 和 Time-lapse。这些数据集涵盖了不同的领域:UCF-101 关注人类体育运动,Taichi-HD 主要包括太极拳视频,Time-lapse 主要特点是天空的延时摄影画面。此外,还有其他一些可用的基准测试数据,但我们选择了这三个,因为它们是最常用的。
评估指标:在对经微调的视频生成任务进行评估时,UCF-101 数据集的常用评估指标包括IS(Inception Score)和 FVD(Fréchet Video Distance)。对于 Time-lapse 和 Taichi-HD 数据集,常见的评估指标包括 FVD 和 KVD。
结果比较:在表 4 中,我们展示了在基准数据集上微调的当前最先进方法的性能。同样,提供了有关方法类型、分辨率和额外依赖项的进一步细节。可以明显看出,基于扩散的方法相对于传统的 GANs 和自回归 Transformer 方法具有明显优势。此外,如果有大规模的预训练或类别条件,性能往往会进一步提高。

4 Video Editing
随着扩散模型的发展,视频编辑研究的数量呈指数级增长。根据许多研究的共识,视频编辑任务应满足以下标准:(1) 保真度(fidelity):每一帧应在内容上与原始视频的相应帧保持一致;(2) 对齐度(alignment):生成的视频应与输入的控制信息对齐;(3) 质量(quality):生成的视频应在时间上保持一致且质量高。虽然可以使用预训练的图像扩散模型逐帧处理视频来进行视频编辑,但跨帧语义一致性的不足使得逐帧编辑视频成为不可行的任务,使视频编辑成为一项具有挑战性的任务。在本节中,我们将视频编辑分为三个类别:文本引导视频编辑(第 4.1 节)、模态引导视频编辑(第 4.2 节)和领域特定视频编辑(第 4.3 节)。视频编辑的分类细节总结如图 4 所示。

4.1 Text-guided Video Editing
在文本引导的视频编辑中,用户提供一个输入视频和一个描述所期望结果视频属性的文本提示。然而,与图像编辑不同,文本引导的视频编辑代表了帧一致性和时间建模的新挑战。一般来说,有两种主要的文本驱动视频编辑方式:(1) 在大规模文本-视频配对数据集上训练 T2V 扩散模型,和 (2) 扩展预训练的 T2I 扩散模型用于视频编辑。由于大规模文本-视频数据集难以获取,而训练 T2V 模型计算成本高昂,因此后者更受关注。为了捕捉视频中的运动,各种时间模块被引入到 T2I 模型中。然而,扩展 T2I 模型的方法面临两个关键问题:时间不一致(Temporal inconsistency),即编辑后的视频在视觉上在帧之间出现闪烁;语义差异(Semantic disparity),即视频未根据给定的文本提示语义进行修改。一些研究从不同的角度解决了这些问题。

4.1.1 Training-based Methods
基于训练的方法指的是在大规模视频文本数据集上进行训练,使其能够成为通用的视频编辑模型。

GEN-1 提出了一种结构和内容感知模型,可以实现对时间、内容和结构一致性的全面控制。该模型将时间层引入预训练的文本到图像(T2I)模型,并在图像和视频上联合进行训练,实现实时控制时间一致性。Dreamix 的高保真度源于两个主要的创新:使用原始视频的低分辨率版本来初始化生成,以及在原始视频上对生成模型进行微调。他们进一步提出了一种混合微调方法,包括全时域注意力和时域注意力掩码,显著提高了动作可编辑性。TCVE 提出了一种时域 U-Net,能够有效地捕捉输入视频的时间一致性。为了连接时域 U-Net 和预训练的文本到图像(T2I) U-Net,作者引入了一个具有连贯的时空建模单元。Control-A-Video 基于预训练的文本到图像(T2I)扩散模型,其中包括一个时空自注意模块和可训练的时域层。此外,他们提出了一种首帧条件策略(即,基于第一帧生成视频序列),使得 Control-A-Video 能够使用自回归方法生成任意长度的视频。与大多数当前方法在单一框架内同时建模外观和时间表示不同,MagicEdit 创新地将内容、结构和动作的学习分开,以实现高保真度和时间一致性。MagicProp 将视频编辑任务分为外观编辑和具有动作感知的外观传播,以实现时间一致性和编辑灵活性。首先,他们从输入视频中选择一帧,并将其外观编辑为参考。然后,他们使用图像扩散模型,自回归地生成目标帧,受其前一帧、目标深度和参考外观的控制。
4.1.2 Training-free Methods
无训练方法涉及使用预训练的文本到图像(T2I)或文本到视频(T2V)模型,并以零样本方式调整它们以执行视频编辑任务。与基于训练的方法相比,无训练方法不需要大量的训练成本。然而,它们可能存在一些潜在的缺点。首先,零样本方式编辑的视频可能会产生时空失真和不一致性。此外,利用T2V模型的方法可能仍会导致高昂的训练和推断成本。我们简要研究了用于解决这些问题的技术。

TokenFlow 表明,在编辑视频中可以通过在扩散特征空间中强制保持一致性来实现一致性。具体来说,这是通过对关键帧进行采样、联合编辑它们,然后根据原始视频特征提供的对应关系将关键帧的特征传播到所有其他帧完成的。这一过程显式地保持了原始视频特征的一致性和精细的共享表示。VidEdit 结合了基于图谱(atlas-based)的方法和预训练的文本到图像(T2I)模型,它不仅展现出高时域一致性,还能提供对视频内容外观的对象级控制。该方法包括将视频分解成带有内容的语义统一表示的分层神经图谱,然后应用预训练的文本驱动的图像扩散模型进行零样本图谱编辑。同时,它通过编码时域外观和空间设置来在图谱空间中保留结构。Rerender A Video 利用分层的跨帧约束来强制时间一致性。其关键思想是使用光流来应用密集的跨帧约束,先前渲染的帧作为当前帧的低级参考,第一帧渲染的帧作为锚点,以保持风格、形状、纹理和颜色的一致性。为了解决图谱学习和单视频微调中的高昂成本问题,FateZero 在逆向扩散过程的每个阶段存储全面的注意力图,以保持出色的运动和结构信息。此外,它还包括时空模块以增强视觉一致性。Vid2Vid-Zero
利用空Vid2Vid-Zero文本逆向(null-text inversion)模块来将文本与视频对齐,使用空间正则化模块实现视频之间的保真度,并使用跨帧建模模块实现时间一致性。类似于 FateZero,它还包括一个时空注意力模块。 Pix2Video 最初利用预训练的结构引导的文本到图像(T2I)模型在锚定帧上进行文本引导的编辑,确保生成的图像保持与编辑提示的一致性。随后,他们逐步通过自注意特征注入将更改传播到未来的帧,以保持时间一致性。InFusion
由两个主要组件组成:首先,它将解码器层中的残差块特征和编辑提示的注意力特征合并到去噪流程中,突出了其零样本编辑能力。其次,它通过使用交叉注意力图获取的掩码提取来合并编辑和未编辑概念的注意力,以确保一致性。ControlVideo 直接采用了 ControlNet 的架构和权重,通过完全的跨帧交互扩展了自注意力,以实现高质量和一致性。为了处理长视频编辑任务,它实施了一个分层采样器,将长视频分成短片段,并通过对关键帧对的条件化来获得全局一致性。EVE 提出了两种策略来增强时间一致性:深度图引导(Depth Map Guidance)用于定位移动物体的空间布局和运动轨迹,以及帧对齐注意力(Frame-Align Attention),强制模型关注先前和当前帧。MeDM 利用显式光流来建立视频帧之间的像素对应关系的实际编码,从而保持时间一致性。此外,他们通过使用从光流导出的时间对应关系指导来迭代地对齐视频帧之间的噪声像素。Gen-L-Video 通过将长视频视为在时间上重叠的短视频,探索了长视频编辑。通过提出的时域协同去噪方法(Temporal Co-Denoising methods),它扩展了现成的短视频编辑模型,以处理包含数百帧的编辑视频并保持一致性。为了确保编辑视频的所有帧之间的一致性,FLATTEN 将光流结合到扩散模型的注意力机制中。所提出的光流引导注意力允许不同帧的块放置在注意力模块内的相同光流路径上,实现相互注意并增强视频编辑的一致性。
4.1.3 One-shot-tuned Methods
一次调整方法涉及使用特定视频实例对预训练的文本到图像(T2I)模型进行微调,从而使其能够生成具有类似运动或内容的视频。尽管这需要额外的训练成本,但与无训练方法相比,这些方法提供了更大的编辑灵活性。

SinFusion 开创了一次调整的扩散模型,能够从仅有几帧的输入视频中学习运动。它的骨干是一个完全卷积的 DDPM 网络,因此可以用于生成任何尺寸的图像。SAVE 对参数空间的谱变换(spectral shift)进行微调,以便学习输入视频中的基本运动概念和内容信息。此外,它提出了一种谱变换正则化器以限制变化。Edit-A-Video 包括两个阶段:第一阶段将预训练的 T2I 模型扩展到 T2V 模型,并使用单个<文本,视频>对进行微调,而第二阶段是传统的扩散和去噪过程。一个关键观察是,编辑后的视频通常会出现背景不一致性的问题。为了解决这个问题,他们提出了一种称为稀疏因果混合(sparse-causal blending)的掩码方法,它可以自动生成一个掩码以逼近编辑区域。Tune-A-Video 利用稀疏的时空注意力机制,只访问第一个和前面的视频帧,以及高效的微调策略,只更新注意力块中的投影矩阵。此外,它在推理时寻求来自输入视频的结构引导,以弥补运动一致性的不足。Video-P2P 不再使用 T2I 模型,而是将其改为一个文本到集合模型(T2S),通过用帧注意力替换自注意力,生成一组语义一致的图像。此外,他们使用分离的引导策略来提高对提示变化的鲁棒性。ControlVideo 主要集中在改进扩散模型和 ControlNet 中的注意力模块。他们将原始的空间自注意力转化为关键帧注意力,将所有帧与选择的一帧进行对齐。此外,他们还结合了时域注意力模块以保持一致性。Shape-aware TLVE 利用 T2I 模型,通过将变形场从输入和编辑的关键帧传播到所有帧来处理形状变化。EI2 进行了两个关键创新:Shift-restricted Temporal Attention Module (STAM) 用于限制时域注意力模块中引入的新参数,以解决语义差异问题,以及 Fine-coarse Frame Attention Module (FFAM) 用于时域一致性,通过沿着空间维度采样来利用时域维度的信息。通过结合这些技术,他们创建了一个 T2V 扩散模型。StableVideo 在现有的 T2I 模型之上设计了一种帧间传播机制和一个聚合网络,以生成从关键帧编辑的图谱,从而实现时空一致性。
4.2 Other Modality-guided Video Editing
先前介绍的大多数方法侧重于文本引导的视频编辑。在本小节中,我们将关注由其他模态(例如,指令和声音)引导的视频编辑。

4.2.1 Instruct-guided Video Editing
指令引导的视频编辑旨在根据给定的输入视频和指令生成视频。由于缺乏视频指令数据集,InstructVid2Vid 利用 ChatGPT、BLIP 和 Tune-A-Video 的组合使用,以相对较低的成本获取输入视频、指令和编辑后视频的三元组。在训练期间,他们提出了帧差异损失,引导模型生成具有时间一致性的帧。CSD 首先使用 Stein 变分梯度下降(SVGD),多个样本共享从扩散模型中蒸馏出的知识以实现样本间的一致性。然后,他们将协作分数蒸馏(CSD)与 InstructPix2Pix 结合起来,实现了带有指令的多图像的连贯编辑。
4.2.2 Sound-guided Video Editing
声音引导的视频编辑的目标是使视觉变化与目标区域的声音一致。为了实现这一目标,Soundini 提出了局部声音引导和光流引导用于扩散采样。具体来说,音频编码器使声音的潜在表示在语义上与潜在图像表示一致。基于扩散模型,SDVE 引入了一个特征串联机制以实现时域一致性。他们通过在残差层中输入噪声信号的频谱特征嵌入来进一步调节网络。
4.2.3 Motion-guided Video Editing
受视频编码过程启发,VideoControlNet 同时利用了扩散模型和 ControlNet。该方法将第一帧设置为 I 帧,其余分成不同的图片组(GoP)。不同 GoP 的最后一帧被设置为 P 帧,而其他帧则设置为 B 帧。然后,给定一个输入视频,模型首先使用扩散模型和 ControlNet 直接基于输入的 I 帧生成 I 帧,然后通过运动引导的 P 帧生成模块(MgPG)生成 P 帧,其中利用了光流信息。最后,B 帧是基于参考的 I/P 帧和运动信息进行插值,而不是使用耗时的扩散模型。
4.2.4 Multi-Modal Video Editing
Make-A-Protagonist 提出了一个多模态条件视频编辑框架,用于更改主角。具体来说,他们利用 BLIP-2 进行视频字幕生成,使用 CLIP Vision Model 和 DALLE-2 Prior 进行视觉和文本线索编码,以及使用 ControlNet 来确保视频的一致性。在推断期间,他们提出了一种基于掩模的去噪采样方法,以将专家模型组合在一起,实现无需注释的视频编辑。CCEdit 将视频结构和外观分离,以实现可控和创意的视频编辑。它使用基础的 ControlNet 来保留视频结构,同时通过文本提示、个性化模型权重和自定义中心帧来进行外观编辑。此外,所提出的时域一致性模块和插值模型可以无缝生成高帧率的视频。
4.3 Domain-specific Video Editing
在本小节中,我们将简要概述一些专为特定领域定制的视频编辑技术,首先介绍视频着色和视频风格转移方法(Sec. 4.3.1),然后介绍专为以人为中心的视频设计的几种视频编辑方法(Sec. 4.3.2)。

4.3.1 Recolor & Restyle
Recolor:视频着色涉及推断灰度帧的合理和时间一致的颜色,这需要同时考虑时间、空间和语义一致性以及颜色的丰富性和忠实度。基于预训练的 T2I 模型,ColorDiffuser 提出了两种新颖的技术:颜色传播注意力作为光流的替代,以及交替采样策略来捕捉相邻帧之间的时空关系。
Restyle: Style-A-Video 设计了一种结合的控制条件方式:文本用于风格指导,视频帧用于内容指导,以及注意力图用于细节指导。值得注意的是,这项工作具有零样本的特点,即无需额外的每个视频训练或微调。
4.3.2 Human Video Editing
Diffusion Video Autoencoders 提出了一种扩散视频自编码器,从给定的以人为中心的视频中提取单一的时不变特征(身份)和每帧的时变特征(运动和背景),并进一步操作单一的不变特征以获得所需的属性,从而实现了时间一致的编辑和高效的计算。为了满足轻松创建高质量 3D 场景的增加需求,Instruct-Video2Avatar 接收一个说话头部视频和编辑指令,并输出一个编辑后的 3D 神经头像化身版本。他们同时利用 Instruct-Pix2Pix 进行图像编辑,EbSynth 进行视频风格化,以及 INSTA 用于照片级别的 3D 神经头像化身。TGDM 采用了零样本 CLIP引导模型来实现灵活的情感控制。此外,他们提出了一个基于多条件扩散模型的 pipeline,以实现复杂的纹理和身份转移。
5. Video Understanding
除了在生成任务中的应用,如视频生成和编辑,扩散模型还在基本视频理解任务中得到了探讨,例如视频时间分割(video temporal segmentation)、视频异常检测(video anomaly detection)、文本视频检索(video retrieval)等,这将在本节中介绍。视频理解的分类详细信息总结在图 5 中。

5.1 Temporal Action Detection& Segmentation
受到 DiffusionDet 的启发,DiffTAD 探索了将扩散模型应用于时间动作检测任务。这涉及将长视频的 ground truth proposals 进行扩散,然后学习去噪过程,这是通过在 DETR 架构中引入一个专门的时域位置查询来实现的。值得注意的是,这种方法在 ActivityNet 和 THUMOS 等基准测试中取得了最先进的性能结果。类似地, DiffAct 使用类似的方法解决了时间动作分割任务,其中动作段从随机噪声中迭代生成,以输入视频特征为条件。所提出的方法的有效性在广泛使用的基准测试中得到了验证,包括GTEA、50Salads 和 Breakfast。
5.2 Video Anomaly Detection
针对无监督视频异常检测,Diff-VAD 和 CMR 利用扩散模型的重建能力来识别异常视频,因为高重建误差通常表示异常。在两个大规模基准测试上进行的实验证明了这种方法的有效性,相对于先前的研究,性能显著提高。 MoCoDAD 侧重于基于骨骼的视频异常检测。该方法应用扩散模型根据个体的过去行动生成多样性和合理的未来运动。通过统计聚合未来的模式,当生成的一组行动偏离实际未来趋势时,就会检测到异常。
5.3 Text-Video Retrieval
DiffusionRet 将检索任务构建为从噪声生成联合分布 �(����������,�����) 的渐进过程。在训练期间,生成器使用生成损失进行优化,而特征提取器则使用对比损失进行训练。通过这种方式,DiffusionRet 灵巧地结合了生成和判别方法的优势,并在开放领域场景中取得了出色的性能,展示了其泛化能力。MomentDiff 和 DiffusionVMR 处理视频片段检索任务,旨在识别与给定文本描述相对应的视频中的特定时间间隔。这两种方法将实际时间间隔扩展为随机噪声,并学会将随机噪声还原为原始时间间隔。这个过程使模型能够学习从任意随机位置到实际位置的映射,有助于从随机初始化中准确定位视频片段。
5.4 Video Captioning
RSFD 研究了视频字幕中经常被忽视的长尾问题。它提出了一种新的用于频率扩散的改进的语义增强方法(RSFD),通过不断识别不常见词元的语言表示,从而改善字幕生成。这使模型能够理解低频词元的语义,从而提高了字幕生成的质量。
5.5 Video Object Segmentation
Pix2Seq-D 将全景分割重新定义为一个离散数据生成问题。它采用了基于模拟比特(analog bits)的扩散模型来建模全景掩模,利用多功能的架构和损失函数。此外,Pix2Seq-D 可以通过整合先前帧的预测来建模视频,从而实现了对物体实例跟踪和视频物体分割的自动学习。
5.6 Video Pose Estimation
DiffPose 解决了基于视频的人体姿势估计问题,将其构建为一个条件热图生成任务。在每个去噪步骤生成的特征的条件下,该方法引入了一个时空表示学习器,它在帧之间聚合视觉特征。此外,还提出了一种基于查找的多尺度特征交互机制,用于在局部关节和全局上下文之间创建多尺度的相关性。这种技术为关键点区域产生了精细的表示。
5.7 Audio-Video Separation
DAVIS 采用生成方法来处理音频-视觉声源分离任务。该模型利用扩散过程从高斯噪声生成分离的幅度,条件是音频混合和视觉内容。由于其生成目标,DAVIS 更适用于实现跨多种类别的高质量声音分离。
5.8 Action Recognition
DDA 专注于基于骨架的人体动作识别。该方法引入了基于扩散的数据增强,以获得高质量和多样性的动作序列。它利用 DDPMs 生成合成的动作序列,生成过程由时空 Transformer 准确引导。实验结果展示了这种方法在自然性和多样性指标方面的优越性。此外,它确认了将合成的高质量数据应用于现有动作识别模型的有效性。
5.9 Video SoundTracker
LORIS 专注于生成与视觉节奏线索同步的音乐配乐。该系统利用潜在条件扩散概率模型进行波形合成。此外,它还结合了上下文感知的条件编码器来考虑时间信息,有助于长期波形生成。作者还将模型的适用性扩展到各种体育场景,能够产生具有出色的音乐质量和节奏对应的长期音乐配乐。
5.10 Video Procedure Planning
PDPP 专注于教学视频中的过程规划。该方法使用扩散模型来描述整个中间动作序列的分布,将规划问题转化为从该分布中进行采样的过程。此外,通过基于初始和最终观察结果的扩散型 U-Net 模型提供准确的条件引导,增强了从学习的分布中学习和采样动作序列的能力。
6. Challenges And Future Trends
尽管基于扩散的方法在视频生成、编辑和理解方面取得了显著进展,但仍存在一些值得探讨的开放性问题。在本节中,我们总结了当前的挑战和潜在的未来方向。
收集大规模视频文本数据集:文本到图像合成取得了巨大成功,主要得益于数十亿高质量(文本,图像)对的可用性。然而,用于文本到视频(T2V)任务的常用数据集相对规模较小,为视频内容收集同样大规模的数据集是一项相当具有挑战性的工作。例如,WebVid 数据集仅包含 1000 万实例,且存在视觉质量有限的显著缺陷,分辨率低至 360P,并受到水印影响。尽管已经在获取数据集的方法方面进行了努力,但仍迫切需要提高数据集规模、注释准确性和视频质量的改进。
高效的训练和推理:与 T2V 模型相关的大规模训练成本是一个重大挑战,一些任务需要使用数百个 GPU。尽管方法如 SimDA 试图减轻训练费用,但数据集的规模和时间复杂度仍然是一个关键问题。因此,探索更高效的模型训练策略和减少推理时间是未来研究的有益方向。
基准和评估方法:虽然存在用于开放领域视频生成的基准(MSRVTT、UCF101)和评估方法(CLIPSIM、FVD),但它们在范围上相对有限,如 Measuring the Quality of Text-to-Video Model Outputs: Metrics and Dataset 中所示。由于在文本到视频(T2V)生成中生成的视频没有真实视频的标准答案,因此现有的度量标准如 Fréchet Video Distance (FVD) 和 Inception Score (IS)主要强调生成视频分布与真实视频分布之间的差异。这使得很难有一个全面的评估度量标准,能够准确反映视频生成的质量。目前,相当依赖用户 AB 测试和主观评分,这是一项劳动密集型任务,可能因主观性而带来偏见。未来构建更加量身定制的评估基准和度量标准也是有意义的研究方向。
模型能力不足:尽管现有方法取得了显著进展,但由于模型能力不足,仍存在许多限制。例如,视频编辑方法在某些情况下经常出现时间一致性失败,比如将人物替换为动物。此外,我们观察到,在第 4.1 节讨论的大多数方法中,对象替换通常受限于生成具有相似属性的输出。此外,在追求高保真度时,许多当前的 T2I 模型使用原始视频的关键帧。然而,由于现成的图像生成模型的固有限制,注入额外对象并同时保持结构和时间一致性仍未解决。进一步的研究和增强是解决这些限制的必要条件。
7. Conclusion
这篇综述深入探讨了 AIGC(AI-Generated Content,人工智能生成内容)时代的最新发展,重点关注了视频扩散模型。据我们所知,这是其类别中的首个工作。我们提供了扩散过程的基本概念、流行的基准数据集以及常用的评估指标的全面概述。在此基础上,我们全面审查了超过 100 种不同的工作,重点关注视频生成、编辑和理解任务,并根据它们的技术观点和研究目标对它们进行了分类。此外,在实验部分,我们详细描述了实验设置,并在各种基准数据集上进行了公平比较分析。最后,我们提出了未来视频扩散模型的几个研究方向。