MongoDB分片集群搭建
----前言
mongodb分片
一般用得比较少,需要较多的服务器,还有三种的角色
一般把mongodb的副本集应用得好就足够用了,可搭建多套mongodb复本集
mongodb分片技术
mongodb副本集可以解决数据备份、读性能的问题,但由于mongodb副本集是每份数据都一模一样的,无法解决数据量过大问题
mongodb分片技术能够把数据分成两份存储,假如shijiange.myuser里面有1亿条数据,分片能够实现5千万左右存储在data1,5千万左右存储在data2
data1、data2需要使用副本集的形式,预防数据丢失
mongodb分片集群三种角色介绍
router角色 #mongodb的路由,提供入口,使得分片集群对外透明。router不存储数据
configsvr角色 #mongodb的配置角色,存储元数据信息。分片集群后端有多份存储,读取数据该去哪个存储上读取,依赖于配置角色。配置角色建议使用副本集
shardsvr角色 #mongodb的存储角色,存储真正的数据,建议使用副本集
依赖关系
当用户通过router角色插入数据时,需要从configsvr知道这份数据插入到哪个节点,然后执行插入动作插入数据到sharedsvr
当用户通过router角色获取数据时,需要从configsvr知道这份数据是存储在哪个节点,然后再去sharedsvr获取数据
mongodb分片集群的搭建说明
使用同一份mongodb二进制文件
修改对应的配置就能实现分片集群的搭建
--第一步,分片集群搭建-configsvr
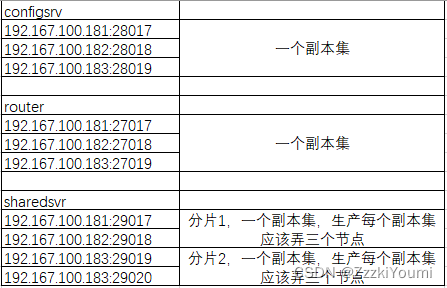
mongodb分片集群实战环境搭建说明
configsvr #使用28017,28018,28019三个端口来搭建
router #使用27017,27018,27019三个端口来搭建
shardsvr #使用29017,29018,29019,29020四个端口来搭建,两个端口一个集群,生产环境肯定是要三个端口
资源有限,就三台服务器,我的分配情况是
mongodb配置角色的搭建,配置文件路径/data/mongodb-fenpiancluster/28017,另外两节点改下路径、端口、IP
systemLog:
destination: file
logAppend: true
path: /data/mongodb-fenpiancluster/28017/mongodb.log
storage:
dbPath: /data/mongodb-fenpiancluster/28017
journal:
enabled: true
processManagement:
fork: true
net:
port: 28017
bindIp: 127.0.0.1,192.167.100.181
replication:
replSetName: zmhconf
sharding:
clusterRole: configsvr
mongodb配置服务集群的启动跟单例的启动方式一致,都是使用mongod
分片集群的配置角色副本集搭建
config = { _id:"zmhconf",
configsvr: true,
members:[
{_id:0,host:"192.167.100.181:28017"},
{_id:1,host:"192.167.100.182:28018"},
{_id:2,host:"192.167.100.183:28019"}
]
}
rs.initiate(config)
验证是否搭建成功
/usr/local/mongodb/bin/mongo 192.167.100.181:28017
rs.status()
--第二步,分片集群搭建-router
router说明
mongodb中的router角色只负责提供一个入口,不存储任何的数据
router角色的搭建,配置文件/data/mongodb-fenpiancluster/27017/mongodb.conf
systemLog:
destination: file
logAppend: true
path: /data/mongodb-fenpiancluster/27017/mongodb.log
processManagement:
fork: true
net:
port: 27017
bindIp: 192.167.100.181
sharding:
configDB: zmhconf/192.167.100.181:28017,192.167.100.182:28018,192.167.100.183:28019
router最重要的配置
指定configsvr的地址,使用副本集id+ip端口的方式指定
配置多个router,任何一个都能正常的获取数据
router的启动
/usr/local/mongodb/bin/mongos -f /data/mongodb-fenpiancluster/27017/mongodb.conf
/usr/local/mongodb/bin/mongos -f /data/mongodb-fenpiancluster/27018/mongodb.conf
/usr/local/mongodb/bin/mongos -f /data/mongodb-fenpiancluster/27019/mongodb.conf
router的验证
需要等到数据角色搭建完才能够进行验证
--第三步,分片集群搭建-sharedsvr
数据角色
分片集群的数据角色里面存储着真正的数据,所以数据角色一定得使用副本集
多个数据角色
mongodb的数据角色搭建,配置文件/data/mongodb-fenpiancluster/29017/mongodb.conf,另外三台也这么写,由于资源不足,把zmhdata2的副本集都放在了192.167.100.183上。
systemLog:
destination: file
logAppend: true
path: /data/mongodb-fenpiancluster/29017/mongodb.log
storage:
dbPath: /data/mongodb-fenpiancluster/29017
journal:
enabled: true
processManagement:
fork: true
net:
port: 29017
bindIp: 192.167.100.181
replication:
replSetName: zmhdata1
sharding:
clusterRole: shardsvr
systemLog:
destination: file
logAppend: true
path: /data/mongodb-fenpiancluster/29019/mongodb.log
storage:
dbPath: /data/mongodb-fenpiancluster/29019
journal:
enabled: true
processManagement:
fork: true
net:
port: 29019
bindIp: 192.167.100.183
replication:
replSetName: zmhdata2
sharding:
clusterRole: shardsvr
数据服务两个集群说明
29017、29018数据角色zmhdata1
29019、29020数据角色zmhdata2
在各自节点分别启动四个数据实例
/usr/local/mongodb/bin/mongod -f /data/mongodb-fenpiancluster/29017/mongodb.log
/usr/local/mongodb/bin/mongod -f /data/mongodb-fenpiancluster/29018/mongodb.log
/usr/local/mongodb/bin/mongod -f /data/mongodb-fenpiancluster/29019/mongodb.log
/usr/local/mongodb/bin/mongod -f /data/mongodb-fenpiancluster/29020/mongodb.log
在各自副本集的节点上写入节点信息(任意找一个副本集内的节点操作):
数据角色zmhdata1
config = { _id:"zmhdata1",
members:[
{_id:0,host:"192.167.100.181:29017"},
{_id:1,host:"192.167.100.182:29018"}
]
}
rs.initiate(config)
数据角色zmhdata2
config = { _id:"zmhdata2",
members:[
{_id:0,host:"192.167.100.183:29019"},
{_id:1,host:"192.167.100.183:29020"}
]
}
rs.initiate(config)
--第四步,分片集群添加数据节点
分片集群添加数据角色,连接到路由角色里面配置,数据角色为副本集的方式
/usr/local/mongodb/bin/mongo 192.167.100.181:27017
sh.addShard("zmhdata1/192.167.100.181:29017,192.167.100.182:29018")
sh.addShard("zmhdata2/192.167.100.183:29019,192.167.100.183:29020")
sh.status()
默认添加数据没有分片存储,操作都是在路由角色里面
use shijiange
for(i=1; i<=500;i++){
db.myuser.insert( {name:'mytest'+i, age:i} )
}
db.dropDatabase() #验证完后删除
经验证发现,新建的数据会随机分配到一个分片中,而不会均分到所有分片。
针对某个数据库的某个表使用hash分片存储,分片存储就会同一个colloection分配两个数据角色(MongoDB的分片是基于集合的,就算有分片集群不等于数据会自动分片,需要实现分片表首先需要启用数据库分片)
use admin
db.runCommand( { enablesharding :"shijiange"});
db.runCommand( { shardcollection : "shijiange.myuser",key : {_id: "hashed"} } )
或者也可以这样的语句来启用分片:
mongos> sh.enableSharding("shijiange")
mongos> sh.shardCollection("shijiange.myuser",{_id: "hashed"});
插入数据校验,分布在两个数据角色上
use shijiange
for(i=1; i<=500;i++){
db.myuser.insert( {name:'mytest'+i, age:i} )
}
配置角色如果挂掉一台会不会有影响
验证mongos多个入口是否能够正常使用