flume 的Channel的种类
目录
1、MemoryChannel
2、FileChannel
3、KafkaChannel
Flume拦截器
消息队列传输消息
1、MemoryChannel
数据放在内存中,会在Flume宕机的时候丢失数据,可以⽤在对数据安全性要求没有那么⾼的场景中⽐如⽇志数据。
2、FileChannel
不会丢失数据,因为数据是放在磁盘上边的⽽且⽀持多⽬录配置可以提⾼写⼊的性能,同时因为有落盘的操作所以效率⽐较低,适合⽤在对数据安全性要求⽐较⾼的场景,⽐如⾦融类的数据。
3、KafkaChannel
主要是为了对接Kafka,使⽤这个可以节省Sink组件也可以提升效率的,我们项⽬中使⽤的就是这个Channel,因为下⼀层是使⽤Kafka来传递消息的。
Flume拦截器
在Flume这⼀层我们还做了⼀个拦截器,主要是对收集到的⽇志做了⼀层过滤,因为⽇志 在后台都是以Json的格式进⾏存储的,在拦截器⾥边对格式不合法的Json进⾏了⼀次简单清洗。还做了⼀个分类型的拦截器,在这个拦截器⾥边我们对数据进⾏类型的区分,主要是做了⼀个打标签的功能对不同的⽇志数据打上不同的标签,然后通过后续的选择器Multiplexing将不同标签的数据放到不同的topic⾥边,⽅便下游对数据进⾏处理。
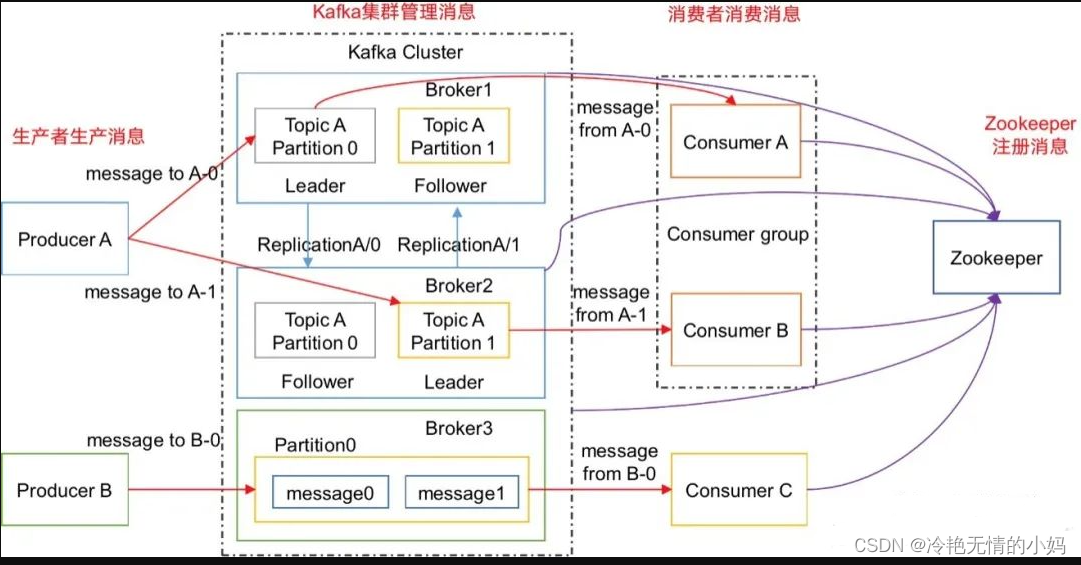
消息队列传输消息
下游数据传输使⽤的是Kafka作为消息队列来传输消息,使⽤Kafka的主要原因是因为Kafka的⾼吞吐量以及可以对数据进⾏分类也就是不同的topic,⽅便下⼀层的使⽤,整体的架构是采⽤Lamda架构设计的,实时和离线都会从Kafka中获取数据来进⾏处理,⽽且还有其他的业务线也是从Kafka中获取数据的,这样做以后可以有效的提⾼数据的复⽤减少数据的冗余。
离线这块我们是在Kafka之后⼜做了⼀层Flume来作为消费者处理Kafka中的数据的,将消费到的数据直接放⼊HDFS中,实时这块使⽤的是flink来消费Kafka中的数据。