单张图像3D重建:原理与PyTorch实现
近年来,深度学习(DL)在解决图像分类、目标检测、语义分割等 2D 图像任务方面表现出了出色的能力。DL 也不例外,在将其应用于 3D 图形问题方面也取得了巨大进展。 在这篇文章中,我们将探讨最近将深度学习扩展到单图像 3D 重建任务的尝试,这是 3D 计算机图形领域最重要和最深刻的挑战之一。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、单图像3D重建任务
单个图像只是 3D 对象到 2D 平面的投影,来自高维空间的一些数据必然在低维表示中丢失。 因此,从单视图 2D 图像来看,永远不会有足够的数据来构造其 3D 组件。

因此,从单个 2D 图像创建 3D 感知的方法需要先了解 3D 形状本身。
在 2D 深度学习中,卷积自动编码器是学习输入图像的压缩表示的非常有效的方法。 将这种架构扩展到学习紧凑的形状知识是将深度学习应用于 3D 数据的最有前途的方法。

2、3D 数据的表示
与只有一种计算机格式(像素)通用表示形式的 2D 图像不同,有多种方法可以用数字格式表示 3D 数据。 它们各有优缺点,因此数据表示的选择直接影响可以使用的方法。

2.1 光栅化形式(体素网格)
光栅法表示的3D模型可以直接应用CNN。
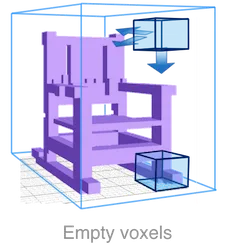
每个蓝色框都是一个体素,大部分体素是空的。
体素(voxel)是体积像素的缩写,是空间网格像素到体积网格体素的直接扩展。 每个体素的局部性共同定义了该体积数据的独特结构,因此 ConvNet 的局部性假设在体积格式中仍然成立。
体素表示的密度低
然而,这种表示是稀疏且浪费的。 有用体素的密度随着分辨率的增加而降低。
- 优点:可以直接应用CNN从2D到3D表示。
- 缺点:浪费表示,细节和资源(计算、内存)之间的高度权衡。
2.2 几何形式
几何形式表达的3D模型不能直接应用CNN。

- 多边形网格:是顶点、边和面的集合,定义了物体的 3 维表面。 它可以以相当紧凑的表示形式捕获粒度细节。
- 点云:3D 坐标 (x, y, z) 中的点的集合,这些点一起形成类似于 3 维物体形状的云。 点的集合越大,获得的细节就越多。 不同顺序的同一组点仍然表示相同的 3D 对象。例如:
# point_cloud1 and point_cloud2 represent the same 3D structure
# even though they are represented differently in memory
point_cloud1 = [(x1, y1, z1), (x2, y2, z2),..., (xn, yn, zn)]
point_cloud2 = [(x2, y2, z2), (x1, y1, z1),..., (xn, yn, zn)]几何表示法的优缺点如下:
- 优点:表现紧凑,注重3D物体的细节表面。
- 缺点:不能直接应用CNN。
3、我们的实现方法
我们将展示一种结合了点云紧凑表示的优点但使用传统的 2D ConvNet 来学习先验形状知识的实现。
3.1 2D 结构生成器
我们将构建一个标准的 2D CNN 结构生成器,用于学习对象的先验形状知识。

体素方法并不受欢迎,因为它效率低下,而且不可能直接用 CNN 学习点云。 因此,我们将学习从单个图像到点云的多个 2D 投影的映射,视点处的 2D 投影定义为: 2D projection == 3D coordinates (x,y,z) + binary mask (m) 。
- 输入:单个 RGB 图像
- 输出:预定视点的 2D 投影
代码如下:
#--------- Pytorch pseudo-code for Structure Generator ---------#
class Structure_Generator(nn.Module):
# contains two module in sequence, an encoder and a decoder
def __init__(self):
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self, RGB_image):
# Encoder takes in one RGB image and
# output an encoded deep shape-embedding
shape_embedding = self.encoder(RGB_image)
# Decoder takes the encoded values and output
# multiples 2D projection (XYZ + mask)
XYZ, maskLogit = self.decoder(shape_embedding)
return XYZ, maskLogit3.2 点云融合
将预测的 2D 投影融合到原生 3D 点云数据中。 这是可能的,因为这些预测的观点是固定的并且是预先已知的。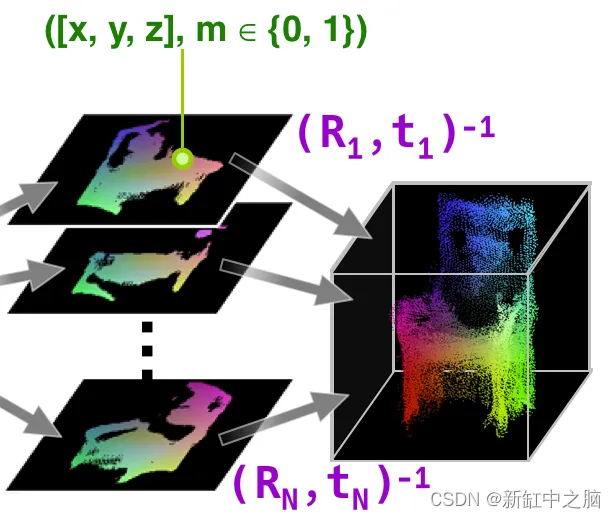
- 输入:预定视点的 2D 投影。
- 输出:点云
3.3 伪渲染器
我们推断,如果从预测的 2D 投影融合的点云有任何好处,那么如果我们从新的视点渲染不同的 2D 投影,它也应该类似于地面实况 3D 模型的投影。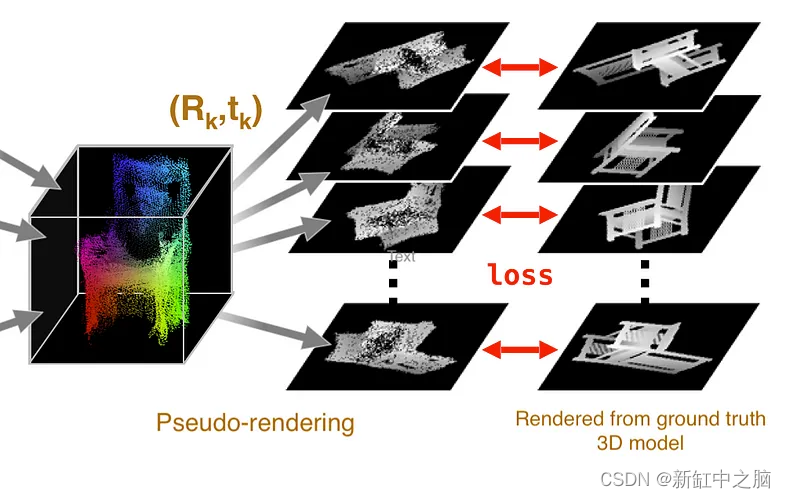
- 输入:点云
- 输出:新视点的深度图像
3.4 训练动态
将这 3 个模块组合在一起,我们获得了端到端模型,该模型学习仅使用 2D 卷积结构生成器从一张 2D 图像生成紧凑的点云表示。
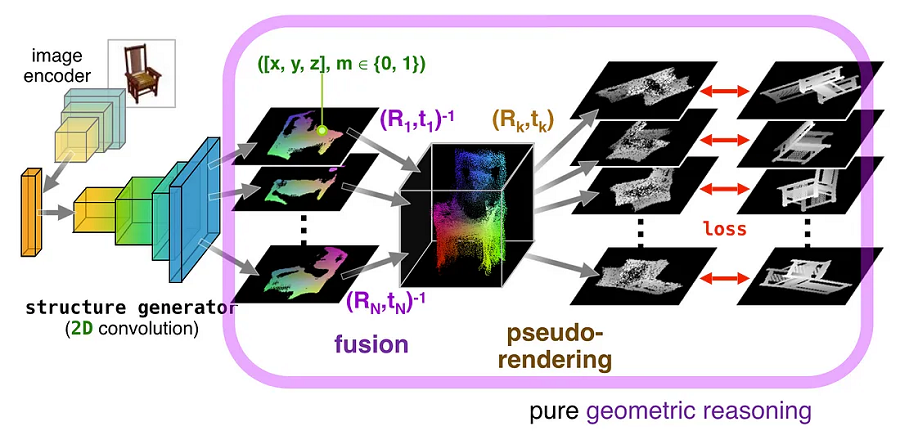
由 2D 卷积结构生成器、点云融合和伪渲染模块组成的完整架构
这个模型的巧妙技巧是让融合+伪渲染模块纯粹可微,几何推理:
- 几何代数意味着没有可学习的参数,使模型尺寸更小并且更容易训练。
- 可微分意味着我们可以通过它反向传播梯度,从而可以使用 2D 投影的损失来学习生成 3D 点云。
代码如下:
# --------- Pytorch pseudo-code for training loop ----------#
# Create 2D Conv Structure generator
model = Structure_Generator()
# only need to learn the 2D structure optimizer
optimizer = optim.SGD(model.parameters())
# 2D projections from predetermined viewpoints
XYZ, maskLogit = model(RGB_images)
# fused point cloud
#fuseTrans is predetermined viewpoints info
XYZid, ML = fuse3D(XYZ, maskLogit, fuseTrans)
# Render new depth images at novel viewpoints
# renderTrans is novel viewpoints info
newDepth, newMaskLogit, collision = render2D(XYZid, ML, renderTrans)
# Compute loss between novel view and ground truth
loss_depth = L1Loss()(newDepth, GTDepth)
loss_mask = BCEWithLogitLoss()(newMaskLogit, GTMask)
loss_total = loss_depth + loss_mask
# Back-propagation to update Structure Generator
loss_total.backward()
optimizer.step()3.5 实验结果
来自地面实况 3D 模型的新深度图像与来自学习点云模型的渲染深度图像的比较:
从一张 RBG 图像 → 3D 点云:

有了详细的点云表示,就可以使用 MeshLab 将其转换为其他表示,例如与 3D 打印机兼容的体素或多边形网格。
原文链接:单图像3D重建原理实现 - BimAnt