Swin Transformer
Swin Transformer
简介
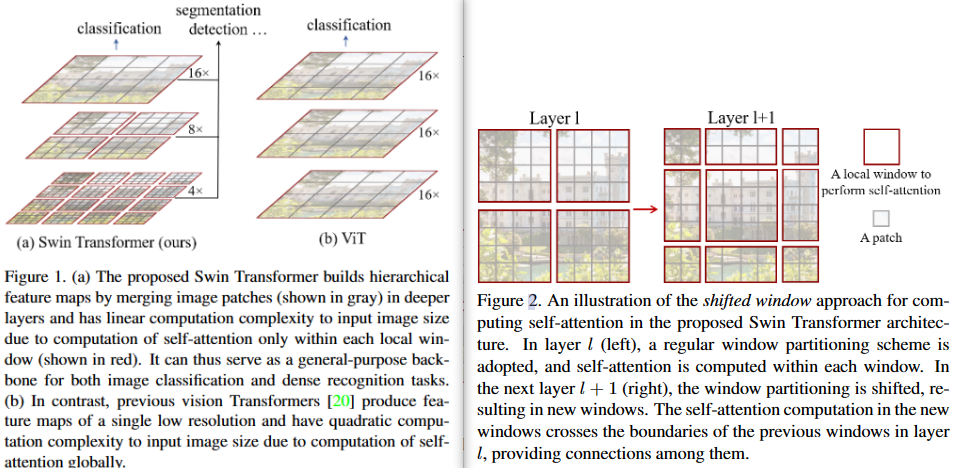
- 下采样的层级设计,能够逐渐增大感受野。
- 采用window进行注意力计算,极大降低了内存消耗,避免了整张图像尺寸大小的qkv矩阵
- 滑窗操作包括不重叠的 local window,和重叠的 cross-window。不重叠的local windows将注意力计算限制在一个窗口(window size固定),而cross-windows则让不同窗口之间信息可以进行关联,实现了信息的交互。
整体架构
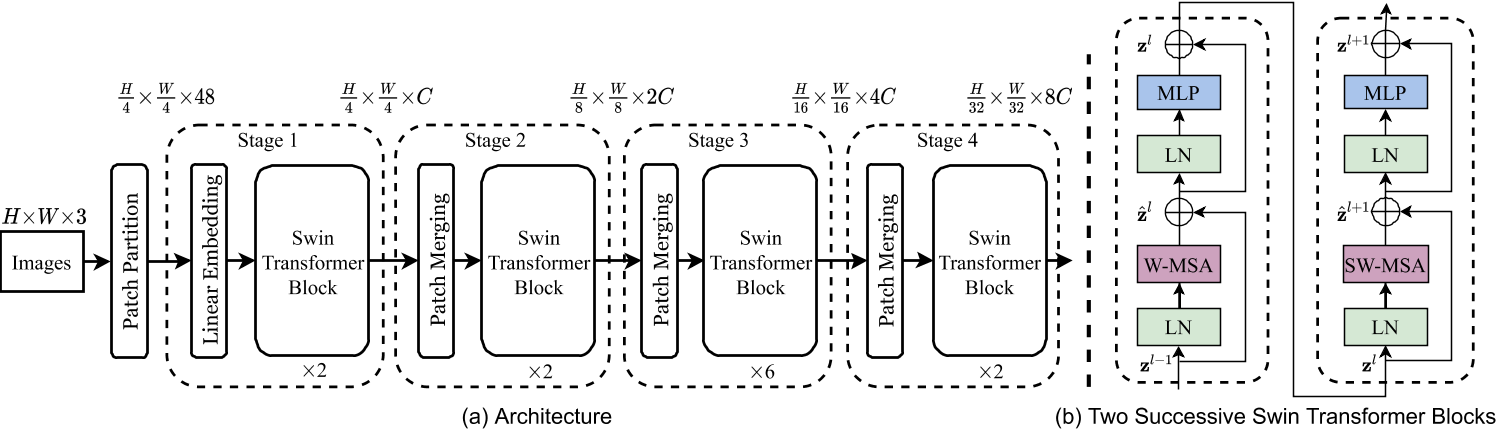
- Patch Partition结构:将图像切分重排,并进行embedding
- Patch Merging结构:下采样方法,实现层次化结构
- Swin Transformer Block:一个W-MSA ,一个SW-MSA,也即是一个window-多头注意力机制和一个shift-windows多头注意力机制,实现将自注意力机制限制在一个windows中进行计算,同时,通过shift-window解决限制在一个windows中后,不同windows之间无信息共享的问题。
Patch Embedding
在图像切分重排中,采用的是使用patch size大小的conv2d进行实现
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding图像切分重排
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
Patch Merging
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x

SW-MSA设计
如下所示,w-msa mask避免窗口5和窗口3进行相似度计算,通过mask只在窗口内部进行计算。
通过对特征图移位,并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价
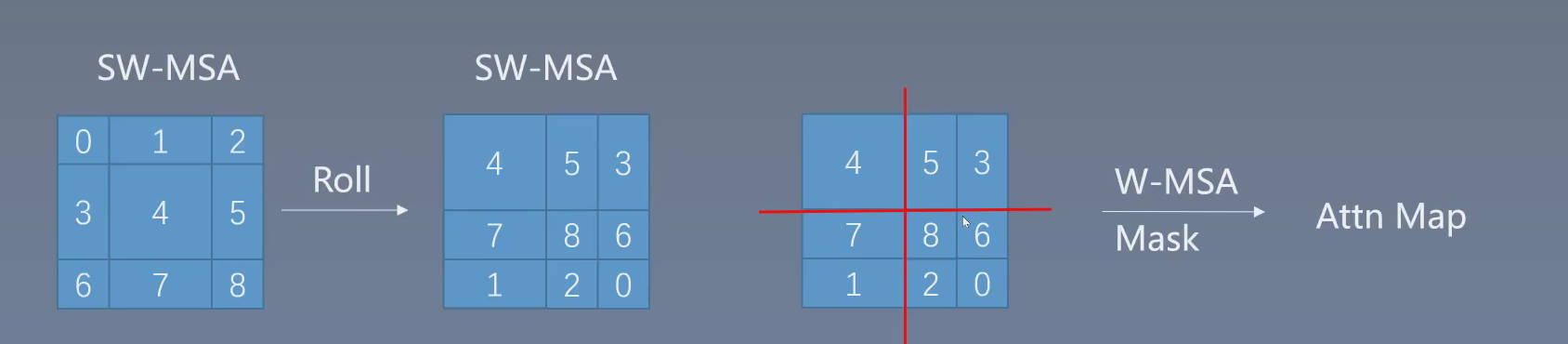

Window Attention
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d + B ) V Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d}}+B)V Attention(Q,K,V)=Softmax(dQKT+B)V
相对位置编码
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)

对于相对位置编码,在2维坐标系中,当偏移从0开始时,(2,1)和(1,2)相对(0,0)的位置编码是不同的,而转为1维坐标后,却是相同数值,为了解决这个问题,采用对x坐标2 * self.window_size[1] - 1操作,从而进行区分。而该相对位置编码需要2 * self.window_size[1] - 1编码数值。
A Survey of Transformers
图解Swin Transformer - 知乎 (zhihu.com)