使用Sqoop命令从Oracle同步数据到Hive,修复数据乱码 %0A的问题
一、创建一张Hive测试表
create table test_oracle_hive(
id_code string
,phone_code string
,status string
,create_time string
) partitioned by(partition_date string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';创建分区字段partition_date,指定分隔符“,”
二、编写Sqoop数据同步命令
我这里使用的是shell脚本的方式:
#!/bin/bash
export LANG="en_US.UTF-8"
part_date=etl_date=`date "-d +0 day" "+%Y%m%d"`
echo "当前分区时间为: $part_date"
sqoop import -D mapred.job.queue.name=root.realtime_queue --connect jdbc:oracle:thin:@//xxx.xxx.xxx.xxx:1521/testdb --username test --password test01 --table APP.TEST_ORACLE_HIVE_TWO --hive-import --hive-partition-key partition_date --hive-partition-value $part_date --hive-table xxx.test_data_oracle_hive --fields-terminated-by ',' --null-string '\\N' --null-non-string '\\N' --hive-overwrite -m 1
if [ $? -eq 0 ]; then
echo ">>>>>>>>>>>>>Oracle同步Hive数据库-执行成功!"
else
echo ">>>>>>>>>>>>>Oracle同步Hive数据库-执行失败!"
fi命令相关属性说明:
- --connect:连接Oracle数据库的URL,例如jdbc:oracle:thin:@219.216.110.120:1521:orcl。
- --username:连接Oracle数据库的用户名,例如TEST1。
- --password:连接Oracle数据库的密码,例如test1。
- --table:要导入的Oracle表名,例如TEST1。
- --hive-table:在Hive中要创建或覆盖的表名,例如test1_test1。
- --fields-terminated-by:指定字段分隔符,例如'\t'(制表符)。
- --hive-import:启用Hive导入。
- --hive-overwrite:在导入数据时覆盖已存在的Hive表。
- --null-string:指定空值对应的字符串,例如'NULL'。
- --null-non-string:指定非空值对应的字符串,例如'NULL'。
三,执行脚本命令
我这里是使用的azkaban做的任务执行,也可以根据自己所需,sh xxx.sh执行脚本,如图:
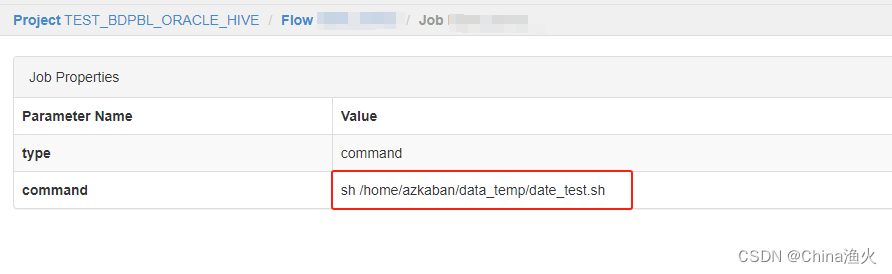
任务执行完成,发现数据有乱码:
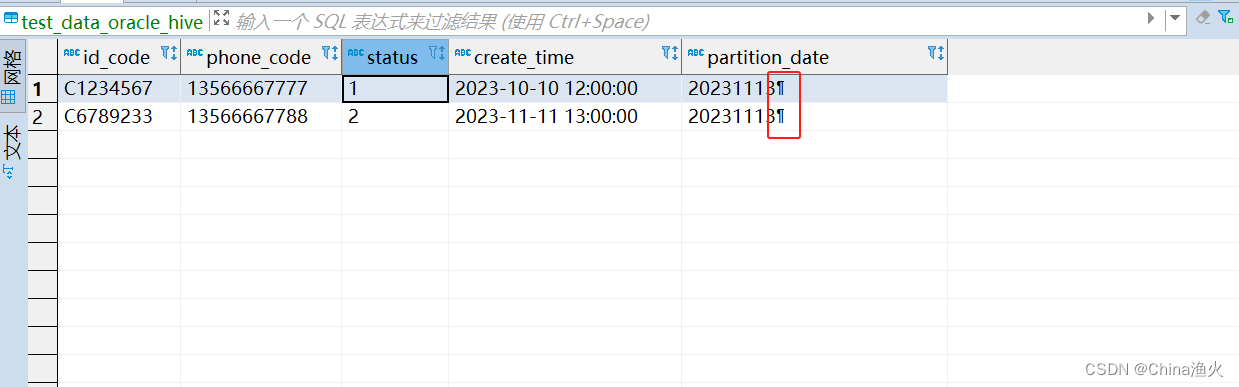
分区时间是这样取值的:

在服务器单独执行命令,发现是文件生成的时候乱码的:

四、问题修改
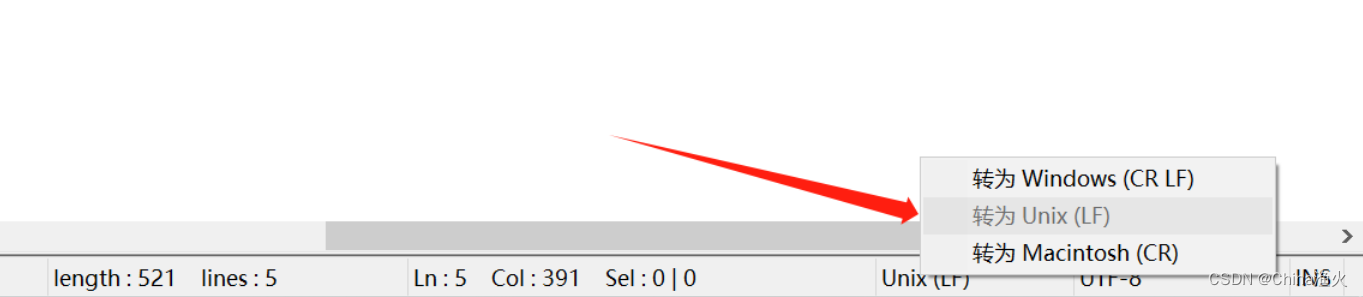
然后,检查命令没问题后,发现我使用的文本编辑器 NotePad++ 在编写命令时,
是在Windows(CR LF) 模式下的,转换为 Unix(LF) ,如图:
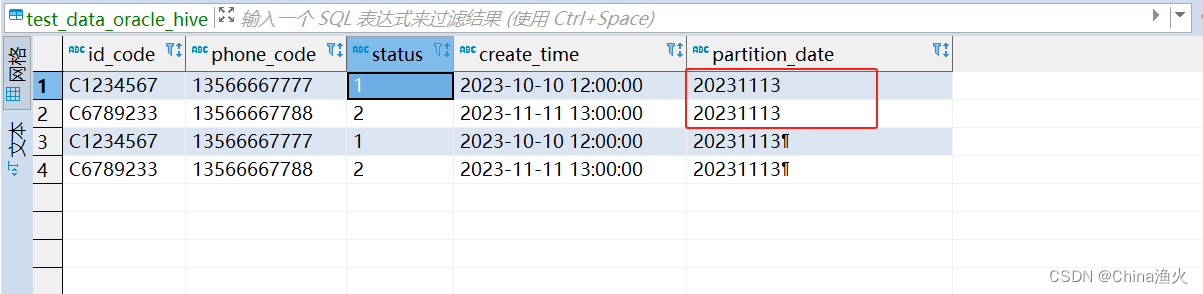
然后,重新执行脚本,数据就恢复正常了

五、Sqoop常用命令
导入数据:
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table users --target-dir /user/hadoop/data导出数据:
sqoop export --connect jdbc:mysql://localhost:3306/test --username root --password root --table users --export-dir /user/hadoop/data查询Job列表:
sqoop job --list查询Job详细信息:
sqoop job --show jobname执行Job
sqoop job --exec jobname删除Job
sqoop job --delete jobname