List 函数排序操作,用对方法事半功倍!
作为一名程序员,以下这些场景你肯定不陌生,
1.数据分析和处理:在处理大量数据时,需要对数据进行排序以进行进一步的分析和处理。例如,在市场调研中,可能需要按照客户的购买频率对客户列表进行排序,以确定哪些客户最有可能购买产品或服务。
2.报表生成:在生成报表时,往往需要按照特定的顺序对数据进行排列,以便清晰地展示数据。例如,在制定销售报告时,可能需要按照销售额对产品进行排序,以了解哪些产品的销售额最高。
3.数据库操作:在数据库管理中,经常需要对数据进行排序以符合特定的查询要求。例如,在查询员工信息时,可能需要按照工资水平对员工列表进行排序,以方便查找工资最高的员工。
4.用户界面设计:在用户界面设计中,经常需要对元素进行排序以实现良好的用户体验。例如,在移动应用中,可能需要按照最近使用的顺序对菜单进行排序,以便用户快速找到他们最常用的功能。
5.算法实现:在实现某些算法时,排序是必要的步骤。例如,快速排序、归并排序等算法的实现需要使用排序操作。
这些场景都用到了List函数排序操作,可以方便地对数据进行整理和分析,以便更好地满足实际需求。
那么,如何高效高质量的使用这一函数呢?
下面是由全栈式全自动软件开发工具 soflu 软件机器人推出的 FuncGPT(慧函数)来操作一波。
函数功能:将2个LIST合并,源LIST合并到目标LIST
参数1:参数名称:fromDatas;参数类型:List<Map<String, Object>>;参数描述:源数据集
参数2:参数名称:toDatas;参数类型:List<Map<String, Object>>;参数描述:目标数据集
参数3:参数名称:fromFiledName;参数类型:String;参数描述:源字段名
参数4:参数名称:toFiledName;参数类型:String;参数描述:目标字段名
返回值:目标LIST
FuncGPT(慧函数)将自动生成以下代码
// 类名:ListMerger
// 函数名:mergeList
// 函数功能:将源LIST合并到目标LIST
// POM依赖包:无
import java.util.List;
import java.util.Map;
import java.util.Objects;
public class ListMerger {
/**
* 将源LIST合并到目标LIST
* @param fromDatas 源数据集
* @param toDatas 目标数据集
* @param fromFieldName 源字段名
* @param toFieldName 目标字段名
* @return 合并后的目标数据集
*/
public static List<Map<String, Object>> mergeList(List<Map<String, Object>> fromDatas, List<Map<String, Object>> toDatas,
String fromFieldName, String toFieldName) {
if (fromDatas == null || toDatas == null) { // 检查数据集是否为空
throw new IllegalArgumentException(“Data lists cannot be null”); // 抛出异常,数据集不能为空
}
if (Objects.equals(fromFieldName, toFieldName)) { // 检查源字段名和目标字段名是否相同
throw new IllegalArgumentException("Field names cannot be the same"); // 抛出异常,字段名不能相同
}
for (Map<String, Object> fromData : fromDatas) { // 遍历源数据集
Object fromFieldValue = fromData.get(fromFieldName); // 获取源字段的值
for (Map<String, Object> toData : toDatas) { // 遍历目标数据集
Object toFieldValue = toData.get(toFieldName); // 获取目标字段的值
if (Objects.equals(fromFieldValue, toFieldValue)) { // 如果源字段的值和目标字段的值相同
toData.putAll(fromData); // 将源数据合并到目标数据
break; // 结束对目标数据集的遍历,进入下一个源数据
}
}
}
return toDatas; // 返回合并后的目标数据集
}
}
// 函数示例
// 将源LIST合并到目标LIST示例
// 入参:fromDatas,源数据集
// 入参:toDatas,目标数据集
// 入参:fromFieldName,源字段名
// 入参:toFieldName,目标字段名
// 出参:mergedList,合并后的目标数据集
// 调用示例:
// List<Map<String, Object>> fromDatas = new ArrayList<>();
// List<Map<String, Object>> toDatas = new ArrayList<>();
// String fromFieldName = “id”;
// String toFieldName = “id”;
// // 添加源数据和目标数据到对应的LIST中
// List<Map<String, Object>> mergedList = ListMerger.mergeList(fromDatas, toDatas, fromFieldName, toFieldName);
// System.out.println(mergedList);
// 输出结果:例如,源数据集fromDatas为:[{id=1, name=A}, {id=2, name=B}],目标数据集toDatas为:[{id=1, age=20}, {id=2, age=30}]
// 合并后的目标数据集为:[{id=1, name=A, age=20}, {id=2, name=B, age=30}]
// 则输出结果为:[{id=1, name=A, age=20}, {id=2, name=B, age=30}]以上代码是由专注AI生成Java函数的FuncGPT(慧函数)秒级生成的。相较于传统人工编码,效率大幅提升不容置疑。使用AI工具辅助代码生成在现下并不是什么新鲜事了,但是选择靠谱的工具是关键。对于开发人员来说,秒级生成代码并不难,难的是生成的代码质量如何,能否拿来即用。如果还需要自己去测试、各种调试,相信很多有一定经验的开发人员宁愿选择手动编码。以下文心一言对该段代码的总结或许能给有担忧的开发人员一剂定心丸。
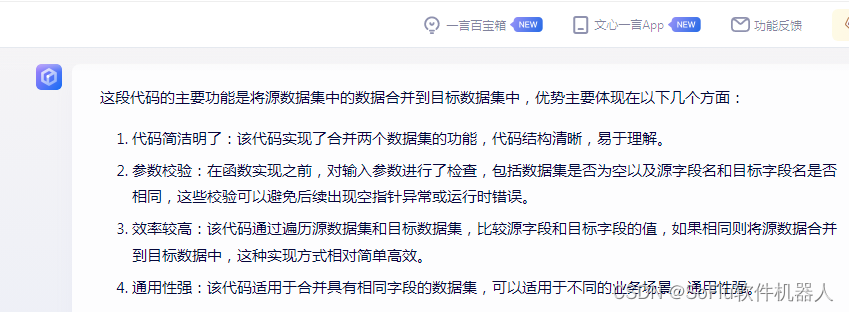
这段代码的主要功能是将源数据集中的数据合并到目标数据集中,优势主要体现在以下几个方面:
代码简洁明了:该代码实现了合并两个数据集的功能,代码结构清晰,易于理解。
参数校验:在函数实现之前,对输入参数进行了检查,包括数据集是否为空以及源字段名和目标字段名是否相同,这些校验可以避免后续出现空指针异常或运行时错误。
效率较高:该代码通过遍历源数据集和目标数据集,比较源字段和目标字段的值,如果相同则将源数据合并到目标数据中,这种实现方式相对简单高效。
通用性强:该代码适用于合并具有相同字段的数据集,可以适用于不同的业务场景,通用性强。
如果你也想使用FuncGPT(慧函数),关注【SoFlu软件机器人】公众号即可免费下载使用。