目标检测标注工具AutoDistill
引言
在快速发展的机器学习领域,有一个方面一直保持不变:繁琐和耗时的数据标注任务。无论是用于图像分类、目标检测还是语义分割,长期以来人工标记的数据集一直是监督学习的基础。
然而,由于一个创新性的工具 AutoDistill,这种情况可能很快会发生改变。
Github代码链接如下:
https://github.com/autodistill/autodistill?source=post_page
AutoDistill 是一个具有开创性的开源项目,旨在彻底改变监督学习的过程。该工具利用大型、较慢的基础模型来训练较小、更快的监督模型,使用户能够从未标记的图像直接转到在边缘运行的自定义模型上进行推断,无需人工干预。
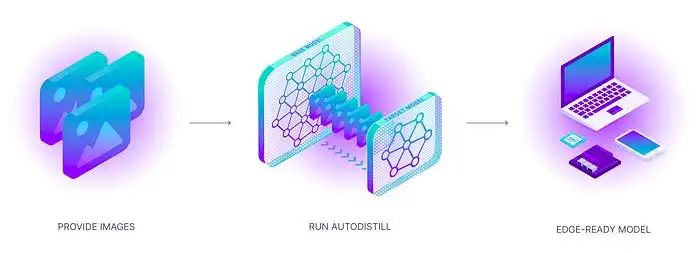
AutoDistill 如何工作?
使用 AutoDistill 的过程就像它的功能一样简单而强大。首先将未标记的数据输入基础模型。然后,基础模型使用本体来为数据集进行标注,以训练目标模型。输出结果是一个蒸馏模型,用于执行特定任务。
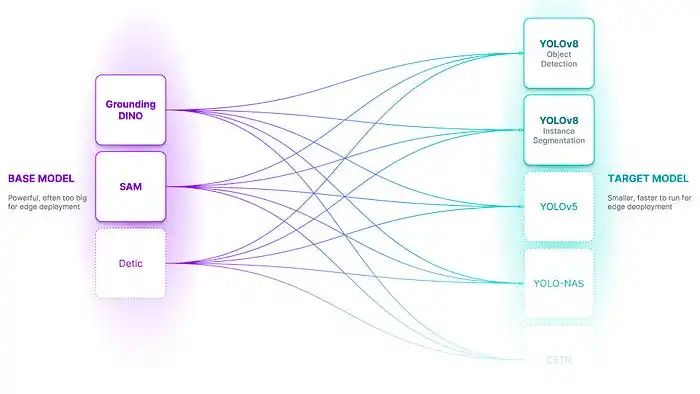
让我们来解释一下这些组件:
-
基础模型:基础模型是一个大型的基础模型,比如 Grounding DINO。这些模型通常是多模式的,可以执行许多任务,尽管它们通常又大又慢,而且昂贵。
-
本体:本体定义了如何提示基础模型、描述数据集的内容以及目标模型将预测什么。
-
数据集:这是一组可以用来训练目标模型的自动标记数据。数据集是由基础模型使用未标记的输入数据和本体生成的。
-
目标模型:目标模型是一个监督模型,用于消耗数据集并输出一个用于部署的蒸馏模型。目标模型的示例可能包括 YOLO、DETR 等。
-
蒸馏模型:这是 AutoDistill 过程的最终输出。它是为您的任务进行了微调的一组权重,可以用于获取预测。
AutoDistill 的易用性确实令人注目:将未标记的输入数据传递给基础模型,比如 Grounding DINO,然后使用本体来标记数据集以训练目标模型,最终得到一个经过加速蒸馏并微调为特定任务的模型。
您可以观看视频,以了解这个过程的实际操作:https://youtu.be/gKTYMfwPo4M
AutoDistill 的影响
标注需要大量人工劳动一直是广泛采用计算机视觉的主要障碍之一。AutoDistill 迈出了克服这一障碍的重要一步。该工具的基础模型可以自主创建许多常见用例的数据集,通过创造性提示和少样本学习,还有扩展其实用性的潜力。
然而,尽管这些进步令人印象深刻,但并不意味着不再需要标记的数据。随着基础模型的不断改进,它们将越来越能够在标注过程中替代或补充人类。但目前,在某种程度上,人工标注仍然是必要的。
目标检测的未来
随着研究人员不断提高目标检测算法的准确性和效率,我们预计将看到它们应用于更广泛的实际应用领域。例如,实时目标检测是一个关键的研究领域,对于自动驾驶、监控系统和体育分析等领域有着众多应用。
另一个具有挑战性的研究领域是视频中的目标检测,它涉及在多个帧之间跟踪对象并处理动态模糊。在这些领域的发展将为目标检测打开新的可能性,并进一步展示了 AutoDistill 等工具的潜力。
结论
AutoDistill 代表了机器学习领域的一项令人兴奋的发展。通过使用基础模型来训练监督模型,该工具为未来铺平了道路,数据标注这一繁琐任务在开发和部署机器学习模型中将不再是一个瓶颈。