AIGC 技术在淘淘秀场景的探索与实践
本文介绍了AIGC相关领域的爆发式增长,并探讨了淘宝秀秀(AI买家秀)的设计思路和技术方案。文章涵盖了图像生成、仿真形象生成和换背景方案,以及模型流程串联等关键技术。
文章还介绍了淘淘秀的使用流程和遇到的问题及处理方法。最后,文章展望了未来AIGC的发展趋势,包括模型使用体验优化、自动化素材生成和产品形态探索等方向。
引言
AIGC相关领域爆发式增长,在图像式AI领域出现Midjourney、SD等专业的工具,也推出了妙鸭相机、美图秀秀等生成虚拟形象的APP。
当前淘宝具有的用户群和商家,可以考虑设计一款结合用户和商家AI工具,以AI生成用户商品代言为主题,帮助商家提高商品展示的吸引力,同时通过个性化和创新的虚拟形象增强用户体验。
在这个背景下,产品同学设计了一款让用户具有代入感的生成产品,淘淘秀(也叫AI买家秀),让用户上传通过照片建立像我但比我好看的商品代言,也会结合一些互动玩法,引发用户创作兴趣提升业务的指标。
关键词:图像类AI创新应用、用户轻松创作、内容分享、结合商家品牌。
技术交流群
建了技术答疑、交流群!想要进交流群、资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

技术调研
整个产品会更复杂一些,这里我们主要探讨AIGC相关的一些技术能力,在买家秀的产品设计下,在AIGC的相关能力依赖上,有如下的诉求:
-
生成优质素材模板,用户要代言的商品素材,以便达到更好的效果;生成
-
结合素材模板和用户图片,生成用户相关图片;用户形象生成
-
在用户图片的基础上,考虑进行背景风格替换,提升丰富性( 策划中,还未上线,也写一下 );背景生成替换
相关的产品链路,这个是比较早期的,在调研之图中的一些方案有做一些调整,但是大致流程接近:
-
生成素材 -> 配置模板 -> 生成用户代言图 -> 进行贴图 ;
-
同时在考虑一些视频类的生成。
图像生成方案对比
要求是**(真人 + 场景 + 商品类目)**的情况下,生成一些比较好的素材图片案例,给到用户使用, 中间使用了几个模型。
现在从事后总结的角度,我觉得对这些模型做一些对比,考虑几个维度:
-
准确性(易用性): 模型生成的图像与提示词描述的一致性
-
可扩展性;API接入与自动化:模型是否支持API接入,支持API的话,跑任务解放运营。影响到速度与效率。
-
成功率: 大约多少张图片,可以有一张可以用的照片, 成功率到一个可以接受的范围。
使用提示词如下:
An ultra-realistic photograph captured with the aesthetics of an iPhone camera, portraying a modern Chinese woman in a distinctive location in Shanghai. The woman is sitting on a wooden bench, the backdrop is softly blurred showcasing the city’s unique architecture. The park is filled with lush greenery and vibrant flowers, exuding tranquility. Soft sunlight bathes the woman’s visage and hair, creating a subtle and natural glow. The image, shot in high resolution with a 750:1200 aspect ratio, exudes the character’s authentic charm and elegance.
不同模型的效果:
模型:Midjourney
特性:易用性高;无可扩展性;成功率高达50%;
优点:生成质量高,真人效果好,可以生成复杂的图像。
缺点:访问限制;没有API,不能直接和系统打通。;速率限制,单个用户一分钟一般只能生成一次。
效果图:

BadCase:

基本不太有,就是风格问题、角度问题等。
模型:通义万相
特性:易用性高;可扩展性高;成功率中等为10~50%;
优点:内部产品;支持API接入;使用起来方便
缺点:真人场景下效果略微差一点,但是不是不能接受;算下来更贵一点,单张照片官网标记价格 0.16元一张。
效果图:

BadCase:

有时候脸会变形
模型:Stable Diffusion
特性:易用性低;可扩展性高;成功率低约为1%;
优点:开源;允许定制模型和自己部署;经过调整后效果也可以达到非常好的地步。
缺点:使用难度大;提示词难调,好的效果需要花较多的时间;只能生成某一种类型的,一旦结合类目或者场景就会有比较大的问题。
效果图:

其实效果也不太行。
BadCase:

出现失败的概率还是比较高的。
模型:DALL·E
特性:DALLE3真人效果当前不太行,暂时忽略。DALLE2还原度有点差。
优点:支持API接入;能生成高分辨率的图像;提示词的还原度比较高
缺点:访问限制;在真人的效果上还是差点意思。
效果图:

BadCase:在我们的场景下,在真实人物上上感觉都是bad case。
模型:堆友
特性:风格、尺寸、生成速度,和上面没有太明显的优势。
优点:内部产品;效果还可以,有一定的还原度
缺点:没有联系对应团队,官网上没有API;在结合具体类目的时候,也会变形;风格有限;尺寸有限
效果图:

整体结论:
-
Midjourney在生成效果上表现最为出色,但其过程需要持续的人工参与,意味着较高的时间成本。
-
在万相和Stable Diffusion效果对比,万相效果更好,如果要做规模化考虑使用下万相;
-
SD在通用场景下效果比较差,但是SD模型提供了全面的定制能力。
基于各自的特色,概括如下:

仿真形象生成方案对比
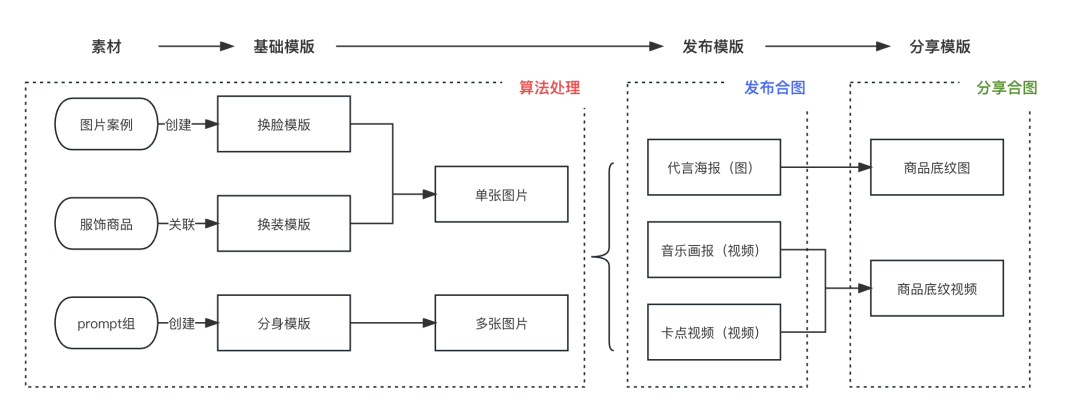
如何让生成的图片要包含对应的人物特征,让用户的代入感更强。我们的算法同学调研不同的方案,数字分身以及换脸。大概效果如下:
考虑到资源问题、以及背后的素材质量问题,走换脸的链路,用的也是主流的Roop模型。
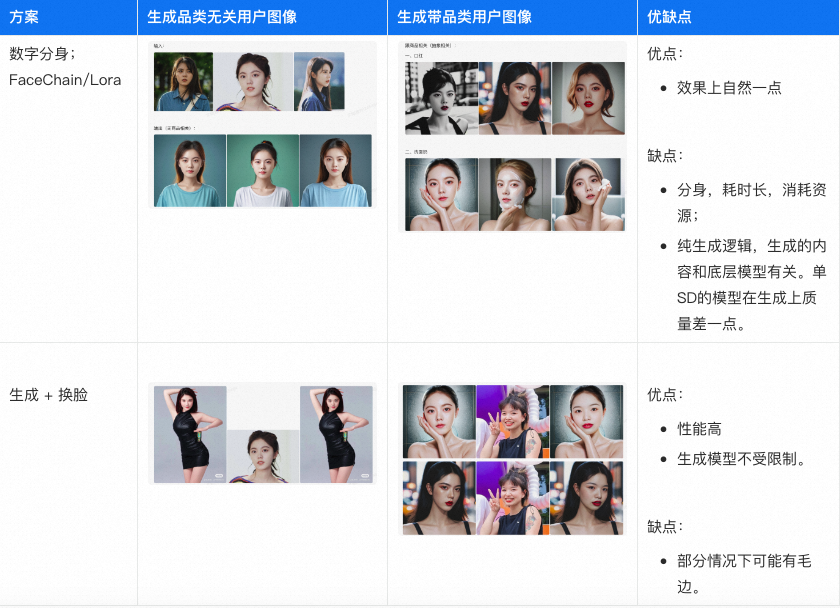
▐ 换背景方案 (测试中)
当前可用的就只有SD的Inpaiting方案,把人物扣出来,使用SemanticGuidedHumanMatting,然后进行背景的补充。因为背后的风格是生成的,提示词未必能涵盖到所有的场景,对输入的图片也要有一定的限制。结果上存在一定的不可控性,
目前效果上还在探索,看以什么样的形态更合适。
一些限制:
-
人不能占空间太小; 背景发挥的空间不要太大。
-
人手里不要拿东西,人物不要有一些物品依赖,比如沙发,坐着之类的,也会生成比较奇怪的内容。
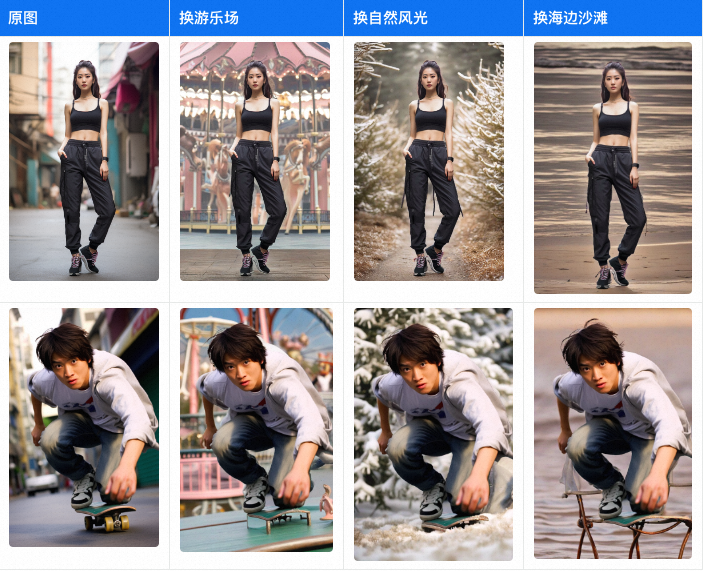
模型流程串联**
可以看一下万相在一些场景上从生成到最终的效果
希望场景:行李箱 - 男- 机场
调整提示词:An Instagram-style portrait that serves as a luggage advertisement featuring a 20-year-old Chinese boy. He’s sitting inside an airport with a suitcase next to him, holding a cup of coffee. The background is the airport, creating a high-end atmosphere. You can see the boy’s complete face and facial features. He’s posing dynamically and relaxed, creating a sophisticated composition, shot using a film camera, 8k
用通义万相随机生成四张照片。(提示词好的话,生成的成功率感觉还可以,效果大家可以评估下到底如何)

淘淘秀AIGC的使用
-
在淘宝客户端搜索【淘淘秀】
-
点击【淘淘秀】进入到对应的小程序。
-
开始我的代言,上传自己的照片
-
生成用户的代言照片;
-
可以选择自己喜欢的代言照片发布到广场,也可以选择私密。
问题与处理
在应用AIGC时遇到的一些问题与处理;
问题1:模型在特定场景下生成效果不佳
方案: 引入外部的Midjourney,人工生产与导入。一些内部模型可以生成的,选择内部模型批量生成组合多个模型使用。
问题2:线上生成效果不稳定,资源消耗大。
方案: 离线生成,人工筛选。预先生成内容以减少资源消耗,并提高内容质量的一致性。
问题3:每部署一个模型,都要写一套TPP;
方案: 利用vipserver进行模型匹配和调用,写一套模型调用的网关,结合限流和队列技术,平衡系统负载,提高部署效率。最开始以为只有TPP才能访问到模型部署的机器,后面发现知道IP之后,应用也可以直接调用模型的服务,就省去TPP这一层了。
问题4: 生成的内容后如何使用。
方案: 开发一些内容的配套工具,内容的导出,内容的检索(图片检索),内容标注,以满足不同场景需求。
展望
在第一阶段,大约一个月的时间主要关注于开发和上线,未来还有一些可尝试的计划和想法:
-
优化模型使用体验:后台体验和用户体验,当前只是确保具备对应的功能,但如何让管理人员介入进来更好的指导模型生产素材,还有很多体验优化可以做。 另外再用户侧的模型生成上,保证效果更好和更稳定。
-
自动化素材生成:看能否设定内容目标后,能利用模型自动化地生成内容,提升内容的规模和丰富性。
-
产品形态探索:从图片到视频,从图片到故事,或者配上音乐等等,有些形态看看是否要尝试,探索更有趣、更吸引人的产品形态。
跳出产品之外,一些预感即将会发生的,随着模型的性能以及效果变好之后,以后对专业的内容创作者依赖越来少,内容的生产效率越来越高。互联网上将会有越来越多的AI内容,针对每个人的个性化素材,解放人们的想象力…
当然内容过度也会有一定的影响,但最后肯定还是往好的方向发展。
考虑到越来越多的AI创新产品出现,本文所涉及到的AIGC能力我们在这次的开发中都沉淀到一个AI的平台,提供一些模型能力的复用, 对类似能力有兴趣的业务,可以探讨交流下,一起探索下更多AI的可能性。