深度学习之基于YoloV5-Pose的人体姿态检测可视化系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
文章目录
- 一项目简介
- 深度学习之基于 YOLOv5-Pose 的人体姿态检测可视化系统介绍
- YOLOv5-Pose 简介
- 系统特点
- 系统架构
- 使用方法
- 二、功能
- 三、系统
- 四. 总结
一项目简介
深度学习之基于 YOLOv5-Pose 的人体姿态检测可视化系统介绍
深度学习在计算机视觉领域取得了显著的成就,其中基于姿态的检测是一个重要的研究方向。本文介绍了基于 YOLOv5-Pose 的人体姿态检测可视化系统。
YOLOv5-Pose 简介
YOLOv5-Pose 是基于 YOLO(You Only Look Once)目标检测框架的一个变种,专注于人体姿态检测。与传统的姿态估计方法不同,YOLOv5-Pose 采用端到端的深度学习方法,通过单一网络实现目标检测和姿态估计,具有较高的准确性和实时性。
系统特点
-
综合性能:YOLOv5-Pose 综合了目标检测和姿态估计,通过一次前向传播实现两个任务,提高了系统整体性能。
-
实时性:采用轻量化网络结构和优化技术,保证了在实时应用中的高效性能,适用于实时人体姿态监测场景。
-
多姿态支持:系统支持检测多种人体姿态,包括站立、坐姿、弯腰等,具有较强的通用性。
-
可视化界面:提供直观的可视化界面,展示检测到的人体姿态信息,方便用户理解和分析。
系统架构
系统整体架构包括以下组件:
-
YOLOv5-Pose 模型:负责目标检测和姿态估计任务。
-
前端界面:通过图形界面展示检测到的人体姿态,提供用户友好的交互方式。
-
后端处理模块:负责接收图像或视频输入,调用 YOLOv5-Pose 模型进行处理,并将结果传递给前端界面。
使用方法
-
数据输入:用户可以通过上传图片或连接摄像头进行实时监测。
-
模型处理:后端模块接收输入数据,使用训练好的 YOLOv5-Pose 模型进行处理。
-
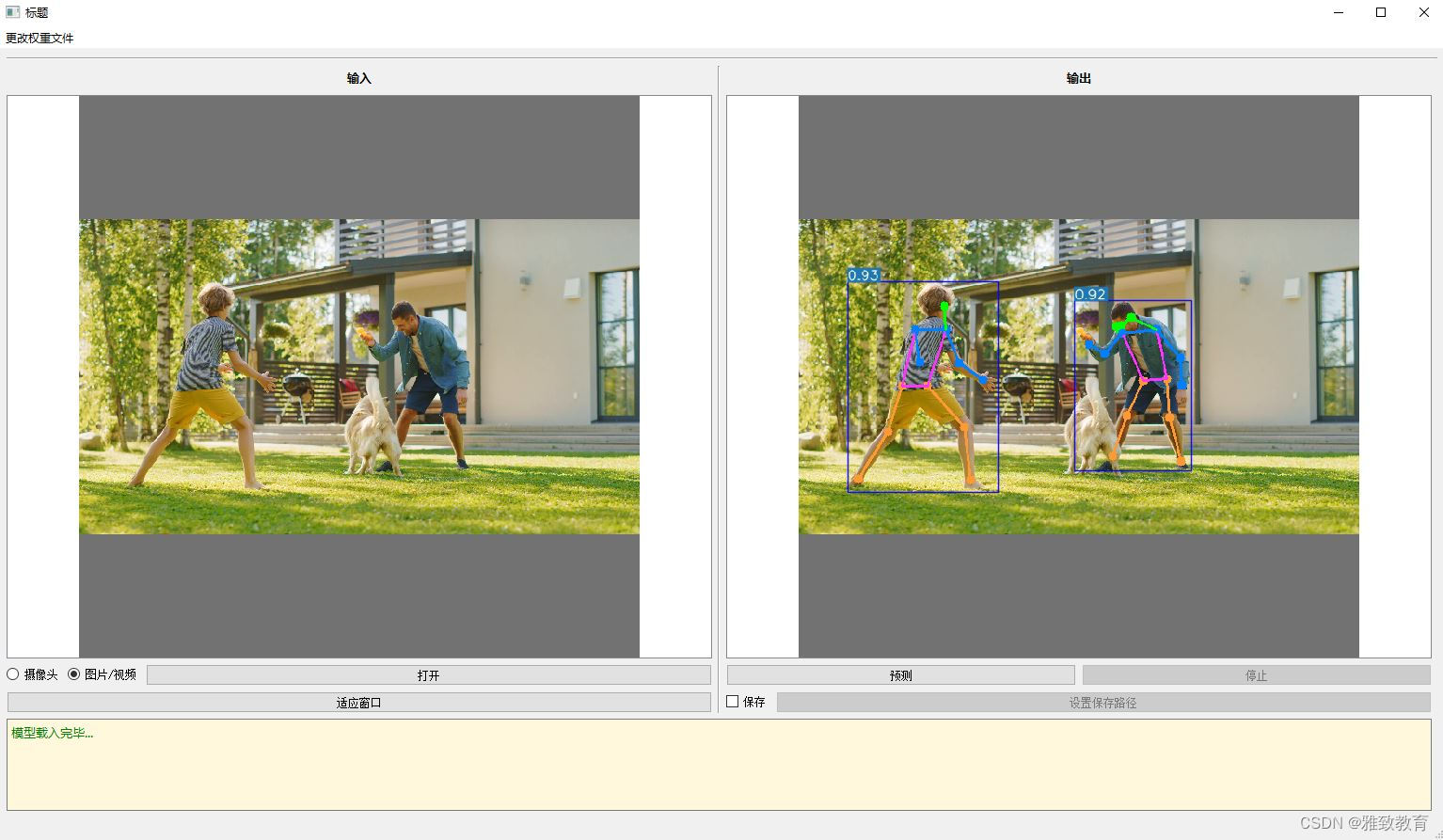
可视化输出:检测到的人体姿态通过前端界面直观展示,包括关键点位置、姿态角度等信息。
二、功能
环境:Python3.7.4、OpenCV4.7、Torch1.10.2、torchvision0.11.3、PyCharm2020
简介:深度学习之基于YoloV5-Pose的人体姿态检测可视化系统(GUI界面),图片,视频,摄像头实时检测。
三、系统
四. 总结
基于 YOLOv5-Pose 的人体姿态检测可视化系统结合了深度学习和实时性能的优势,为人体姿态监测提供了一种高效、准确的解决方案。系统的可视化界面使其在不同应用场景中都具备良好的用户体验和应用前景。