光谱图像超分辨率综述
光谱图像超分辨率综述
简介
论文链接:A Review of Hyperspectral Image Super-Resolution Based on Deep Learning
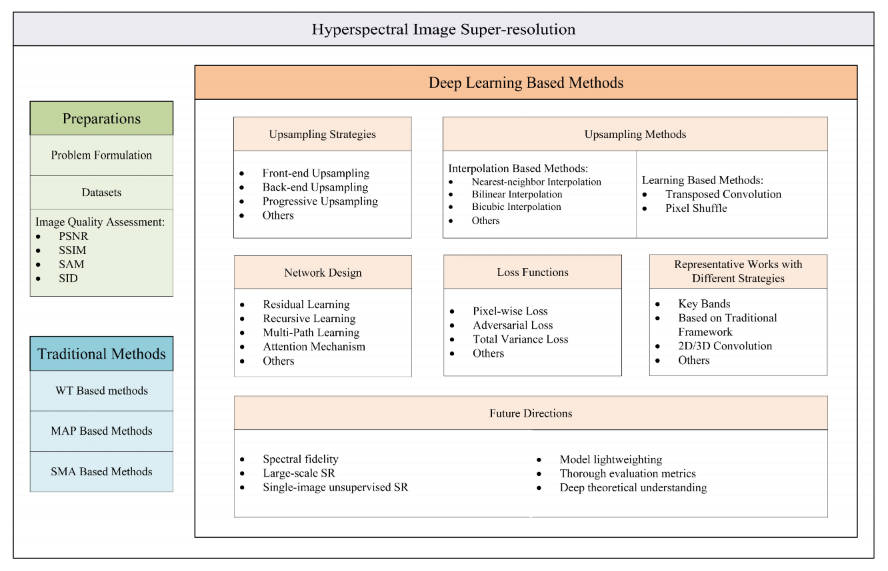
UpSample网络框架
1.Front-end Upsampling
在Front-end上采样中,是首先扩大LR图像,然后通过卷积网络对放大图像进行优化。如"Image Super-Resolution Using Deep Convolutional Networks"(SRCNN)中,首先使用bicubic对图像进行放大,再采用卷积进行处理。
缺点:
- 由于先进行上采样,再进行其他操作,根据上采样倍数的不同,导致卷积部分计算量巨大
- 直接进行上采样,可能将LR图像中的噪声放大,导致超分结果不理想。
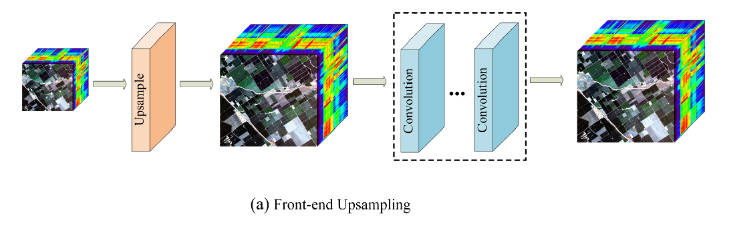
2.Back-end Upsamling
为了降低计算成本,充分利用神经网络的学习能力,将Upsample层放到模型后端进行操作。也就是先通过神经网络对LR图像特征进行提取,减弱噪声部分影响,再采用上采样操作对图像进行超分辨率。如"Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network".(ESPCN),先使用卷积层进行LR图像的特征提取,再采用提出的Pixelshuffle模块——亚像素卷积层(sub-pixelconvolutionlayer)进行上采样得到重建图像。
缺点:
- 由于只进行一次上采样操作,对于较大缩放因子,仍然不是一个好的选择。
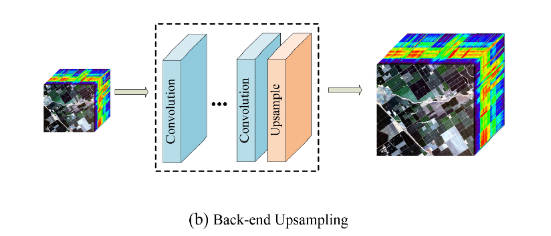
3.Progressive Upsampling
解决缩放因子较大时的问题,通过将其拆分为几个子任务进行解决。
缺点:网络结构更加复杂
Upsample方法
1.基于插值的方法
- Nearest-neighbor Interpolation
- Bilinear Interpolation:没有考虑相邻像素之间灰度值变化率的影响,从而破坏了插值图像的高频信息,经常得到模糊图像边缘
- Bicubic Interpolation:考虑了四个最近像素的灰度值的影响,同时也考虑了周围灰度值变化率的影响,从而获得比前两种插值方法更平滑的边缘、更少的伪影和更少的丢失图像信息,但是其计算量巨大。
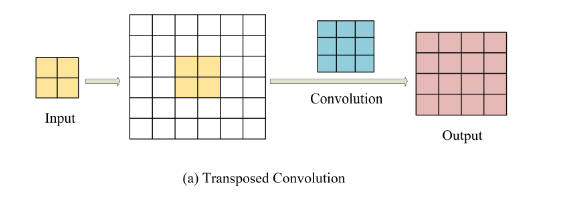
2.Transposed Convolution转置卷积
import torch
import torch.nn as nn
nn.ConvTranspose2d()
#函数定义
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int]],
stride: Union[int, Tuple[int, int]] = 1,
padding: Union[int, Tuple[int, int]] = 0,
output_padding: Union[int, Tuple[int, int]] = 0,
groups: int = 1,
bias: bool = True,
dilation: Union[int, Tuple[int, int]] = 1,
padding_mode: str = 'zeros',
device: Any = None,
dtype: Any = None) -> None
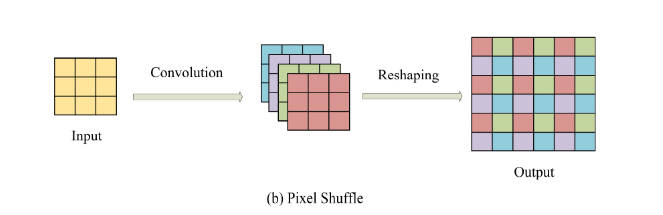
3.Pixel Shuffle
import torch
import torch.nn as nn
self.ps = nn.PixelShuffle(8)
#8为上采样因子,需要注意的是用其处理时,首先需要使用卷积调整channel维度,使其满足为采样因子平方的倍数
常见网络结构
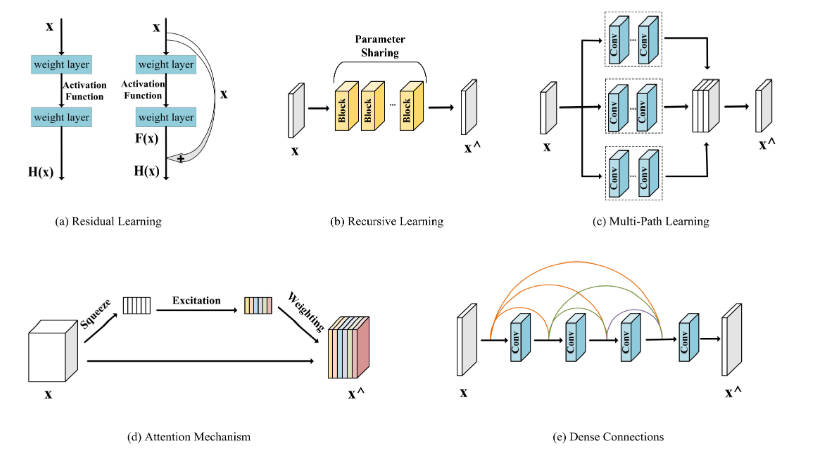
1.残差学习
引人残差网络,方便加深网络,避免梯度消失
2.递归学习
所有残差单元共享相同的权重,大大减少了模型参数的数量。同时,递归学习固有地引入了梯度消失或梯度爆炸的问题因此将残差学习与递归学习相结合是明智的选择。
3.多路径学习
通过将图像输入到不同路径进行特征提取,方便提取多个维度的特征,可以使得特征之间的细节有效互补
4.注意力机制
采用channel attention以及spatial attention,可以分别学习channel维度(频段维度),spatial维度(空间维度hw)之间特定的信息,用于保留输入图像的关键空间信息以及频段信息。
5.密集连接
密集连接最重要的特点是能够重用包括低级特征和高级特征在内的特征,与普通skip connection相比,这是一个优越的方面。
损失计算
1.Pixel-wise损失
像素级别的损失,常见的是L1损失和L2损失,它们都是逐像素进行误差计算。
与L1损失相比,L2损失可以有力地处理较大的误差,但不能对较小的误差进行有效的惩罚,因此经常导致结果过于平滑。这使得L1损耗在大多数情况下是更好的选择。
图像评价指标
- PSNR:峰值信噪比,侧重于像素之间的差异,也就是重建的像素与像素之间的差异,无法对主观感知信息进行较好评估。
- SSIM:结构相似度,人类的主观感知对观察对象的结构很敏感,研究人员提出了结构相似性 (SSIM) 指数来衡量标记图像和重建图像之间的结构相似性。它的评估基于图像结构,比PSNR更能考虑视觉感知。使用SSIM下的结果更符合人类的主观感受
- SAM:将HSI的每个图像元素的频谱视为高维向量,通过计算对应向量之间的角度来测量光谱相似度。角度越小,它属于同一类型特征的可能性就越大。在执行分类任务时,通过计算未知向量与已知向量之间的谱角的大小来识别未知图像元素的类。
- 详细请见光谱图像常见评价指标-CSDN博客