hologres 索引与查询优化
hologres 优化部分
- 1 hologres 建表优化
- 1.1 建表中的配置优化
- 1.1 字典索引 dictionary_encoding_columns
- 1.2 位图索引 bitmap_columns
- 1.2.2 Bitmap和Clustering Key的区别
- 1.3 聚簇索引Clustering Key
1 hologres 建表优化
1.1 建表中的配置优化
根据 holo的 存储引擎部分的知识可以得知,holo在建表的时候设置合适的索引和排序规则十分重要。
Hologres存储引擎的基本抽象是分布式的表,为了让系统可扩展,我们需要把表切分为分片(Shard)。 为了更高效地支持JOIN以及多表更新等场景,用户可能需要把几个相关的表存放在一起,为此Hologres引入了表组(Table Group)的概念。分片策略完全一样的一组表就构成了一个表组,同一个表组的所有表有同样数量的分片。用户可以通过“shard_count"来指定表的分片数,通过“distribution_key"来指定分片列。目前我们只支持Hash的分片方式。
表的数据存储格式分为两类,一类是行存表,一类是列存表,格式可以通过“orientation"来指定。
每张表里的记录都有一定的存储顺序,用户可以通过“clustering_key"来指定。如果没有指定排序列,存储引擎会按照插入的顺序自动排序。选择合适的排序列能够大大优化一些查询的性能。
表还可以支持多种索引,目前我们支持了字典索引和位图索引。用户可以通过“dictionary_encoding_columns"和“bitmap_columns"来指定需要索引的列。
下面是一个示例:
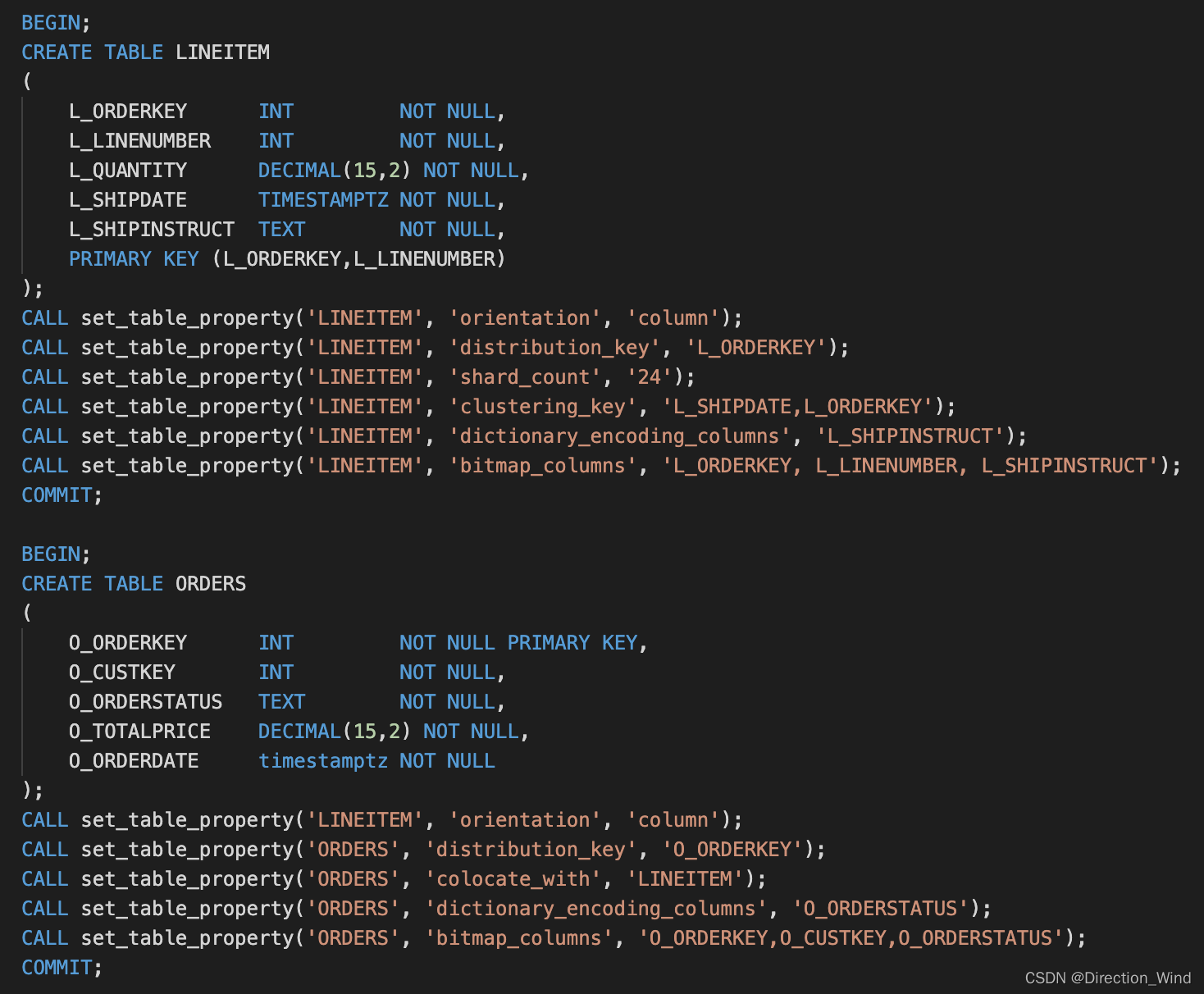
这个例子建了LINEITEM 和 ORDERS两个表,由于LINEITEM表还指定了主键(PRIMARY KEY),存储引擎会自动建立索引来保证主键的唯一。用户通过指定“colocate_with“把这两个表放到了同一个表组。这个表组被分成24个分片(由shard_count指定)。 LINEITEM将根据L_ORDERKEY的数据值来分片,而ORDERS将根据O_ORDERKEY的数据值来分片。LINEITEM的L_SHIPINSTRUCT以及ORDERS的O_ORDERSTATUS字段将会创建字典。LINEITEM的L_ORDERKEY, L_LINENUMBER, L_SHIPINSTRUCT字段以及ORDERS的O_ORDERKEY,O_CUSTKEY,O_ORDERSTATUS字段将会建立位图索引。
这里额外介绍一下 字典索引 dictionary_encoding_columns 和 位图索引 bitmap_columns。
1.1 字典索引 dictionary_encoding_columns
字典编码可以将字符串的比较转成数字的比较,加速Group By、Filter等查询。在Hologres中可以对指定字段进行字典编码,即为指定字段的值构建字典映射,设置Dictionary Encoding的命令语法如下。
-- Hologres V2.1版本起支持的语法
CREATE TABLE <table_name> (...) WITH (dictionary_encoding_columns = '[<columnName>{:[on|off|auto]}[,...]]');
-- 所有版本支持的语法
CREATE TABLE <table_name> (...);
CALL set_table_property('table_name', 'dictionary_encoding_columns', '[<columnName>{:[on|off|auto]}[,...]]');

使用建议
建议将有字符串比较的列设置为字典编码列(dictionary_encoding_columns),并且列的基数较小,即数据重复度较高。
不建议将所有的列都设置为字典编码列,因为这样做会带来额外的编码、解码开销。
不建议为实际内容为JSON,但保存为text类型的列设置字典编码。
可以在建表之后单独使用设置字典编码。表示修改字典编码列,修改之后非立即生效,字典编码构建和删除在后台异步执行,详情请参见ALTER TABLE。
使用说明
Dictionary Encoding只能用于列存表或者行列共存表。
Dictionary Encoding指定的列可以为空。
取值较少的列适合设置字典编码,可以压缩存储。
Hologres V0.8及更早版本中默认所有TEXT类型字段都会被隐式地设置为Dictionary Encoding。Hologres V0.9及之后版本中,所有TEXT数据类型字段的dictionary_encoding_columns属性默认取值auto。即当表有数据写入时,如果字段里数值的重复度大于等于90%,那么系统就会对该字段开启字典编码。
技术原理
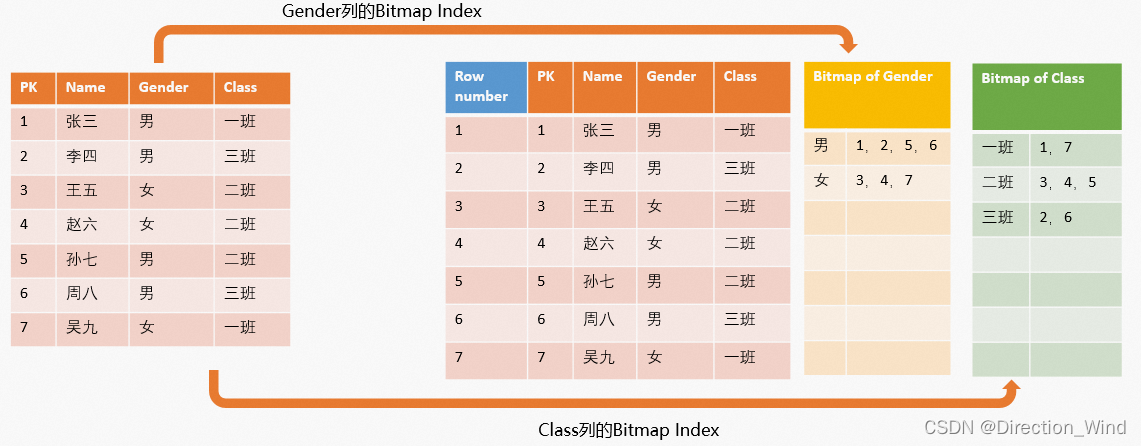
Dictionary Encoding是一种压缩存储的技术,系统会将原始数据编码为数值类型存储,同时也会维护对应的编码表结构,在数据读取时,会根据编码表进行数据解码操作,因此在字符串比较的场景中,尤其是对基数小的列,有加速作用,常用于Group By、Filter等过滤查询场景中。系统会默认将TEXT数据类型的字段设置Dictionary Encoding。但是解码会带来额外的计算开销,尤其是基数大的列(数据的重复度较低,比如一列里一半值都不相同)和用于Join的字段,字典编码会带来更多额外的编码、解码开销,因此不建议所有的列都设置为Dictionary Encoding。字典编码示意图如下所示。

使用示例
- V2.1版本起支持的语法:
CREATE TABLE tbl (
a int NOT NULL,
b text NOT NULL,
c text NOT NULL
)
WITH (
dictionary_encoding_columns = 'a:on,b:off,c:auto'
);
-- 修改dictionary_encoding_columns
ALTER TABLE tbl SET (dictionary_encoding_columns = 'a:off');--ALTER TABLE语法仅支持全量修改
- 所有版本支持的语法:
--创建表tbl并设置dictionary_encoding_columns索引
begin;
create table tbl (
a int not null,
b text not null,
c text not null
);
call set_table_property('tbl', 'dictionary_encoding_columns', 'a:on,b:off,c:auto');
commit;
--修改dictionary_encoding_columns索引
call set_table_property('tbl', 'dictionary_encoding_columns', 'a:off');--全量修改,b和c因为是text列,会被默认设置为dictionary_encoding_columns
call update_table_property('tbl', 'dictionary_encoding_columns', 'c:off');--增量修改,仅将c关闭dictionary_encoding_columns
1.2 位图索引 bitmap_columns
在Hologres中,bitmap_columns属性指定位图索引,是数据存储之外的独立索引结构,以位图向量结构加速等值比较场景,能够对文件块内的数据进行快速的等值过滤,适用于等值过滤查询的场景。使用语法如下。
-- Hologres V2.1版本起支持的语法
CREATE TABLE <table_name> (...) WITH (bitmap_columns = '[<columnName>{:[on|off]}[,...]]');
-- 所有版本支持的语法
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'bitmap_columns', '[<columnName>{:[on|off]}[,...]]');

使用建议
适合将等值查询的列设置为Bitmap,能够快速定位到符合条件的数据所在的行号。但需要注意的是Bitmap对于基数比较高(重复数据较少)的列会有比较大的额外存储开销。
不建议为每一列都设置Bitmap,不仅会有额外存储开销,也会影响写入性能(因为要为每一列构造Bitmap)。
不建议为实际内容为JSON,但保存为text类型的列设置Bitmap。
使用限制
只有列存表和行列共存表支持设置Bitmap,行存表不支持设置。
Bitmap指定的列可以为空。
当前版本默认所有TEXT类型的列都会被隐式地设置为Bitmap。
设置位图索引命令可以在事务之外单独使用,表示修改位图索引列,修改之后非立即生效,比特编码构建和删除在后台异步执行,详情请参见ALTER TABLE。
bitmap_columns属性仅支持设为on或off,Hologres V2.0版本起,不支持将bitmap_columns属性设为auto。
技术原理
Bitmap不同于Distribution Key和Clustering Key,Bitmap是数据存储之外的独立索引,设置了Bitmap索引之后,系统会将列对应的数值生成一个二进制字符串,用于表示取值所在位置的Bitmap,当查询命中Bitmap时,会快速定位到数据所在的行号(Row Number),从而快速过滤出数据。但Bitmap并不是没有开销的,对于以下场景需要注意事项如下:
列的基数较高(重复数据较少)场景:假如列的基数较高,那么就会为每一个值生成一个Bitmap,当非重复值很多的时候,就会形成稀疏数组,占用存储较多。
大宽表的每一列都设置为Bitmap场景:如果为大宽表的每一列都设置为Bitmap,那么在写入时每个值都需要构建成Bitmap,会有一定的系统开销,从而影响写入性能。
综上,Bitmap本质上是空间换时间的手段,对于数据分布比较均匀的列有比较高的性价比。
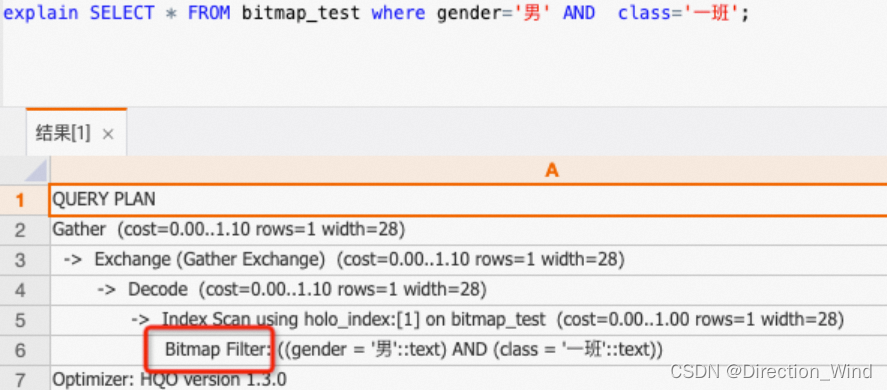
如下示例,可以通过explain SQL查看是否命中Bitmap索引。在执行计划中,有Bitmap Filter则说明命中Bitmap索引。
- V2.1版本起支持的语法:
CREATE TABLE bitmap_test (
uid int NOT NULL,
name text NOT NULL,
gender text NOT NULL,
class text NOT NULL,
PRIMARY KEY (uid)
)
WITH (
bitmap_columns = 'gender,class'
);
INSERT INTO bitmap_test VALUES
(1,'张三','男','一班'),
(2,'李四','男','三班'),
(3,'王五','女','二班'),
(4,'赵六','女','二班'),
(5,'孙七','男','二班'),
(6,'周八','男','三班'),
(7,'吴九','女','一班');
explain SELECT * FROM bitmap_test where gender='男' AND class='一班';
- 所有版本支持的语法:
begin;
create table bitmap_test (
uid int not null,
name text not null,
gender text not null,
class text not null,
PRIMARY KEY (uid)
);
call set_table_property('bitmap_test', 'bitmap_columns', 'gender,class');
commit;
INSERT INTO bitmap_test VALUES
(1,'张三','男','一班'),
(2,'李四','男','三班'),
(3,'王五','女','二班'),
(4,'赵六','女','二班'),
(5,'孙七','男','二班'),
(6,'周八','男','三班'),
(7,'吴九','女','一班');
explain SELECT * FROM bitmap_test where gender='男' AND class='一班';
如下所示执行计划结果中有Bitmap Filter算子,说明命中Bitmap索引。
1.2.2 Bitmap和Clustering Key的区别
-
相同点:
Bitmap和Clustering Key都是文件内的数据过滤。 -
不同点:
Bitmap更适合等值查询,通过文件号定位到数据;Clustering Key是文件内的排序,因此更适合范围查询。
Clustering Key的优先级会比Bitmap更高,即如果为同一个字段设置了Clustering Key和Bitmap,那么优化器会优先使用Clustering Key去匹配文件,示例如下: -
V2.1版本起支持的语法:
--设置uid,class,date 3列为clustering key,text列设置默认为bitmap
CREATE TABLE ck_bit_test (
uid int NOT NULL,
name text NOT NULL,
class text NOT NULL,
date text NOT NULL,
PRIMARY KEY (uid)
)
WITH (
clustering_key = 'uid,class,date',
bitmap_columns = 'name,class,date'
);
INSERT INTO ck_bit_test VALUES
(1,'张三','1','2022-10-19'),
(2,'李四','3','2022-10-19'),
(3,'王五','2','2022-10-20'),
(4,'赵六','2','2022-10-20'),
(5,'孙七','2','2022-10-18'),
(6,'周八','3','2022-10-17'),
(7,'吴九','3','2022-10-20');
-所有版本支持的语法:
--设置uid,class,date 3列为clustering key,text列设置默认为bitmap
begin;
create table ck_bit_test (
uid int not null,
name text not null,
class text not null,
date text not null,
PRIMARY KEY (uid)
);
call set_table_property('ck_bit_test', 'clustering_key', 'uid,class,date');
call set_table_property('ck_bit_test', 'bitmap_columns', 'name,class,date');
commit;
INSERT INTO ck_bit_test VALUES
(1,'张三','1','2022-10-19'),
(2,'李四','3','2022-10-19'),
(3,'王五','2','2022-10-20'),
(4,'赵六','2','2022-10-20'),
(5,'孙七','2','2022-10-18'),
(6,'周八','3','2022-10-17'),
(7,'吴九','3','2022-10-20');
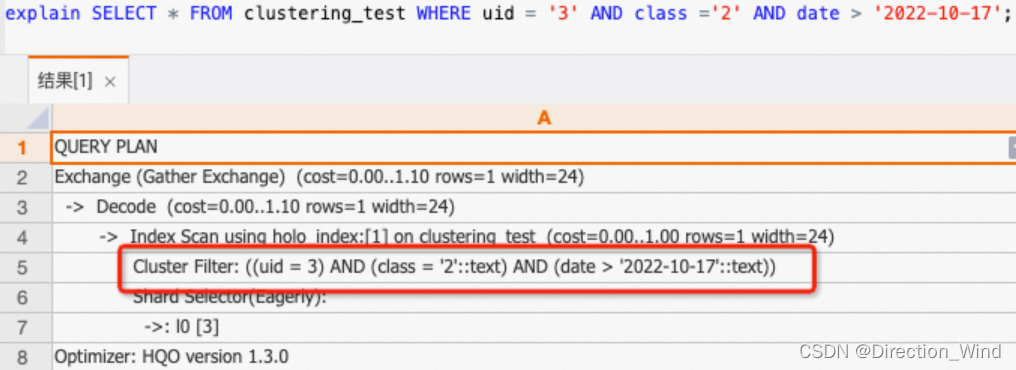
查询uid,class,date 三列,SQL符合左匹配特征,都命中Clustering Key,即使是等值查询也走Clustering Key,而不是走Bitmap。
SELECT * FROM clustering_test WHERE uid = ‘3’ AND class =‘2’ AND date > ‘2022-10-17’;
如下所示执行计划结果中有Cluster Filter算子,没有Bitmap Filter算子,说明查询走Clustering Key,而不是走Bitmap。
查询uid,class,date 三列,但class是范围查询,根据左匹配原则,SQL里匹配到>或者<则停止左匹配,那么date因不满足左匹配原则,就不会命中Clustering Key。date设置了Bitmap,则会使用Bitmap。
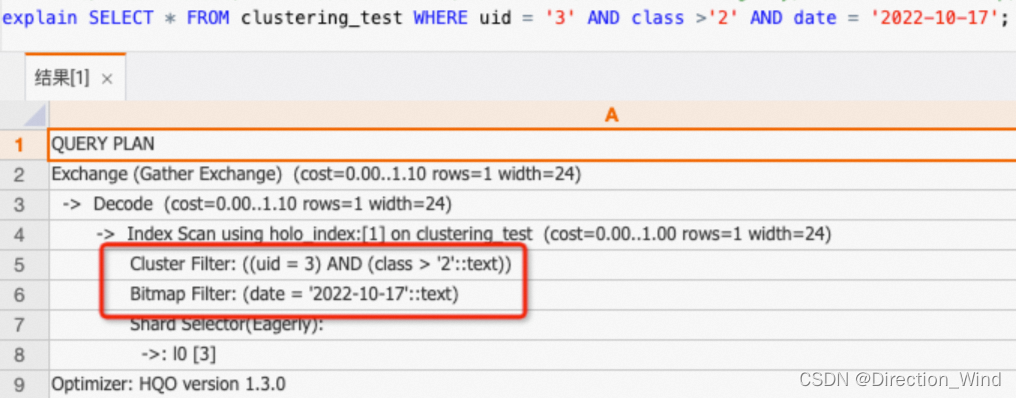
SELECT * FROM clustering_test WHERE uid = ‘3’ AND class >‘2’ AND date = ‘2022-10-17’;
如下所示执行计划结果中有Cluster Filter算子,说明查询uid,class走走Clustering Key;有Bitmap Filter算子,说明查询date走Bitmap。
使用示例
V2.1版本起支持的语法:
CREATE TABLE tbl (
a text NOT NULL,
b text NOT NULL
)
WITH (
bitmap_columns = 'a:on,b:off'
);
-- 修改bitmap_columns
ALTER TABLE tbl SET (bitmap_columns = 'a:off');--ALTER TABLE语法仅支持全量修改
所有版本支持的语法:
--创建tbl并设置bitmap索引
begin; create table tbl (
a text not null,
b text not null
);
call set_table_property('tbl', 'bitmap_columns', 'a:on,b:off');
commit;
--修改bitmap索引
call set_table_property('tbl', 'bitmap_columns', 'a:off');--全量修改,将a字段的bitmap都关闭
call update_table_property('tbl', 'bitmap_columns', 'b:off');--增量修改,将b字段的bitmap关闭,a保留
1.3 聚簇索引Clustering Key
https://www.alibabacloud.com/help/zh/hologres/user-guide/clustering-key?spm=a2c63.p38356.0.0.1dc97ed4wuX9pr