理解CLIP模型
1.简介
学习深度学习必看CLIP!论文链接arxiv.org/pdf/2103.00020v1.pdf。
简单来说就是传统的分类任务被用来预测指定的类别,有监督训练限制了模型的通用性和可用性,并且需要带有标签的数据来训练,该篇论文就想直接从原始文本中学习图像特征,具体就是从网络上采集大量的带有文字描述的图片,同时向网络输入原始文字和图像,网络来学习他们之间的关系。预测时通过输入一句话就能判断图像是否与其匹配了,具有很强的泛化性能。这就是zero shot,不用数据集中任何一张图片,就能够达到ResNet-50的精度。
2.方法
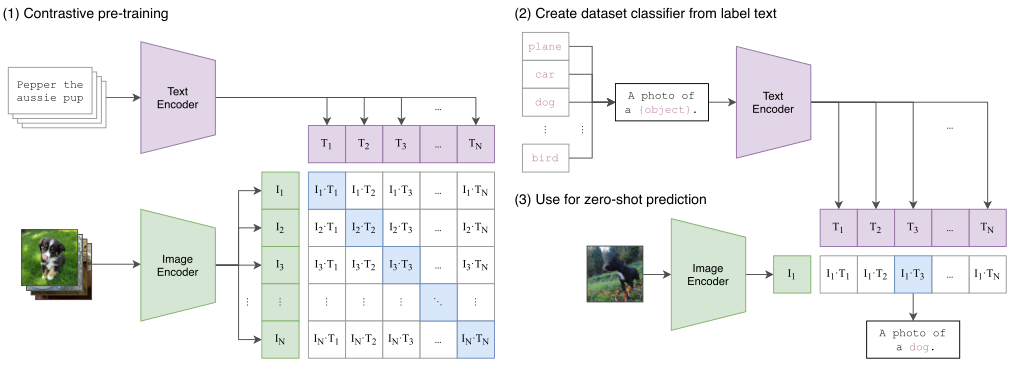
方法的核心思想是从自然语言的监督中学习感知。这种方法其实一点都不新,之前也有人做过,只不过之前的方法描述的很混淆,并且数据规模不大。那么为什么非要用自然语言监督的方法来训练一个视觉模型呢?第一个就是说你不需要再去标注数据了,直接从网上下载图像和文字的配对就行了,减少了很多的工作量。第二个就是将图片和文字绑定到了一起,模型学习的就是一个多模态的特征了。这样就很容易去做zero-shot的迁移任务了。
该方法不需要之前的那种黄金标签,而是从互联网上的大量文本中学习。与大多数无监督或自监督学习方法相比,从自然语言中学习也有重要的优势,因为它不仅“只是”学习表征,而且还将该表征与语言联系起来,从而实现灵活的零迁移。
2.1构建数据集
构建了一个新的数据集,其中包含4亿对(图像,文本)对,这些数据来自互联网上各种公开可用的资源。
2.2选择有效的预训练方法
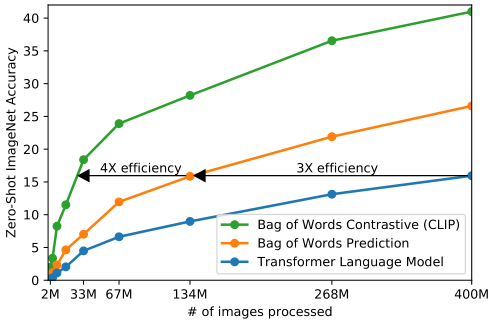
一开始作者选用了VirTex的方法,图像用CNN,文本用transformer来进行,CNN用来预测图像对应的文本,但是由于一个图像对应的描述实在是太多了,所以这样预训练的效果很差,于是作者决定用对比学习的方法来进行预训练。
从上图我们可以发现,蓝色的线是类似gpt的方法,基于transformer去做预测性的任务,逐字逐句的去预测文本。橘黄色的线是去预测已经全局化抽象成特征的文本(bag of words prediction)。可以发现训练效率提高了三倍。绿色的线是用对比学习的方法来判断图像和文本是否配对,这样效率是最高的。

上图是CLIP训练的一个伪代码。首先是两个编码器,用来对图像和文本进行编码。图像的编码器可以用ResNet或者ViT,文本的编码器可以用CBOW和Text Transformer。然后对提取的两个特征归一化并求一个余弦相似度,然后做一个交叉熵的损失函数来预训练网络。