大数据平台/大数据技术与原理-实验报告--部署全分布模式Hadoop集群
| 实验名称 | 部署全分布模式Hadoop集群 | ||
| 实验性质 (必修、选修) | 必修 | 实验类型(验证、设计、创新、综合) | 综合 |
| 实验课时 | 2 | 实验日期 | 2023.10.16-2023.10.20 |
| 实验仪器设备以及实验软硬件要求 | 专业实验室(配有centos7.5系统的linux虚拟机三台) | ||
| 实验目的 | 1. 熟练掌握Linux基本命令。 2. 掌握静态IP地址的配置、主机名和域名映射的修改。 3. 掌握Linux环境下Java的安装、环境变量的配置、Java基本命令的使用。 4. 理解为何需要配置SSH免密登录,掌握Linux环境下SSH的安装、免密登录的配置。 5. 熟练掌握在Linux环境下如何部署全分布模式Hadoop集群。 | ||
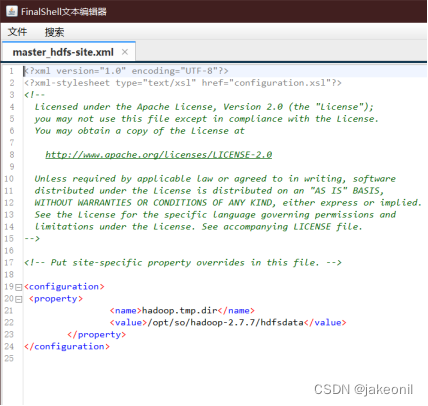
| 实验内容(实验原理、运用的理论知识、算法、程序、步骤和方法) 一:实验原理 1. Linux基本命令 - Linux是一个免费使用和自由传播的类Unix操作系统,支持多用户、多任务、多线程和多CPU。 - Linux基本命令包括查看当前目录(pwd)、切换目录(cd)、罗列文件(ls)、创建目录(mkdir)、拷贝文件(cp)、移动或重命名文件(mv)、删除文件(rm)、查看进程(ps)、压缩与解压文件(tar)、查看文件内容(cat)、查看机器IP配置(ip address)等。 2. vim编辑器 - vim是一个功能强大、高度可定制的文本编辑器,是vi的加强版,支持命令模式、输入模式和末行模式。 - vi/vim的工作模式包括命令模式、输入模式和末行模式,用户可以在这些模式之间切换,执行相应的操作。 3. Java基本命令 - Java是一种跨平台的编程语言,Hadoop使用Java语言编写。 - Java基本命令包括查看Java版本(java -version)、查看当前所有Java进程(jps)、编译Java程序(javac)、运行Java程序(java)、打包Java程序为jar文件(jar)等。 4. SSH安全通信协议 - SSH(Secure Shell)是一种安全通信协议,用于远程管理其他机器,提供加密的网络数据传输。 - SSH使用非对称加密,包括服务端发送公钥、客户端利用公钥加密数据、服务端利用私钥解密验证等步骤。 - Hadoop主节点到各个从节点的SSH免密登录配置是为了方便管理整个集群。 5. Hadoop - Hadoop是一个分布式存储和计算的软件框架,具有高可用、弹性可扩展的特点,适合处理大规模数据。 - Hadoop包括分布式文件系统HDFS、统一资源管理和调度框架YARN、分布式计算框架MapReduce。 - Hadoop的运行环境需要配置操作系统(Linux)、Java环境、SSH。 - Hadoop运行模式包括单机模式、伪分布模式和全分布模式。 - Hadoop的生态系统涵盖了许多子系统,形成了一个庞大的体系。 - Hadoop集群采用主从架构,包括Master(NameNode、ResourceManager)和Slave(DataNode、NodeManager)。 - Hadoop的主要配置文件包括hadoop-env.sh、yarn-env.sh、mapred-env.sh、core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml等。 二:实验步骤 这里直接从hadoop的安装和jdk安装,环境配置讲起: 1.Hadoop解压后的文件目录:
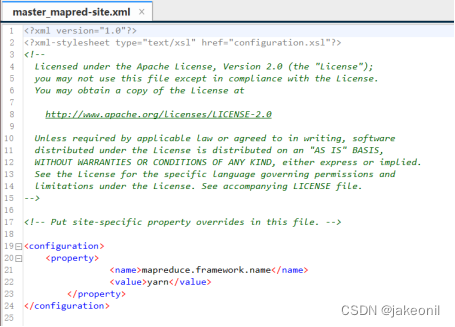
2.Jdk的解压文件目录: 3.修改的环境变量的文件: 此时在master节点上修改好hadoop的配置文件: 4.配置core-site.xml: 5.配置mapred-env.sh: 6.配置hdfs-site.xml:
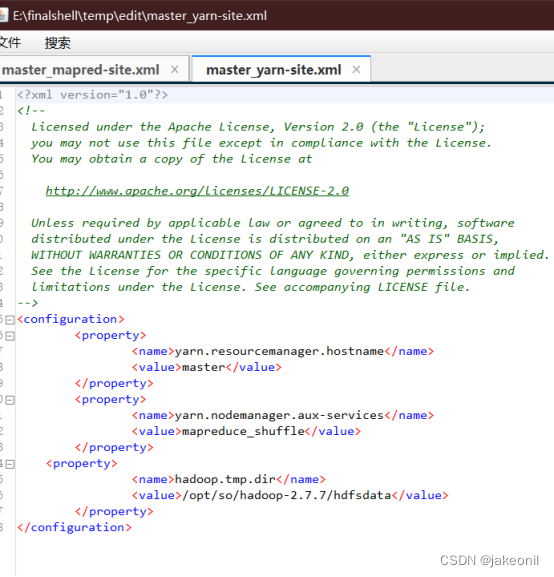
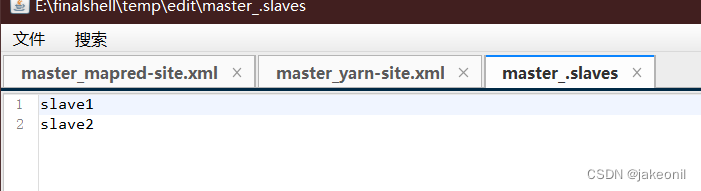
7.配置mapred-site.xml: 8.配置yarn-site.xml: 9.配置文件slaves:
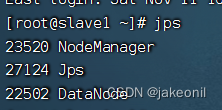
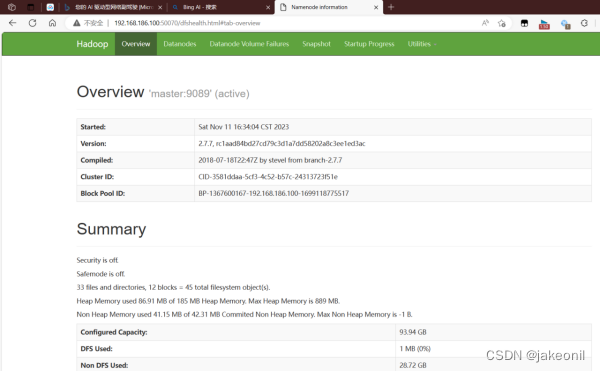
start-dfs.sh start-yarn.sh mr-jobhistory-daemon.sh start historyserver 启动结果如下图所示: start-dfs.sh start-yarn.sh 此时使用jps查看各个节点端口的启用情况: 主节点: 从节点: mr-jobhistory-daemon.sh start historyserver 此时就可以进入hadoop的webui的界面了: | |||
| 实验结果与分析 部署全分布模式Hadoop集群的实验结果与分析主要包括以下几个步骤: 1.网络和节点规划:首先,我们需要规划网络和节点。例如,我们可以为主节点和从节点分配不同的IP地址。 2.环境准备:这包括克隆虚拟机,网络配置,修改主机名,配置网络映射等。 3.设置SSH无密码登录节点:这是为了确保主节点可以无密码登录到所有从节点。 4.安装配置Hadoop集群:这包括配置Java、Hadoop的环境变量,配置分布式集群环境(6个配置文件),分发Hadoop集群安装目录及文件,启动和停止Hadoop集群等。 5.时间同步:安装NTP服务器,配置其他机器的时间同步。 这个过程可能会遇到一些问题,但通过不断的实践和调整,我们可以逐步优化集群的性能。 总的来说,部署全分布模式Hadoop集群是一个复杂的过程,需要对Hadoop和相关技术有深入的理解。但是,一旦集群部署成功,它将为处理大规模数据提供强大的计算能力。 | |||