rdf-file:分布式环境下的文件处理
一:数据量大了以后,单机解析或者生成文件的效率就很低,需要通过集群处理
- 机构过来的文件:我们先对文件进行分片,在利用集群集群处理分片文件。
- 给机构文件:分库分表数据,每个分表生成一个分片文件,最终合成一个完整文件。
二:分布式下文件处理需要分布式的文件存储
- 目前组件内部实现了NAS/OSS分布式的文件存储操作实现
文件大了单机处理就很慢, 数据库解决单机瓶颈方式是分库分表, 文件也一样需要将文件拆分,利用集群机器并发处理。
- 导入类文件一般会先对文件按大小切分,生成分片任务。
- 导出类文件一般会根据分库分表位,生成分片任务。
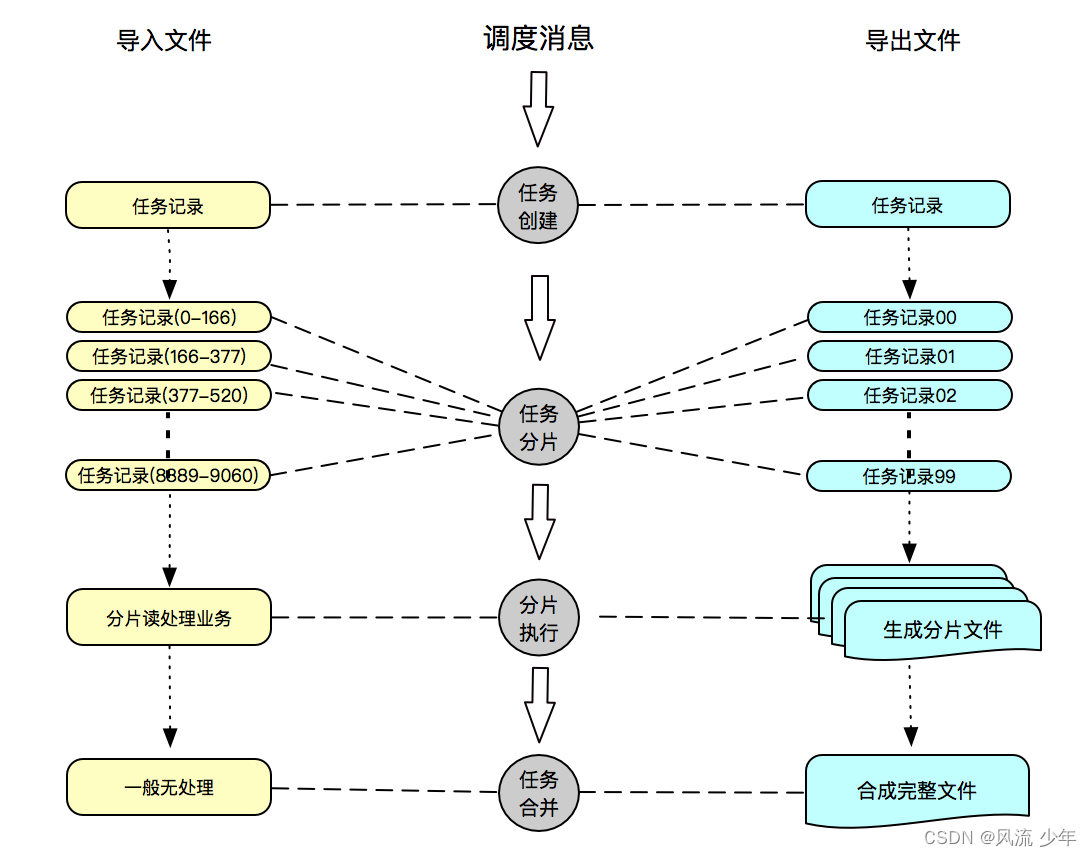
文件切分是指按大小将数据内容分片, 这里分片到行不会在行中间断开。
分布式环境一般处理流程
- 创建文件分片工具 FileSplitter splitter = FileFactory.createSplitter(config.getStorageConfig());
- 创建文件分片: (这里并没有真正对文件进行物理拆分)
FileSlice headSlice = splitter.getHeadSlice(config);
List slices = splitter.getBodySlices(config, 256);
FileSlice tailSlice = splitter.getTailSlice(config); - 将所有分片落成分片任务, 然后向集群分发分片任务
- 集群中机器拿到分片任务,根据分片数据范围处理数据