Python04 数据序列-字符串
Python04 数据序列-字符串
4.1 字符串概念
字符串是 Python 中最常用的数据类型。我们可以使用引号( ’ 或 " )来创建字符串。
格式:
变量名 = '数据' / "数据" / """ 数据 """
案例:
a = 'hello world'
b = "abcdefg"
c="""hello
你好
真棒
"""
三引号:
- 三引号形式的字符串支持换行。
- 自始至终保持一小块字符串的格式是所谓的 WYSIWYG(所见即所得)格式的。
4.2 字符串 输入 输出
- 字符串输入输出 请移步至 Python02 基础语法 的 输入输出
4.3 字符串中值的访问-详解
如果想直接使用定义好的字符串变量,那么可以直接使用变量名,比如:print(a)
如果需要用到具体的元素,那么需要用到下标
4.3.1 下标
“下标”又叫“索引”,就是编号。- 比如我们坐高铁时车票上的座位号,我们可以按照座位号快速找到对应的座位。
- 下标的作用就是通过下标能够快速找到对应的数据。

格式:
字符串[下标]
- 下标从 0 开始 依次递增
案例:取出 字符串 str 中的 每一个字符
str="abcd"
print(str[0])#a
print(str[1])#b
print(str[2])#c
print(str[3])#d
图示:
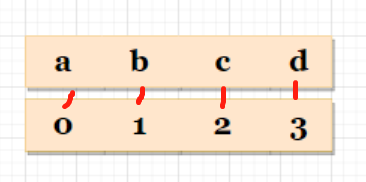
注意:
- 不要将最大下标 和 字符串 长度搞错
- 以刚才为例:最大下标=3 字符串长度=4
4.3.2 切片
切片就是截取 某一部分 字符
格式:
str[start,stop,step]]
字符串[开始,结束,步长]
案例:
str="abcd"
print(str[2:4:1]) # cd
print(str[2:4]) # cd
print(str[:5]) # abcd
print(str[1:]) # bcd
print(str[:]) # abcd
print(str[::2]) # ac
print(str[:-1]) # abc, -1:表示倒数第一个数据
print(str[-4:-1]) # abc
print(str[::-1]) # dcba
- 切片截取时不包含下标所对应的数据
- 下标正负数均可(-1表示从末尾开始)
- 步长正负数均可(正:从前往后 , 负:从后往前)
4.4 字符常见操作方法
字符串的常见从操作方法有:查找、修改、判断三种
4.4.1 查找
4.4.1.1 index()
index():检测某个子串是否在这个字符串中,如果在就返回这个子串开始的位置下标,否则则报异常。
格式:
字符串序列.index(子串[,start,end)//(字串,开始下标,结束下标)
开始和结束位置下标不写(省略),表示在整个字符串序列中查找
案例:
str="检测某个子串是否在这个字符串中,如果在就返回这个子串开始的位置下标,否则则报异常"
print(str.index('是否')) # 6
print(str.index('是否', 5, 30)) # 6
print(str.index('是否s')) # 报错
rindex():和index()功能相同,但查找方向为右侧开始。
4.4.1.2 find()
find():检测某个子串是否包含在这个字符串中,如果在就返回这个子串开始的位置下标,否则则返回-1。
格式:
字符串序列.find(子串[,start,end)//(字串,开始下标,结束下标)
开始和结束位置下标不写(省略),表示在整个字符串序列中查找
案例:
str="检测某个子串是否在这个字符串中,如果在就返回这个子串开始的位置下标,否则则报异常"
print(str.find('是否')) # 6
print(str.find('是否', 5, 30)) # 6
print(str.find('是否s')) # -1
rfind(): 和find()功能相同,但查找方向为右侧开始。
4.4.1.3 count()
count():统计某个子串在字符串中出现的次数
格式:
字符串序列.count(子串[,start,end)//(字串,开始下标,结束下标)
开始和结束位置下标不写(省略),表示在整个字符串序列中查找
案例:
str="检测某个子串是否在这个字符串中,如果在就返回这个子串开始的位置下标,否则则报异常"
print(str.count('是否')) # 1
print(str.count('是否', 5, 30)) # 1
print(str.count('是否s')) # -0
4.4.2 修改
修改字符串中的数据(字符串属于不可变数据类型,所以修改之后会返回新的数据,不会改变原始数据)
4.4.2.1 replace()
replace():替换原字符串中的数据
格式:
字符串序列.replace(old,new[,max])//(旧子串,新子串,最大替换次数)
开始和结束位置下标不写(省略),表示在整个字符串序列中查找
案例:
str="检测某个子串是否在这个字符串中,如果在就返回这个子串开始的位置下标,否则则报异常"
print(str.replace('是否',"奥里给")) # 替换 1 次
print(str.replace('是否', "奥里给",5)) # 替换 1 次
print(str) # 原始数据不变
- 最大替换次数如果不写,默认替换所有的旧字串
- 若旧字串< 指定的最大替换次数,默认替换所有的旧字串
4.4.2.2 split()
split():按照指定字符分割字符串
格式:
字符串序列.split(str="",num)//(str="分割的字符",分割 num 次)
num表示的是分割字符出现的次数,返回数据个数为num+1个
案例:
str="检测某个子串是否在这个字符串中,如果在就返回这个子串开始的位置下标,否则则报异常"
print(str.split('是否',))
print(str.split('是否',4))
分割字符若是原有字符串中的子串,分割后则丢失该子串

4.4.2.3 strip()
split():删除字符串两侧指定字符
格式:
字符串序列.split(str="")//(str="删除的字符")
split():若不跟参数,默认删除两次所有的空白字符
案例:
str=" 1 1检测某个子串是否在这个字符串中,如果在就返回这个子串开始的位置下标,否则则报异常 1 1 "print(str.strip())
print(str.strip("1"))
print(str.strip("1 1"))

- rstrip():删除字符串右侧指定字符。
- lstrip():删除字符串左侧指定字符。
4.4.2.4 字符大小写转换()
将字符串中的字符按照指定的要求进行转换
- capitalize():将字符串第一个字符转换成大写
- title():将字符串每个单词首字母转换成大写。
- lower():将字符串中大写转小写
- upper():将字符串中小写转大写
- swapcase():将字符串中大写转换为小写,小写转换为大写
案例:
str="hello world"
print(str.capitalize()) # Hello world
print(str.title()) # Hello World
print(str.lower()) # hello world
print(str.upper()) # HELLO WORLD
print(str.swapcase()) # HELLO WORLD
4.4.3 判断
判断字符是否满足要求,返回布尔类型结果(True | False)
4.4.3.1 判断开头结尾
- startswith():检查字符串是否是以指定子串开头,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查。
- endswith():检查字符串是否是以指定子串结尾,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查。
格式:
字符串序列.startswith(子串, 开始位置下标, 结束位置下标)
字符串序列.endswith(子串, 开始位置下标, 结束位置下标)
案例:
# 判断开头
str = "hello world"
print(str.startswith('hello')) # True
print(str.startswith('hello', 5, 10)) # False
# 判断结尾
print(str.endswith('world')) # True
print(str.endswith('world', 5, 10)) # False
4.4.3.2 判断包含字符情况
- isalpha():如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False
- isdigit():如果字符串只包含数字则返回 True 否则返回 False。
- isalnum():如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False。
- isspace():如果字符串中只包含空白,则返回 True,否则返回 False。
4.5 字符串内置函数
| 方法 | 参数 | 描述 |
|---|---|---|
| 关于字母的内置函数 | ||
| capitalize() | 无 | 将字符串的第一个字符转换为大写 |
| title() | NA | 单词都是以大写开始,其余字母均为小写 |
| upper() | NA | 转换字符串中的小写字母为大写 |
| swapcase() | NA | 将字符串中大写转换为小写,小写转换为大写 |
| max(str) | str – 字符串 | 方法返回字符串中最大的字母 |
| min(str) | str – 字符串 | 方法返回字符串中最小的字母 |
| 关于判断的内置函数 | ||
| isalnum() | 无 | 字符串中只有字母或数字则返 回 True,否则返回 False |
| isalpha() | 无 | 检测字符串是否只由字母组成。是则返回 True, 否则返回 False |
| isdigit() | 无 | 字符串是否只由数字组成,是则返回 True 否则返回 False。 |
| islower() | 无 | 检测字符串是否由小写字母组成,是则返回 True,否则返回 False |
| isnumeric() | 无 | 字符串是否只由数字组成。这种方法是只针对unicode对象。是返回 True, False |
| isdecimal() | 无 | 字符串是否只包含十进制字符。这种方法只存在于unicode对象.是返回 True, False |
| isspace() | 无 | 字符串是否只由空白字符组成。是返回 True, 否则False |
| istitle() | 无 | 检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写。是返回 True, 否则False |
| isupper() | 无 | 字符串中所有的字母是否都为大写 .是返回 True, 否则False |
| 替换 | ||
| replace(old, new[, max]) | old – 将被替换的子字符串。new – 新字符串,用于替换old子字符串。max – 可选字符串, 替换不超过 max 次 | 把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。 |
| expandtabs(tabsize=8) | tabsize – 指定转换字符串中的 tab 符号(’\t’)转为空格的字符数。 | 把字符串中的 tab 符号(’\t’)转为空格,tab 符号(’\t’)默认的空格数是 8。 |
| maketrans(intab, outtab) | intab – 字符串中要替代的字符组成的字符串。outtab – 相应的映射字符的字符串。 | 用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。两个字符串的长度必须相同,为一一对应的关系。 |
| 位置对齐 | ||
| zfill(width) | width – 指定字符串的长度。原字符串右对齐,前面填充0。 | 返回指定长度的字符串,原字符串右对齐,前面填充0。 |
| rjust(width[, fillchar]) | 1.width – 指定填充指定字符后中字符串的总长度.2.fillchar – 填充的字符,默认为空格。返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。 | |
| center(width[, fillchar]) | width – 字符串的总宽度。fillchar – 填充字符。 | 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| ljust(width[, fillchar]) | width – 指定字符串长度。fillchar – 填充字符,默认为空格。 | 返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。 |
| 检查查找 | ||
| startswith(substr, beg=0,end=len(string)) | str – 检测的字符串。substr – 指定的子字符串。strbeg – 可选参数用于设置字符串检测的起始位置。strend – 可选参数用于设置字符串检测的结束位置。 | 用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。 |
| endswith(suffix[, start[, end]]) | suffix – 该参数可以是一个字符串或者是一个元素。start – 字符串中的开始位置。end – 字符中结束位置。 | 用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回 True,否则返回 False。可选参数 “start” 与 “end” 为检索字符串的开始与结束位置。 |
| find(str, beg=0, end=len(string)) | str – 指定检索的字符串beg – 开始索引,默认为0。end – 结束索引,默认为字符串的长度 | 检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。 |
| rfind(str, beg=0 end=len(string)) | str – 查找的字符串beg – 开始查找的位置,默认为0end – 结束查找位置,默认为字符串的长度。 | 返回字符串最后一次出现的位置,如果没有匹配项则返回-1 |
| index(str, beg=0, end=len(string)) | str – 指定检索的字符串beg – 开始索引,默认为0。end – 结束索引,默认为字符串的长度。 | 检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。 |
| rindex(str, beg=0 end=len(string)) | str – 查找的字符串beg – 开始查找的位置,默认为0end – 结束查找位置,默认为字符串的长度。 | 返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常,你可以指定可选参数[beg:end]设置查找的区间。 |
| 删除 | ||
| rstrip([chars]) | chars – 指定删除的字符(默认为空格) | 删除 string 字符串末尾的指定字符(默认为空格) |
| lstrip([chars]) | chars – 指定删除的字符(默认为空格) | 删除 string 字符串开头的指定字符(默认为空格) |
| strip([chars]) | chars – 移除字符串头尾指定的字符序列。 | 用于移除字符串头尾指定的字符(默认为空格)或字符序列。 |
| 拼接 | ||
| join(sequence) | sequence – 要连接的元素序列。 | 用于将序列中的元素以指定的字符连接生成一个新的字符串。 |
| 分割 | ||
| split(str=“”, num=string.count(str)) | 1.str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。2.num – 分割次数。默认为 -1, 即分隔所有。 | 通过指定分隔符对字符串进行切片,如果第二个参数 num 有指定值,则分割为 num+1 个子字符串。 |
| 返回元素列表 | ||
| splitlines([keepends]) | keepends – 在输出结果里是否去掉换行符(’\r’, ‘\r\n’, \n’),默认为 False,不包含换行符,如果为 True,则保留换行符。 | 按照行(’\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 计算数量 | ||
| count(sub, start= 0,end=len(string)) | sub – 搜索的子字符串start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。 | 用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。 |
| len( s ) | s – 对象。 | 返回对象(字符、列表、元组等)长度或项目个数。 |
| 过滤 | ||
| 1.translate(table) 2.bytes.translate(table[, delete]) 3.bytearray.translate(table[, delete]) | table – 翻译表,翻译表是通过 maketrans() 方法转换而来。 deletechars – 字符串中要过滤的字符列表。 | 根据参数table给出的表(包含 256 个字符)转换字符串的字符,要过滤掉的字符放到 deletechars 参数中。 |
| 编码解码 | ||
| bytes.decode(encoding=“utf-8”, errors=“strict”) | encoding – 要使用的编码,如"UTF-8"。errors – 设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个UnicodeError。 其他可能得值有 ‘ignore’, ‘replace’,‘xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。 | 以指定的编码格式解码 bytes 对象。默认编码为 ‘utf-8’。 |
| encode(encoding=‘UTF-8’,errors=‘strict’) | encoding – 要使用的编码,如: UTF-8。errors – 设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个UnicodeError。 其他可能得值有 ‘ignore’, ‘replace’,‘xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。 | 以指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案。 |
4.6 练习
"""
1. 将字符串 "abcd" 转成大写
2. 计算字符串 "cd" 在 字符串 "abcd"中出现的位置
3. 字符串 "a,b,c,d" ,请用逗号分割字符串,分割后的结果是什么类型的?
4. "{name}喜欢{fruit}".format(name="李雷") 执行会出错,请修改代码让其正确执行
5. string = "Python is good", 请将字符串里的Python替换成 python,并输出替换后的结果
6. 有一个字符串 string = "python修炼第一期.html",请写程序从这个字符串里获得.html前面的部分,要用尽可能多的方式来做这个事情
7. 如何获取字符串的长度?
8. "this is a book",请将字符串里的book替换成apple
9. "this is a book", 请用程序判断该字符串是否以this开头
10. "this is a book", 请用程序判断该字符串是否以apple结尾
11. "This IS a book", 请将字符串里的大写字符转成小写字符
12. "This IS a book", 请将字符串里的小写字符,转成大写字符
13. "this is a book\n", 字符串的末尾有一个回车符,请将其删除
14. 判断用户输入的变量名是否合法(是否符合标识符命名规则)
15. 判断用户输入的内容是否存在敏感词汇,如果存在,将其替换成"*" (哪些是敏感词汇请自己定义)
16. 模拟文件下载的进度条
"""

"""
17. 模拟 简易掌上银行操作系统
普通用户
1. 用户注册(需要判断个人是否已经注册过)
1.1. 如果已经注册过,那么就不能再次注册,但是可以选择找回密码
1.2. 找回密码:(先验证自己之前所预留的手机号码),
比如:请输入之前预留号码的隐藏数字:1534079****
如果输入正确,那么随机产生一个临时密码,用于登录,登录之后可以修改密码
2. 用户登录
2.1 判断用户名和密码是否正确(可以选择忘记密码,选择找回密码,和上面注册找回密码同理)
2.2 登录之后可选功能
2.2.1 查看、修改、删除某部分自己的个人信息
2.2.2 查看账户余额
2.2.3 余额充值
2.2.4 取出余额
2.2.5 为另一位用户转账
管理员(用户:root ,密码:root)
1.登录
2.查询所有用户信息(现阶段只考虑一个用户,上面那一个普通用户)
3.锁定账户
4.解锁账户
5.退出
"""