深度强化学习(Double DQN)
一、先回顾一下Deep Q Networks
其主要的三部分
1.深度神经网络的应用
DQN是一个多层神经网络,它接收状态(state)作为输入,并输出该状态下各个动作的价值估计。这里的状态空间是n维的,动作空间包含m个动作,神经网络从映射到。这意味着对于每一个可能的状态,DQN都会给出每一个可能动作的预期回报值。
2.目标网络(Target Network)
DQN算法的一个重要组成部分是目标网络,其参数用θ−表示。目标网络与在线网络(即主网络)结构相同,但是其参数是周期性从在线网络复制过来的。这种机制有助于稳定学习过程,因为它减少了目标值在学习过程中的波动。
3.经验回放(Experience Replay)
DQN还使用了经验回放机制。在这种机制中,观察到的状态转换(transitions)被存储一段时间,并从这个存储库中随机采样来更新网络。这有助于打破连续样本间的相关性,提高学习过程的稳定性和效率。
二、Double Q-learning
Double Q-learning 的核心思想是将动作的选择和评估分离。在标准Q学习和DQN中,使用同一组值(θ)来选择和评估动作,这增加了选择过估计值的可能性,从而导致过度乐观的价值估计。为了防止这种情况,Double Q-learning 引入了两套权重(θ)来学习两个不同的价值函数,分别用于动作的选择和评估。
具体来说,在Double Q-learning中,每次经验更新时,随机选择一个价值函数进行更新。对于每次更新,其中一套权重用于确定贪婪策略(即选择最优动作),而另一套权重用于评估该策略的价值。通过这种方式,可以有效地减少动作值的过度估计。
三、Overoptimism due to estimation errors
这一块有理论证明,大家感兴趣的话可以看看附录,我就结合自身以往的经验重点介绍一下为什么会出现overestimate这种情况吧。我认为主要有三个方面
最大化偏差
在Q学习算法中,更新规则包括一个最大化步骤,即选择所有可能动作中具有最高估计值的动作。由于这些估计值是基于有限的数据和可能的不完全准确的学习模型得出的,因此容易出现过估计。在更新过程中,算法倾向于选择那些偶然被高估的值,导致这种高估随着时间积累。
函数逼近误差
在使用深度学习或其他函数逼近方法时,由于模型的泛化,对不经常遇到的状态-动作对的估计可能不准确。这种逼近误差可以导致某些状态或动作的价值被高估。
探索与利用的平衡
在强化学习中,算法需要在探索(尝试新动作)和利用(使用已知的最佳动作)之间取得平衡。在过度侧重于利用已知信息的情况下,算法可能会重复选择过去估计值较高的动作,即使这些估计并不准确,从而加剧了过度估计的问题。
这样说大家没感觉,我举一个例子:
| 假设我们有一个在线视频游戏平台,该平台使用强化学习算法来推荐游戏给用户。推荐系统的目标是增加用户的参与度,比如通过推荐那些用户可能会喜欢并玩得更长时间的游戏。 使用DQN就会出现一个问题 传统DQN可能会过度估计某些游戏的吸引力。例如,如果一款新游戏刚推出时吸引了大量点击,DQN可能会认为这款游戏对所有用户都具有很高的长期价值。这可能导致系统重复推荐这款游戏,即使其他游戏可能更适合某些用户。 |
四、Double DQN
正是由于上面DQN的缺点,所以引出了Double DQN,它的核心思想如下
1.减少过度估计
Double Q-learning的基本理念是通过分解目标中的最大操作(max operation)来减少过度估计。这一操作涉及动作选择和动作评估的分离。
2.利用现有的DQN架构
尽管没有完全解耦,DQN架构中的目标网络(target network)提供了第二个价值函数的自然候选项,无需引入额外的网络。因此,Double DQN提出使用在线网络(online network)来评估贪婪策略,但使用目标网络来估计其价值
3.更新规则
Double DQN的更新规则与DQN相同,但它用Double DQN的目标替换了DQN 的目标 。
4.目标网络的更新
目标网络的更新规则与DQN中的相同,依然是定期从在线网络复制权重
五、从公式的角度解释一下DQN和Double DQN的不同
DQN的公式:
的目标值是基于贝尔曼方程,其公式如下:
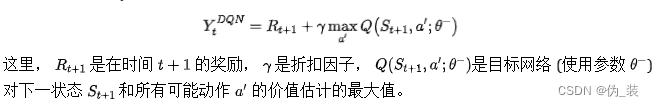
Double DQN的公式:
Double DQN的目标值 也是基于贝尔曼方程,但在计算最大化的动作值时采取了分离策略,其公式如下:

区别:
在DQN中,动作值的选择和评估都是由同一个网络(目标网络)完成的。而在Double DQN中,动作选择由在线网络执行,而动作值的评估则由目标网络执行。这种分离策略旨在减少估计值的过度乐观偏差。