Python自动化办公:PDF文件的分割与合并
我们平时办公中,可能需要对pdf进行合并或者分割,但奈何没有可以白嫖的工具,此时python就是一个万能工具库。
其中PyPDF2是一个用于处理PDF文件的Python库,它提供了分割和合并PDF文件的功能。
在本篇博客中,我们将详细介绍如何使用PyPDF2库对PDF文件进行分割和合并,并通过案例进行演示。
1. 安装PyPDF2库
首先,确保你已经安装了PyPDF2库。如果没有安装,可以使用以下命令进行安装:
pip install PyPDF2
2. 分割PDF文件
案例演示:将一个PDF文件分割成多个文件
import PyPDF2
def split_pdf(input_pdf, output_prefix):
# 打开PDF文件
with open(input_pdf, 'rb') as file:
# 创建PDF阅读器对象
pdf_reader = PyPDF2.PdfReader(file)
# 遍历每一页
for page_num in range(len(pdf_reader.pages)):
# 创建新的PDF写入对象
pdf_writer = PyPDF2.PdfWriter()
# 添加当前页到新的PDF对象中
pdf_writer.add_page(pdf_reader.pages[page_num])
# 构建输出文件名
output_file = f"{output_prefix}_page_{page_num + 1}.pdf"
# 写入新的PDF文件
with open(output_file, 'wb') as output:
pdf_writer.write(output)
# 使用示例
split_pdf('input.pdf', 'output_split')
在这个示例中,我们定义了一个split_pdf函数,该函数接受一个输入PDF文件和输出文件的前缀,并将输入的PDF文件分割成多个文件,每个文件包含一页。你可以根据需要修改输入文件和输出前缀。
可以看到运行代码后,会生成分割后的pdf文件
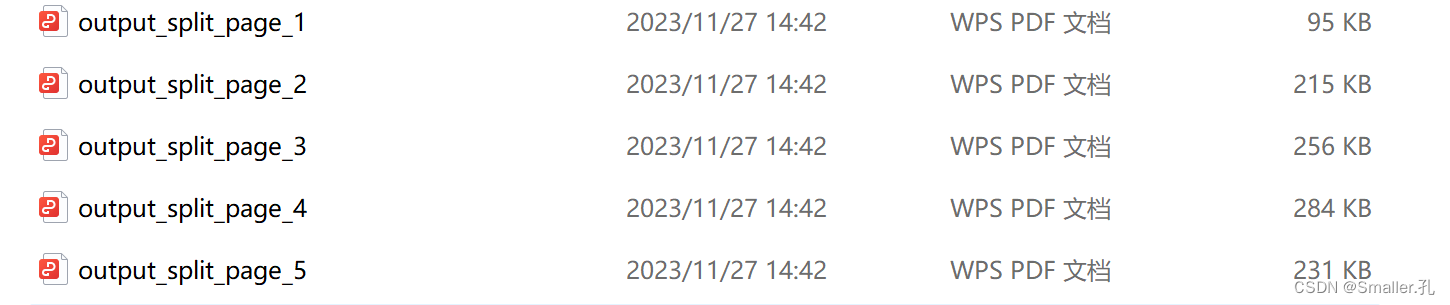
3. 合并PDF文件
案例演示:将多个PDF文件合并成一个文件
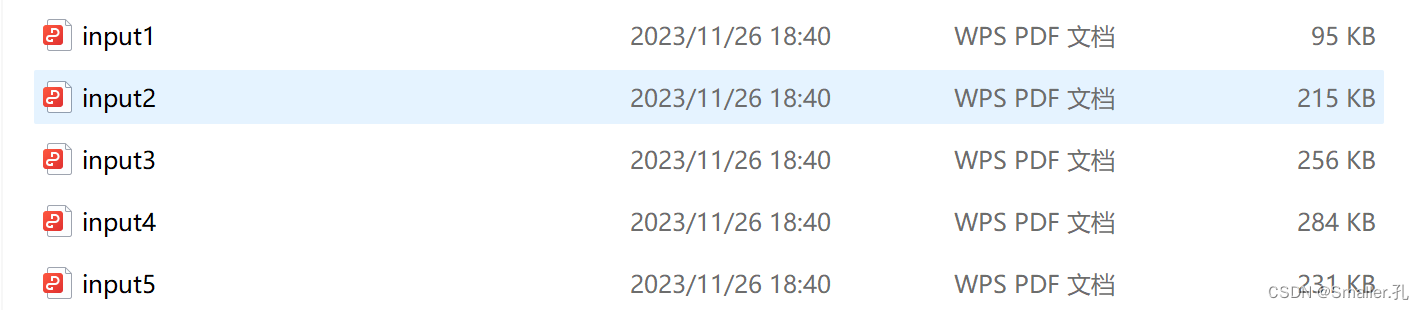
import PyPDF2
def merge_pdfs(input_pdfs, output_pdf):
# 创建PDF写入对象
pdf_writer = PyPDF2.PdfWriter()
# 遍历每个输入PDF文件
for input_pdf in input_pdfs:
# 打开当前输入PDF文件
with open(input_pdf, 'rb') as file:
# 创建PDF阅读器对象
pdf_reader = PyPDF2.PdfReader(file)
# 遍历每一页并添加到写入对象中
for page_num in range(len(pdf_reader.pages)):
pdf_writer.add_page(pdf_reader.pages[page_num])
# 写入合并后的PDF文件
with open(output_pdf, 'wb') as output:
pdf_writer.write(output)
# 使用示例
merge_pdfs(['input1.pdf', 'input2.pdf', 'input3.pdf', 'input4.pdf', 'input5.pdf'], 'output_merge.pdf')
在这个示例中,我们定义了一个merge_pdfs函数,该函数接受多个输入PDF文件和一个输出PDF文件,并将输入的多个PDF文件合并成一个文件。你可以根据需要修改输入文件和输出文件。

通过这些示例,你可以了解如何使用PyPDF2库对PDF文件进行分割和合并。