CPU、GPU、TPU内存子系统架构
文章目录
- CPU、GPU、TPU内存子系统架构
- 概要
- CPU
- GPU
- TPU
- 共同点和差异:
CPU、GPU、TPU内存子系统架构
概要
Memory Subsystem Architecture,图源自TVM
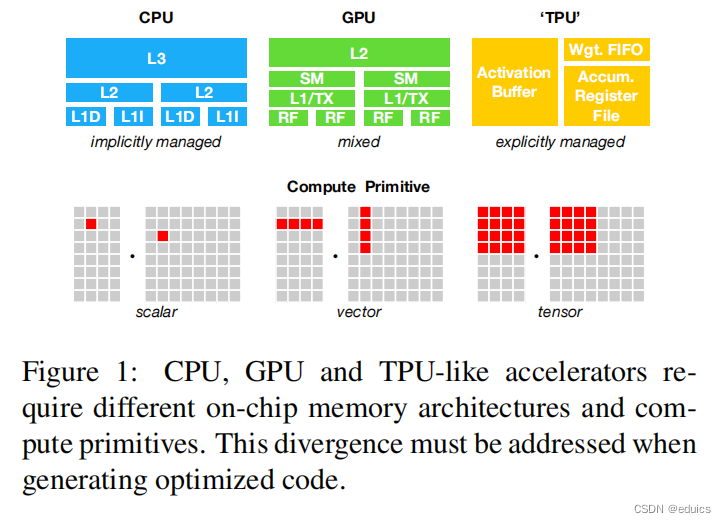
CPU
CPU(中央处理器)的内存子系统:隐式管理
主内存(RAM): CPU通常与主内存进行直接交互,主内存是用于存储程序和数据的地方。CPU通过内存总线访问主内存,用于执行计算任务和存储程序的指令。缓存: CPU还包括多级缓存(L1、L2、L3),这是一种速度更快但容量较小的存储,用于缓存最常用的数据和指令,以提高访问速度。- L1分为L1D与L1I:
在CPU的内存体系结构中,L1D(Level 1 Data Cache)和L1I(Level 1 Instruction Cache)是两个不同类型的缓存,分别用于存储数据和指令。
L1D(Level 1 Data Cache):
作用: L1D缓存用于存储处理器执行过程中使用的数据。这包括从主存中读取的数据以及处理器计算过程中生成的中间结果。L1D缓存的目标是提供对数据的快速访问,以减少因为等待主存数据而引起的计算延迟。
特点: L1D通常是双口(读写同时)的,具有较小的容量但具有很高的访问速度。由于它离处理器核心非常近,可以在一个时钟周期内响应访问请求。
L1I(Level 1 Instruction Cache):
作用: L1I缓存用于存储处理器执行的指令。指令是由处理器执行的操作的二进制表示形式。通过将指令缓存在L1I中,可以更快速地提供给处理器核心,减少从主存中获取指令的时间。
特点: 类似于L1D,L1I也是双口的,但它存储指令而不是数据。L1I通常具有相对较小但非常快速的访问时间,以确保指令的快速提供。
这两个缓存层级(L1D和L1I)都位于处理器核心内部,离核心非常近,以便最小化访问延迟。当处理器执行指令时,首先从L1I缓存中获取指令,然后执行这些指令并在L1D中存储或检索相关的数据。如果在L1缓存中未找到所需的数据或指令,处理器将继续查找更高层级的缓存(如L2、L3缓存)或主内存。
GPU
GPU(图形处理器)的内存子系统:混合管理
全局内存:GPU拥有自己的全局内存,用于存储大量的数据,例如图形、纹理和模型数据。全局内存对于大规模并行计算非常重要,但与主内存相比,它通常具有更高的延迟。共享内存:在GPU中,共享内存是一种高速且共享给同一个工作组(通常是一个线程块)中的线程使用的内存。这种内存形式用于在工作组内进行通信和数据交换。纹理内存:用于存储和处理图形数据的特殊内存。纹理内存通常用于图形渲染,但在深度学习等领域也可以用于特殊用途。
GPU(图形处理器)内部,有一些关键的组成部分和缓存层次,其中一些常见的术语包括:
RF(Register File):
作用: 寄存器文件是GPU中用于存储临时数据和中间结果的地方。GPU中的线程(也称为CUDA核心或着色器)在执行计算时使用寄存器进行临时存储,而RF就是这些寄存器的组织结构。
特点: RF非常快速,但容量有限。它用于存储当前线程的局部变量和中间计算结果。L1 Cache / Texture Cache (L1/TC):
L1 Cache(数据缓存):用于存储处理器核心正在访问的数据。这包括从全局内存读取的数据,以及线程间共享的数据。L1 Cache可以被分为L1D(数据缓存)和L1I(指令缓存)。
Texture Cache(纹理缓存):专门用于处理图形处理中的纹理贴图数据,提供对纹理数据的快速访问。纹理缓存通常用于图形渲染中的纹理映射。SM(Streaming Multiprocessor):
作用: SM是GPU中的一个处理单元,用于执行并行计算任务。每个SM包含多个CUDA核心,可以同时执行多个线程。
特点: SM具有自己的寄存器文件(RF)、共享内存、L1 Cache等资源。多个SM并行工作以实现高度并行的计算。L2 Cache(Level 2 Cache):
作用: L2缓存是GPU中的更大容量、相对较慢但仍然很快的缓存层。它用于存储全局内存的数据,以及L1 Cache之间的数据传输。
特点: L2 Cache能够缓存更多的数据,并提供更大的访问带宽,以支持更高效的数据共享和传输。
这些组成部分在GPU中协同工作,以支持大规模的并行计算,特别是在图形渲染和通用计算任务中。不同的GPU架构和制造商可能有不同的设计和术语,上述描述主要适用于NVIDIA的CUDA架构。
关于GPU架构请参考我的另外一篇文章:
https://blog.csdn.net/qq_47564006/article/details/134579941
TPU
TPU(张量处理单元)的内存子系统:显示管理
高带宽存储(HBM):TPU通常使用高带宽存储,这是一种高速、低延迟的内存,专门设计用于存储大规模的张量数据。这对于深度学习等涉及大量矩阵和张量运算的任务非常重要。缓存:TPU可能还包含一些缓存,用于存储和加速对常用数据的访问。
在谷歌的Tensor Processing Unit(TPU)中,存在一些特定的组成部分和缓存结构,其中包括 Activation Buffer、Weight FIFO(First-In, First-Out)以及 Accumulator Register File。以下是对这些组成部分的简要说明:
Activation Buffer:
作用: Activation Buffer 用于存储神经网络中的激活值(activation values)。激活值是神经网络中每个神经元的输出,是神经网络前向传播的结果。
特点: Activation Buffer 提供了一个快速的临时存储区域,以存储当前层的激活值。这有助于提高处理速度,因为激活值通常在神经网络的不同层之间传递,而无需每次都访问主存。
Weight FIFO(Wgt.FIFO):
作用: Weight FIFO 用于存储神经网络中的权重(weights)。权重是神经网络中连接两个神经元之间的参数,它们在神经网络的训练过程中被学习。
特点: Weight FIFO 提供了一个先进先出的缓冲区,用于暂存权重。这有助于提供对权重的快速访问,以支持神经网络的前向和反向传播。
Accumulator Register File:
作用: Accumulator Register File 用于存储神经网络中的累加器值。在神经网络的计算过程中,累加器用于累积加权和,计算神经元的输出。
特点: Accumulator Register File 提供了一个用于临时存储累加器值的区域,以支持神经网络的前向和反向传播。这有助于加速计算过程。
这些组成部分共同协作,为TPU提供了对神经网络计算所需的各种参数和中间结果的高效访问。TPU旨在针对深度学习任务进行优化,因此这些缓存结构和寄存器文件等组件的设计都考虑了深度学习计算的特殊需求。
共同点和差异:
- 共同点: 所有这三种处理器都具有一些形式的缓存,用于加速对常用数据的访问。
- 差异: 不同之处在于主要设计目标和应用领域。CPU通常用于通用计算,GPU专注于图形处理和大规模并行计算,而TPU专门为深度学习任务设计,通过优化张量计算来提高性能。
总的来说,每种处理器的内存子系统都是根据其设计目标和应用领域进行了优化的,以最大限度地提高性能和效率。