2023年APMCM亚太杯数学建模竞赛C题思路解析
C 题: 中国新能源电动汽车的发展趋势
The Development Trend of New Energy Electric Vehicles in China
思路总览【请电脑打开本文链接,扫描下方名片中二维码,获取更多资料】

一、问题重述
新能源汽车指的是采用先进技术原理、新技术和新结构,以非常规车辆燃料作为动力源(非常规汽车燃料指的是除汽油和柴油之外的燃料),并整合车辆动力控制和驱动的先进技术的车辆。新能源汽车包括四种主要类型:混合动力汽车、纯电动汽车、燃料电池电动汽车和其他新能源汽车。作为新能源汽车的一种,新能源电动汽车由于其低污染、低能耗以及调节电力消耗峰值的能力等特性,近年来取得了快速发展。电动汽车包括电动公交车和座位少于7个的家用电动汽车,在全球范围内受到消费者和政府的青睐。
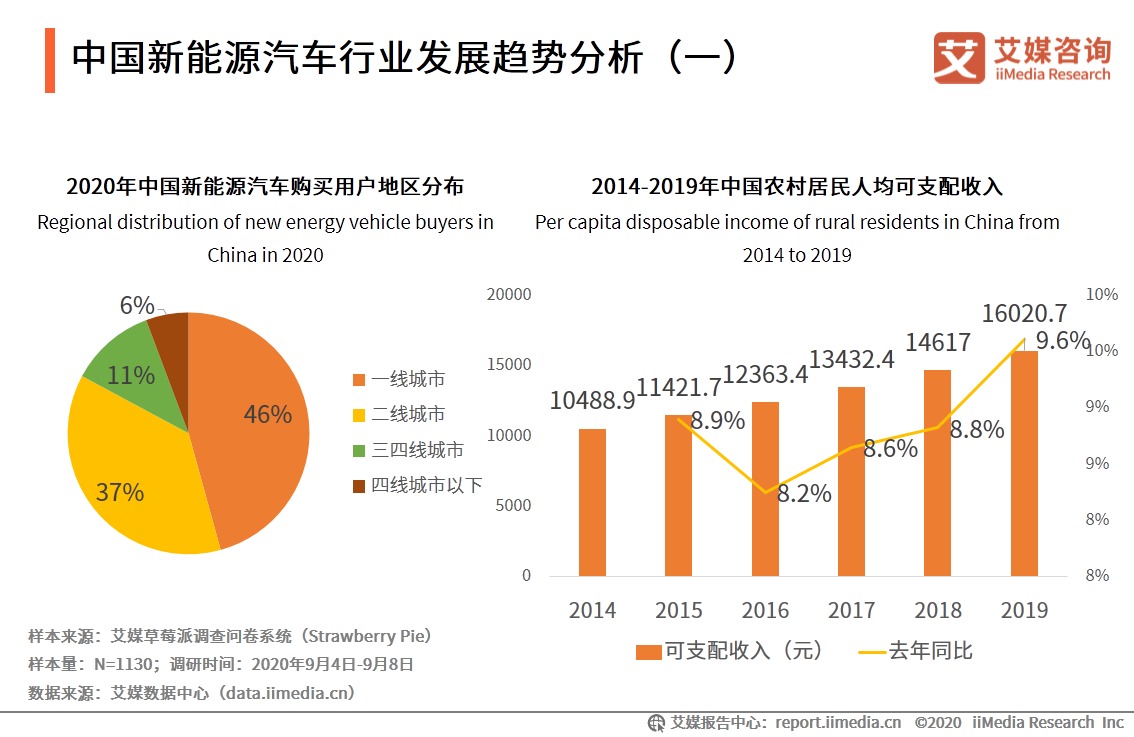
自2011年以来,中国政府积极推动新能源电动汽车的发展,并制定了一系列优惠政策。新能源电动汽车产业取得了巨大发展,逐渐成为继“中国高铁”之后的又一个中国象征。现在,您的团队被邀请完成以下问题:
**问题1:**分析影响中国新能源电动汽车发展的主要因素,建立数学模型,并描述这些因素对中国新能源电动汽车发展的影响。
**问题2:**收集中国新能源电动汽车的行业发展数据,建立数学模型描述并预测未来10年中国新能源电动汽车的发展。
**问题3:**收集数据,建立数学模型分析新能源电动汽车对全球传统能源汽车行业的影响。
**问题4:**一些国家制定了一系列旨在抵制中国新能源电动汽车发展的政策。建立数学模型分析这些政策对中国新能源电动汽车发展的影响。
**问题5:**分析城市新能源电动汽车电气化对生态环境的影响(包括电动公共汽车)。假设城市人口为100万,请提供模型的计算结果。
**问题6:**基于问题5的结论,向市民写一封公开信,宣传新能源电动汽车的好处以及世界各国电动汽车产业的贡献。
二、思路解析
问题一:影响中国新能源电动汽车发展的主要因素
**1、确定相关因素指标:**查找各种资料和参考文献,确定影响中国新能源电动汽车发展的主要因素,在这里给出几种可能影响的因素:
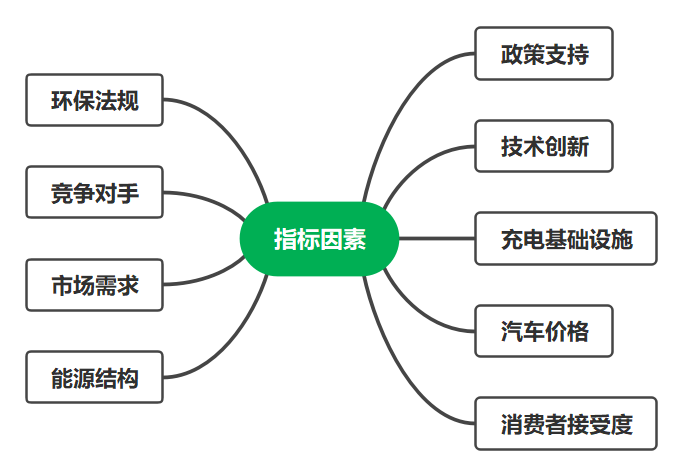
- 政策支持: 政府出台的支持新能源汽车发展的政策,包括购车补贴、免费停车、免费充电等。
- 技术创新: 新技术的引入和创新,如电池技术的改进、电动汽车的智能化和互联技术的应用。
- 充电基础设施: 充电桩的建设和分布,能否提供方便、高效的充电服务对电动汽车的普及具有重要影响。
- 汽车价格: 新能源汽车的价格相对传统汽车的竞争力,包括购车成本和使用成本。
- 消费者接受度: 消费者对新能源汽车的认知和接受程度,包括对电动汽车的认同、使用体验和信任度。
- 能源结构: 国家能源结构的变化,包括可再生能源的比例和煤炭等传统能源的减少,对新能源汽车的发展也有直接影响。
- 市场需求: 对新能源汽车的市场需求,包括城市化程度、交通拥堵状况和环境意识。
- 竞争对手: 其他汽车制造商的参与和竞争,以及它们对新能源汽车技术和市场的影响。
- 环保法规: 对尾气排放的限制和环保法规的加强,可能促使企业和个人更倾向于选择新能源汽车。
2、数据收集和预处理:问题一属于数据分析题,由于本题没有提供数据集,因此需要自行搜集数据,数据无疑是本题的重要一环,具体来说就是根据上面确定的影响新能源发展的指标因素去搜集相关数据。
对于搜集好的数据文件,我们后期会统一打包发在【扣 君羊】里提供给大家去使用,大家可以持续关!
这里给出几个可以搜集数据的来源,我们建议论文中要标注出自己的数据来源,增加文章的可靠性:
① 政府部门和机构的官方报告和数据发布
- 国家统计局:提供有关汽车销量、产值、政策支持等方面的数据。
- 工信部:发布汽车产业发展报告、新能源汽车生产销售数据等。
- 发改委、能源局、交通运输部:发布有关新能源汽车政策、发展规划等方面的数据和文件。
② 行业协会和研究机构报告
- 中国汽车工业协会:发布汽车产业发展、销售数据等报告。
- 市场研究公司:如IDC、Gartner等发布关于新能源汽车市场趋势、预测等报告。
③ 在线数据库和网站
- 中国汽车产业信息网、能源汽车网等:提供有关汽车产业、新能源汽车的数据和行业动态。
- 政府官方网站:如各部委官网、国家统计局网站等发布的政策文件和数据。
④ 企业年报和财务报告
- 汽车制造商:通过各汽车制造商的年度报告、财务报告等获取有关新能源汽车产量、销量、市场份额、技术创新等方面的数据。
⑤ 国际组织和外部数据来源
- 国际能源署(IEA):提供有关全球能源和新能源汽车发展的数据和报告。
- 外部数据库:如World Bank、UNESCO等提供的有关能源、环境和交通领域的数据。
数据搜集完之后通常是不能够直接用的,需要进行数据预处理,包括:缺失值处理、异常值处理、数据清洗等,当然自己搜集到的数据集通常具有量纲的差距,需要进行归一化处理,标准化方法也有很多,这里就不一一列举了。
3、探究指标因素之间的相关性:首先使用相关性分析描述不同因素与新能源电动汽车发展之间的关联程度,最好贴一张相关性热力图,示例代码如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 假设 df 是包含各种因素和新能源电动汽车发展情况的数据框
df = pd.read_csv("your_dataset.csv")
# 选择要分析的变量
variables_to_analyze = ['PolicySupport', 'TechnologyInnovation', 'ChargingInfrastructure', 'CarPrice', 'ConsumerAcceptance']
# 计算相关系数矩阵
correlation_matrix = df[variables_to_analyze].corr()
# 绘制热图
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.show()
当然,如果您选择的指标量很多,相关性分析发现有较多指标之间存在较强的关联性,那可以考虑使用**主成分分析(PCA)**进行降维。
4、 建立数学建模:建立一个考虑各因素影响的综合评价模型,这里我们提供了一些模型可供大家选择,后续也会选择一个最合适的给出建模过程,发裙里给大家使用:
① 多元线性回归模型
- 模型类型:利用多元线性回归,探究不同因素对新能源电动汽车发展的影响程度。
- 步骤:确定自变量(如政策支持、技术进步、市场需求、充电设施等)和因变量(如电动汽车销量增长率),进行数据收集、变量筛选和模型拟合。
一个简单线性回归示例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
# 假设已有数据集,包含各种影响因素和新能源电动汽车发展情况的数据
# 在实际情况中,可能需要更复杂的数据处理和特征工程
data = pd.read_csv("your_dataset.csv")
# 划分特征和标签
X = data[['Factor1', 'Factor2', 'Factor3', ...]] # 选择适当的因素列
y = data['ElectricVehicleDevelopment']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 建立线性回归模型
model = LinearRegression()
# 模型训练
model.fit(X_train, y_train)
# 模型预测
y_pred = model.predict(X_test)
# 评估模型性能
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
# 输出模型系数
print('Coefficients:', model.coef_)
② 系统动力学模型
- 模型类型:系统动力学模型可以更好地描述复杂系统内在的动态变化和因果关系。
- 步骤:通过构建系统结构图,定义各个因素之间的关系,然后使用微分方程组或差分方程等描述系统动态变化,模拟新能源电动汽车发展的系统动态。
③ Logistic增长模型
- 模型类型:适用于描述增长达到饱和的情况,预测市场饱和度等情形。
- 步骤:将新能源电动汽车发展的增长趋势建模为S形曲线,考虑增长速率逐渐减缓至稳定状态。
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
# 假设的数据
years = np.array([2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019])
sales = np.array([500, 800, 1200, 2000, 3000, 4000, 5500, 6500, 7000, 7200])
# 定义Logistic函数模型
def logistic_model(x, a, b, c):
return c / (1 + np.exp(-(x - b) / a))
# 拟合Logistic模型
params, covariance = curve_fit(logistic_model, years, sales, maxfev=10000)
# 拟合后的参数
[a, b, c] = params
# 绘制拟合曲线
plt.figure(figsize=(8, 6))
plt.scatter(years, sales, label='实际数据')
plt.plot(years, logistic_model(years, a, b, c), label='Logistic增长模型拟合', color='red')
plt.title('新能源电动汽车销量的Logistic增长模型拟合')
plt.xlabel('年份')
plt.ylabel('销量')
plt.legend()
plt.grid(True)
plt.show()
print(f"模型参数 a: {a}, b: {b}, c: {c}")
④ 深度学习模型
- 模型类型:可以使用神经网络等深度学习方法处理复杂的非线性关系。
- 步骤:利用历史数据,通过深度学习模型学习各因素之间复杂的非线性关系,预测新能源电动汽车的发展趋势。
⑤ 时间序列模型
- 模型类型:适用于分析随时间变化的数据趋势。
- 步骤:收集历史数据,利用ARIMA(自回归移动平均模型)等时间序列方法,预测未来新能源电动汽车的发展趋势。
**5、 建模评估:**收集和整理相关的数据,以用于模型的训练和验证。确保数据的准确性和完整性。对模型进行评估,检查其对现有数据的拟合程度,并考虑使用验证数据进行验证。解释模型的结果,理解每个因素对新能源电动汽车发展的影响程度,最终给出影响因素。
问题二:预测中国新能源电动汽车未来10年的发展
**1、数据收集与预处理:**同问题一,我们后期会把搜集好的数据文件会统一打包发在【扣 君羊】里提供给大家去使用
2、探索性数据分析(EDA):对历史数据进行可视化分析,观察销售趋势、季节性变化、增长率等特征,这里要绘制出一些可视化图表,这里给出一些可绘制的图表类型,后续也会绘制好图表发裙里提供给大家:
① 直方图和密度图
直方图:展示数值型数据的分布情况。
密度图:更平滑地展示数据分布的趋势。
② 箱线图
显示数据的中位数、四分位数和异常值,有助于发现数据的离群点和分布范围。
③ 散点图
显示两个数值型变量之间的关系,有助于观察变量之间的相关性或趋势。
④ 折线图
展示数据随时间或其他连续变量的趋势,适用于展示时间序列数据或连续变量的变化。
⑤ 条形图和柱状图
条形图:展示类别型数据的频数或比例。
柱状图:通常用于比较不同类别之间的数值。
⑥ 饼图
展示类别型数据的占比情况,用于显示各类别在整体中的相对比例。
⑦ 热力图
用颜色来表示两个类别变量之间的关联程度或数值大小,特别适用于展示数据的相关性。
⑧ 地理空间图
展示地理位置相关的数据,可用于展示区域间的差异或分布情况。
**3、建立预测模型:**这里给出可供选择的预测模型,如下:
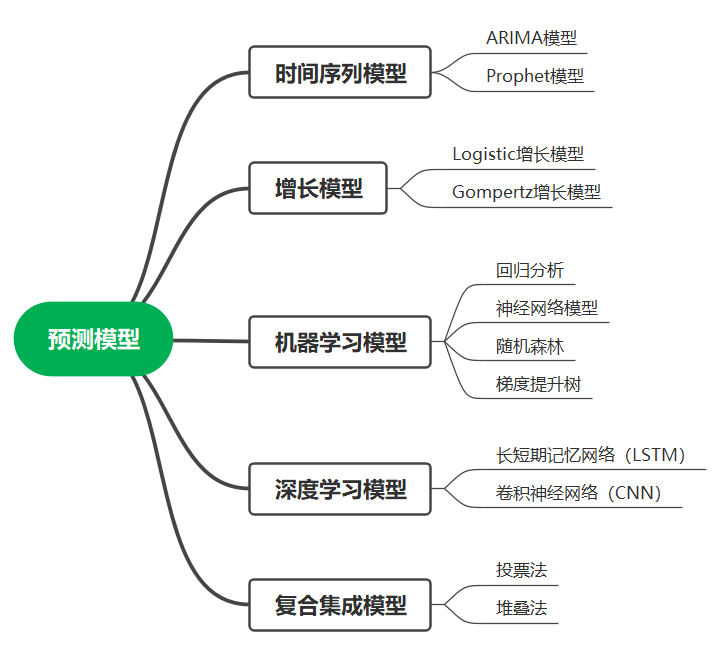
① 时间序列模型
- ARIMA模型(自回归滑动平均模型):适用于分析时间序列数据,能够捕捉趋势、季节性和周期性。
示例代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# 示例数据(假设的时间序列数据)
# 请替换为你自己的数据
data = [100, 120, 130, 145, 150, 165, 180, 190, 200, 210]
# 将数据转换为时间序列
date_range = pd.date_range(start='2022-01-01', periods=len(data), freq='M')
time_series = pd.Series(data, index=date_range)
# 绘制时间序列图
plt.figure(figsize=(10, 6))
plt.plot(time_series)
plt.title('新能源电动汽车销量时间序列')
plt.xlabel('时间')
plt.ylabel('销量')
plt.show()
# 绘制ACF和PACF图
plot_acf(time_series)
plot_pacf(time_series)
plt.show()
# 建立ARIMA模型
# 参数可根据ACF和PACF图进行选择
# 这里以ARIMA(1, 1, 1)为例
arima_model = ARIMA(time_series, order=(1, 1, 1))
arima_result = arima_model.fit()
# 打印模型的摘要信息
print(arima_result.summary())
# 进行未来10期的预测
forecast = arima_result.forecast(steps=10)
# 打印预测结果
print(f"未来10期的预测值:{forecast}")
- Prophet模型:由Facebook开发,处理具有季节性、节假日效应的时间序列数据。
② 增长模型
- Logistic增长模型:适用于描述增长达到饱和的情况,用于预测市场饱和度等情形。
- Gompertz增长模型:类似于Logistic模型,用于描述成长速度逐渐减缓的现象。
③ 机器学习模型
- 回归分析:使用线性回归或多项式回归分析变量之间的关系。
- 神经网络模型:如多层感知器(MLP)、循环神经网络(RNN)等,在处理复杂的非线性关系方面表现出色。
- 随机森林:结合多个决策树进行预测,适用于特征较多的情况。
- 梯度提升树:以集成多个弱分类器/回归器为基础,逐步改进模型的预测效果。
④ 深度学习模型
- 长短期记忆网络(LSTM):一种特殊的循环神经网络,能够学习长期依赖关系,适用于时间序列预测。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
# 示例数据(假设的时间序列数据)
# 请替换为你自己的数据
data = np.array([100, 120, 130, 145, 150, 165, 180, 190, 200, 210])
# 数据预处理
scaler = MinMaxScaler(feature_range=(0, 1))
data = scaler.fit_transform(data.reshape(-1, 1))
# 构建时间序列数据集
def create_dataset(data, time_steps=1):
X, y = [], []
for i in range(len(data) - time_steps):
X.append(data[i:(i + time_steps), 0])
y.append(data[i + time_steps, 0])
return np.array(X), np.array(y)
# 设置时间步长(根据需要调整)
time_steps = 3
X, y = create_dataset(data, time_steps)
# 转换为适用于LSTM的三维格式 [样本数, 时间步长, 特征数]
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
# 建立LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X.shape[1], 1)))
model.add(LSTM(units=50))
model.add(Dense(units=1))
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 拟合模型
model.fit(X, y, epochs=100, batch_size=1)
# 进行未来预测
future_steps = 5
future_input = data[-time_steps:].reshape(1, time_steps, 1)
future_predictions = []
for i in range(future_steps):
prediction = model.predict(future_input)[0, 0]
future_predictions.append(prediction)
future_input = np.append(future_input[:, 1:, :], [[prediction]], axis=1)
# 将预测结果反缩放到原始范围
future_predictions = scaler.inverse_transform(np.array(future_predictions).reshape(-1, 1))
# 打印未来预测结果
print(f"未来{future_steps}期的预测值:{future_predictions}")
- 卷积神经网络(CNN):在某些场景下也可用于时间序列数据分析。
⑤ 复合模型
- 模型集成:将多个不同模型的预测结果进行整合,如投票法、堆叠法(stacking)等。
**4、模型求解分析结果:**此处步骤写的极尽详细,大家不必完全按照这个步骤,可以省略其中几个步骤
- 数据拟合:利用选定的模型对历史数据进行拟合,确定模型的参数。
- 模型验证:使用历史数据中的一部分进行模型训练,然后使用保留的数据进行验证,评估模型的预测能力。
- 模型应用:将已验证的模型用于未来10年的预测。根据历史数据的走势和模型参数,对未来新能源电动汽车的销售量、市场份额等进行预测。
- 预测结果分析:分析预测结果的可信度和置信区间,评估模型的预测准确性,并提供相应的预测结果。
- 结果呈现:使用图表、数据报告等方式清晰地展示未来10年新能源电动汽车的发展趋势。
- 解释和讨论:对预测结果进行解释,说明影响因素、政策变化等对未来发展的影响,并提出可能的发展趋势及其背后的原因。
5、不确定性和风险分析
- 不确定性分析:考虑模型的不确定性,例如数据质量、模型假设、外部因素的变化等,这里推荐使用敏感性分析,并对未来预测的不确定性进行讨论。
- 风险评估:分析可能影响预测结果的风险因素,如经济波动、政策调整、技术突破等,并评估其对预测结果的潜在影响。
问题三:分析新能源电动汽车对全球传统能源汽车行业的影响
**1、数据收集和预处理:**同问题一,收集全球传统能源汽车销售、新能源电动汽车占比等数据。我们后期会把搜集好的数据文件会统一打包发在【扣 君羊】里提供给大家去使用
2、数学模型建立:建立数学模型,利用市场份额分析、对比数据、市场模拟等方法来评估新能源电动汽车对传统能源汽车产业的影响。推荐以下可选模型:
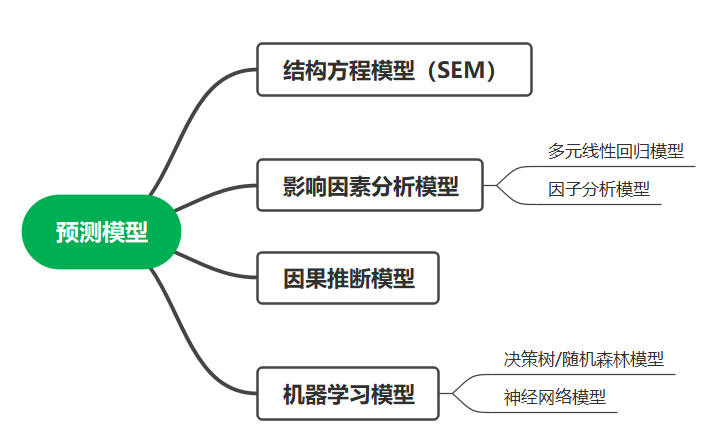
① 结构方程模型(SEM)
- SEM:用于探究不同因素对新能源汽车和传统能源汽车市场份额影响的路径和关系,包括直接影响和间接影响。
import semopy
import pandas as pd
# 示例数据
# 请替换为你自己的数据
data = pd.DataFrame({
'新能源销量': [100, 120, 130, 145, 150],
'传统能源销量': [300, 280, 250, 200, 180],
'政策影响': [0.8, 0.7, 0.6, 0.5, 0.4],
'市场变化': [0.5, 0.6, 0.7, 0.8, 0.9]
})
# 创建结构方程模型
model = '''
# 模型变量定义
新能源销量 =~ 政策影响 + 市场变化
传统能源销量 =~ 市场变化
# 定义误差项相关性
新能源销量 ~~ 传统能源销量
# 修正因素
新能源销量 ~~ 1*新能源销量
传统能源销量 ~~ 1*传统能源销量
政策影响 ~~ 1*政策影响
市场变化 ~~ 1*市场变化
'''
# 创建模型对象
mod = semopy.Model(model)
# 拟合数据
fit = mod.fit(data)
# 查看模型拟合结果
print(fit)
② 影响因素分析模型
- 多元线性回归模型:探究不同因素对新能源汽车和传统能源汽车市场份额影响的程度和方向。
- 因子分析模型:用于确定哪些因素对于两种车辆类型的影响更为显著。
import pandas as pd
from factor_analyzer import FactorAnalyzer
import matplotlib.pyplot as plt
# 示例数据
# 请替换为你自己的数据
data = pd.DataFrame({
'变量1': [1, 2, 3, 4, 5],
'变量2': [2, 3, 4, 5, 6],
'变量3': [1, 1, 2, 2, 3],
'变量4': [3, 4, 5, 6, 7],
'变量5': [4, 4, 5, 6, 7],
})
# 创建因子分析模型对象
fa = FactorAnalyzer(n_factors=2, rotation='varimax')
# 拟合数据
fa.fit(data)
# 提取因子载荷
loadings = fa.loadings_
# 打印因子载荷
print("因子载荷:")
print(loadings)
# 绘制因子载荷热力图
plt.figure(figsize=(8, 6))
plt.imshow(loadings, cmap='viridis', interpolation='nearest')
plt.colorbar()
plt.title('因子载荷热力图')
plt.xlabel('因子')
plt.ylabel('变量')
plt.show()
③ 因果推断模型
- 用于分析不同国家或地区对新能源汽车和传统能源汽车制定的政策对市场份额的影响。
④ 机器学习模型
- 决策树或随机森林模型:用于探究决定新能源汽车和传统能源汽车市场份额的关键特征。
决策树示例代码:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载示例数据(鸢尾花数据集)
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 建立决策树模型
clf = DecisionTreeClassifier(random_state=42)
# 拟合模型
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"决策树模型的准确率为: {accuracy}")
随机森林示例代码:
from sklearn.ensemble import RandomForestClassifier
# 使用同样的数据(鸢尾花数据集)
# X, y = load_iris(return_X_y=True) # 这行代码可以替代之前的加载数据的部分
# 划分训练集和测试集(这里假设已经有了 X, y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 建立随机森林模型
clf_rf = RandomForestClassifier(n_estimators=100, random_state=42)
# 拟合模型
clf_rf.fit(X_train, y_train)
# 预测
y_pred_rf = clf_rf.predict(X_test)
# 计算准确率
accuracy_rf = accuracy_score(y_test, y_pred_rf)
print(f"随机森林模型的准确率为: {accuracy_rf}")
- 神经网络模型:用于处理复杂的非线性关系和多维度数据。
3、影响评估:分析影响,包括市场份额变化、产业结构调整等,可以采用曲线图或数据对比展示不同类型汽车销售量随时间变化的趋势。
问题四:分析针对中国新能源电动汽车的政策对其发展的影响
1、 数据收集
- 政策文件和新闻报道:收集涉及抵制中国新能源电动汽车发展的各国政策文件、官方声明以及相关的新闻报道。
- 中国新能源电动汽车发展数据:获取中国新能源电动汽车销售、市场份额、技术进展等数据。
2. 政策分析
- 梳理政策内容:分析不同国家对中国新能源电动汽车制定的政策措施,包括关税调整、补贴政策变动、技术限制等。
- 确定政策影响因素:分析不同政策对电动汽车发展的影响,如补贴政策、准入限制、税收政策等。
- 政策影响评估:评估各项政策对中国新能源电动汽车产业链、技术进步、市场份额等方面的影响程度。
3. 建立数学模型
- 多元线性回归模型:将政策因素作为自变量,中国新能源电动汽车发展数据作为因变量,建立数学模型。
import pandas as pd
import statsmodels.api as sm
# 示例数据
# 请替换为你自己的数据
data = {
'政策因素1': [1, 2, 3, 4, 5],
'政策因素2': [2, 3, 4, 5, 6],
'政策因素3': [3, 4, 5, 6, 7],
'新能源汽车发展数据': [10, 20, 30, 40, 50]
}
# 转换为DataFrame格式
df = pd.DataFrame(data)
# 设置自变量和因变量
X = df[['政策因素1', '政策因素2', '政策因素3']]
y = df['新能源汽车发展数据']
# 添加截距项
X = sm.add_constant(X)
# 建立多元线性回归模型
model = sm.OLS(y, X).fit()
# 打印回归结果摘要
print(model.summary())
- 时间序列模型:分析不同政策出台后中国新能源电动汽车发展数据的时间序列变化,建立政策影响的时间序列模型。
- 因果推断模型:分析政策因素与中国新能源电动汽车发展数据之间的因果关系。
4. 数据分析与解释
- 数据处理与可视化:对收集到的数据进行清洗、处理,利用图表等方式呈现政策与新能源汽车发展数据的关系。
- 解释模型结果:根据建立的数学模型结果,解释不同政策对中国新能源电动汽车发展的影响。
- 提出结论与建议:总结分析结果,评估各国政策对中国新能源电动汽车发展的影响程度,提出应对措施和建议。
问题五:分析新能源电动汽车在城市中电气化对生态环境的影响
1、 数据收集与准备
- 新能源汽车数据:收集新能源汽车(包括电动公共汽车)的数量、行驶里程、充电设施覆盖率等数据。
- 生态环境数据:获取城市生态环境相关的数据,如空气质量指数(AQI)、二氧化碳排放量、颗粒物浓度等。
2、因果关系建模
- 回归分析模型:建立回归模型,将新能源汽车数量或使用量作为自变量,生态环境指标作为因变量,探索两者之间的关系。
import pandas as pd
import statsmodels.api as sm
# 示例数据
# 请替换为你自己的数据
data = {
'政策因素1': [1, 2, 3, 4, 5],
'政策因素2': [2, 3, 4, 5, 6],
'政策因素3': [3, 4, 5, 6, 7],
'新能源汽车发展数据': [10, 20, 30, 40, 50]
}
# 转换为DataFrame格式
df = pd.DataFrame(data)
# 设置自变量和因变量
X = df[['政策因素1', '政策因素2', '政策因素3']]
y = df['新能源汽车发展数据']
# 添加截距项
X = sm.add_constant(X)
# 建立多元线性回归模型
model = sm.OLS(y, X).fit()
# 打印回归结果摘要
print(model.summary())
- 因果推断分析:通过因果推断模型来评估新能源汽车电气化与生态环境之间的因果关系,确定其对生态环境的影响。
3、空气质量影响评估
- 时间序列分析:对新能源汽车使用数据与城市空气质量指标进行时间序列分析,分析它们之间的关系及影响趋势。
- 灰色关联分析:探究新能源汽车使用与生态环境指标之间的关联度,特别是对空气质量的影响程度。
import pandas as pd
import numpy as np
# 示例数据
# 请替换为你自己的数据
data = {
'新能源汽车销量': [10, 15, 20, 25, 30],
'环境指数': [80, 75, 70, 65, 60],
'经济指数': [30, 35, 40, 45, 50],
'社会指数': [50, 45, 40, 35, 30],
}
# 转换为DataFrame格式
df = pd.DataFrame(data)
# 计算各变量的均值和标准差
means = df.mean()
stds = df.std()
# 标准化数据
for column in df.columns:
df[column] = (df[column] - means[column]) / stds[column]
# 灰色关联度计算函数
def grey_relation_coefficient(x0, x):
rho = 0.5 # 灰色关联系数的确定参数,一般取0.5
min_x0 = min(x0)
max_x0 = max(x0)
min_x = min(x)
max_x = max(x)
# 灰色关联度计算公式
delta_x0 = rho * (max_x0 - min_x0) + (1 - rho) * (max_x0 - x0)
delta_x = rho * (max_x - min_x) + (1 - rho) * (max_x - x)
return delta_x0 / (delta_x0 + delta_x)
# 计算灰色关联度
grey_rel_results = {}
for column in df.columns:
grey_rel_results[column] = grey_relation_coefficient(df[column], df['新能源汽车销量'])
# 打印灰色关联度结果
print("灰色关联度结果:")
for key, value in grey_rel_results.items():
print(f"{key}: {value}")
4、生态环境模拟与预测
- 系统动力学模型:建立系统动力学模型模拟新能源汽车推广对城市生态环境的影响趋势,尤其是空气质量改善情况。
import pysd
# 创建系统动力学模型
model = pysd.read_vensim('path/to/your/model.mdl') # 替换为你的模型文件路径
# 设置模型参数
model.set_components({'新能源汽车推广率': 0.5}) # 设置新能源汽车推广率,此为示例参数
# 运行模型进行模拟
res = model.run()
# 打印模拟结果
print(res)
- 机器学习预测模型:利用机器学习模型(如神经网络、回归模型等)预测未来新能源汽车推广对生态环境的影响。
5、模型计算结果
- 数据模拟与计算:根据建立的模型,结合城市人口为100万的情况,进行模拟和计算。
- 结果解释与呈现:将模型的计算结果用图表、可视化等方式进行清晰展示,包括新能源汽车对生态环境各指标的影响程度及未来趋势。
问题六:撰写新能源电动汽车及其产业贡献公开信
这里我们列出了一些公开信的内容:
- 引言:介绍信件的目的和重要性,吸引读者的注意。
- 新能源电动汽车的好处:说明新能源电动汽车相比传统汽车的优势,如环保、能源效率、减少尾气排放等。
- 新能源电动汽车优势:收集新能源电动汽车的相关信息和研究报告,包括环保性能、节能特点、使用成本等方面的数据。
- 电动汽车行业数据:收集电动汽车行业对经济、环境、社会等方面的贡献数据,如经济效益、碳排放减少、就业创造等数据。
- 成功案例和实证数据:寻找各国电动汽车推广的成功案例和实际数据,以支撑信件中的观点和主张。
- 电动汽车行业对全球的贡献:描述电动汽车行业对环境、经济和社会的积极影响,例如创造就业机会、促进技术创新、降低空气污染等。
- 结尾与号召:总结信件内容,呼吁读者支持和参与推动新能源电动汽车发展。
【扫描下方名片中二维码,获取更多资料~】