python pdf转txt文本、pdf转json
文章目录
- 一、前言
- 二、实现方法
- 1. 目录结构
- 2. 代码
一、前言
此方法只能转文本格式的pdf,如果是图片格式的pdf需要用到ocr包,以后如果有这方面需求再加这个方法
二、实现方法
1. 目录结构
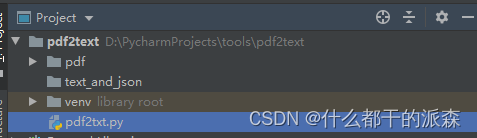
2. 代码
pdf2txt.py 代码如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import json
import os
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage, PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
def batch_process(src_dir, tgt_dir):
'''
批处理
:return:
'''
for pdf_name in os.listdir(src_dir):
pdf_path = os.path.join(src_dir, pdf_name)
text_path = os.path.join(tgt_dir, f'{os.path.splitext(pdf_name)[0]}.txt')
json_path = os.path.join(tgt_dir, f'{os.path.splitext(pdf_name)[0]}.json')
pdf_utils = PDFUtils()
pdf_list = pdf_utils.pdf2list(pdf_path)
# pdf2txt
with open(text_path, mode='w', encoding='utf-8') as f:
f.write(''.join([''.join(page) for page in pdf_list]))
# pdf2json
with open(json_path, mode='w', encoding='utf-8') as f:
f.write(json.dumps(pdf_list, ensure_ascii=False))
class PDFUtils():
def __init__(self):
pass
def pdf2list(self, path):
pdf_list = [] # 二维数组,一维放页,二维放行
with open(path, 'rb') as f:
praser = PDFParser(f)
doc = PDFDocument(praser)
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
pdfrm = PDFResourceManager()
laparams = LAParams()
device = PDFPageAggregator(pdfrm, laparams=laparams)
interpreter = PDFPageInterpreter(pdfrm, device)
for page_idx, page in enumerate(PDFPage.create_pages(doc)):
line_list = [] # 保存每行数据
# print(page_idx)
interpreter.process_page(page)
layout = device.get_result()
for line_idx, line in enumerate(layout):
# print(line_idx)
if hasattr(line, "get_text"):
content = line.get_text()
# print(content)
# output = StringIO()
# output.write(content)
# content = output.getvalue()
# output.close()
# print(content)
if content and content.replace(' ', '') != '\n':
line_list.append(content)
# print(content)
pdf_list.append(line_list)
# output.close()
return pdf_list
if __name__ == '__main__':
# pdf目录
src_dir = './pdf'
# 生成的txt和json文件的保存目录
tgt_dir = './text_and_json'
# 批量转换
batch_process(src_dir, tgt_dir)