相关性分析和作图
相关的类型
1. Pearson、Spearman和Kendall相关
cor(x, y = NULL, use = "everything",
method = c("pearson", "kendall", "spearman"))
states<-state.x77[,1:6]
cov(states)#协方差
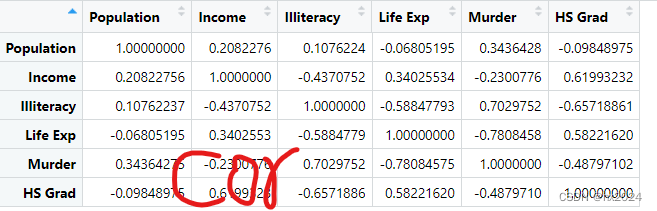
cor <- cor(states)#相关性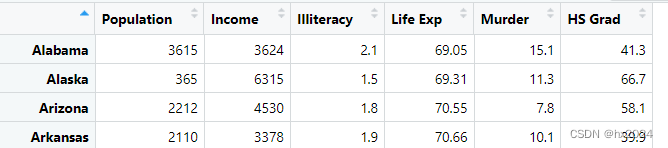
1.计量资料 计量资料(measurement data)又称定量资料(quantitative data)或数值变量(numericalvariable)资料。为观测每个观察单位某项指标的大小而获得的资料。其变量值是定量的,表现为数值大小,一般有度量衡单位。根据其观测值取值是否连续,又可分为连续型(continuous)或离散型(discrete)两类。前者可在实数范围内任意取值,如身高、体重、血压等;后者只取整数值,如某医院每年的病死人数等。
2.计数资料 计数资料(cnumeration data)又称定性资料(qualitative data)或无序分类变量(unorderedcategorical variable)资料,亦称名义变量(nominal variable)资料。为将观察单位按某种属性或类别分组计数,分组汇总各组观察单位数后而得到的资料。其变量值是定性的,表现为互不相容的属性或类别,如试验结果的阳性阴性、家族史的有无等。分两种情形:
(1)二分类:如检查某小学学生大便中的蛔虫卵,以每个学生为观察单位,结果可报告为蛔虫卵阴性与阳性两类;如观察某药治疗某病患者的疗效,以每个患者为观察单位,结果可归纳为治愈与未愈两类。两类间相互对立,互不相容。
(2)多分类:如观察某人群的血型分布,以人为观察单位,结果可分为A型、B型、AB型与O型,为互不相容的四个类别。
3.等级资料 等级资料(ranked data)又称半定量资料(semi-quantitative data)或有序分类变量(ordinalcategorical variable)资料。为将观察单位按某种属性的不同程度分成等级后分组计数,分类汇总各组观察单位数后而得到的资料。其变量值具有半定量性质,表现为等级大小或属性程度。如观察某人群某血清反应,以人为观察单位,根据反应强度,结果可分一、±、+、++、+++、++++六级;又如观察用某药治疗某病患者的疗效,以每名患者为观察单位,结果可分为治愈、显效、好转、无效四级等。
2. 偏相关
library(ggm)
pcor(c(1,5,2,3,6),cov(states))
[1] 0.3462724pcor(c(1,5,2,3,6),cov(states))##控制了变量
相关性的显著性检验
cor.test()
可以使用cor.test()函数对单个的Pearson、Spearman和Kendall相 系数进行检验。简化后的使用格式为:
cor.test(x, y,
alternative = c("two.sided", "less", "greater"),#指定进行双侧检验或单侧检验
method = c("pearson", "kendall", "spearman"),#计算的相关类型
exact = NULL, conf.level = 0.95, continuity = FALSE, ...)
cor.test(states[,3],states[,5])
Pearson's product-moment correlation
data: states[, 3] and states[, 5]
t = 6.8479, df = 48, p-value = 1.258e-08
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.5279280 0.8207295
sample estimates:
cor
0.7029752
corr.test()更好
library(psych)
res <-corr.test(states,use = "pairwise")
#"pairwise"或"complete" 分别表示对缺失值执行成对删除或行删除
corr <- res$r#可以查看相关性R值
corp <- res$p#可以查看P值
res$p.adj#可以查看FDR值library(psych)
res <- corr.test(data, exp, use = 'pairwise',
method = 'spearman', adjust = 'holm',#FDR值
alpha = 0.05)
res$p.adj#可以查看FDR值
res$r#可以查看相关性R值
相关性方法选择
正态分布Pearson
直线相关(linear correlation)又称简单相关(simple correlation),用于双变量正态分布(bivariate normaldistribution)资料。直线相关的性质可由散点图直观的说明。
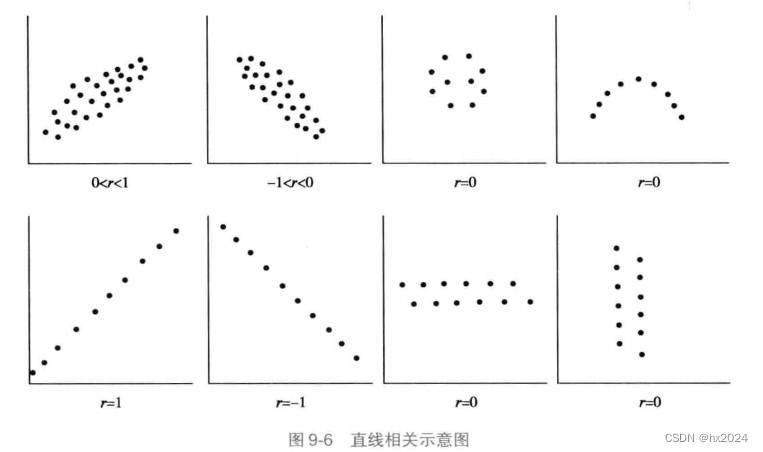
相关系数(coefficient of correlation)又称Pearson积差相关系数(coefficient of product-momentcorrelation),以符号r表示样本相关系数,符号p表示其总体相关系数。它用来说明具有直线关系的两变量间相关的密切程度与相关方向。R²取值在0到1之间且无单位,其数值大小反映了回归贡献的相对程度,也就是在Y的总变异中回归关系所能解释的百分比。回归平方和越接近总平方和,则r绝对值越接近1,说明相关的实际效果越好。
正态分布检测:t检验(连续变量)和卡方检验(分类变量)-CSDN博客
data <- iris##鸢尾花数据集
data1 <- data[,c(1,5)]
data2 <- data1[data1$Species=="setosa"|data1$Species=="versicolor",]
##提取鸢尾花数据集的部分数据进行分析
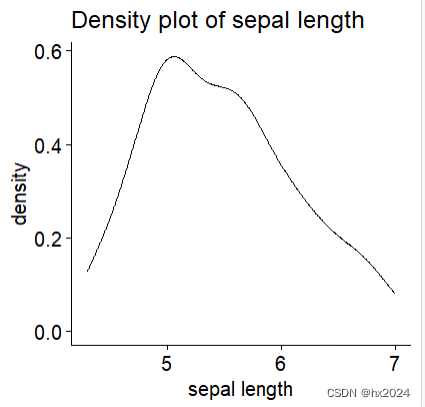
shapiro.test(data2$Sepal.Length)
#W = 0.96964, p-value = 0.02076 不符合正太分布
#密度图
ggdensity(data2$Sepal.Length,
main = "Density plot of sepal length",
xlab = "sepal length")
#正态性测试对样本量敏感。小样本最常通过正态性测试。
#因此,重要的是将外观检查和显着性测试相结合以做出正确的决定
#综合分析也可以采用t检验
秩相关Spearman
秩相关(rank correlation)或称等级相关,是用双变量等级数据作直线相关分析,这类方法对原变量分布不作要求,属于非参数统计方法。适用于下列资料:①不服从双变量正态分布而不宜作积差相关分析,这一点从原始数据的基本统计描述或直观的散点图中可以看出;②总体分布型未知,例如限于仪器测量精度个别样品的具体数值无法读出而出现“超限值”时(如X<0.001);③原始数据是用等级表示。用等级相关系数r来说明两个变量间直线相关关系的密切程度与相关方向。
相关性热图
corrplot包corrplot函数
数据处理:计算相关性系数和P值
rm(list = ls())
library(corrplot)
# 计算相关性
corData = cor(mtcars,
method = "pearson", # 计算相关性的方法有"pearson", "spearman", "kendall"
use = "pairwise.complete.obs") # 缺失值处理的方式
# 计算相关性的P值和置信区间
testRes = cor.mtest(mtcars,
conf.level = 0.95, # 置信区间
method = "pearson") # 计算相关性的方法有"pearson", "spearman", "kendall"
corrp <- testRes$p

绘图:
#pdf("plot.pdf",width = 4,height = 4)##保存图片
# 绘图
?corrplot
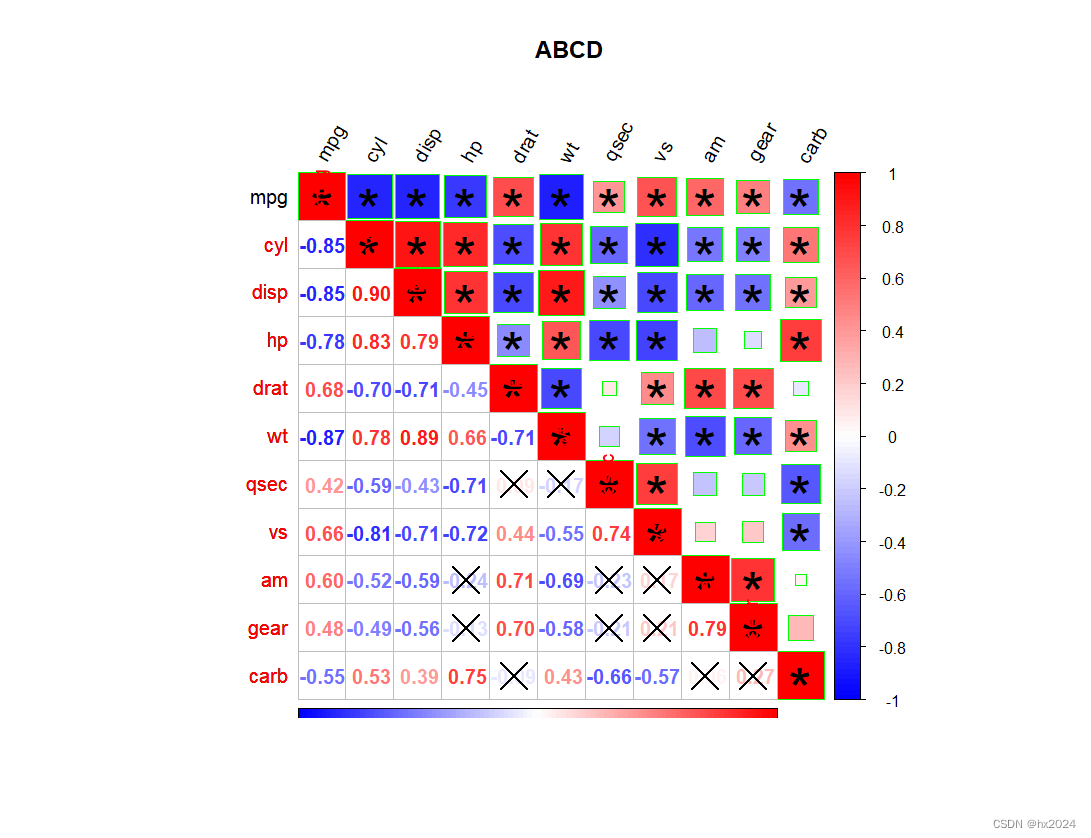
corrplot(corData,
method = "square", # 图案形状 "square"方框,"circle"圆, "ellipse"椭圆, "number"数字, "shade"阴影花纹, "color"颜色方框, "pie饼图"
type = "full", # 绘制范围"full"全部, "lower"下半部分, "upper"半部分
col=colorRampPalette(c('#0000ff','#ffffff','#ff0000'))(100), # 主体颜色
bg = "white", # 背景颜色
# col.lim = c(-1,1), # 数据颜色的范围,是相关性数据的话,直接is.corr = T就好
title = "ABCD", # 标题
is.corr = T, # 输入相关性矩阵,数据范围-1到1
add = F, # 是否在原来的图层上添加图形
diag = T, # 是否显示主对角
outline = "green", # 轮廓,True或False或设置颜色
mar = c(5, 4, 4, 2), # bottom,left,top,right 指定的边距行数(需要一定的边距才能显示标题)
addgrid.col = NA, # 网格线的颜色,NA为不绘制,NULl为默认的灰色
addCoefasPercent = F, # 是否把相关性数值改为百分数
order = "original", # 排序方式 c("original", "AOE", "FPC", "hclust", "alphabet")
hclust.method = c("complete", "ward", "ward.D", "ward.D2", "single", "average","mcquitty", "median", "centroid"),
#position of text labels标签参数(好像没有缩短图例的参数)
tl.pos = "lt", # 位置'lt', 'ld', 'td', 'd' or 'n'
tl.cex = 1, # 字体的大小
tl.col = "black", # 字体的颜色
tl.offset = 0.4, # 标签离图案的距离
tl.srt = 60, # 坐标轴标签旋转角度
#color-legend;图例参数
cl.pos = "r", # 图例位置:r右边 b下边 n不显示
cl.length = NULL, # 数字越大,图例的分隔越稠
cl.cex = 0.8, # 图例的字体大小
cl.ratio = 0.2, # 图例的宽度
cl.align.text = "c", # 图例文字的对齐方式 l左对齐 c居中 r右对齐
cl.offset = 1, # 图例文字距离图例颜色条的距离 居中时无效
#数值显示
number.cex = 1, # 相关性数字标签的字体大小
number.font = 2, # 相关性数字标签的字体
number.digits = 2, # 相关性数字标签,保留的小数点位数
na.label = "", # 当为NA时,显示的内容
## P值矩阵
p.mat = testRes$p,
sig.level = 0.05, # 当p大于sig.level时触发动作
insig = "label_sig", # sig.level, insig, pch, pch.col, pch.cex,label_sig(星号)
#置信区间
plotCI = "n", # c("n", "square", "circle", "rect")
lowCI.mat = testRes$lowCI, # p值置信区间下边界数据
uppCI.mat = testRes$uppCI, # p值置信区间上边界数据
)

添加下三角:上下三角不一致
add = T, diag = F,
#添加图形
corrplot(corData,
method = "number",
type = "lower", #下三角
col=colorRampPalette(c('#0000ff','#ffffff','#ff0000'))(100), # 主体颜色
add = T, # 是否在原来的图层上添加图形
diag = F, # 是否显示主对角
order = "original",
na.label = "", # 当为NA时,显示的内容
p.mat = testRes$p, # P值矩阵
sig.level = 0.05, # 当p大于sig.level时触发动作
)
dev.off()
ggcorrplot包ggcorrplot函数
数据
rm(list = ls())
library(ggcorrplot)
library(ggtext)
data(mtcars)
corr <- round(cor(mtcars), 2)#相关系数(保留2位小数)
p.mat <- cor_pmat(mtcars)##P值
作图
(这个图例要小很多)
?ggcorrplot
ggcorrplot(corr, method = "square", #"square", "circle"
type ="full" , #full完全(默认),lower下三角,upper上三角
ggtheme = ggplot2::theme_minimal,
title = "ABCD",
show.legend = TRUE, #是否显示图例。
legend.title = "CorrA", #指定图例标题。
show.diag =T , #对角线
colors = c("blue", "white", "red"), #颜色设置
outline.color = "white", #指定方形或圆形的边线颜色
hc.order = FALSE, #是否按hclust(层次聚类顺序)排列
##显示相关性系数设置
lab =F , #是否添加相关系数
lab_col = "black", #相关系数的颜色,只有当lab=TRUE时有效
lab_size = 4, #指定相关系数大小,只有当lab=TRUE时有效。
#P值显示
p.mat = p.mat , #p.mat= p_mat,insig= "pch", pch.col= "red", pch.cex= 4,
sig.level = 0.05,#P值
insig = c("pch", "blank"),#显示X
pch = 8, #8为星号
pch.cex = 4, #大小
#标签
tl.cex = 10, #指定变量文本的大小,
tl.col = "black", #指定变量文本的颜色,
tl.srt = 45, #指定变量文本的旋转角度。
digits = 2 #指定相关系数的显示小数位数(默认2)。
)
dev.off()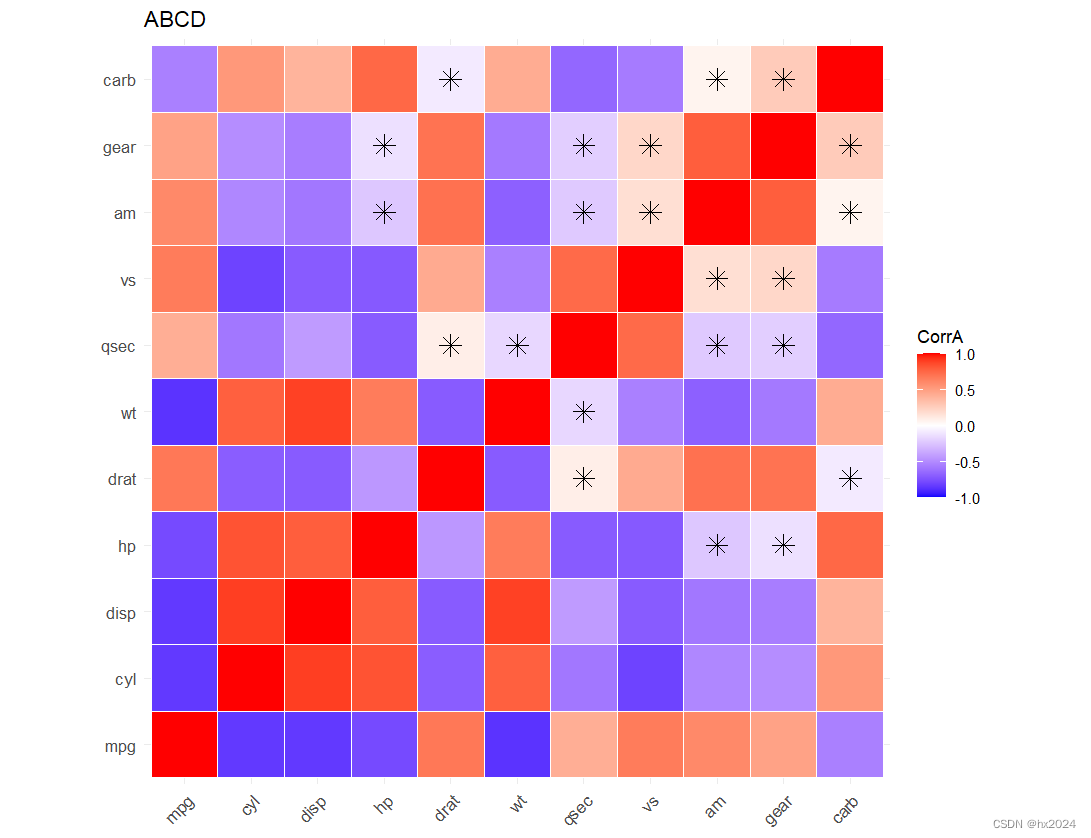
如果需要显示相关性系数:展示
##显示相关性系数设置
lab =T , #是否添加相关系数
lab_col = "black", #相关系数的颜色,只有当lab=TRUE时有效
lab_size = 4, #指定相关系数大小,只有当lab=TRUE时有效。
计算矩阵后使用pheatmap作图
pheatmap作图可以更好的展示P值
数据准备
rm(list = ls())
library(ggcorrplot)
library(ggtext)
library(psych)
library(pheatmap)
library(reshape2)
data(mtcars)
corr <- round(cor(mtcars), 2)
p.mat <- cor_pmat(mtcars)
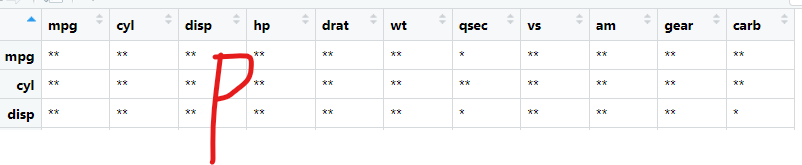
table(p.mat<0.05)#P计数
##对所有p值进行判断,p<0.01的以“**”标注,p值0.01<p<0.05的以“*”标注
if (!is.null(p.mat)){
ssmt <- p.mat< 0.01
p.mat[ssmt] <-'**'
smt <- p.mat >0.01& p.mat <0.05
p.mat[smt] <- '*'
p.mat[!ssmt&!smt]<- ''
} else {
p.mat <- F
}
作图
#自定义颜色范围
mycol<-colorRampPalette(c("blue","white","tomato"))(100)
#绘制热图,可根据个人需求调整对应参数
?pheatmap
pheatmap(corr,
scale = "none",#均一化处理
cluster_row = T, #行距类
cluster_col = T, #列聚类
treeheight_col = 0, #设置为0 即不显示聚类树
treeheight_row = 20,#行聚类树
border=NA,#边框颜色
display_numbers = p.mat,##显著性标记
fontsize_number = 12,
number_color = "white",
cellwidth = 20, #格子宽度
cellheight =20,#格子高度
color=mycol,#颜色
legend=T,#是否显示图例
main="ABCD")#标题
dev.off()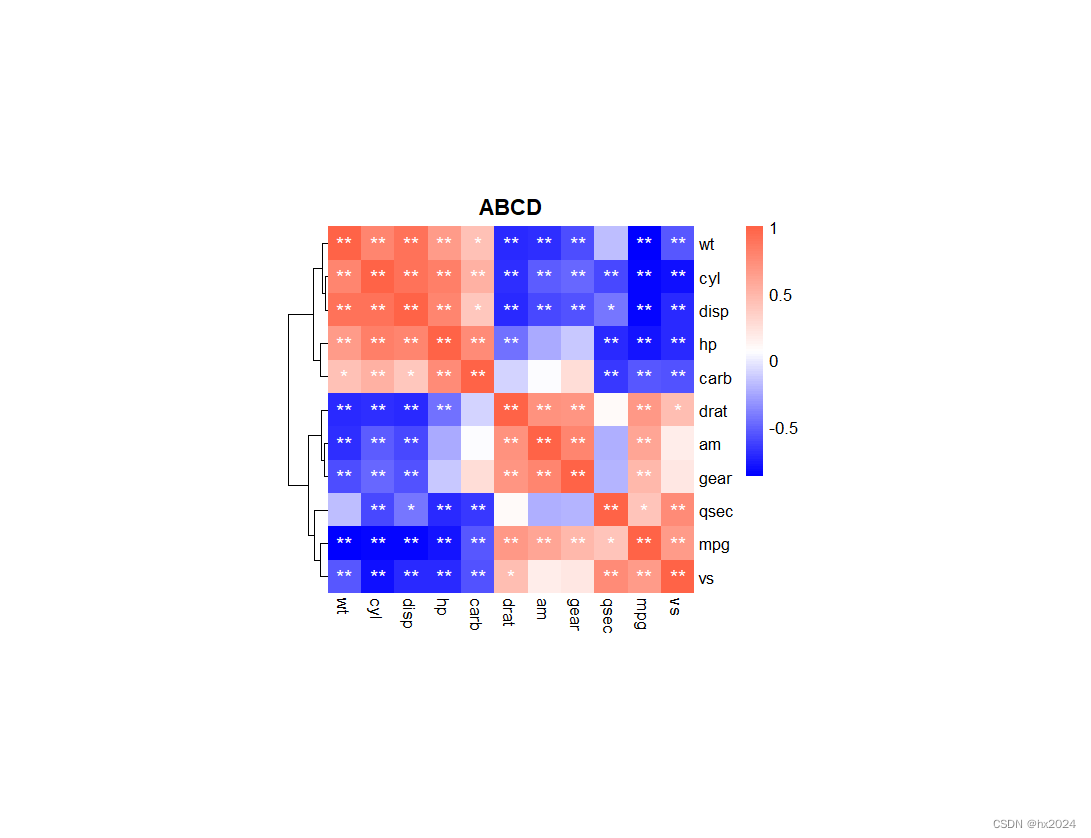
参考:
1:医学统计学/孙振球,徐勇勇主编.—4版.一北京:人民卫生出版社,2014
2:R语言实战/(美)卡巴科弗(Kabacoff,R.I.)著;高涛,肖楠,陈钢译.--北京:人民邮电出版社,
2013.1
3:R语言---相关系数_r语言相关系数-CSDN博客