论文阅读——DDeP(cvpr2023)
分割标签耗时且贵,所以常常使用预训练提高分割模型标签有效性,反正就是,需要一个预训练分割模型。典型的分割模型encoder部分通过分类任务预训练,decoder部分参数随机初始化。作者认为这个方法次优,尤其标签比较少的情况。

于是提出可以和监督学习encoder结合的基于去噪denoising的decoder预训练方法。当标签少的时候这个方法表现很好,超过监督学习。

所以整个方法就是,encoder在ImageNet-21k上预训练,然后冻结encoder参数,再在ImageNet-21k预训练decoder参数,不需要使用标签。然后在特定数据集上统一微调encoder和decoder。
架构:

标准的去噪公式是:
![]()

也就是预测原始图片x。
但是扩散模型预测的是噪声:

于是做实验看预测哪个比较好:

所以预测噪声。
所以,上述说明,本文的方法是一个无监督、去噪的方法。
无监督的预训练方法最终受到预训练目标所学习的表示与最终目标任务所需的表示之间不匹配的限制。对于任何无监督目标,一个重要的“健全性检查”是它不会很快达到这个极限,以确保它与目标任务很好地一致。增大预训练计算预算(应该是训练迭代多一些),可以提高表示能力。说明去噪是一种可扩展的方法,增大预训练计算预算,表示能力提高。

和监督训练相比,数据多的时候不如监督预训练,少的时候超过。

噪声的影响:
去噪预训练的解码器一个很重要的超参数是噪声的大小。噪声方差必须足够大,这样网络才能学习到有意义的表示从而去除噪声,但不能太大,导致干净图像和有噪声图像之间的过度分布偏移。
可伸缩的加性噪声(Scaled Additive Noise)性能好于简单加性噪声(Simple Additive Noise)。
简单加性噪声:![]()
可伸缩加性噪声:![]()

从图上看,论文给出的最好的噪声大小是0.22
encoder部分在ImageNet-21K数据集做分类任务预训练,然后固定参数。
单独预训练去噪decoder。原则上,任何一个数据集都能进行去噪预训练,但是会有这样的担心:即预训练数据和目标数据之间分布的变化可能会影响目标任务的性能。为了验证这种担心,作者在几个数据集上预训练了decoder,而encoder都是ImageNet-21K数据集做分类任务预训练,参数固定。最后发现还是在ImageNet-21K预训练的decoder效果最好。这个结论也适用于和ImageNet-21K数据集分布不同的Cityscapes数据集,因此,用DDeP预训练的模型可以用于很多其他数据集。

上面这些预训练目标的选择,也就是预测噪声而不是x,和噪声的选择等,和扩散模型很相似,这样自然就会产生一个问题,即如果使用完全的扩散模型预训练,是不是提高性能。结果是用DDPM方法预训练没有提高性能。
前面提到的噪声大小的γ,在我们的模型是一个定值,也就是相当于扩散模型的一步,PPDM是一个完全的扩散模型,它每一个训练例子中都从[0,1]中随机均匀选一个γ值。于是作者试验了随机选择γ,但是效果不如固定的γ。

实验部分:
微调设置:cross-entropy loss, Adam with a cosine learning rate decay schedule,a batch size of 512 and train for 100 epochs,learning rate is 6e−5 for the 1× and 3× width decoders, and 1e−4 for the 2× width decoder;
random cropping and random left-right flipping,1024 × 1024 for Cityscapes and 512×512 for ADE20K and Pascal Context,All of the decoder denoising pretraining runs are conducted at a 224 × 224 resolution。
inference on Cityscapes:apply horizontal flip and average the results for each half;For Pascal Context and ADE20K, we also use multi-scale evaluation with rescaled versions of the image in addition to the horizontal flips. The scaling factors used are (0.5, 0.75, 1.0, 1.25, 1.5, 1.75)。
结果:



上面这些结果使用的是TransUNet,下面标准UNet
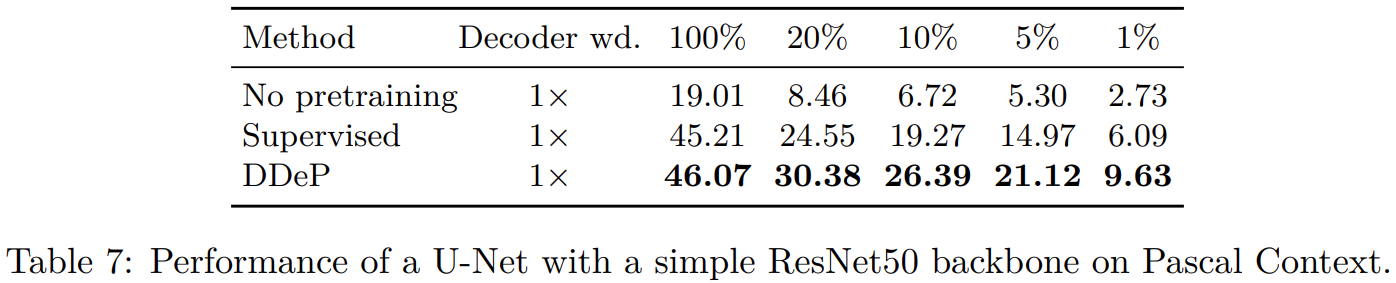
说明这个方法可以泛化到其他不是transformer architectures的结构,即backbone-agnostic。