Kafka 保证消息消费全局顺序性
当有消息被生产出来的时候,如果没有指定分区或者指定 key ,那么消费会按照【轮询】的方式均匀地分配到所有可用分区中,但不一定按照分区顺序来分配

我们知道,在 Kafka 中消费者可以订阅一个或多个主题,并被分配一个或多个分区

如果一个消费者消费了多个分区,某些场景下消费者需要顺序地消费消息,但消息并不是按照顺序分配给分区的,所以就不一定能够保证消息消费的全局顺序性
比如下图中 Msg0002 消息并不是在 Msg0001 消息之后的,就有可能导致消费者先把 Msg0002 消息给消费, Msg0001 消息才被消费

那么这种情况该怎么解决?如何尽可能地保证消息消费的全局顺序性?(即这些消息具有因果关系)要想消费消息 B 必须先消费消息 A
要注意的是,Kafka 的设计目标是提供高吞吐量和低延迟,而不是强制保证全局有序性
所以这篇文章探讨的是需要强调全局顺序性场景下的 Kafka 应用
单分区
最简单粗暴的方法,虽然 Kafka 不能保证全局消费顺序性,但是能够保证分区内的消息顺序性

所以我们可以只创建一个分区,并让消费者消费这个分区,这样就能够保证消费的消息是有序的
但是这样做大大降低了吞吐量和处理效率,容易使得性能出现瓶颈
基于 key
在 Kafka 中,基于 key 的消息分配策略是通过消息中的键(key)来确定消息发送到哪个分区
当生产者发送消息时,可以指定一个键(key),Kafka 使用这个键通过哈希算法来确定消息被发送到哪个分区

由于相同的 key 就发送到同一分区,这样就能够保证了消费的消息是有序的
然而,如果只有一个消费者消费相同 key 的消息,那么与单分区相比,基于 key 的消息分配策略不会提高吞吐量
因为即使相同 key 的消息在多个分区中,但同一消费者依然只能从一个分区中消费,这并不会增加整体的处理能力。
但如果有多个消费者消费相同 key 的消息,基于 key 的分区策略可以提高消费者并行消费的能力
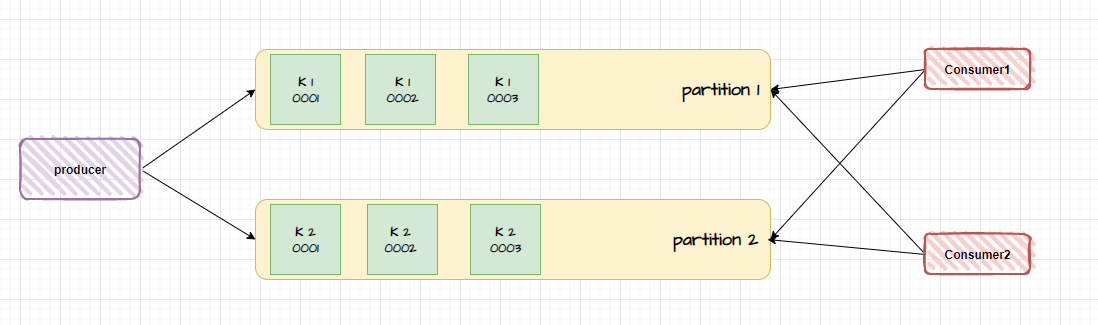
因为这些消费者可以同时从不同分区中读取消息,从而增加整体的处理速度。这种情况下,基于 key 的消息分配可以提高整体吞吐量
最后总结一下:
-
Kafka 的设计目标是提供高吞吐量和低延迟,而不是强制保证全局有序性,所以Kafka使用多分区的概念,并且只保证单分区有序
-
如果想要实现消息的全局有序
-
单分区策略:
一个主题下只创建一个分区,一个消费者只消费一个分区,但这样做毫无并发性可言,极大降低系统性能
-
基于 key 的消息分配策略:
由于相同的 key 就发送到同一分区,这样就能够保证了消费的消息是有序的。然而,如果只有一个消费者消费相同 key 的消息,与前面单分区相比没有什么区别
-