深度视觉目标跟踪进展综述
1 引言
目标跟踪旨在基于初始帧中指定的感兴趣目标( 一般用矩形框表示) ,在后续帧中对该目标进行持续的定位。
基于深度学习的跟踪算法,采用的框架包括相关滤波器、分类式网络、双路网络等。
处理跟踪任务的角度,分为基于匹配思路的双路网络和基于二分类的辨别式跟踪器。
最初的深度跟踪算法聚焦于相关滤波器,通过深度学习的特征+相关滤波器实现。
基于双路网络跟踪算法那,将跟踪视为模板匹配,抗干扰能力较差。
近期基于Transformer的深度跟踪器使用注意力机制,取得了领先的性能。

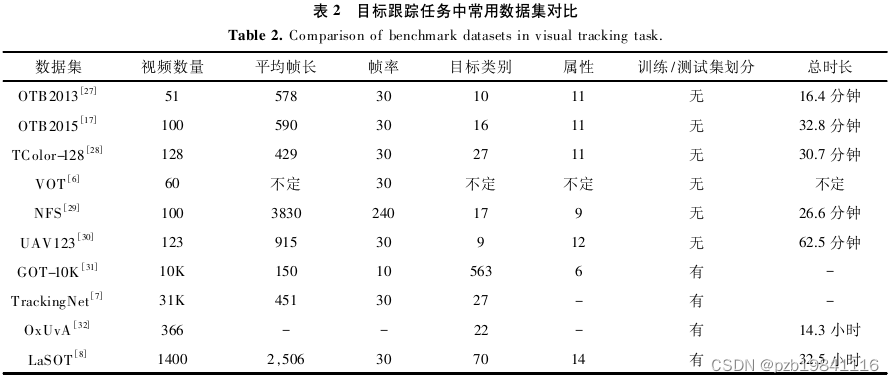
2 跟踪数据集发展趋势
数据、算法和算力是人工智能最重要的三个要素,是人工智能的三个基石。
3 深度跟踪算法
3.1 深度相关滤波器跟踪
相关滤波器( correlation filter,CF) 通过学习一个具有区分力的滤波器来处理待跟踪的图片,其输出结果为一个响应图,表示目标在后续帧中不同位置的置信度.
在早期的工作中,研究人员探索如何将离线训练好的深度特征(如利用ImageNet预训练的 VGG模型)与相关滤波器进行结合。本质就是将HOG等手工特征替换成神经网络提取的特征。
深度学习提取特征的特点是,高层的语义特征对于目标的抽象表达能力很强,而低层的模型特征擅长刻画目标的纹理、形状等底层信息.
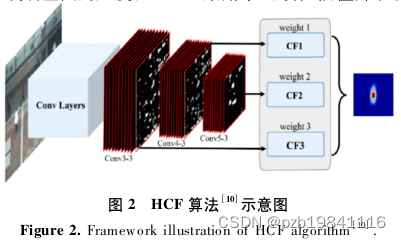
HCF算法的示意图,融合了不同层次的深度特征。
得益于相关滤波器的闭合解,研究人员尝试将滤波器和深度特征提取网络进行联合训练,等于是深度特征从离线获取升级到联合训练。
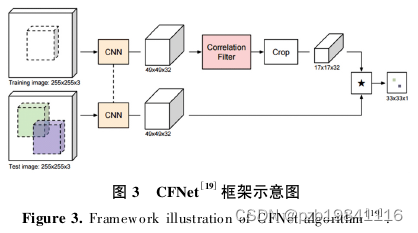
CFNet算法的架构,就是采用联合训练的模式。
3.2 基于分类的深度跟踪器
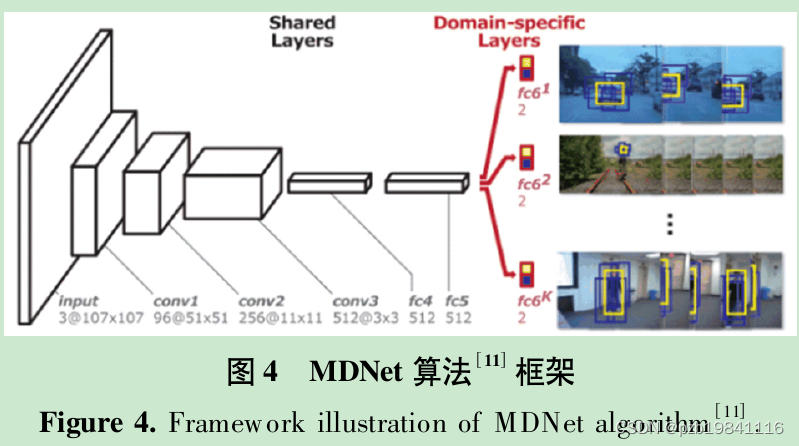
基于分类的深度跟踪方法受经典的目标检测框架R-CNN的启发,将目标跟踪任务视为二分类( 目标和背景) 任务。
对每个视频,分别训练独立的分类层(最后一个全连接层)用于区分当前视频域中的目标和干扰物.
3.3双路网络跟踪算法
双路网络框架(SiamFC),此方法利用卷积网络提取目标模板和搜索区域的特征,然后再进性相关操作生成响应图,其中响应图上的峰值点就是目标所在的位置。

在此之后,考虑到SiamFC对目标尺度的回归仍然采用传统缩放形式不能准确地获得目标的尺度信息。
SiamRPN ++解决了边界填充问题,也使用了多层次特征融合的方法。
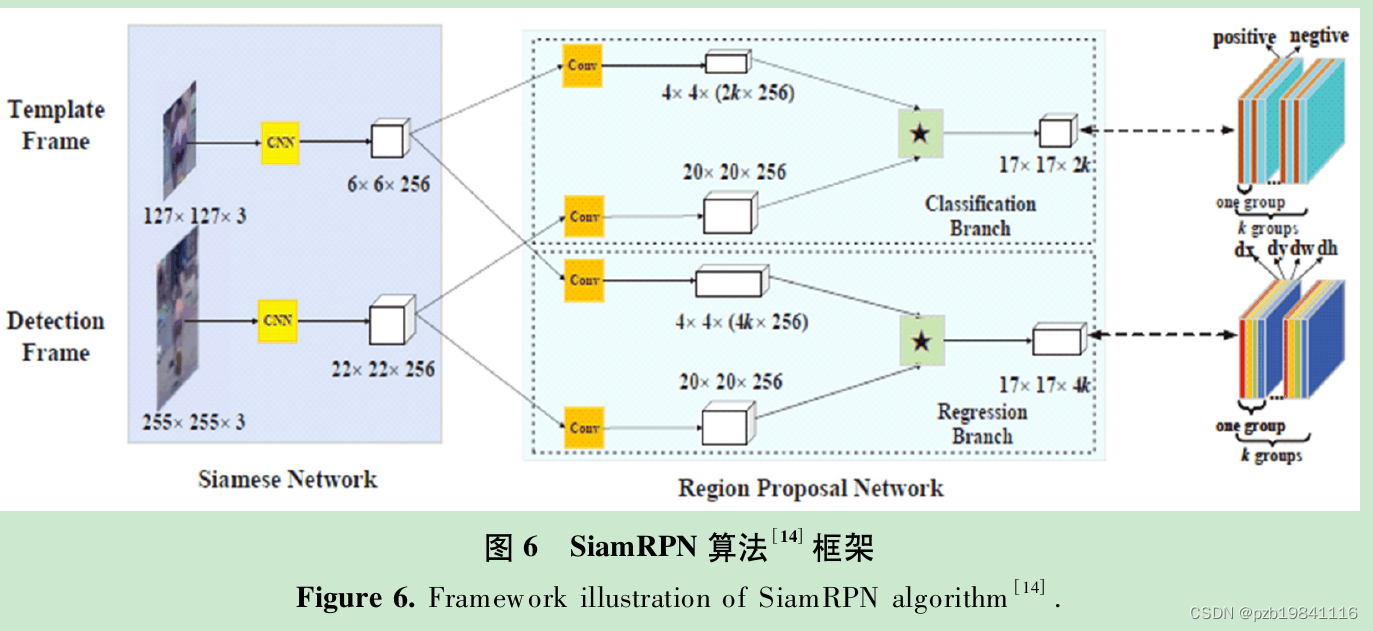
尽管以上的双路网络方法在视频目标跟踪中取得了很大的成功,但是仍然存在缺陷,缺少在线更新过程.MemTrack、Meta-Tracker、Re2EMA、UpdateNet和GradNet等, 提出了不同的模板更新算法。
3.4基于梯度优化的深度跟踪方法
CREST的该卷积核和搜索图片的特征图进行卷积,可以生成响应图用于目标跟踪,有点模版匹配的味道。
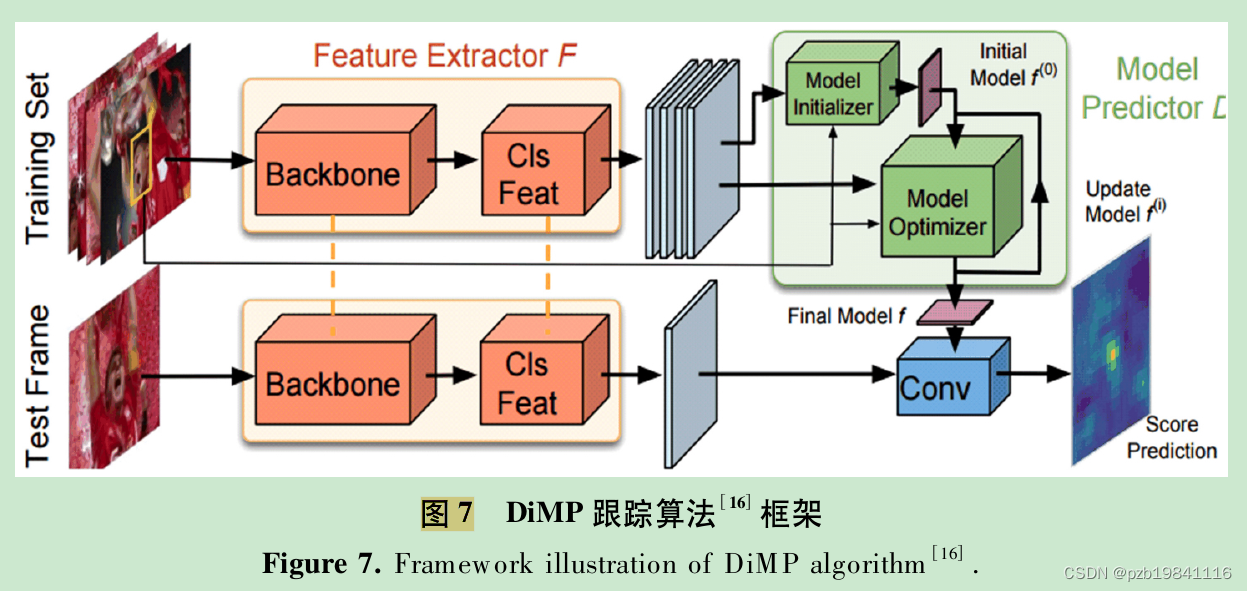
3.5基于Transformer的深度跟踪方法
Transformer的核心模块是注意力机制,可以将全局信息聚合到需要的位置.
4展望
如何设计适合他们的轻量级模型,例如使用神经网络搜索的方式来获得更优的模型结构,以兼顾低内存消耗和高精度具有重要的研究价值。总之就是平衡精度与模型复杂度之间矛盾。
5结论
虽然深度学习算法取得了令人瞩目的成绩,但与此同时带来的跟踪效率限制和模型存储消耗等问题仍需进一步完善.