【解决】HDFS JournalNode启动慢问题排查
文章目录
- 一. 问题描述
- 二. 问题分析
- 1. 排查机器性能
- 2. DNS的问题
- 三. 问题解决
- 1. 修复DNS服务
- 2. 添加主机映射为0.0.0.0
- 3. 修改hadoop源码
一句话:因为dns的问题导致journalnode启动时很慢,通过修复dns对0.0.0.0域名解析,修复此问题。
一. 问题描述
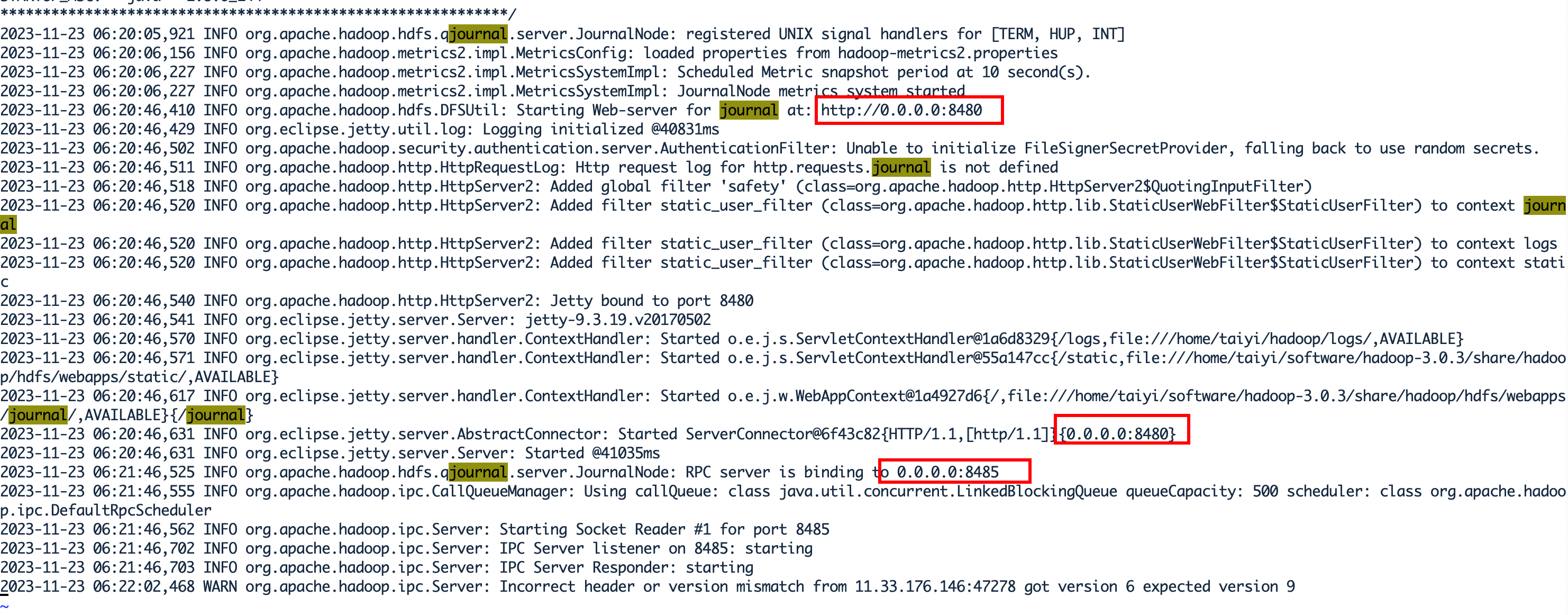
从journalnode启动到服务可用,完成RPC Listen,需要花费大概1分多钟的问题,而这不符合安装预期。
二. 问题分析
1. 排查机器性能
简单查看cpu、内存、磁盘、网络等是否存在问题
# top 资源占用
top
# 内存
free -h
# 磁盘占用
df -h
# 网络延迟
ping hostname
发现都正常。
2. DNS的问题
查看了资源都正常,此时有些迷茫,打开chat-gpt问问:
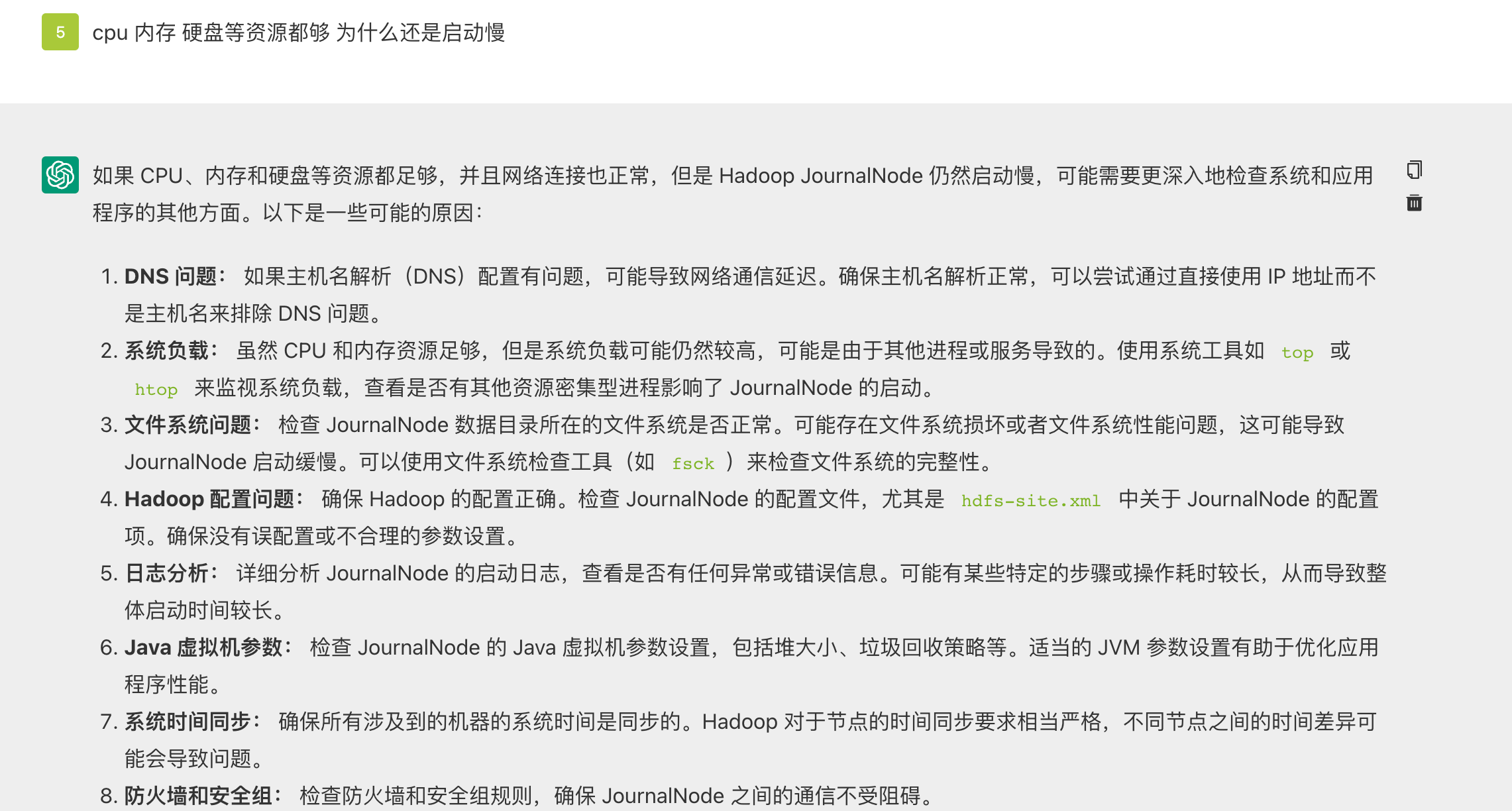
其中第一点提到了DNS的问题,而日志中看到:
在启动journalnode过程中会启动8480、和8485端口,而这两个端口使用的ip都是0.0.0.0。
0.0.0.0意味着journalnode将监听所有可用ip地址,这里的ip地址指的是journalnode所在节点的所有地址。
好处是内网ip和外网ip都能被访问ing?
执行:nmap -v 0.0.0.0
nmap -v 0.0.0.0
。。。
Initiating Parallel DNS resolution of 1 host. at 18:00
Completed Parallel DNS resolution of 1 host. at 18:00, 13.00s elapsed
。。。
大概意思是0.0.0.0的DNS解析花费了13秒。
另外一台机同样执行:
nmap -v 0.0.0.0
。。。
Initiating Parallel DNS resolution of 1 host. at 18:17
Completed Parallel DNS resolution of 1 host. at 18:17, 0.03s elapsed
。。。
只花了0.03秒,说明此节点的DNS解析确实有问题。
再观察个有意思的现象:
nmap -v hostname1
Starting Nmap 6.40 ( http://nmap.org ) at 2023-11-23 18:20 CST
Initiating Ping Scan at 18:20
Scanning xxx [2 ports]
Completed Ping Scan at 18:20, 0.00s elapsed (1 total hosts)
Initiating Connect Scan at 18:20
。。。。
Completed Connect Scan at 18:20, 0.03s elapsed (1000 total ports)
。。。
Host is up (0.00038s latency).
Not shown: 994 closed ports
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
3306/tcp open mysql
8899/tcp open ospf-lite
9000/tcp open cslistener
9010/tcp open sdr
Read data files from: /usr/bin/../share/nmap
Nmap done: 1 IP address (1 host up) scanned in 0.06 seconds
当我对具体hostname执行这个命令时,发现没有DNS解析,这里是hosts文件起了作用,绕开了DNS。
Hosts文件是一种本地的文本文件,位于计算机的文件系统中。它用于将特定的主机名映射到相应的IP地址,充当本地的静态映射表。
当系统尝试访问某个主机名时,它首先会查找本地hosts文件,如果找到对应的映射,就直接使用这个映射而不进行DNS查询。这可以提高访问速度,并且可以在本地定义自定义的主机名到IP地址的映射。
那既然能绕过DNS,我将journalnode的配置改成具体hostname,如下:hdfs-site.xml
<property>
<name>dfs.journalnode.rpc-address</name>
<value>hostname1:8485</value>
<description>Address for JournalNode RPC (e.g., "hostname:8485")</description>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>hostname1:8480</value>
<description>Address for JournalNode HTTP (e.g., "hostname:8480")</description>
</property>
重新启动journalnode:
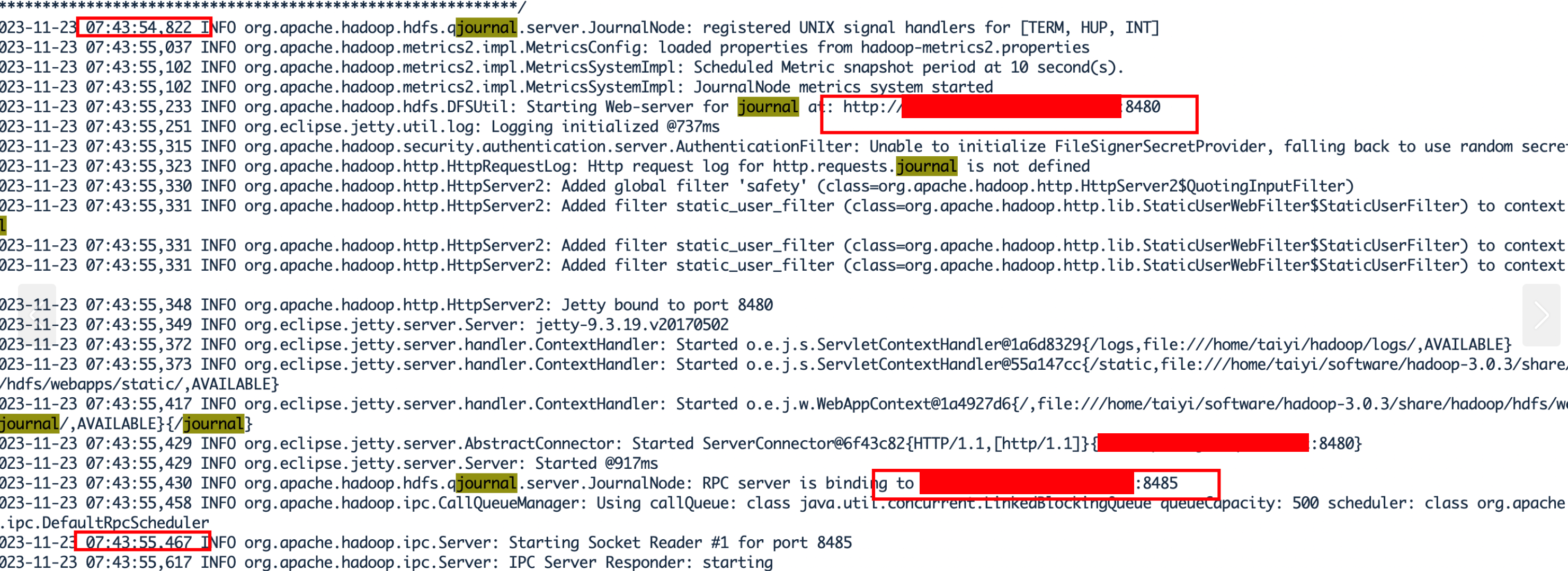
发现启动速度果然上来了。那基本上可以确定是因为DNS解析慢导致了hadoop组件启动慢。
三. 问题解决
1. 修复DNS服务
修改DNS配置

去掉无法连接的DNS地址后,测试journalNode服务在0.0.0.0地址监听,启动过程无延迟。
2. 添加主机映射为0.0.0.0
如果碰到机器中没有办法配置DNS服务的,可以修改hdfs-site.xml如上操作,另外可以修改/etc/hosts:
0.0.0.0 hostname1
这样Hadoop启动时也会绕过DNS解析,快速启动Hadoop服务。
3. 修改hadoop源码
github hadoop/hdfs/qjournal/server/JournalNodeRpcServer.java
class JournalNodeRpcServer implements QJournalProtocol {
...
static InetSocketAddress getAddress(Configuration conf) {
String addr = conf.get(
DFSConfigKeys.DFS_JOURNALNODE_RPC_ADDRESS_KEY,
DFSConfigKeys.DFS_JOURNALNODE_RPC_ADDRESS_DEFAULT);
return NetUtils.createSocketAddr(addr, 0,
DFSConfigKeys.DFS_JOURNALNODE_RPC_ADDRESS_KEY);
}
...
}
@InterfaceAudience.Private
public class DFSConfigKeys extends CommonConfigurationKeys {
...
public static final String DFS_JOURNALNODE_RPC_ADDRESS_KEY = "dfs.journalnode.rpc-address";
public static final String DFS_JOURNALNODE_RPC_ADDRESS_DEFAULT = "0.0.0.0:" + DFS_JOURNALNODE_RPC_PORT_DEFAULT;
...
}
可以看到当不配置dfs.journalnode.rpc-address时会使用0.0.0.0来启动journalNode,我们可以写一个方法主动获取当前启动节点的hostname,然后覆盖这个0.0.0.0。
写个类简单测试下:
package com.gao.utils;
import java.net.InetAddress;
public class GetHostname {
public static void main(String[] args) {
try {
// 使用 InetAddress 类的 getLocalHost() 方法获取本地主机信息
InetAddress localHost = InetAddress.getLocalHost();
// 获取主机名
String hostname = localHost.getHostName();
// 输出主机名
System.out.println("当前节点的主机名是: " + hostname);
} catch (Exception e) {
// 处理异常
e.printStackTrace();
}
}
}
打包、上传、在启动节点执行:
java -cp daily-test-1.0-SNAPSHOT.jar com.gao.utils.GetHostname
当前节点的主机名是: hostname1