Fuzz进阶教学——人工智能在模糊测试中的应用
【参考文献】白海波.人工智能技术在模糊测试中的应用[J].数字技术与应用,2023,41(08):16-18.DOI:10.19695/j.cnki.cn12-1369.2023.08.05.
目录
摘要
一、模糊测试简介
1、原理
2、工作流程
3、分类
4、应用领域
二、人工智能在模糊测试中的应用
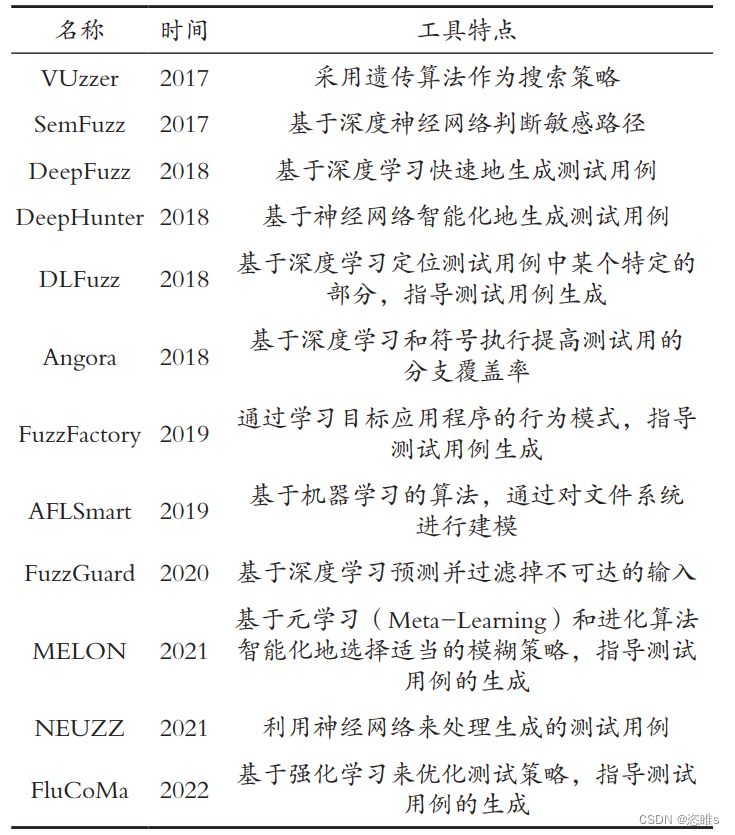
1、人工智能技术
2、人工智能技术指导模糊测试过程
3、人工智能技术在模糊测试中的应用案例
摘要
- 模糊测试作为一种简单、易用、低成本的技术,已经被广泛应用于软件系统的漏洞检测,它的基本原理是通过模拟随机输入数据来探测软件系统中的潜在漏洞。
- 虽然模糊测试方法简单,但由于数据的随机性往往比较高,导致测试效率和准确性不能得到保 证。
- 随着人工智能技术的不断发展,将人工智能技术应用于模糊测试中,可以帮助测试人员在更短的时间内发现更多的漏洞。
一、模糊测试简介
1、原理
- 模糊测试 (Fuzzing)也称为随机测试,是一种软件测试技术,它通过产生随机的测试用例,并将其输入到目标程序中执行,观察程序的反应,进而发现程序中的漏洞和异常行为。
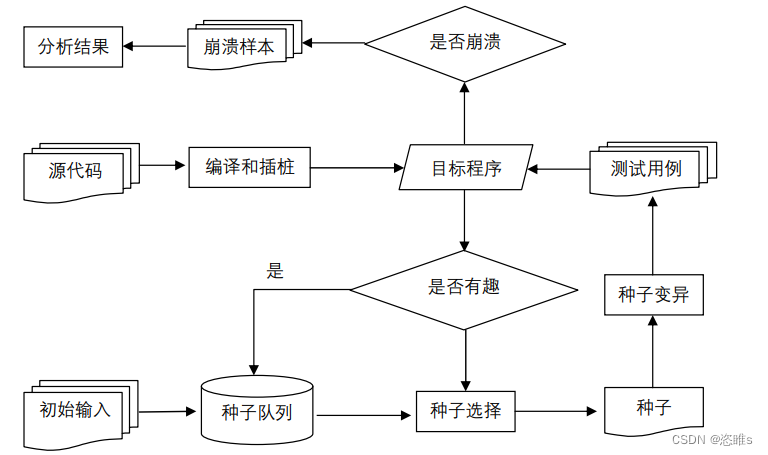
2、工作流程
- 确定测试目标
- 首先要确定测试的目标。例如,测试一个应用程序的某个特定功能或对程序的全部模块 进行测试。
- 确定测试目标后,需要了解程序的特点。例如,程序的输入参数、限制、响应机制等。
- 生成测试用例
- 首先需要收集一些输入数据作为种子,然后通过对种子进行变异操作(如修改、插入、删除、替换等)来生成大量的测试用例,并将这些测试用例提供给被测软件进行执行,以尽可能地触发潜在漏洞。
- 执行测试用例
- 将生成的测试用例输入到程序中,并记录程序输出结果和异常情况。
- 分析和处理结果
- 整理并分析测试结果,筛选出能够让程序产生错误的测试用例,找出Bug所在位置。通过分析和处理结果,可以进一步调整测试用例生成方式(反馈),提高下次迭代的测试效率和覆盖率。
-
3、分类
- 根据模糊测试过程中生成测试用例的方式,模糊测试技术可以分为:
- 基于变异的模糊测试
- 在原始测试用例的基础上进行随机变异,生成新的测试用例。
- 这些变异可以是针对单个字节、一组字节、整行或整个文件进行的,以生成具有各种不同变化的测试用例。
- 基于生成的模糊测试
- 通过学习和模拟程序输入数据的规则,以生成符合输入规则的测试用例。
- 这种方式需要提前了解程序输入数据的规则和结构,针对不同的程序类型,需要考虑的输入数据结构和规则也会有所不同,如输入必须满足通信协议、格式、长度限制 等。
- 基于变异的模糊测试
-

4、应用领域
- 二进制的漏洞挖掘
- 模糊测试可以在二进制程序中产生随机输入并执行,发现程序中的漏洞,进而提高软件安全性。
- 网络协议的漏洞挖掘
- 模糊测试可以模拟各种网络数据包,产生随机数据对网络协议进行测试,发现协议的漏洞和异常情况,从而提高网络协议的安全性。
- Web应用的漏洞挖掘
- 模糊测试可以生成随机的HTTP请求和表单提交,发现Web应用程序的漏洞和错误。例如,SQL 注入、跨站脚本攻击和文件包含漏洞等。
- 操作系统和系统调用的漏洞挖掘
- 模糊测试可以在操作系统中模拟各种异常事件和输入(例如,系统调用、文件输入和设备驱动程序等),以检测操作系统和系统调用的漏洞和错误,提高操作系统的稳定性和安全性。
二、人工智能在模糊测试中的应用
1、人工智能技术
- 人工智能技术主要应用在模糊测试中的测试用例生成和筛选,涉及的技术主要是遗传算法和神经网络。
- 遗传算法:一种基于自然选择和遗传学理论的优化算法,它主要应用于解决优化问题。
- 神经网络:一种模拟生物神经系统的数学模型,可以通过学习和适应各种数据集来进行复杂的预测和分类任务。
- 测试用例生成
- 使用遗传算法中的适应度函数,通过某些标准(例如覆盖率或风险值)来评价每个测试用例的质量,然后修改测试用例并生成新的测试用例, 直到找到漏洞或达到覆盖率要求。
- 也可以使用循环神经网络 (RNN)和生成对抗网络 (GAN)来产生高质量的测试用例。
- 测试用例筛选
- 应用遗传算法从海量测试用例中筛选出能够触发漏洞或异常行为的有效测试用例, 从而使测试用例的数量减少至较少且更有代表性的用例集合,可以节省计算资源并提高模糊测试的效率。
- 也可以通过神经网络的分类模型,对测试用例进行筛选和分类,将其划分为不同的类别或者标记为异常情况,从而辅助质量测试人员在测试用例分析和维护时提供参考。
2、人工智能技术指导模糊测试过程
- 预测漏洞位置
- 通过对已知漏洞的分类和识别,预测、发现潜在的未知漏洞。主要通过使用神经网络等 技术提取目标程序特征,训练目标程序分析模型,并使用已知的漏洞样本进行模型优化,最后分析并预测程序中的漏洞位置。
- 测试用例生成
- 在模糊测试过程中,测试用例的生成通常是随机的。利用人工智能生成测试用例,可以提高测试用例的覆盖率和测试效果,也可以降低测试工作的人力成本和时间成本。
- 主要通过使用神经网络等技术提取目标程序特征(包括函数参数、函数 调用序列、变量名、API 调用序列等)。根据提取的特征,训练测试用例生成模型,使模型能够从大量的程序信息中学习有效地测试用例生成规律。最后根据输入数据生成具有代表性的测试用例。
- 测试用例筛选
- 在模糊测试过程中,利用人工智能筛选测试用例,可以过滤掉重复、无效或低优先级地测试用例,提高测试效率和测试覆盖率,降低测试工作的人力成本和时间成本。
- 主要通过使用神经网络等技术提取目标程序特征,训练测试用例筛选模型,使模型能够从大量的程序信息中学习有效地测试用例筛选规律。最后根据生成的特征和筛选模型等信息,对测试用例进行筛选和优化,筛选出具有更高覆盖率、更高可检测性的测试用例。
- 变异算子的选择
- 在模糊测试中,变异算子的选择对测试结果的质量和效率有着重要的影响。利用人工智能选择变异算子,可以更加深入地了解被测试的程序,使得变异后生成的测试用例能够覆盖更多的程序路径、更快地触发漏洞。
- 例如,在某些场景中可采取针对特定漏洞的变异算子以增加测试覆盖率。
- 漏洞分类和识别
- 在模糊测试过程中,利用人工智能分析测试结果,可以快速准确地定位检测结果中的漏洞或异常现象,进而有效地辅助漏洞挖掘和修复,提高程序的安全性和可靠性,同时也可以降低测试工作的人力成本和时间成本。
- 在应用过程中,可以使用神经网络来训练分析模型,分析模型可以根据不同的学习算法和特征提取技术,将结果划分为不同的类别,如内存泄漏、权限提升、代码注入等。