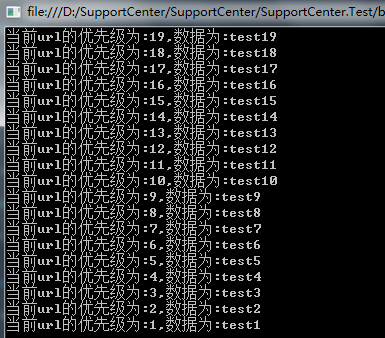
基于C#实现优先队列
一、堆结构
1.1性质
堆是一种很松散的序结构树,只保存了父节点和孩子节点的大小关系,并不规定左右孩子的大小,不像排序树那样严格,又因为堆是一种完全二叉树,设节点为 i,则 i/2 是 i 的父节点,2i 是 i 的左孩子,2i+1 是 i 的右孩子,所以在实现方式上可以采用轻量级的数组。

1.2用途
如果大家玩过微软的 MSMQ 的话,我们发现它其实也是一个优先队列,还有刚才说的抓取 url,不过很遗憾,为什么.net 类库中没有优先队列,而 java1.5 中就已经支持了。
1.3实现
<1> 堆结构节点定义:
我们在每个节点上定义一个level,表示该节点的优先级,也是构建堆时采取的依据。
/// <summary>
/// 定义一个数组来存放节点
/// </summary>
private List<HeapNode> nodeList = new List<HeapNode>();
#region 堆节点定义
/// <summary>
/// 堆节点定义
/// </summary>
public class HeapNode
{
/// <summary>
/// 实体数据
/// </summary>
public T t { get; set; }
/// <summary>
/// 优先级别 1-10个级别 (优先级别递增)
/// </summary>
public int level { get; set; }
public HeapNode(T t, int level)
{
this.t = t;
this.level = level;
}
public HeapNode() { }
}
#endregion
<2> 入队操作
入队操作时我们要注意几个问题:
①:完全二叉树的构建操作是“从上到下,从左到右”的形式,所以入队的节点是放在数组的最后,也就是树中叶子层的有序最右边空位。
②:当节点插入到最后时,有可能破坏了堆的性质,此时我们要进行“上滤操作”,当然时间复杂度为 O(lgN)。
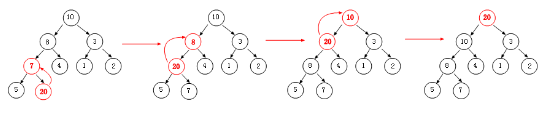
当我将节点“20”插入到堆尾的时候,此时破坏了堆的性质,从图中我们可以清楚的看到节点“20”的整个上滤过程,有意思吧,还有一点就是:获取插入节点的父亲节点的算法是:parent=list.count/2-1。这也得益于完全二叉树的特性。
#region 添加操作
/// <summary>
/// 添加操作
/// </summary>
public void Eequeue(T t, int level = 1)
{
//将当前节点追加到堆尾
nodeList.Add(new HeapNode(t, level));
//如果只有一个节点,则不需要进行筛操作
if (nodeList.Count == 1)
return;
//获取最后一个非叶子节点
int parent = nodeList.Count / 2 - 1;
//堆调整
UpHeapAdjust(nodeList, parent);
}
#endregion
#region 对堆进行上滤操作,使得满足堆性质
/// <summary>
/// 对堆进行上滤操作,使得满足堆性质
/// </summary>
/// <param name="nodeList"></param>
/// <param name="index">非叶子节点的之后指针(这里要注意:我们
/// 的筛操作时针对非叶节点的)
/// </param>
public void UpHeapAdjust(List<HeapNode> nodeList, int parent)
{
while (parent >= 0)
{
//当前index节点的左孩子
var left = 2 * parent + 1;
//当前index节点的右孩子
var right = left + 1;
//parent子节点中最大的孩子节点,方便于parent进行比较
//默认为left节点
var max = left;
//判断当前节点是否有右孩子
if (right < nodeList.Count)
{
//判断parent要比较的最大子节点
max = nodeList[left].level < nodeList[right].level ? right : left;
}
//如果parent节点小于它的某个子节点的话,此时筛操作
if (nodeList[parent].level < nodeList[max].level)
{
//子节点和父节点进行交换操作
var temp = nodeList[parent];
nodeList[parent] = nodeList[max];
nodeList[max] = temp;
//继续进行更上一层的过滤
parent = (int)Math.Ceiling(parent / 2d) - 1;
}
else
{
break;
}
}
}
#endregion
<3> 出队操作
从图中我们可以看出,优先级最大的节点会在一阵痉挛后上升到堆顶,出队操作时,我们采取的方案是:弹出堆顶元素,然后将叶子层中的最右子节点赋给堆顶,同样这时也会可能存在破坏堆的性质,最后我们要被迫进行下滤操作。
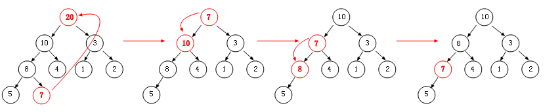
我图中可以看出:首先将堆顶 20 弹出,然后将 7 赋给堆顶,此时堆性质遭到破坏,最后我们清楚的看到节点 7 的下滤过程,从摊还分析的角度上来说,下滤的层数不超过 2-3 层,所以整体上来说出队的时间复杂度为一个常量 O(1)。
#region 优先队列的出队操作
/// <summary>
/// 优先队列的出队操作
/// </summary>
/// <returns></returns>
public HeapNode Dequeue()
{
if (nodeList.Count == 0)
return null;
//出队列操作,弹出数据头元素
var pop = nodeList[0];
//用尾元素填充头元素
nodeList[0] = nodeList[nodeList.Count - 1];
//删除尾节点
nodeList.RemoveAt(nodeList.Count - 1);
//然后从根节点下滤堆
DownHeapAdjust(nodeList, 0);
return pop;
}
#endregion
#region 对堆进行下滤操作,使得满足堆性质
/// <summary>
/// 对堆进行下滤操作,使得满足堆性质
/// </summary>
/// <param name="nodeList"></param>
/// <param name="index">非叶子节点的之后指针(这里要注意:我们
/// 的筛操作时针对非叶节点的)
/// </param>
public void DownHeapAdjust(List<HeapNode> nodeList, int parent)
{
while (2 * parent + 1 < nodeList.Count)
{
//当前index节点的左孩子
var left = 2 * parent + 1;
//当前index节点的右孩子
var right = left + 1;
//parent子节点中最大的孩子节点,方便于parent进行比较
//默认为left节点
var max = left;
//判断当前节点是否有右孩子
if (right < nodeList.Count)
{
//判断parent要比较的最大子节点
max = nodeList[left].level < nodeList[right].level ? right : left;
}
//如果parent节点小于它的某个子节点的话,此时筛操作
if (nodeList[parent].level < nodeList[max].level)
{
//子节点和父节点进行交换操作
var temp = nodeList[parent];
nodeList[parent] = nodeList[max];
nodeList[max] = temp;
//继续进行更下一层的过滤
parent = max;
}
else
{
break;
}
}
}
#endregion