Elasticsearch:向量搜索 (kNN) 实施指南 - API 版
作者:Jeff Vestal

本指南重点介绍通过 HTTP 或 Python 使用 Elasticsearch API 设置 Elasticsearch 以进行近似 k 最近邻 (kNN) 搜索。
对于主要使用 Kibana 或希望通过 UI 进行测试的用户,请访问使用 Elastic 爬虫的语义搜索入门指南。你也可以参考文章 “ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据(二)”。
如果你想切入主题并在 Jupyter Notebook 中运行一些代码,我们可以为你提供随附的 notebook。
Elastic Learned Sparse Encoder
如果你使用的文本是英文文本,请考虑使用 Elastic Learned Sparse Encoder。
Elastic Learned Sparse EncodeR(或 ELSER)是由 Elastic 训练的 NLP 模型,使你能够使用稀疏向量表示来执行语义搜索。 语义搜索不是根据搜索词进行字面匹配,而是根据搜索查询的意图和上下文含义来检索结果。
否则,请继续阅读下文,了解有关使用近似 kNN 搜索进行语义向量搜索的信息。
高层架构
在 Elastic 中实现向量搜索有四个关键组件:
- 嵌入模型:机器学习模型,将数据作为输入并返回数据的数字表示(向量,也称为 “嵌入(embedding)”)
- 推理端点:将机器学习模型应用于文本数据的 Elastic Inference API 或 Elastic Inference 管道处理器。 当你提取数据和对数据执行查询时,你都可以使用推理端点。 **注意:**对于非文本数据(例如图像文件),请在你的 ML 模型中使用外部脚本,以便生成你将在 Elastic 中存储和使用的嵌入。
- 搜索:Elastic 将嵌入与元数据一起存储在其索引中,然后执行(近似)k 最近邻搜索以查找查询与数据最接近的匹配项(在向量空间中,也称为“嵌入空间”)
- 应用程序逻辑:你的应用程序在核心向量搜索之外所需的一切,例如与用户通信或应用你的业务逻辑。

集群注意事项
集群大小估计
内存注意事项
为了提高性能,向量需要 “适合” 数据节点上的堆外 RAM。 从 Elasticsearch 版本 8.7+ 开始,向量所需的粗略估计为
NumVectors×4×(NumDimensions+12)注意:该公式适用于 float 类型向量。
使用 20,000 个向量字段的快速示例(我们假设每个文档有 1 个向量):
20,000,000×4×(768+12)≈115 GB of RAM off heap注意:添加的每个副本都需要相同数量的额外 RAM(例如,对于上面的示例,1 个主副本和 1 个副本,我们估计需要 2 倍的 RAM,即 130GB)。
性能测试
由于每个用户的数据都不同,估计 RAM 需求的最佳方法是通过测试。 我们建议从单个节点、单个主分片、无副本开始,然后进行测试,以找出在性能下降之前有多少向量 “适合” 节点。
实现这一目标的一种方法是使用 Elastic 的基准测试工具 Rally。
如果所有向量都相当小(例如,64GB 节点上的 3GB),你可以简单地加载向量并一次性开始测试。
使用上面的估计公式,将向量数量的 75% 加载到单个节点中,运行挑战,并评估响应时间指标。 逐渐增加向量计数,重新运行测试,直到性能下降到可接受的水平以下。 响应时间可接受的最大计数通常可以被认为是单个节点的向量数量。 从那里你可以横向扩展节点和副本。
Jupyter Notebook Code

下面的所有代码都可以在 python Jupyter Notebook 中找到 该代码可以完全从浏览器中运行,使用 Google Colab,以便使用随附的 notebook 进行快速设置和测试
集群配置
每个字段单个向量与每个字段多个向量
向量布局的标准方法是每个字段一个向量。 这就是我们下面将遵循的方法。 但是,从 8.11 开始,Elasticsearch 支持嵌套向量,允许每个字段使用多个向量。 有关设置该方法的信息,请查看 Elasticsearch Labs 博客 “通过摄取管道对大型文档进行分块加上嵌套向量等于简单的段落搜索”。
加载嵌入模型
嵌入模型在机器学习节点上运行。 确保你部署了一个或多个 ML 节点。
要将嵌入模型加载到 Elasticsearch 中,你需要使用 Eland。 Eland 是一个 Python Elasticsearch 客户端,用于使用熟悉的 Pandas 兼容 API 探索和分析 Elasticsearch 中的数据。
- 你可以使用 Docker 从 Hugging Face 快速加载模型。
- 吗还可以在 Colab 中使用 jupyter 笔记本快速加载模型(后续“部署NLP模型”)
- 对于无法直接连接到 Hugging Face 的环境,请按照文档在气隙环境中使用 Eland 加载嵌入模型中概述的步骤操作
摄取管道设置
有多种方法可以生成新文档的嵌入。 最简单的方法是创建摄取管道并配置针对索引的数据,以自动使用管道通过推理处理器调用模型。
在下面的示例中,我们将创建一个带有一个处理器(推理处理器)的管道。 该处理器将:
- 将我们要为其创建嵌入的字段 my_text 映射到嵌入模型在本例中期望的名称 text_field
- 通过 model_id 配置要使用的模型。 这是 Elasticsearch 中模型的名称
- 监控可能出现错误时进行处理。
PUT _ingest/pipeline/vector_embedding_demo
{
"processors": [
{
"inference": {
"field_map": {
"my_text": "text_field"
},
"model_id": "sentence-transformers__all-distilroberta-v1",
"target_field": "ml.inference.my_vector",
"on_failure": [
{
"append": {
"field": "_source._ingest.inference_errors",
"value": [
{
"message": "Processor 'inference' in pipeline 'ml-inference-title-vector' failed with message '{{ _ingest.on_failure_message }}'",
"pipeline": "ml-inference-title-vector",
"timestamp": "{{{ _ingest.timestamp }}}"
}
]
}
}
]
}
},
{
"set": {
"field": "my_vector",
"if": "ctx?.ml?.inference != null && ctx.ml.inference['my_vector'] != null",
"copy_from": "ml.inference.my_vector.predicted_value",
"description": "Copy the predicted_value to 'my_vector'"
}
},
{
"remove": {
"field": "ml.inference.my_vector",
"ignore_missing": true
}
}
]
}索引映射/模板设置
嵌入(向量)存储在 Elasticsearch 中的密集向量字段类型中。 接下来,我们将在索引文档和生成嵌入之前配置索引模板。
下面的 API 调用将创建一个索引模板来匹配具有 my_vector_index-* 模式的任何索引
它会:
- 如文档中所述,为 my_vector 配置密集向量。
- 建议从 _source 中排除向量字段
- 我们还将在本示例中包含一个文本字段 my_text,它将作为生成嵌入的源。
PUT /_index_template/my_vector_index
{
"index_patterns": [
"my_vector_index-*"
],
"priority": 1,
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.default_pipeline": "vector_embedding_demo"
},
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "dot_product"
},
"my_text": {
"type": "text"
}
},
"_source": {
"excludes": [
"my_vector"
]
}
}
}
}索引数据
有多种方法可以将数据索引到 Elasticsearch 中。 下面的示例显示了要索引到示例索引中的一组快速测试文档。 当推理处理器对嵌入模型进行内部 API 调用时,嵌入将由摄取管道在摄取中生成。
POST my_vector_index-01/_bulk?refresh=true
{"index": {}}
{"my_text": "Hey, careful, man, there's a beverage here!", "my_metadata": "The Dude"}
{"index": {}}
{"my_text": "I’m The Dude. So, that’s what you call me. You know, that or, uh, His Dudeness, or, uh, Duder, or El Duderino, if you’re not into the whole brevity thing", "my_metadata": "The Dude"}
{"index": {}}
{"my_text": "You don't go out looking for a job dressed like that? On a weekday?", "my_metadata": "The Big Lebowski"}
{"index": {}}
{"my_text": "What do you mean brought it bowling, Dude? ", "my_metadata": "Walter Sobchak"}
{"index": {}}
{"my_text": "Donny was a good bowler, and a good man. He was one of us. He was a man who loved the outdoors... and bowling, and as a surfer he explored the beaches of Southern California, from La Jolla to Leo Carrillo and... up to... Pismo", "my_metadata": "Walter Sobchak"}查询数据
Approximate k-nearest neighbor
GET my_vector_index-01/_search
{
"knn": [
{
"field": "my_vector",
"k": 1,
"num_candidates": 5,
"query_vector_builder": {
"text_embedding": {
"model_id": "sentence-transformers__all-distilroberta-v1",
"model_text": "Watchout I have a drink"
}
}
}
]
}具有倒数排名融合技术预览的混合搜索(kNN + BM25)
GET my_vector_index-01/_search
{
"size": 2,
"query": {
"match": {
"my_text": "bowling"
}
},
"knn":{
"field": "my_vector",
"k": 3,
"num_candidates": 5,
"query_vector_builder": {
"text_embedding": {
"model_id": "sentence-transformers__all-distilroberta-v1",
"model_text": "He enjoyed the game"
}
}
},
"rank": {
"rrf": {}
}
}Filtering
GET my_vector_index-01/_search
{
"knn": {
"field": "my_vector",
"k": 1,
"num_candidates": 5,
"query_vector_builder": {
"text_embedding": {
"model_id": "sentence-transformers__all-distilroberta-v1",
"model_text": "Did you bring the dog?"
}
},
"filter": {
"term": {
"my_metadata": "The Dude"
}
}
}
}返回选择字段的聚合
GET my_vector_index-01/_search
{
"knn": {
"field": "my_vector",
"k": 2,
"num_candidates": 5,
"query_vector_builder": {
"text_embedding": {
"model_id": "sentence-transformers__all-distilroberta-v1",
"model_text": "did you bring it?"
}
}
},
"aggs": {
"metadata": {
"terms": {
"field": "my_metadata"
}
}
},
"fields": [
"my_text",
"my_metadata"
],
"_source": false
}kNN 调整选项
调整近似 kNN 搜索文档中介绍了调整选项的概述
搜索的计算成本:向量数量的对数,前提是它们通过 HNSW 进行索引。 dot_product 相似度的维数略好于线性。
_search
调整近似 kNN 以提高速度或准确性文档
距离度量的选择
- 只要有可能,我们建议在将向量搜索部署到生产环境时使用 dot_product 而不是余弦相似度。 使用点积可以避免每次相似性计算时都必须计算向量幅度(因为向量已提前归一化为全部幅度为 1)。 这意味着它可以将搜索和索引速度提高约 2-3 倍。
- 也就是说,consine 在文本应用程序中很受欢迎:查询的长度通常比摄取的文档短得多,因此与原始文档的距离对相似性的测量没有有意义的贡献。 请记住,余弦每个元组需要 6 次运算,而点积每个维度只需要两次(将每个元素相乘,然后求和)。 因此,我们建议仅将余弦用于测试/探索,并在投入生产时切换到点积(通过归一化,点积毕竟会计算余弦)。
- 在所有其他用例中首先尝试 dot_product - 因为它的执行速度比 L2 规范(标准欧几里得)快得多。
Ingest
Indexing considerations Docs
索引新数据
除非你生成自己的嵌入,否则你必须在摄取新数据时生成嵌入。 对于文本,这是通过带有调用托管嵌入模型的推理处理器的摄取管道来完成的。 请注意,这需要白金许可证。
添加更多数据也会增加 RAM - 因为你需要将所有向量保留在堆外(而传统搜索则需要在磁盘上)
精确 kNN 搜索
又名强力(brute force)或脚本分数
精确 kNN 搜索文档
不要假设你需要 ANN,因为某些用例无需 ANN 也能正常工作。 根据经验,如果你实际排名的文档数量(即应用过滤器后)低于 10k,那么使用强力选项可能会更好。
在本地环境中运行 jupyter notebook
在很多情况下,我们在本地电脑里来运行上面的练习。我们可以按照如下的步骤来进行:
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
特别注意的是:我们将以最新的 Elastic Stack 8.6.1 来进行展示。请参考 Elastic Stack 8.x 的文章进行安装。
启动白金版试用功能
由于上传模型是一个白金版的功能,我们需要启动试用功能。更多关于订阅的信息,请参考网址:订阅 | Elastic Stack 产品和支持 | Elastic。
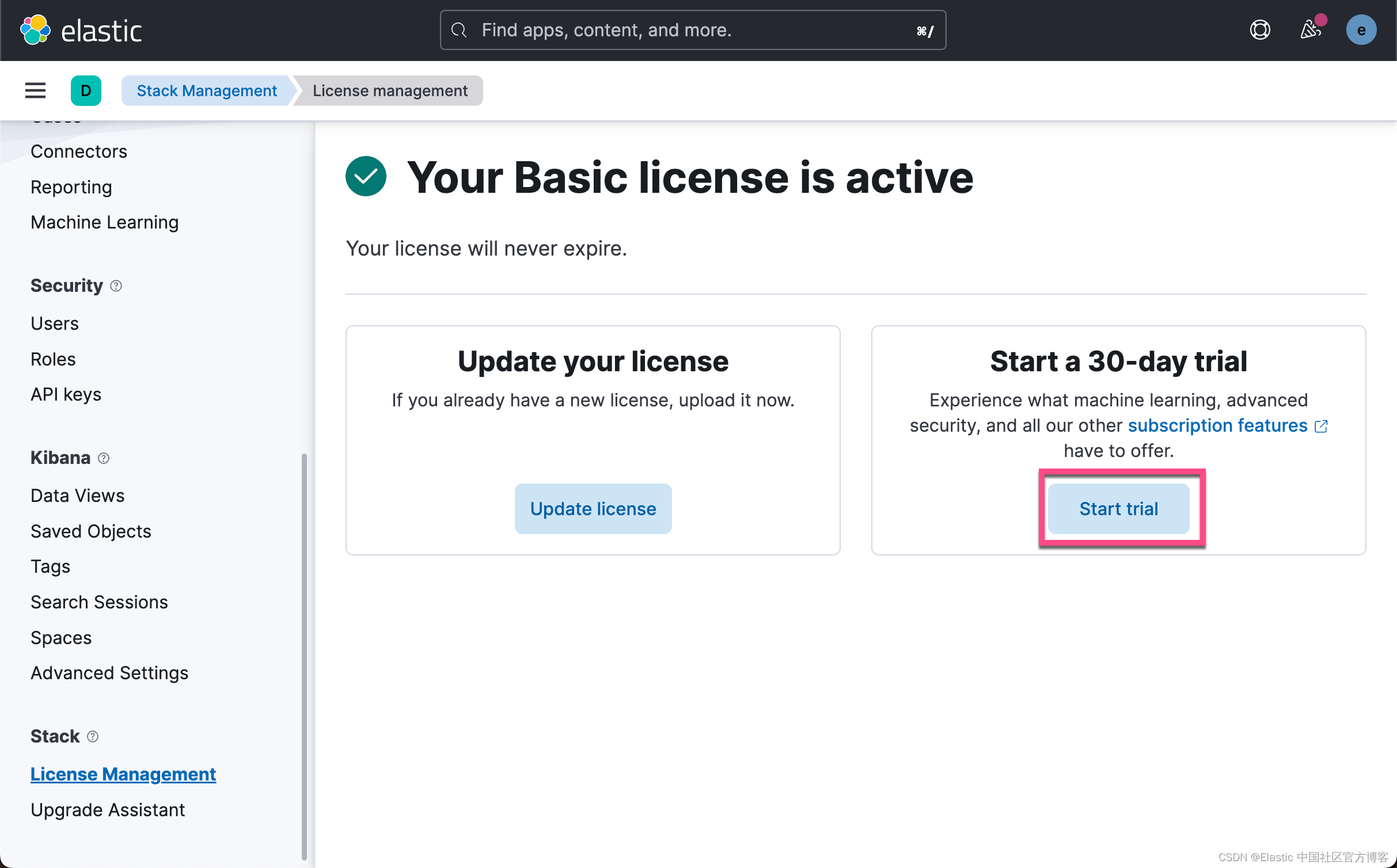
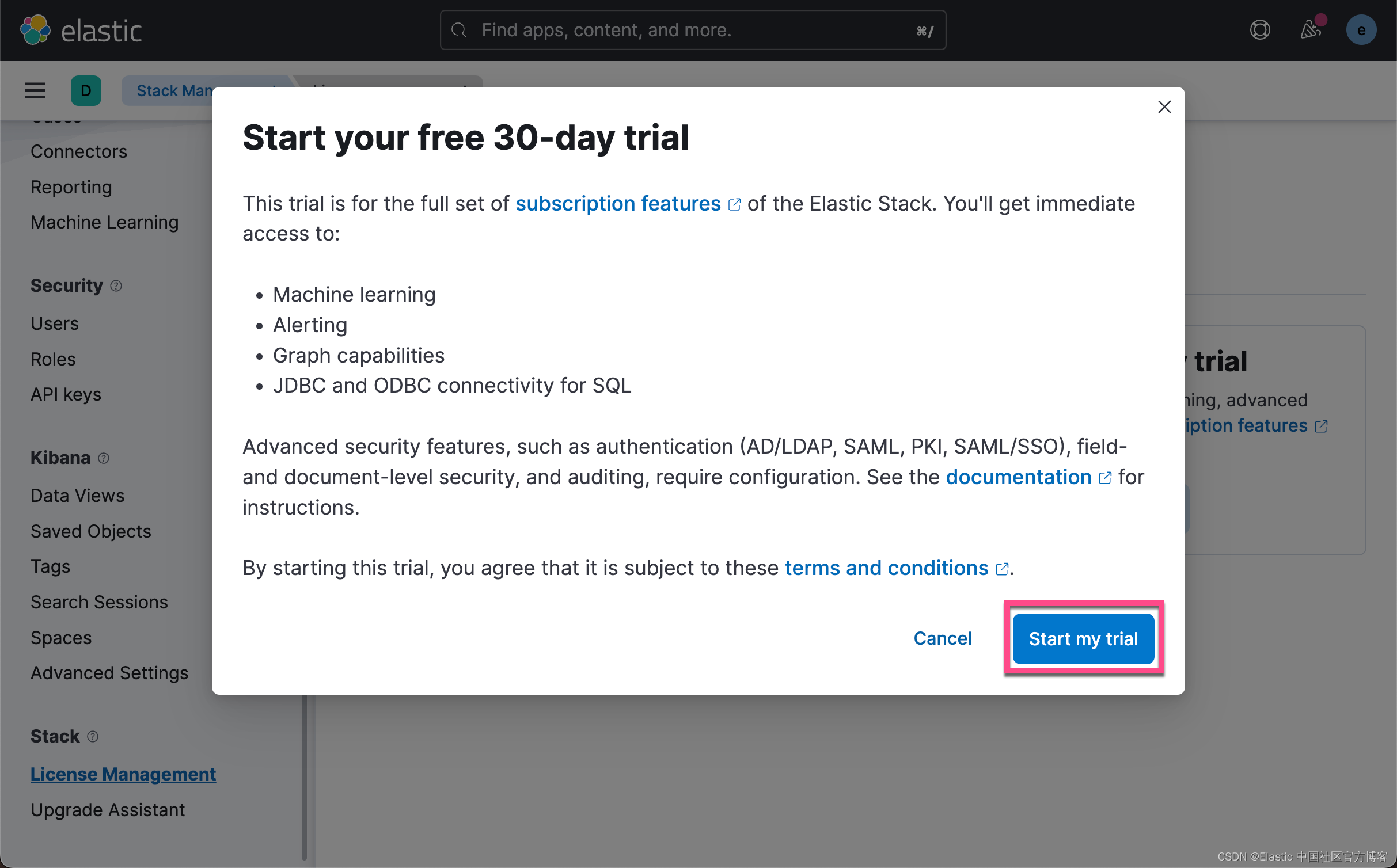
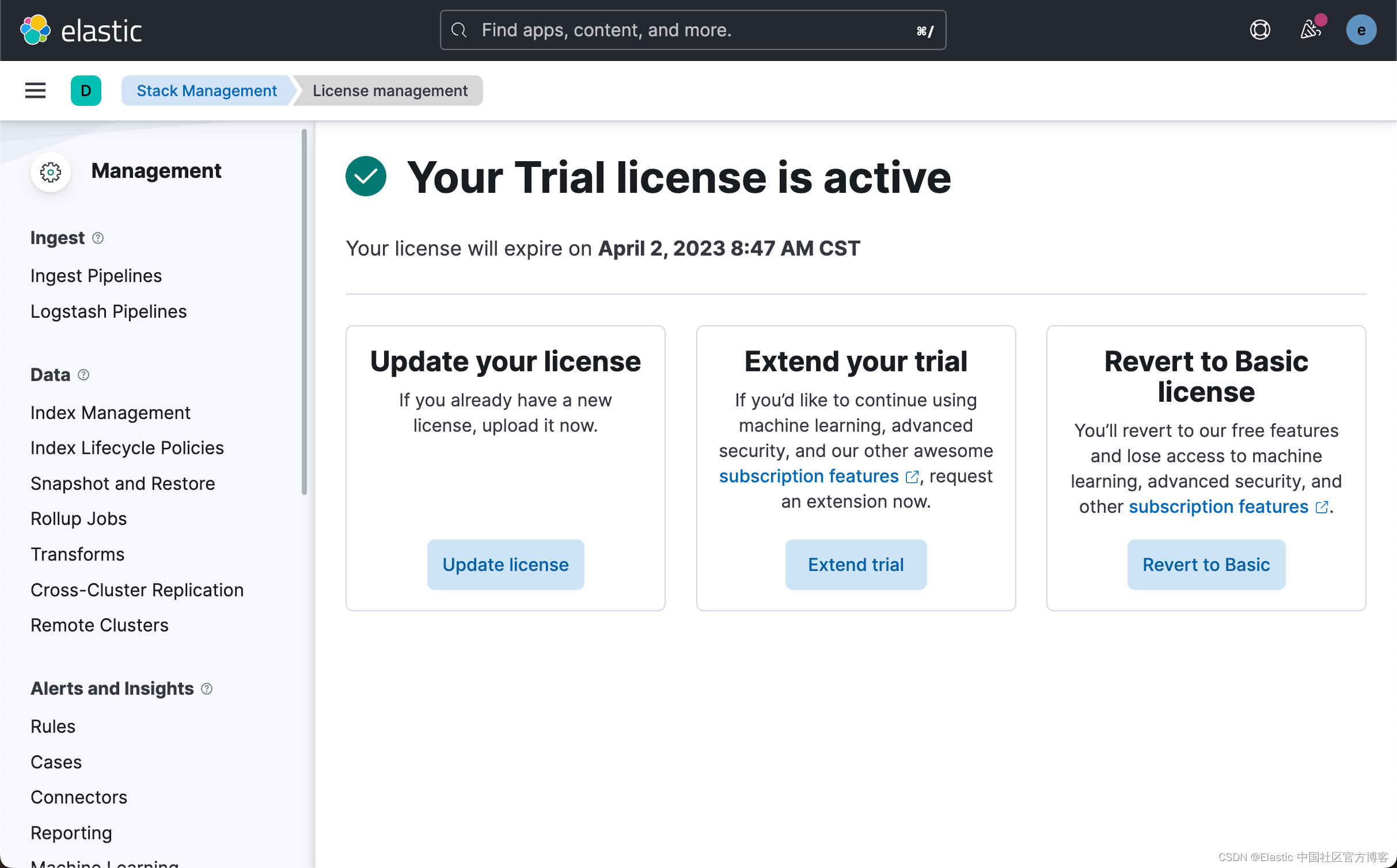
这样我们就成功地启动了白金版试用功能。
上传模型
我们使用如下的命令来安装 eland:
pip3 install eland
pip3 install -q elasticsearch eland[pytorch]
然后,我们使用如下的命令来上传所需要的模型:
eland_import_hub_model --url https://elastic:o6G_pvRL=8P*7on+o6XH@localhost:9200 \
--hub-model-id sentence-transformers/all-distilroberta-v1 \
--task-type text_embedding \
--ca-certs /Users/liuxg/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt \
--start
在上面,我们需要根据自己的安装:
- 修改上面的 elastic 超级用户的密码
- 修改上面的证书路径
完成上面的命令后,我们可以在 Kibana 中看到:
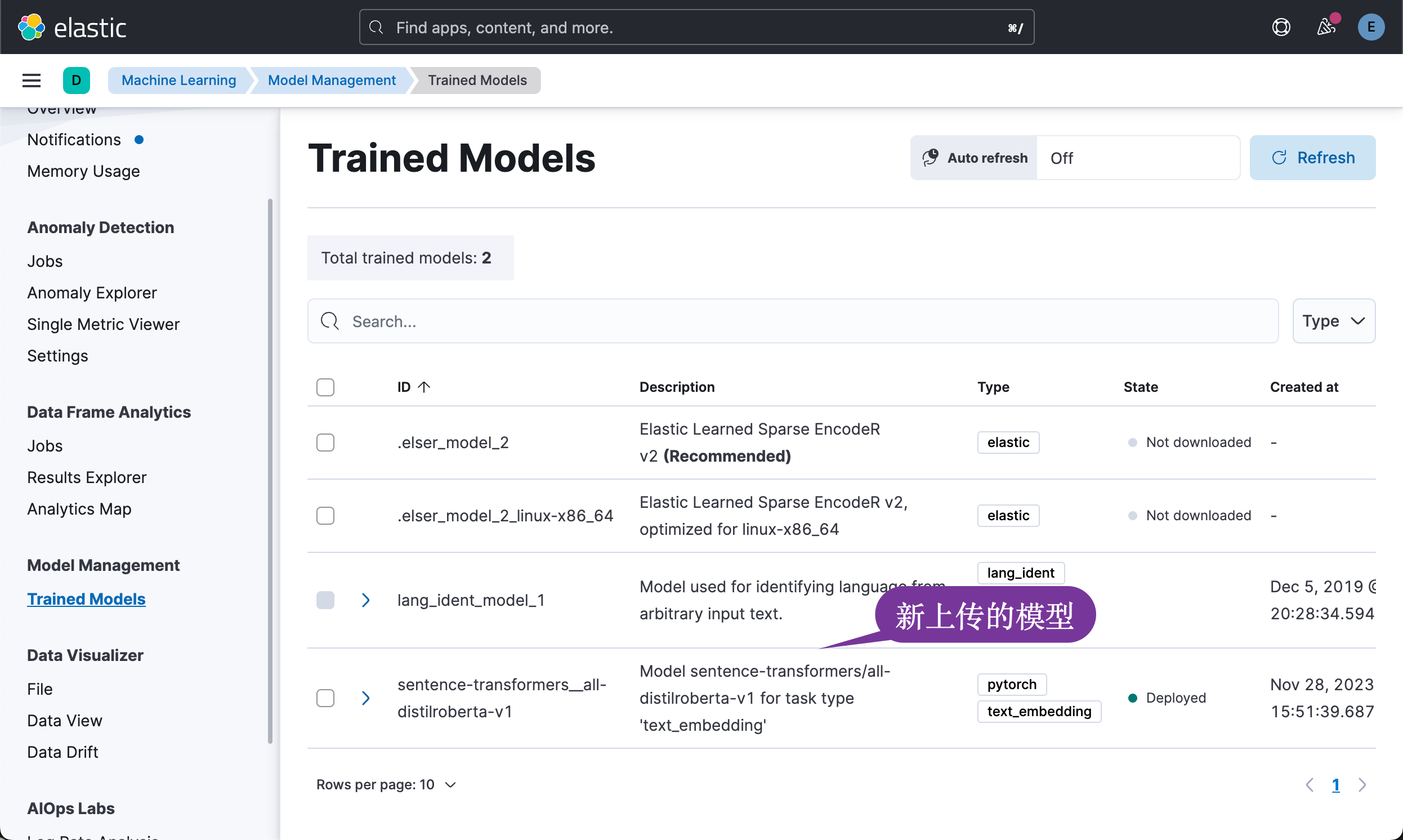
运行 Notebook
我们把 Elasticsearch 的证书拷贝到当前的项目根目录下:
cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .我们使用 jupyter notebook 来创建一个叫做 vector_search_implementation_guide_api.ipynb 的 notebook。你可以发现整个 notebook。
原文:Vector Search (kNN) Implementation Guide - API Edition — Elastic Search Labs