CTA-GAN:基于生成对抗性网络的主动脉和颈动脉非集中CT血管造影 CT到增强CT的合成技术
Generative Adversarial Network–based Noncontrast CT Angiography for Aorta and Carotid Arteries
- 基于生成对抗性网络的主动脉和颈动脉非集中CT血管造影
- 背景
- 贡献
- 实验
- 方法
- 损失函数
- Thinking
基于生成对抗性网络的主动脉和颈动脉非集中CT血管造影
https://github.com/ying-fu/CTA-GAN
Radiology 2023
背景
碘造影剂(ICAs)广泛用于CT血管造影术(CTA),可能会对人体产生不良影响,而且使用耗时且成本高昂。研究用平扫CT合成造影剂CT并评价生成的效果很有意义。CTA——Syn-CTA
- 难点:传统的深度学习模型不能充分解决成对未对准图像的映射翻译问题。此外,先前的医学图像翻译研究集中在单个解剖位置,而临床诊断经常在多个位置进行(14,15)。
贡献
- 本文:开发一种基于生成对抗性网络(GAN)的CTA成像模型(16-21),以合成独立于ICAs的高质量CTA样图像,并评估使用这些合成CTA(Syn-CTA)图像辅助临床诊断的可行性。使用内部和外部测试数据从定量指标、视觉质量和血管疾病诊断准确性方面评估Syn-CTA图像
实验
- 数据集:收集了17-22年颈部和腹部的成对的CT和CTA图像,1749名患者,1137训练,400验证,212测试,外部验证42名。
- 数据处理:每个NCCT和CTA扫描被重采样到0.67x0.67x1.25的体积中,由75-490各切片组成,512x512分辨率,CTA造影剂浓度370mg/ml,注射速率4.5ml/s,将-2000-2095的像素值标准化到-1-1,排除手动检查后图像质量较差的扫描。
- Patient Characteristics(患者特征),在1833名符合条件的患者中,84名图像质量较差的患者被排除在外,1749名患者(中位年龄,60岁[IQR,50-68岁];1057名[60.4%]男性患者和692名[39.6%]女性患者)被纳入分析。1137名患者的CT扫描用于模型训练;来自400名患者的扫描用于模型开发验证;212名患者的扫描用于模型测试(图1)。外部独立验证集包括42名患者(中位年龄67岁[IQR,59–74岁];37名[88.1%]男性患者和5名[11.9%]女性患者)。
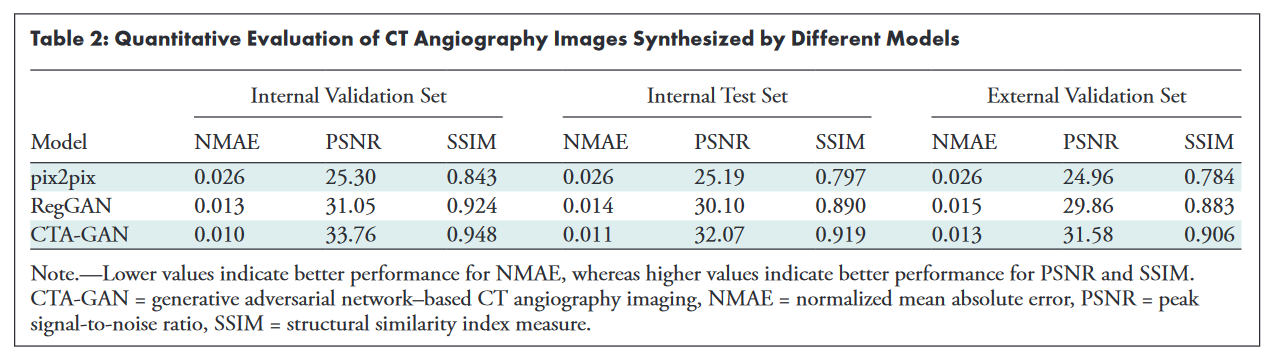
- 评估方法:Quantitative Evaluation(定量评价),正态平均绝对误差(NMAE)、峰值信噪比(PSNR)、结构相似性指数测量(SSIM)
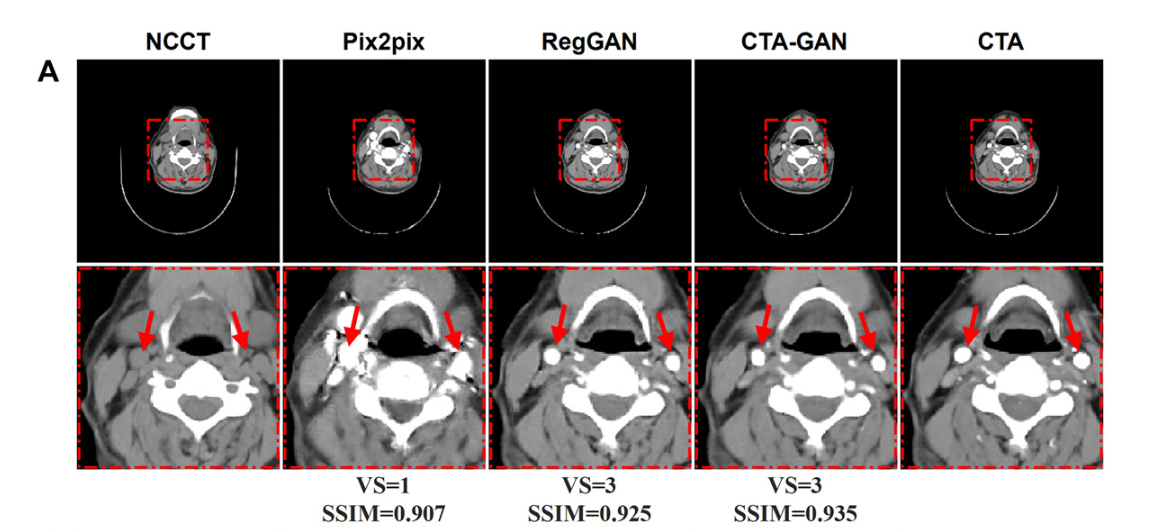
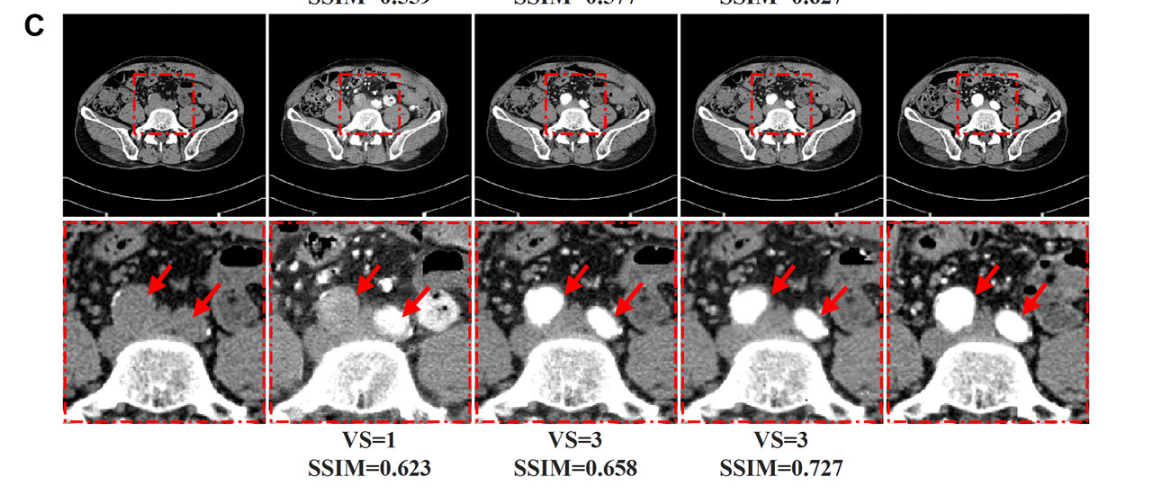
- Visual Quality Evaluation(视觉质量评估),具有10年经验的专家,独立评估了CTA和Syn-CTA图像的图像质量。任何分歧都通过协商一致的方式解决。放射科医生使用主观三点量表(视觉质量评分)(25,26)评估Syn-CTA和真实CTA扫描的图像质量1、质量差;2、质量合格;3、质量好;具体而言,图像质量评估包括血管壁清晰度、管腔边缘清晰度和管腔壁对比度(附录S1,图S1)。
- Diagnostic Evaluation(诊断评估),对每次扫描的Syn-CTA图像和真实CTA图像进行匿名化,然后将其随机并按序列号呈现给进行独立阅读视觉质量评估的同两名放射科医生。基于每次扫描的血管诊断(动脉瘤、夹层、动脉粥样硬化或健康动脉)由两名放射科医生确定。通过一致阅读解决任何诊断分歧(附录S1)。从真实的CTA图像中读取的血管诊断被视为基本事实。
人工评价:Syn-CTA测试集中的高质量分数(分数=3)的比率均大于90%,高质量分数的总体比率为95%
方法
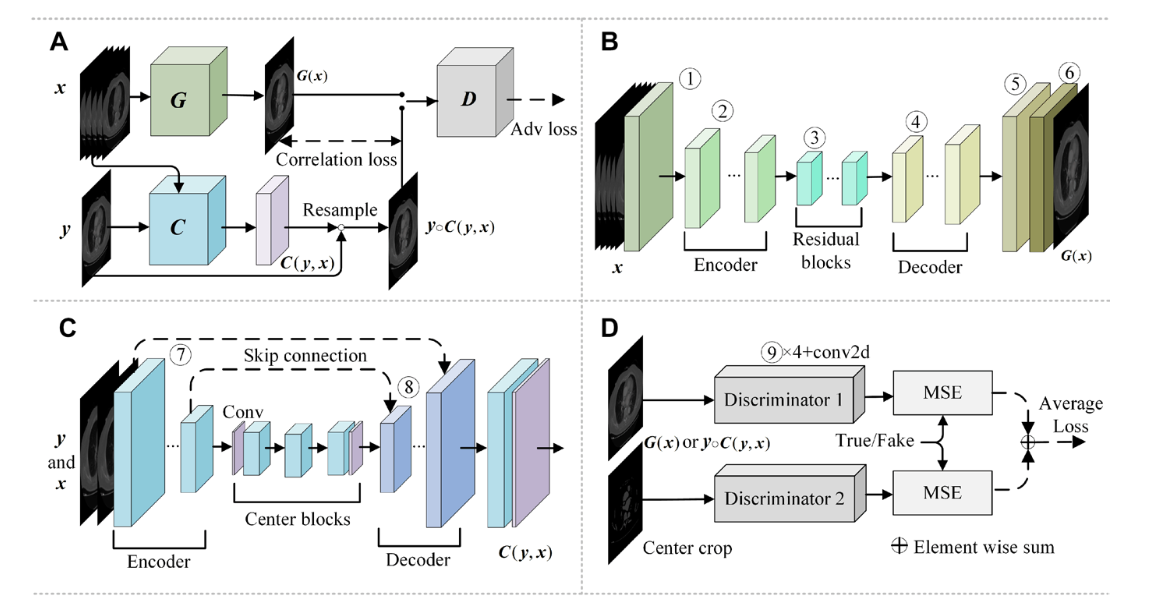
论文中对方法描述不多,以下是从源代码中简化的训练步骤伪代码
# real_A2是CT,real_B2是Syn_CTA,
# NetG_A2B是生成器,R_A是校准器,spatial_transform是进行采样的一个配准场不是模型,
# netD_B是判别器,target_real = Variable(Tensor(1,1).fill_(1.0), requires_grad=False),
# target_fake = Variable(Tensor(1,1).fill_(0.0), requires_grad=False
optimizer_R_A.zero_grad()
optimizer_G.zero_grad() # 只更新生成器和校准器
fake_B = netG_A2B(real_A2) # CT生成的Syn_CTA,fake_B
Trans = R_A(fake_B, real_B2) # fake_B和real_B校准得到Trans
SysRegist_A2B = spatial_transform(fake_B, Trans) # fake_B和Trans,配准得到,SysRegist_A2B
pred_fake0 = netD_B(fake_B) # fake_B输入到判别器得到pred_fake0
SM_loss = smoothing_loss(Trans)
SR_loss = L1_loss(SysRegist_A2B, real_B2) # 配准后的生成图和real_B要长得像
adv_loss = MSE_loss(pred_fake0, target_real) # 对抗,fake_B的pred_fake0和1的MSEloss
loss = SM_loss + SR_loss + adv_loss # 总损失
loss.backward() # 梯度回传
optimizer_R_A.step() # 更新R_A和G
optimizer_G.step()
optimizer_D_B.zero_grad() # 只更新判别器
with torch.no_grad():
fake_B = netG_A2B(real_A2) # 生成器不更新权重
pred_fake0 = netD_B(fake_B) # 再算一次pred_fake0
real_BB2 = copy.deepcopy(real_B2)
pred_real = netD_B(real_BB2) # 判别real_B得到pred_real
loss_D_B = MSE_loss(pred_fake0, target_fake) # 对抗,pred_fake0和0,pred_real和1
+ MSE_loss(pred_real, target_real)
loss_D_B.backward()
optimizer_D_B.step() # 更新判别器
损失函数
配准后的图像和源图像的L1 loss,对抗loss
Thinking
输入是未配准的成对CT-SynCTA影像,先用CT影像生成SynCTA影像,再对SynCTA影像进行配准,再通过判别器,判别生成的影像和原始SynCTA影像。最终合成配准了的SynCTA影像。