Java核心知识点整理大全26-笔记
目录
27. Storm
7.1.1. 概念
27.1.1. 集群架构
27.1.1.1. Nimbus(master-代码分发给 Supervisor)
27.1.1.2. Supervisor(slave-管理 Worker 进程的启动和终止)
27.1.1.3. Worker(具体处理组件逻辑的进程)
27.1.1.4. Task
27.1.1.5. ZooKeeper
27.1.2. 编程模型(spout->tuple->bolt)
27.1.2.1. Topology
27.1.2.2. Spout
27.1.2.3. Bolt
27.1.2.4. Tuple
27.1.2.5. Stream
27.1.3. Topology 运行
27.1.3.1. Worker(1 个 worker 进程执行的是 1 个 topology 的子集)
27.1.3.2. Executor(executor 是 1 个被 worker 进程启动的单独线程)
27.1.3.3. Task(最终运行 spout 或 bolt 中代码的单元)
27.1.4. Storm Streaming Grouping
27.1.4.1. huffle Grouping
27.1.4.2. Fields Grouping
27.1.4.3. All grouping :广播
27.1.4.4. Global grouping
27.1.4.5. None grouping :不分组
27.1.4.6. Direct grouping :直接分组 指定分组
28. YARN
28.1.1. 概念
28.1.2. ResourceManager
28.1.3. NodeManager
28.1.4. ApplicationMaster
28.1.5.YARN 运行流程
29. 机器学习
Java核心知识点整理大全24-笔记-CSDN博客
往期快速传送门👆(在文章最后):
27. Storm
7.1.1. 概念
Storm 是一个免费并开源的分布式实时计算系统。利用 Storm 可以很容易做到可靠地处理无限的 数据流,像 Hadoop 批量处理大数据一样,Storm 可以实时处理数据。
27.1.1. 集群架构

27.1.1.1. Nimbus(master-代码分发给 Supervisor)
Storm 集群的 Master 节点,负责分发用户代码,指派给具体的 Supervisor 节点上的 Worker 节 点,去运行 Topology 对应的组件(Spout/Bolt)的 Task。
27.1.1.2. Supervisor(slave-管理 Worker 进程的启动和终止)
Storm 集群的从节点,负责管理运行在 Supervisor 节点上的每一个 Worker 进程的启动和终止。 通过 Storm 的配置文件中的 supervisor.slots.ports 配置项,可以指定在一个 Supervisor 上最大 允许多少个 Slot,每个 Slot 通过端口号来唯一标识,一个端口号对应一个 Worker 进程(如果该 Worker 进程被启动)。
27.1.1.3. Worker(具体处理组件逻辑的进程)
运行具体处理组件逻辑的进程。Worker 运行的任务类型只有两种,一种是 Spout 任务,一种是 Bolt 任务。
27.1.1.4. Task
worker中每一个spout/bolt的线程称为一个task. 在storm0.8 之后,task不再与物理线程对应, 不同 spout/bolt 的 task 可能会共享一个物理线程,该线程称为 executor。
27.1.1.5. ZooKeeper
用来协调 Nimbus 和 Supervisor,如果 Supervisor 因故障出现问题而无法运行 Topology, Nimbus 会第一时间感知到,并重新分配 Topology 到其它可用的 Supervisor 上运行
27.1.2. 编程模型(spout->tuple->bolt)
strom 在运行中可分为 spout 与 bolt 两个组件,其中,数据源从 spout 开始,数据以 tuple 的方 式发送到 bolt,多个 bolt 可以串连起来,一个 bolt 也可以接入多个 spot/bolt.运行时原理如下图:
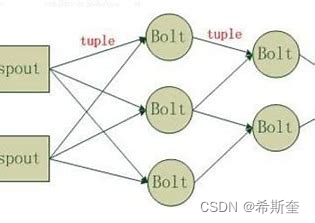
27.1.2.1. Topology
Storm 中运行的一个实时应用程序的名称。将 Spout、 Bolt 整合起来的拓扑图。定义了 Spout 和 Bolt 的结合关系、并发数量、配置等等
27.1.2.2. Spout
在一个 topology 中获取源数据流的组件。通常情况下 spout 会从外部数据源中读取数据,然后转 换为 topology 内部的源数据。
27.1.2.3. Bolt
接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
27.1.2.4. Tuple
一次消息传递的基本单元,理解为一组消息就是一个 Tuple。
27.1.2.5. Stream
Tuple 的集合。表示数据的流向。
27.1.3. Topology 运行
在 Storm 中,一个实时应用的计算任务被打包作为 Topology 发布,这同 Hadoop MapReduce 任务相似。但是有一点不同的是:在 Hadoop 中,MapReduce 任务最终会执行完成后结束;而在 Storm 中,Topology 任务一旦提交后永远不会结束,除非你显示去停止任务。计算任务 Topology 是由不同的 Spouts 和 Bolts,通过数据流(Stream)连接起来的图。一个 Storm 在集 群上运行一个 Topology 时,主要通过以下 3 个实体来完成 Topology 的执行工作:
(1). Worker(进程)
(2). Executor(线程)
(3). Task
27.1.3.1. Worker(1 个 worker 进程执行的是 1 个 topology 的子集)
1 个 worker 进程执行的是 1 个 topology 的子集(注:不会出现 1 个 worker 为多个 topology 服务)。1 个 worker 进程会启动 1 个或多个 executor 线程来执行 1 个 topology 的 component(spout 或 bolt)。因此,1 个运行中的 topology 就是由集群中多台物理机上的多个 worker 进程组成的。
27.1.3.2. Executor(executor 是 1 个被 worker 进程启动的单独线程)
executor 是 1 个被 worker 进程启动的单独线程。每个 executor 只会运行 1 个 topology 的 1 个 component(spout 或 bolt)的 task(注:task 可以是 1 个或多个,storm 默认是 1 个 component 只生成 1 个 task,executor 线程里会在每次循环里顺序调用所有 task 实例)。
27.1.3.3. Task(最终运行 spout 或 bolt 中代码的单元)
是最终运行 spout 或 bolt 中代码的单元(注:1 个 task 即为 spout 或 bolt 的 1 个实例, executor 线程在执行期间会调用该 task 的 nextTuple 或 execute 方法)。topology 启动后,1 个 component(spout 或 bolt)的 task 数目是固定不变的,但该 component 使用的 executor 线 程数可以动态调整(例如:1 个 executor 线程可以执行该 component 的 1 个或多个 task 实 例)。这意味着,对于 1 个 component 存在这样的条件:#threads<=#tasks(即:线程数小于 等于 task 数目)。默认情况下 task 的数目等于 executor 线程数目,即 1 个 executor 线程只运 行 1 个 task。
27.1.4. Storm Streaming Grouping
Storm 中最重要的抽象,应该就是 Stream grouping 了,它能够控制 Spot/Bolt 对应的 Task 以 什么样的方式来分发 Tuple,将 Tuple 发射到目的 Spot/Bolt 对应的 Task.
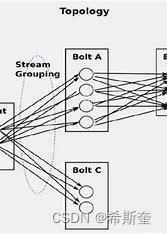
目前,Storm Streaming Grouping 支持如下几种类型:
27.1.4.1. huffle Grouping
随机分组,尽量均匀分布到下游 Bolt 中将流分组定义为混排。这种混排分组意味着来自 Spout 的 输入将混排,或随机分发给此 Bolt 中的任务。shuffle grouping 对各个 task 的 tuple 分配的比 较均匀。
27.1.4.2. Fields Grouping
按字段分组,按数据中 field 值进行分组;相同 field 值的 Tuple 被发送到相同的 Task 这种 grouping 机制保证相同 field 值的 tuple 会去同一个 task。
27.1.4.3. All grouping :广播
广播发送, 对于每一个 tuple 将会复制到每一个 bolt 中处理。
27.1.4.4. Global grouping
全局分组,Tuple 被分配到一个 Bolt 中的一个 Task,实现事务性的 Topology。Stream 中的所 有的 tuple 都会发送给同一个 bolt 任务处理,所有的 tuple 将会发送给拥有最小 task_id 的 bolt 任务处理。
27.1.4.5. None grouping :不分组
不关注并行处理负载均衡策略时使用该方式,目前等同于 shuffle grouping,另外 storm 将会把 bolt 任务和他的上游提供数据的任务安排在同一个线程下。
27.1.4.6. Direct grouping :直接分组 指定分组
由 tuple 的发射单元直接决定 tuple 将发射给那个 bolt,一般情况下是由接收 tuple 的 bolt 决定 接收哪个 bolt 发射的 Tuple。这是一种比较特别的分组方法,用这种分组意味着消息的发送者指 定由消息接收者的哪个 task 处理这个消息。 只有被声明为 Direct Stream 的消息流可以声明这种 分组方法。而且这种消息 tuple 必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的 taskid (OutputCollector.emit 方法也会返回 taskid)
28. YARN
28.1.1. 概念
YARN 是一个资源管理、任务调度的框架,主要包含三大模块:ResourceManager(RM)、 NodeManager(NM)、ApplicationMaster(AM)。其中,ResourceManager 负责所有资 源的监控、分配和管理; ApplicationMaster 负责每一个具体应用程序的调度和协调; NodeManager 负责每一个节点的维护。对于所有的 applications,RM 拥有绝对的控制权和对资 源的分配权。而每个 AM 则会和 RM 协商资源,同时和 NodeManager 通信来执行和监控 task。 几个模块之间的关系如图所示。

28.1.2. ResourceManager
1. ResourceManager 负责整个集群的资源管理和分配,是一个全局的资源管理系统。
2. NodeManager 以心跳的方式向 ResourceManager 汇报资源使用情况(目前主要是 CPU 和 内存的使用情况)。RM 只接受 NM 的资源回报信息,对于具体的资源处理则交给 NM 自己 处理。
3. YARN Scheduler 根据 application 的请求为其分配资源,不负责 application job 的监控、 追踪、运行状态反馈、启动等工作。
28.1.3. NodeManager
1. NodeManager 是每个节点上的资源和任务管理器,它是管理这台机器的代理,负责该节点 程序的运行,以及该节点资源的管理和监控。YARN集群每个节点都运行一个NodeManager。
2. NodeManager 定时向 ResourceManager 汇报本节点资源(CPU、内存)的使用情况和 Container 的运行状态。当 ResourceManager 宕机时 NodeManager 自动连接 RM 备用节 点。
3. NodeManager 接收并处理来自 ApplicationMaster 的 Container 启动、停止等各种请求。
28.1.4. ApplicationMaster
用户提交的每个应用程序均包含一个 ApplicationMaster,它可以运行在 ResourceManager 以外 的机器上。
1. 负责与 RM 调度器协商以获取资源(用 Container 表示)。
2. 将得到的任务进一步分配给内部的任务(资源的二次分配)。
3. 与 NM 通信以启动/停止任务。
4. 监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
5. 当前 YARN 自带了两个 ApplicationMaster 实现,一个是用于演示 AM 编写方法的实例程序 DistributedShell,它可以申请一定数目的 Container 以并行运行一个 Shell 命令或者 Shell 脚本;另一个是运行 MapReduce 应用程序的 AM—MRAppMaster。
注:RM 只负责监控 AM,并在 AM 运行失败时候启动它。RM 不负责 AM 内部任务的容错,任务 的容错由 AM 完成。
28.1.5.YARN 运行流程
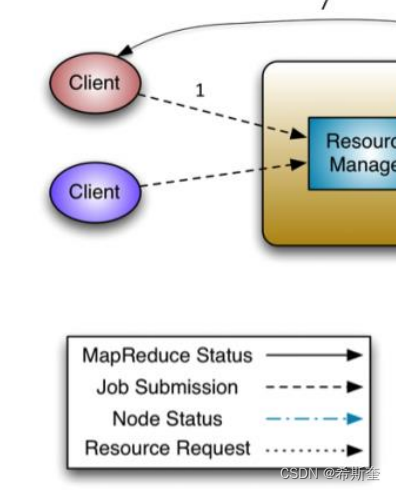

1. client 向 RM 提交应用程序,其中包括启动该应用的 ApplicationMaster 的必须信息,例如 ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等。
2. ResourceManager 启动一个 container 用于运行 ApplicationMaster。
3. 启动中的ApplicationMaster向ResourceManager注册自己,启动成功后与RM保持心跳。
4. ApplicationMaster 向 ResourceManager 发送请求,申请相应数目的 container。
5. ResourceManager 返回 ApplicationMaster 的申请的 containers 信息。申请成功的 container,由 ApplicationMaster 进行初始化。container 的启动信息初始化后,AM 与对 应的 NodeManager 通信,要求 NM 启动 container。AM 与 NM 保持心跳,从而对 NM 上 运行的任务进行监控和管理。
6. container 运行期间,ApplicationMaster 对 container 进行监控。container 通过 RPC 协议 向对应的 AM 汇报自己的进度和状态等信息。
7. 应用运行期间,client 直接与 AM 通信获取应用的状态、进度更新等信息。
8. 应用运行结束后,ApplicationMaster 向 ResourceManager 注销自己,并允许属于它的
container 被收回。
29. 机器学习
29.1.1. 决策树
29.1.2. 随机森林算法
29.1.3. 逻辑回归
29.1.4. SVM
29.1.5. 朴素贝叶斯
29.1.6. K 最近邻算法
29.1.7. K 均值算法
29.1.8. Adaboost 算法
29.1.9. 神经网络
29.1.10. 马尔可夫