Course2-Week1-神经网络
Course2-Week1-神经网络
文章目录
- Course2-Week1-神经网络
- 1. 神经网络概述
- 1.1 欢迎来到Course2
- 1.2 神经元和大脑
- 1.3 引入神经网络-需求预测
- 1.4 神经网络的其他示例-图像感知
- 2. 神经网络的数学表达式
- 2.1 单层的神经网络-需求预测
- 2.3 前向传播的神经网络-手写数字识别
- 3. TensorFlow简介
- 3.1 配置TensorFlow环境
- 3.2 TensorFlow中的张量
- 4. 神经网络的代码实现
- 4.1 使用代码实现推理-烤咖啡豆
- 4.2 神经网络的完整架构-烤咖啡豆
- 4.3 神经网络的内部实现-烤咖啡豆
- 4.4 代码实现-手写数字识别
- 5. AGI漫谈
- 笔记主要参考B站视频“(强推|双字)2022吴恩达机器学习Deeplearning.ai课程”。
- 本篇笔记对应课程 Course2-Week1(下图中深紫色)。

1. 神经网络概述
1.1 欢迎来到Course2
Course2会学习“神经网络”(也被称为“深度学习”)、决策树等算法,这些是最强大、最广泛使用的机器学习算法之一。另外也会介绍构建机器学习系统的建议,比如在进行神经网络训练时,是应该收集更多数据?应该购买更强大的GPU来构建更大的神经网络?下面是这几周的大致内容:
- Week1:使用别人训练好参数的神经网络,进行预测被称为“推理(infrence)”。本周重点介绍“神经网络”的计算原理和调用代码,只“推理”而不涉及“训练”。
- Week2:介绍如何训练神经网络。也就是根据标记好的训练集,训练神经网络参数。
- Week3:将给出构建机器学习系统的建议。
- Week4:介绍“决策树(Decision trees)”,尽管和“神经网络”相比没有那么出名,但这也是一个很强大、广泛使用的机器学习方法。
1.2 神经元和大脑
神经网络起源
在几十年前,当“神经网络(neural networks)”被首次提出时,其最初的动机模仿(mimic)人脑或生物大脑学习和思考的方式,编写一个可以自动运行的软件。虽然如今的“神经网络”,也被称为“人工神经网络(artifical neural network)”,其原理已经和我们大脑实际上的工作方式相去甚远,但是我们还是会看到一些最初的“生物学动机(biological motivations)”。首先来看看“神经网络”的发展历程:
- 1950’s年代:由于人脑或者说生物大脑的比任何“智能”都有着更高的水平,于是“神经网络”最初是想建立模仿大脑的软件。1950’s年代开始这项工作,但是后来就没落了(估计是因为算力不够+也不了解神经元)。
- 1980’s~1990’s早期:由于被应用于手写数字识别等应用中,“神经网络”再度被重视。比如识别邮政编码从而分拣信件、识别手写支票中的美元数字等。但是在1990’s晚期再度失宠。
- 大约2005年~至今:开始复苏,并被重新命名成“深度学习”。从那以后,“神经网络”在一个有一个领域取得了空前进展。
- 第一个由于“神经网络”而取得巨大进步的领域是“语音识别(speech recognition)”,邓力 和 杰弗里·辛顿 等人将现代深度学习算法应用到该领域。
- 然后就是“计算机视觉(cpmputer vision)”,2012年是ImageNet的推出对计算机视觉产生了重要的影响。
- 接下来几年进入了“文本处理”或“自然语言处理(NLP)”。
- 如今:神经网络被应用于方方面面,比如气候变化、医学成像、在线广告推广等。基本上很多推荐机制都是使用神经网络来完成。
注:“神经网络”被重新命名成“深度学习”,一方面是因为听起来更高大上,另一方面是因为人类根本不了解“神经元”的工作方式,现代的深度学习也不想再深究以前的生物学动机,只想从工程的角度构建更有效的算法,所以逐渐舍弃“神经网络”这种叫法。
神经元简化结构
人脑由几百亿个神经元组成,现在我们来看看神经元的简化结构。如下左图,单个神经元有很多“树突(dendrite)”作为输入端,通过“轴突(axon)”输出,该输出可以继续连接一个或多个神经元。于是,单个神经元可以看成“多个输入到单个输出的映射”。在下右图中,使用“蓝色小圈”表示单个神经元,于是“神经网络”就是由多个神经元组成的,能够将输入映射到输出的系统。
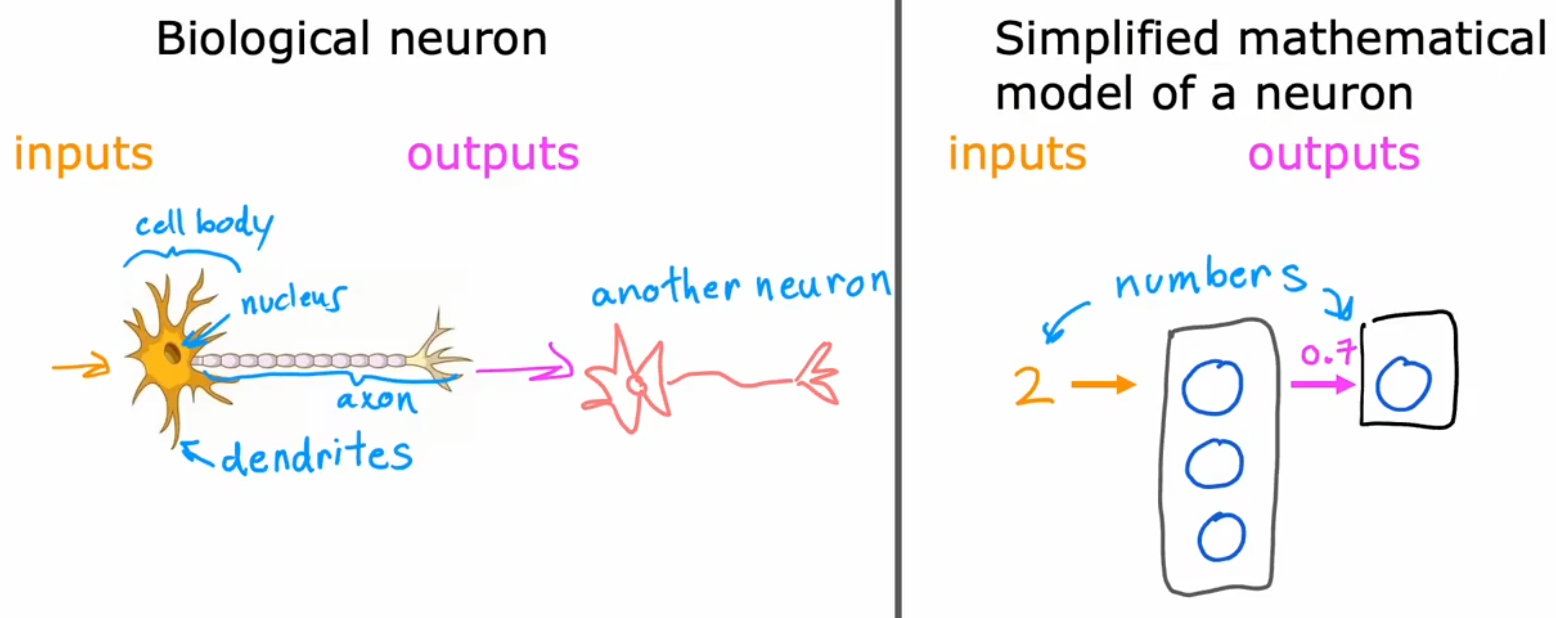
注意这里的介绍只是一个简单的类比,实际上人脑的工作方式更加复杂和精妙,人类目前并不能完全了解人脑的工作方式。基本上每隔几年,神经科学家都会在人脑工作方式领域有根本性的突破。但即使是这些及其简化的神经元模型,也可以训练出很强大的深度学习模型。事实上,从事神经网络研究的人已经从寻找生物学动机渐渐远离,大家只是想从“工程原理”的角度来构建更有效的算法,所以不要太把自己局限在这些生物学动机当中。当然,时不时的想想神经元真正的工作方式也很有趣。
神经网络兴起的真正原因
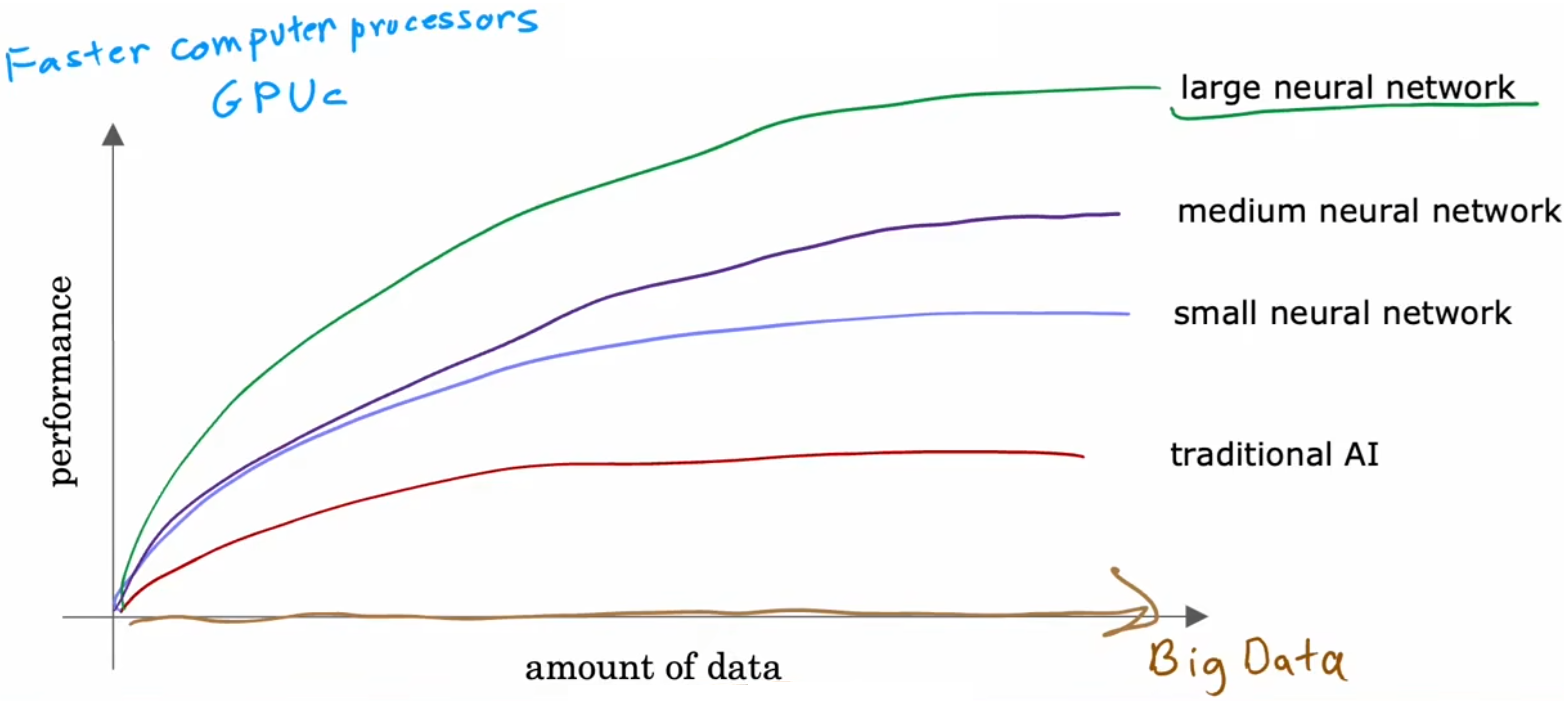
既然神经网络已经在几十年前就提出了,为什么最近几年才开始真正的发展呢?简单来说,是因为存储和算力的发展。在下图中,横轴表示对某问题所拥有的数据量,纵轴表示应用于该问题的“学习算法”的性能或精度。过去几十年间,随着互联网的发展,横轴上的数据在不断增长,若使用传统的机器学习算法,比如“线性回归”或“逻辑回归”,算法性能已经趋于上限。也就是说,传统的AI算法不能有效的利用现在庞大的数据。而得益于算力的发展,主要是GPU的发展,可以部署越来越大规模的神经网络模型,算法精度也相应的取得了质的提升。也就是说,得益于现在的存储和算力,神经网络才取得长足的发展。
1.3 引入神经网络-需求预测
为了说明神经网络的形成原理,本节先从一个小例子——“需求预测”问题开始:
“需求预测(Demand Predication)”问题:预测某产品是否为畅销产品。
- 输入特征:价格、运费、市场营销、材质等。
- 输出:二元输出,是否为畅销产品(0/1)。
我们先只考虑“价格”这一个特征,对于这种二元分类问题,仿照“逻辑回归”,我们仍然可以使用Sigmoid函数来拟合单个神经元的模型函数。于是该神经元模型,输入价格特征 x x x,输出当前衬衫为畅销产品的概率 f ( x ) f(x) f(x)(在神经网络中被称为“激活值” a a a)。这个小逻辑回归算法可以认为是非常简化的单个神经元模型,如下图所示:
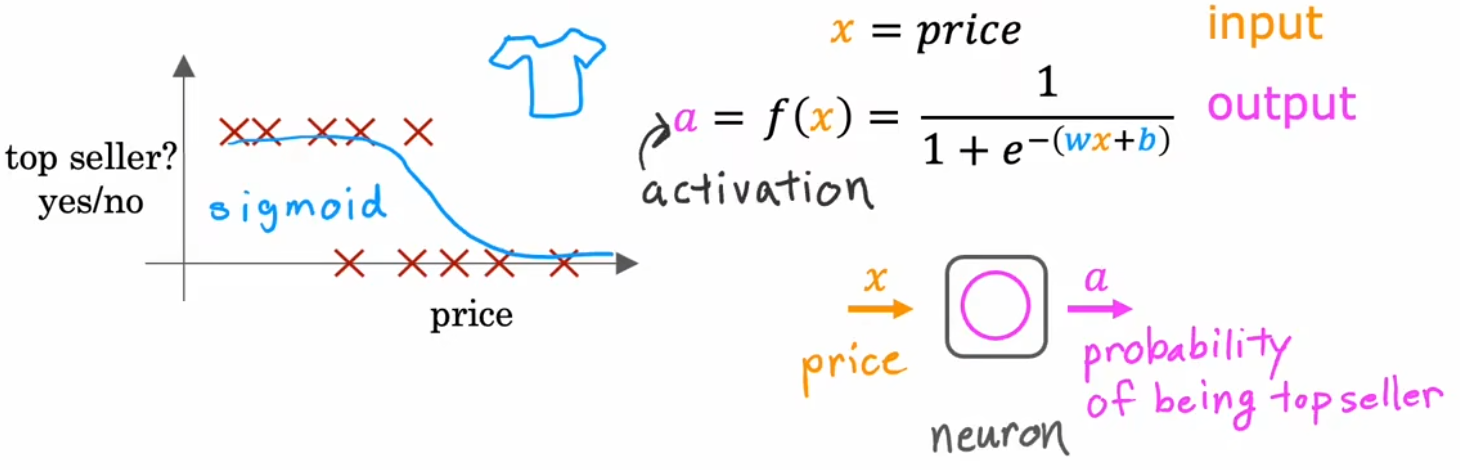
- a a a表示“激活(activation)”。来自于神经科学中的术语,表示当前神经元向下一神经元发送的电脉冲强度(0~1之间的数字)。
下面进一步改进模型,首先是将输入特征扩展为四个(价格、运费、市场营销、材质),但若将这几个特征直接和最后一个神经元相连,这就回到之前的“逻辑回归”了,我们不能这么做。所以我们我们不妨添加一层“消费者因素”,我们定义消费者是否购买一件产品可能取决于三个因素(“心理预期价格”、“认可度”、“产品质量”),这三种因素又取决于不同的输入特征(如下图黄色连线所示)。于是,将“输入特征”、“消费者因素”、“输出概率”这三者使用不同层的神经元连接在一起,每个神经元都是一个小型的逻辑回归算法,便将“单神经元模型”扩展为“神经网络模型”:
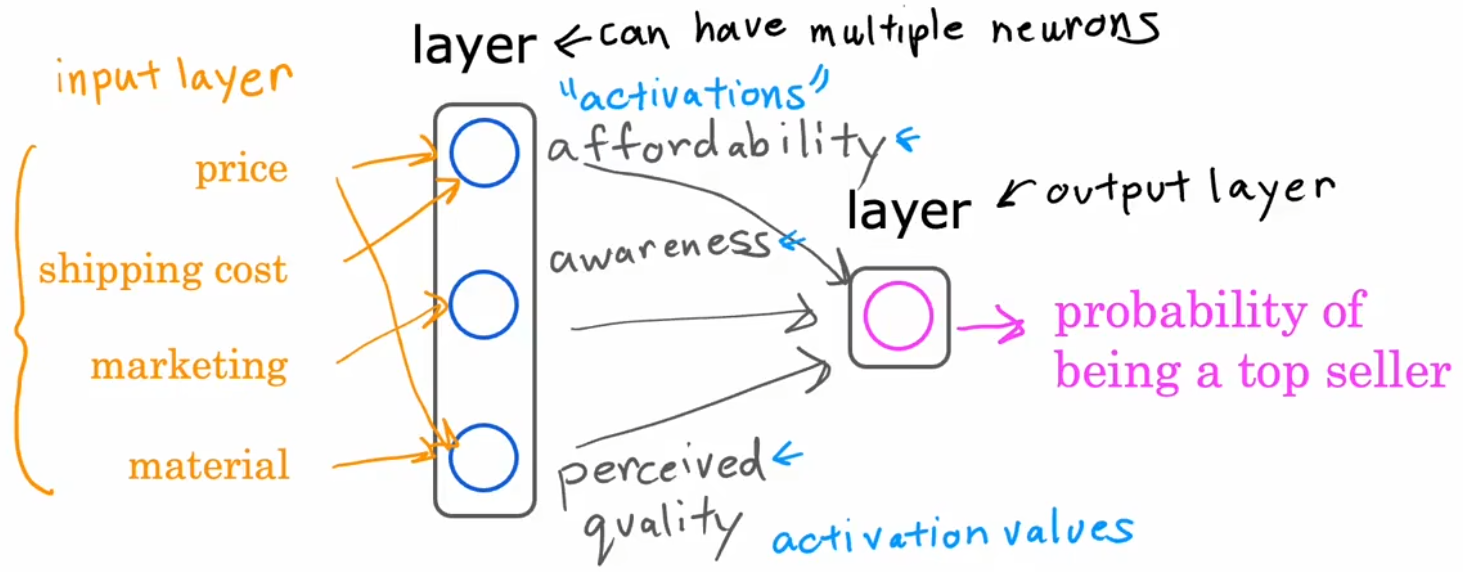
- 输入层(input layer):包含全部的特征,一般表示为 “输入特征向量” x ⃗ \vec{x} x。
- 隐藏层(hidden layer):对输入层的 x ⃗ \vec{x} x 进行映射,得到 “激活向量” a ⃗ \vec{a} a,发送给输出层。
- 输出层(output layer):根据 a ⃗ \vec{a} a 计算出最终的预测结果,也就是成为畅销产品的概率。
注1:具有相似输入特征的神经元会被分组为同一“层”(layer)。
注2:除了输入层,所有隐藏层+输出层=神经网络总层数。比如上图就是两层神经网络。
上述就是整个神经网络的形成原理。但注意到上述我们手动规定了“隐藏层”的神经元数量、每个神经元与输入特征的关系。要是遇到庞大且复杂的神经网络,显然都靠手动规定几乎不可能!所以实际构建神经网络时,只需要设定隐藏层数量、以及每个隐藏层的神经元数量,其他的对应关系等无需规定,神经网络模型都可以自行学习(Week2介绍)。这也解释了,之所以称之为“隐藏层”,是因为我们一般只知道数据集 ( X ⃗ , Y ⃗ ) (\vec{X},\vec{Y}) (X,Y),而不会像上述一样预先设置好“消费者因素”,也就是说,我们一开始并不知道“隐藏层”间的神经元之间的对应关系。
最后要说的一点是,上述只是具有单个隐藏层的神经网络模型,下面是具有多个隐藏层的,某些文献中也被称为“多层感知器(multilayer perceptron)”:

1.4 神经网络的其他示例-图像感知
那“隐藏层”具体都在做什么事情呢?我们使用计算机视觉中的“人脸识别”来举例,现在有一个已经训练好的神经网络模型,下面来看看隐藏层在做什么工作(注意不同的神经网络可能不同):
“人脸识别”(face recognition)问题:识别图片中的人脸是谁。
- 输入特征:100x100的图片。
- 输出:图片中的人脸,是某个人的概率。
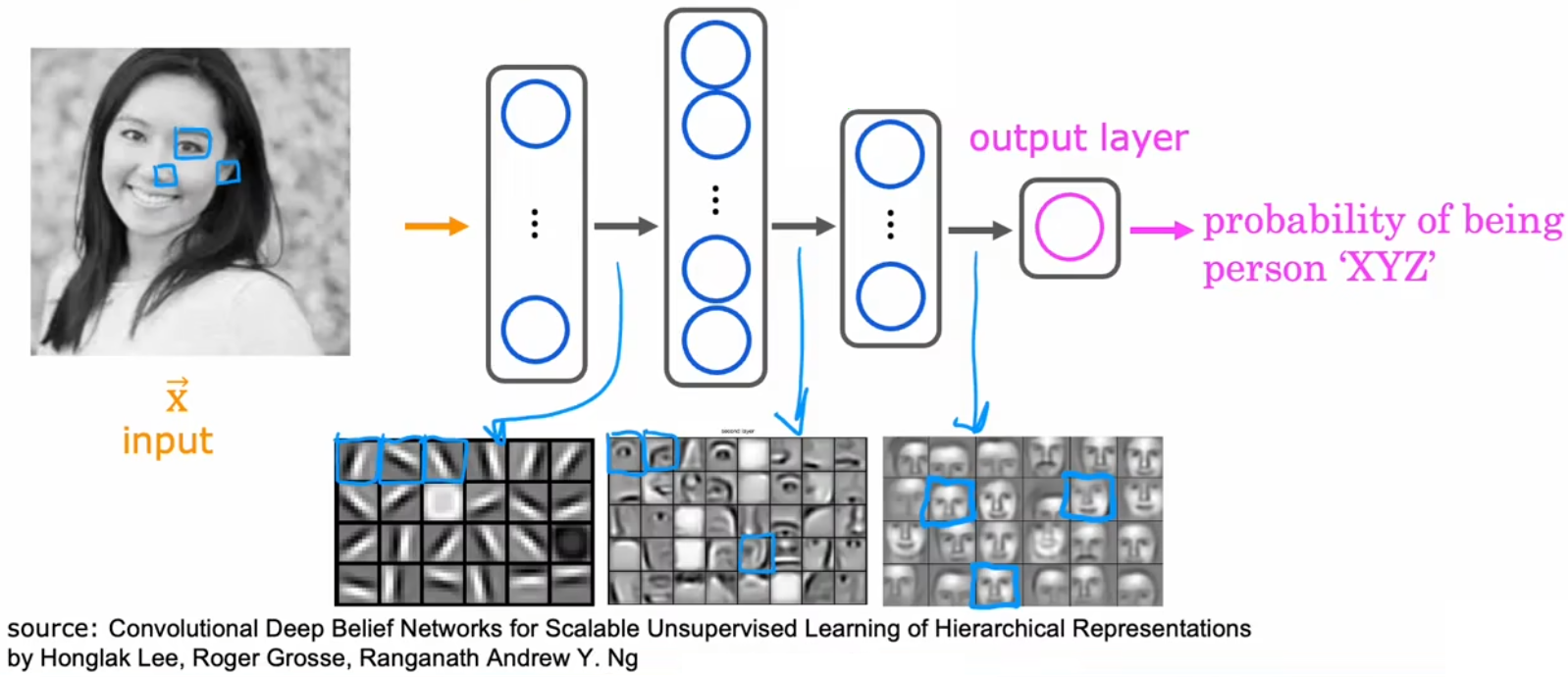
- 隐藏层1:识别一些很小的边缘或线,比如不同的神经元识别不同方向的小边缘或线。
- 隐藏层2:将小边缘组合在一起,识别面部的某个区域,比如鼻子、眼睛、嘴等。
- 隐藏层3:将上述面部区域再组合,检测到整张人脸,然后再根据脸型对比和目标人脸的相似程度。
总结:越靠后的隐藏层,识别区域越大。
注:“汽车检测”的隐藏层功能也相似。
可以看到,神经网络如此强大!我们预先并没有告诉这些隐藏层需要做什么,但仅仅通过学习输入的数据,神经网络便可以自动生成这些不同隐藏层的特征检测器。本周晚些时候还会介绍如何构建“手写数字识别”的神经网络。
本节 Quiz:
Which of these are terms used to refer to components of an artificial neural network?
√ activation function
√ layers
√ neurons
× axon(轴突)Neural networks take inspiration from, but do not very accurately mimic, how neurons in a biological brain learn.
× False
√ True
2. 神经网络的数学表达式
2.1 单层的神经网络-需求预测
数学术语
- 上标方括号 [ l ] ^{[l]} [l]:表示第 l l l 层神经网络。
- w ⃗ j [ l ] \vec{w}_j^{[l]} wj[l]、 b j [ l ] b_j^{[l]} bj[l]:第 l l l 层神经网络的第 j j j 个神经元的参数。
- a ⃗ [ l ] \vec{a}^{[l]} a[l]:第 l l l 层神经网络输出的向量形式的“激活值”。
- a [ l ] a^{[l]} a[l]:第 l l l 层神经网络输出的单个“激活值”,一般是最后一层的“输出层”的输出。
- a ⃗ [ 0 ] \vec{a}^{[0]} a[0]:一般等价于输入特征 x ⃗ \vec{x} x,该表达式是为了与“隐藏层”、“输出层”统一形式。
- g ( ⋅ ) g(·) g(⋅):默认表示Sigmoid函数,是神经网络“激活函数”的其中一种,下周介绍其他激活函数。
概念明晰:
- 按照惯例,神经网络的层数 = 所有隐藏层 + 输出层。比如,两层神经网络就是只包含一个隐藏层。
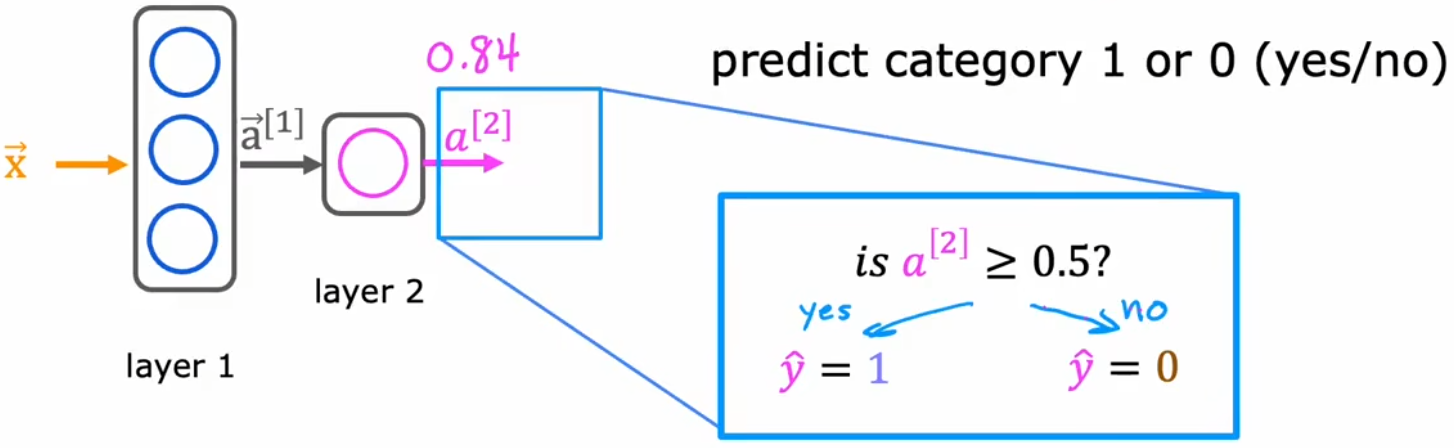
本节将学习“单层神经网络”的数学计算原理。大多数现代神经网络的 基本构造块 是 一层神经元,将几十或几百层神经元组合在一起,就能形成一个大型神经网络。我们先从最简单的“两层神经网络”开始,下图就是“1.3节-需求预测问题”的神经网络,分别给出了“隐藏层”、“输出层”、“判决”的数学表达式(假设每个神经元都是一个小逻辑回归算法):

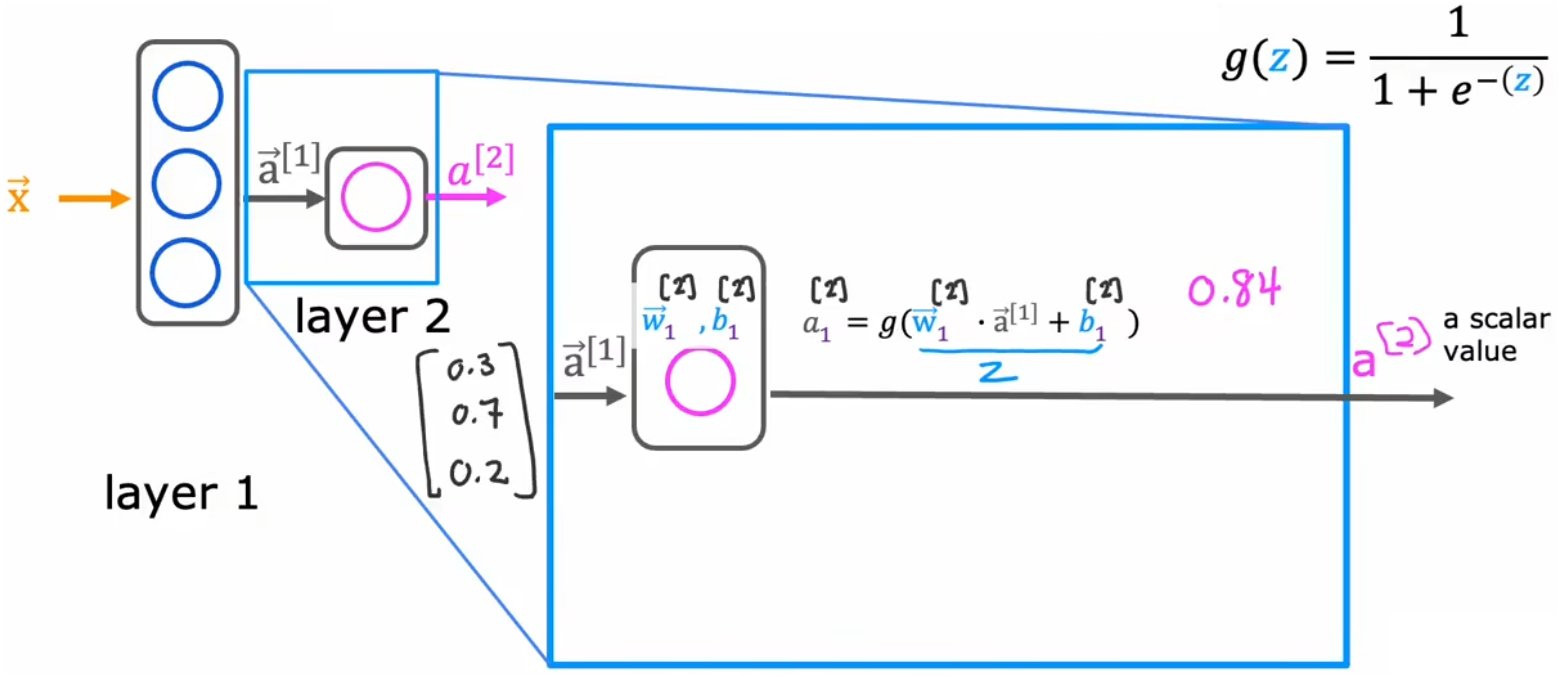
- 输入层(layer0):给出特征向量 x ⃗ \vec{x} x,比如令 x ⃗ = [ 197 , 184 , 136 , 214 ] \vec{x} = [197,184,136,214] x=[197,184,136,214]。
- 隐藏层(layer1):上一左图,包括三个神经元,每个神经元使用Sigmoid函数,并且都有各自的参数 w ⃗ j [ 1 ] \vec{w}_j^{[1]} wj[1]、 b j [ 1 ] b_j^{[1]} bj[1], j = 1 , 2 , 3 j=1,2,3 j=1,2,3。假设这三个神经元的计算结果组成当前层的激活向量 a ⃗ [ 1 ] = [ 0.3 , 0.7 , 0.2 ] \vec{a}^{[1]} = [0.3,0.7,0.2] a[1]=[0.3,0.7,0.2]。
- 输出层(layer2):上一右图,只有单个神经元,利用参数 w ⃗ 1 [ 2 ] \vec{w}_1^{[2]} w1[2]、 b 1 [ 2 ] b_1^{[2]} b1[2] 和输入的 a ⃗ [ 1 ] \vec{a}^{[1]} a[1] 计算出 a [ 2 ] = 0.84 a^{[2]} = 0.84 a[2]=0.84。
- 判决:上第二行图,对输出层的结果进行二进制判决,阈值可设置为0.5。这一步并不是必要的。
显然上图中,每一层都有一个输入向量,经过当前层所有神经元的得到输出向量,传递给下一层。将符号整理得更加清晰一些,于是第
l
l
l 层神经网络的第
j
j
j 个神经元的输出可以写成:
a
j
[
l
]
=
g
(
w
⃗
j
[
l
]
⋅
a
⃗
[
l
−
1
]
+
b
j
[
l
]
)
a_j^{[l]} = g(\vec{w}_j^{[l]}·\vec{a}^{[l-1]}+b_j^{[l]})
aj[l]=g(wj[l]⋅a[l−1]+bj[l])
- 符号说明间本节开始的“数学术语”。
注:将输入特征写为 x ⃗ = a ⃗ [ 0 ] \vec{x} = \vec{a}^{[0]} x=a[0],上式就具有通用性。
将上述表达式合并,于是第
l
l
l 层神经网络的输出为(矩阵格式):
A
⃗
[
l
]
=
g
(
A
⃗
[
l
−
1
]
W
⃗
[
l
]
+
B
⃗
[
l
]
)
\vec{A}^{[l]} = g(\vec{A}^{[l-1]} \vec{W}^{[l]}+\vec{B}^{[l]})
A[l]=g(A[l−1]W[l]+B[l])
- 约定当前层为 l l l,且当前层总共有 M M M 个神经元。
- A ⃗ [ l − 1 ] \vec{A}^{[l-1]} A[l−1]: 1 × N 1×N 1×N二维矩阵,上一层输出的激活向量。假设其长度为 N N N。
- W ⃗ [ l ] \vec{W}^{[l]} W[l]: N × M N×M N×M二维矩阵,当前层所有的 w ⃗ j [ l ] \vec{w}_j^{[l]} wj[l] 参数。第 j j j 列表示第 j j j 个神经元的参数 w ⃗ j [ l ] \vec{w}_j^{[l]} wj[l](列向量)。
- B ⃗ [ l ] \vec{B}^{[l]} B[l]: 1 × N 1×N 1×N二维矩阵,当前层所有的 b j [ l ] b_j^{[l]} bj[l] 参数。
- g ( ⋅ ) g(·) g(⋅):表示Sigmoid函数,也被称为“激活函数”。这里会针对内部的每个元素都分别计算。
- A ⃗ [ l ] \vec{A}^{[l]} A[l]: 1 × N 1×N 1×N二维矩阵,当前层输出的激活向量。
注1:这里的行、列定义并不是强制要求,我只是为了和后面代码对应上。
注2:我将“行向量”称为“二维矩阵”,是因为在TensorFlow中“一维的数字列表”无法参与“矩阵运算”,起提醒作用。
2.3 前向传播的神经网络-手写数字识别
上一小节介绍了神经网络单层的数学表达形式,现在来看看整体的数学形式。首先引入新的示例:
“手写数字识别”问题:简洁起见,只识别手写数字0和1。
- 输入特征:8x8的灰度图(灰度级0~255),0表示黑色,255表示白色。于是输入特征 x ⃗ \vec{x} x 的长度为64。
- 输出:二元分类,输入图片是数字1的概率。
假设我们使用三层神经网络,隐藏层1有25个神经元、隐藏层2有15个神经元,每层神经元的计算公式如下图最右侧所示,并且图片下方也给出了矩阵形式的数学表达式:

x ⃗ = A ⃗ [ 0 ] ⟶ A ⃗ [ 1 ] = g ( A ⃗ [ 0 ] W ⃗ [ 1 ] + B ⃗ [ 1 ] ) ⟶ A ⃗ [ 2 ] = g ( A ⃗ [ 0 ] W ⃗ [ 1 ] + B ⃗ [ 2 ] ) ⟶ A ⃗ [ 3 ] = g ( A ⃗ [ 0 ] W ⃗ [ 1 ] + B ⃗ [ 3 ] ) \begin{aligned} \vec{x} &= \vec{A}^{[0]} \\ \longrightarrow \vec{A}^{[1]} &= g(\vec{A}^{[0]} \vec{W}^{[1]}+\vec{B}^{[1]}) \\ \longrightarrow \vec{A}^{[2]} &= g(\vec{A}^{[0]} \vec{W}^{[1]}+\vec{B}^{[2]}) \\ \longrightarrow \vec{A}^{[3]} &= g(\vec{A}^{[0]} \vec{W}^{[1]}+\vec{B}^{[3]}) \end{aligned} x⟶A[1]⟶A[2]⟶A[3]=A[0]=g(A[0]W[1]+B[1])=g(A[0]W[1]+B[2])=g(A[0]W[1]+B[3])
- 定义每层的输出为行向量,主要是因为为了编程方便, x ⃗ \vec{x} x 一般都会按行输入。
- A ⃗ [ 3 ] \vec{A}^{[3]} A[3] 只有一个元素,所以可以认为是一个值。
注意到上述神经网络模型是按照从左向右的顺序激活神经元的,所以也被称为“前向传播(forward propagation)”。下周将学习“反向传播(backward propagation/back propagation)”。注意到越靠近输出层,隐藏层的神经元数量越少,这是神经网络非常典型的架构。
本节 Quiz:
For a neural network, here is the formula for calculating the activation of the third neuron in layer 2, given the activation vector from layer1: a 3 [ 2 ] = g ( w ⃗ 3 [ 2 ] ⋅ a ⃗ [ 1 ] + b 3 2 ) a_3^{[2]} = g(\vec{w}_3^{[2]}·\vec{a}^{[1]}+b_3^2) a3[2]=g(w3[2]⋅a[1]+b32). Which of the following are correct statements?
√ The activation of layer 2 is determined using the activations from the previous layer.
√ The activation of unit 3 (neuron 3) of layer 2 is calculated using a parameter vector w ⃗ \vec{w} w and b b b that are specific to unit 3 (neuron3).
√ Unit3 (neuron 3) outputs a single number (a scalar).
× If you are calculating the activation for layer 1, then the previous layer’s activations would be denoted by a ⃗ − 1 \vec{a}^{-1} a−1.For the binary classification for handwriting recognition, discussed in the lecture, which of the following statements are correct?
√ There is a single unit (neuron) in the output layer.
√ The output of the model can be interpreted as the probability that the handwritten image is of the number one “1”.
√ After choosing a threshold, you can convert neural network’s output into a category of 0 or 1.
× The neural network cannot be designed to predict if a handwritten imageis 8 or 9.For a neural network, what is the expression for calculating the activation of the third neuron in layer 2? Note, this is different from the question that you saw in the lecture video.
√ a 3 [ 2 ] = g ( w ⃗ 3 [ 2 ] ⋅ a ⃗ [ 1 ] + b 3 2 ) a_3^{[2]} = g(\vec{w}_3^{[2]}·\vec{a}^{[1]}+b_3^2) a3[2]=g(w3[2]⋅a[1]+b32)
× a 3 [ 2 ] = g ( w ⃗ 2 [ 3 ] ⋅ a ⃗ [ 2 ] + b 2 3 ) a_3^{[2]} = g(\vec{w}_2^{[3]}·\vec{a}^{[2]}+b_2^3) a3[2]=g(w2[3]⋅a[2]+b23)
× a 3 [ 2 ] = g ( w ⃗ 3 [ 2 ] ⋅ a ⃗ [ 2 ] + b 3 2 ) a_3^{[2]} = g(\vec{w}_3^{[2]}·\vec{a}^{[2]}+b_3^2) a3[2]=g(w3[2]⋅a[2]+b32)
× a 3 [ 2 ] = g ( w ⃗ 2 [ 3 ] ⋅ a ⃗ [ 1 ] + b 2 3 ) a_3^{[2]} = g(\vec{w}_2^{[3]}·\vec{a}^{[1]}+b_2^3) a3[2]=g(w2[3]⋅a[1]+b23)For the handwriting recognition task discussed in lecture(三层神经网络), what is the output a 1 [ 3 ] a_1^{[3]} a1[3]?
× A vector of several numbers that take values between 0 and 1.
√ The estimated probability that the input image is of a number 1, a number that ranges from 0 to 1.
× A vector of several numbers, each of which is either exactly 0 or 1.
× A number that is either exactly 0 or 1, comprising the network’s prediction.
3. TensorFlow简介
从本节开始,我们开始演示如何使用代码实现神经网络。目前最流行的深度学习框架主要有PyTorch、TensorFlow,本节课将使用TensorFlow(但目前国内最常使用PyTorch),但不用担心,两者代码几乎完全相同。下面首先来配置一下TensorFlow环境。
3.1 配置TensorFlow环境
- 明确目的:成功使用 Jyputer Notebook 运行课程资料,而不是训练大型网络。
- 我的版本:python 3.11.5 + tensorflow(CPU) 2.15.0。(非有意组合,指令自动匹配)
- 课程环境:python3.7.6 + 目测最少是 tensorflow(GPU) 2.0.0。
在Course1-Week1已经配置好了Jupyter Notebook,现在只需要安装TensorFlow即可。由于GPU版本我安装不上(总是有各种各样的问题),而且课程资料中也不会涉及特别大型的神经网络,且后续开发我用Pytorch(国内常用),所以直接简单快捷的安装个CPU版本,赶紧把课上完即可。
- 配置Jupyter Notebook环境:参考“辅助笔记-Jupyter Notebook的安装和使用”。
- 配置TensorFlow环境:参考“不愧是公认的讲的最好的【Tensorflow全套教程】”。
注:和课程 tensorflow 版本不匹配,可能会有一些函数库已经改位置了,运行代码时按照相应的 warning 更改即可。
安装TensorFlow-CPU版本
直接打开 Anaconda Promat,输入下面的指令即可:
# 安装时会自动选择和Python环境匹配的版本
pip install tensorflow
安装TensorFlow-GPU版本
硬件最好为AMD显卡(N卡)。然后,配置好CUDA10;再打开 Anaconda Promat,输入下面的指令:
# 安装时会自动选择和Python环境匹配的版本
pip install tensorflow-gpu
3.2 TensorFlow中的张量
本节主要来区分一下NumPy中的“数字列表”、“矩阵”,并说明NumPy和TensorFlow数据格式的不同。在Python中,大家最常使用“NumPy库”来完成线性代数的运算;而涉及到神经网络的计算,则通常交给Tensorflow完成。但可惜的是,因为历史遗留问题,两者的数据格式并不统一。如下所示,NumPy中行向量、列向量、数字列表的区别主要在于方括号的层数:
# 最外层方括号:表示定义矩阵
# 里层的方括号:表示一行数据
x = np.array([[200, 17]]) # 行向量,1x2的二维数组
x = np.array([[200],
[17]]) # 列向量,2x1的二维数组
x = np.array([200, 17]) # 数字列表,无法参与矩阵运算
而TensorFlow旨在处理非常大的数据集,所以传入其内部的数据都会转化成“张量(tnesor)”,这样可以使其内部计算更加高效。TensorFlow的二维张量和NumPy的二维数组,存储格式并不相同。比如“2.1节-需求预测问题”隐藏层的输出:
# 直接打印
tf.Tensor([[0.3 0.7 0.2]], shape=(1, 3), dtype=float32)
# 转换成NumPy格式再打印
a1.numpy()
array([[0.3 0.7 0.2]], dtype=float32) # 不显示矩阵大小
所以建议:
- 传入数据:要传递给TensorFlow的数据,都使用两层方括号定义成矩阵(二维张量)。
- 读出数据:TensorFlow处理完毕后,可以先将其转换成NumPy的数据格式,再调用NumPy的方法进行后续处理。
4. 神经网络的代码实现
4.1 使用代码实现推理-烤咖啡豆
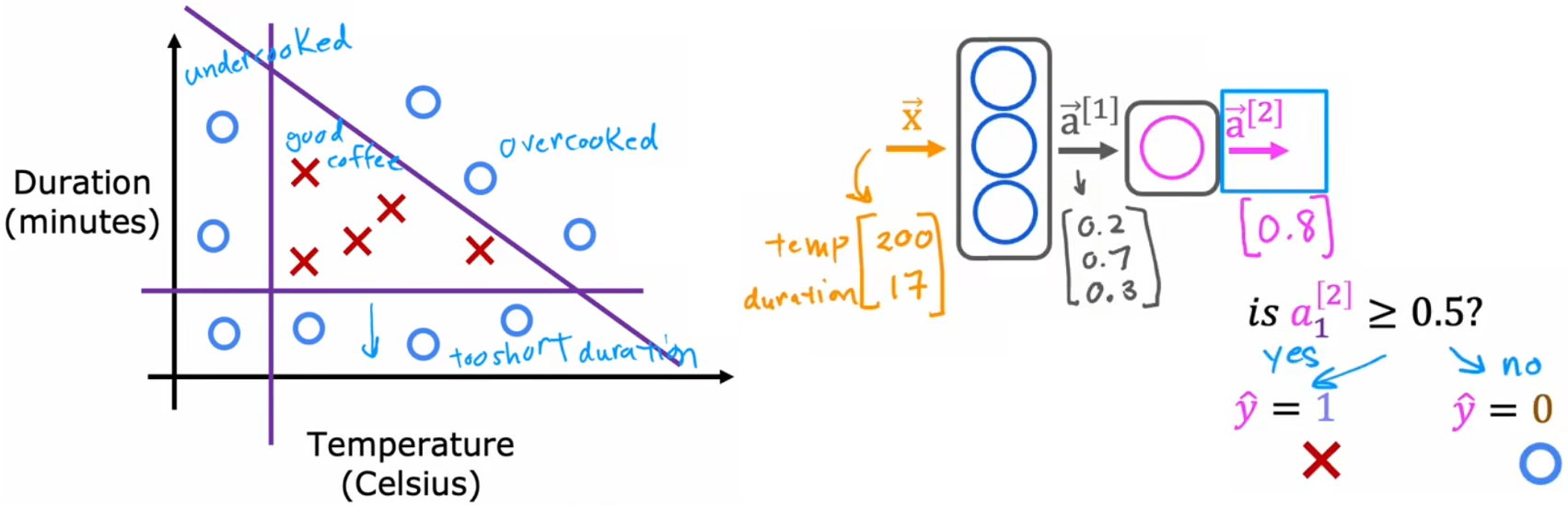
神经网络最显著的特点之一就是,不同的应用程序可以使用相同的算法(框架)。下面引入简单且贴近日常的“烤咖啡豆”问题,来简化神经网络的说明,为解决“手写数字识别”做铺垫。该问题使用最简单的两层神经网络模型,直接按照“前向传播”的方式依次计算激活向量即可,问题模型和代码如下:
“烤咖啡豆”问题:
- 输入特征:“烘焙温度”、“烘焙时间”。
- 输出:二元分类,咖啡豆是否烤好了,红叉表示烤好了、蓝圈表示没烤好。
# TensorFlow伪代码-烤咖啡豆
######################################
# 隐藏层
x = np.array([[200.0, 17.0]]) # 输入特征
layer_1 = Dense(units=3, activation='sigmoid') # 定义隐藏层
a1 = layer_1(x) # 计算激活向量
# 输出层
layer_2 = Dense(units=1, activation='sigmoid') # 定义输出层
a2 = layer_2(a1) # 计算输出值
# 判决
if a2 >= 0.5:
yhat = 1
else:
yhat = 0
注1:dense 是神经网络单层(layer)的另一个名称,4.3节 会介绍
Dense()函数的实现原理。
注2:隐藏层的定义中会预设参数的初始值。
实际上已经有很多实际落地的项目,使用神经网络来优化咖啡烘焙。但显然上述只是一个TensorFlow伪代码,帮助大家理解代码框架,下面几节会逐步完善代码细节。
4.2 神经网络的完整架构-烤咖啡豆
上一小节的代码只是直观的计算过程,但实际上神经网络模型还需要编译和拟合后才能使用。并且正常情况下,我们也不需要观察隐藏层的输出,于是代码如下:
# 烤咖啡豆-代码整合
# 定义训练集
x = np.array([[200.0, 17.0],
[120.0, 5.0],
[425.0, 20.0],
[212.0, 18.0])
y = np.array([1,0,0,1])
# 定义神经网络
layer_1 = Dense(units=3, activation='sigmoid') # 定义隐藏层
layer_2 = Dense(units=1, activation='sigmoid') # 定义输出层
model = Sequential([layer_1, layer_2]) # 连接两层
# 编译并训练网络
model.compile(...) # 编译整个神经网络,下周具体介绍
model.fit(x,y) # 训练数据集,下周具体介绍
# 预测并判决
a_last = model.predict(x_new)
if a_last >= 0.5:
yhat = 1
else:
yhat = 0
显然上述都是直接调用TensorFlow库代码即可实现神经网络的构建,虽然直接调用很有效率,但是了解其背后的工作原理还是非常重要的,尤其是当程序出问题时,比如运行很慢、运行结果错误、代码有bug等,在进行debug的时候就会更加得心应手。下面就来介绍。
4.3 神经网络的内部实现-烤咖啡豆
代码约定:
wl_j:表示第 l l l 层的第 j j j 个神经元参数。比如w2_1表示 w ⃗ 1 [ 2 ] \vec{w}_1^{[2]} w1[2]。- 大写字母表示矩阵(二维及以上数组),小写字母表示向量(一维数组)或标量。
还是“烤咖啡豆”问题。下图的优化过程如下:
- 图2-1-10:给出了对每个神经元的硬编码。
- 图2-1-11:将每一层神经元的计算封装成一个
Dense(a_in,w,b,g)函数,再将所有层封装成一个网络sequential()。- 图2-1-12:使用矩阵运算优化
Dense()函数,使整个神经网络的运行效率大大提高。



图2-1-12中:
- 左侧还有一些“数字列表”,右侧全是二维数组。也就是进行了“向量化”。
np.matmul()函数是矩阵乘法函数,具体的矩阵乘法过程见“线性代数”知识,这里省略。Z = np.matmul(AT,W)等价于Z = AT @ W,也就是说@就是NumPy中的矩阵乘法符号。
最后想再强调一下“矢量化”的好处。神经网络的规模之所以可以越来越大,得益于“矢量化”,这保证神经网络可以使用矩阵运算高效地部署。这是因为并行计算硬件,比如GPU或者强大的CPU,非常擅长做非常大的矩阵运算。
4.4 代码实现-手写数字识别
现在回到手写数字识别问题,显然代码如下:
# 手写数字识别-代码整合
# 定义训练集
x = np.array([[0..., 245, ..., 17], # 1的训练图片
[0..., 200, ..., 184]) # 0的训练图片
y = np.array([1,0])
# 定义神经网络
layer_1 = Dense(units=25, activation='sigmoid') # 定义隐藏层1
layer_2 = Dense(units=15, activation='sigmoid') # 定义隐藏层2
layer_3 = Dense(units=1, activation='sigmoid') # 定义输出层
model = Sequential([layer_1, layer_2, layer_3]) # 连接三层
###################也可以将上述四行合并####################
# model = Sequential([
# Dense(units=25, activation='sigmoid'), # 隐藏层1
# Dense(units=15, activation='sigmoid'), # 隐藏层2
# Dense(units=1, activation='sigmoid')]) # 输出层
#########################################################
# 编译并训练网络
model.compile(...) # 编译整个神经网络,下周具体介绍
model.fit(x,y) # 训练数据集,下周具体介绍
# 预测并判决
a_last = model.predict(x_new)
if a_last >= 0.5:
yhat = 1
else:
yhat = 0
本节 Quiz:
- For the the following code, will this code define a neural network with how many layers?
Answer: 4model = Sequential([ Dense(units=25, activation="sigmoid"), Dense(units=15, activation="sigmoid"), Dense(units=10, activation="sigmoid"), Dense(units=1, activation="sigmoid")])
How do you define the second layer of a neural network that has 4 neurons and a sigmoid activation?
×Dense(units=[4], activation=['sigmoid'])
×Dense(layer=2, units=4, activation = *sigmoid')
√Dense(units=4, activation='sigmoid)
×Dense(units=4)If the input features are temperature (in Celsius) and duration (in minutes), how do you write the code for the first feature vector x [200.0, 17.0]?
×x = np.array([[200.0], [17.0])
√x = np.array([[200.0, 17.0]])
×x = np.array([[200.0 + 17.0]])
×x = np.array([['200.0', '17.0'])
本节 Quiz:
- According to the lecture, how do you calculate the activation of the third neuron in the first layer using NumPy?
z1_3 = np.dot(w1_3, x) + b a1_3 = sigmoid(z1_3) √z1_3 = w1_3*x + b a1_3 = sigmoid(z1_3) ×layer_1 = Dense(units=3, activation='sigmoid') a_1 = layer_1(x) ×
According to the lecture, when coding up the numpy array W, where would you place the w parameters for each neuron?
× In the rows of W.
√ In the columns of W.For the code above in the “dense” function that defines a single layer of neurons, how many times does the code go through the “for loop”? Note that W has 2 rows and 3 columns.
× 2 times
× 6 times
√ 3 times
× 5 times
5. AGI漫谈
最后一节放松一下,来谈谈“AGI(Artifical General Intelligence, 通用人工智能)”。老师一直梦想着构建一个和人一样聪明的AI系统,这也是全世界人工智能领域的愿景,但是前路漫漫,不知道几十年、上百年能否实现。不过,如今AGI的目标是构建一个“和人一样聪明的AI”,这让人兴奋但同时又有很多不切实际的炒作,比如《终结者》系列电影中的“天网”要灭绝人类,这引起一部分人对于AI的恐慌。但其实AI主要包括两方面完全不一样的内容:
- ANI(Artifical Narrow Intelligence, 狭义人工智能):一次只做一件事的AI。比如智能扬声器、自动驾驶汽车、网络搜索、用于特定农场或工厂的AI等。过去几年间,ANI取得了巨大的进步并带动了巨大的社会经济效益,常见于生活的方方面面。
- AGI(Artifical General Intelligence, 通用人工智能):可以像人类一样做任何事的AI。
总结:ANI的成功带动了AI的发展,但是很难说推动了AGI的进步。
并且,即使从“模拟人脑”的角度来看,要想实现真正的AGI依旧非常困难,主要有两个原因:
- 目前的神经元模型非常简单,实际上人脑神经元的工作机制要复杂得多。
- 从医学角度来说,我们也不完全了解人脑是如何工作的。
总结:老师认为仅通过“模拟大脑神经元”的方式,就实现了AGI,是非常困难的。
注:这大概也是现在改称“深度学习”的原因。
虽然不用恐慌,但是我们就没有实现AGI的可能了吗?也不是,比如下面的几个实验就显示出,人类大脑的某个区域,即使是非常小的一块区域,都具有惊人的适应性、可塑性:

- 使用“听觉皮层”看:将大脑的“听觉皮层”和原有的神经切断,再连接上图像信号,那么一段时间后,该区域皮层就“学会了看”。用于感受触觉的“体感皮层”也是同理。
- 使用舌头看。头上安装摄像机,并将其拍摄到的灰度值映射到舌头上的电压矩阵。给盲人带上学习一段时间,盲人就可以“看见”物体。
- 人体声纳。训练人类发出“哒哒声”(类似于弹舌),并观察声音是如何在环境中反射的。经过一段时间的训练,有些人可以实现“回声定位”。
- 方向感知。带上一个腰带,该腰带中指向北方的蜂鸣器会缓慢震动,一段时间后,就会一直知道北方在哪里(带着腰带),而不是再去首先感受蜂鸣器振动。
- 植入第三只眼。一段时间后,青蛙就会熟练使用第三只眼。
这一系列实验表明,大脑的许多区域,其功能仅取决于输入的数据,换言之,这些区域都有一个“通用算法”。如果我们能了解这一小块区域的算法,我们就能用计算机进行模拟,进而可能会创造出AGI。但显然这是一条很困难的道路,因为我们不确定大脑是不是就是一堆算法,就算是,我们也不知道这个算法是什么,但希望通过我们的努力在某一个可以接近这个“算法”。
实现AGI的想法真的很迷人,我们应当理性看待,而不应过度炒作。但如果同学们觉得这些伦理问题困扰到了自己,就不用想这么多,也不用想什么AGI,只要知道神经网络是一个很有帮助的工具也很不错。