pandas基础操作2
数据读取
我们想要使用 Pandas 来分析数据,那么首先需要读取数据。大多数情况下,数据都来源于外部的数据文件或者数据库。Pandas 提供了一系列的方法来读取外部数据,非常全面。下面,我们以最常用的 CSV 数据文件为例进行介绍。
读取数据 CSV 文件的方法是 pandas.read_csv(),你可以直接传入一个相对路径,或者是网络 URL。
df = pd.read_csv("path/name.csv")
df
df.head() # 默认显示前 5 条
df.tail(7) # 指定显示后 7 条
df.describe() #escribe() 相当于对数据集进行概览,会输出该数据集每一列数据的计数、最大值、最小值等。
df.values #Pandas 基于 NumPy 开发,所以任何时候你都可以通过 .values 将 DataFrame 转换为 NumPy 数组。
df.columns # 查看列名 结果:Index(['Zip Code', 'Total Population', 'Median Age', 'Total Males','Total Females', 'Total Households', 'Average Household Size'],dtype='object')
df.index # 查看索引 结果:RangeIndex(start=0, stop=319, step=1)
df.shape # 查看行列大小
由于 CSV 存储时是一个二维的表格,那么 Pandas 会自动将其读取为 DataFrame 类型。
pd.read_ 前缀开始的方法还可以读取各式各样的数据文件,且支持连接数据库。这里,我们不再依次赘述,你可以阅读 官方文档相应章节 熟悉这些方法以及搞清楚这些方法包含的参数。
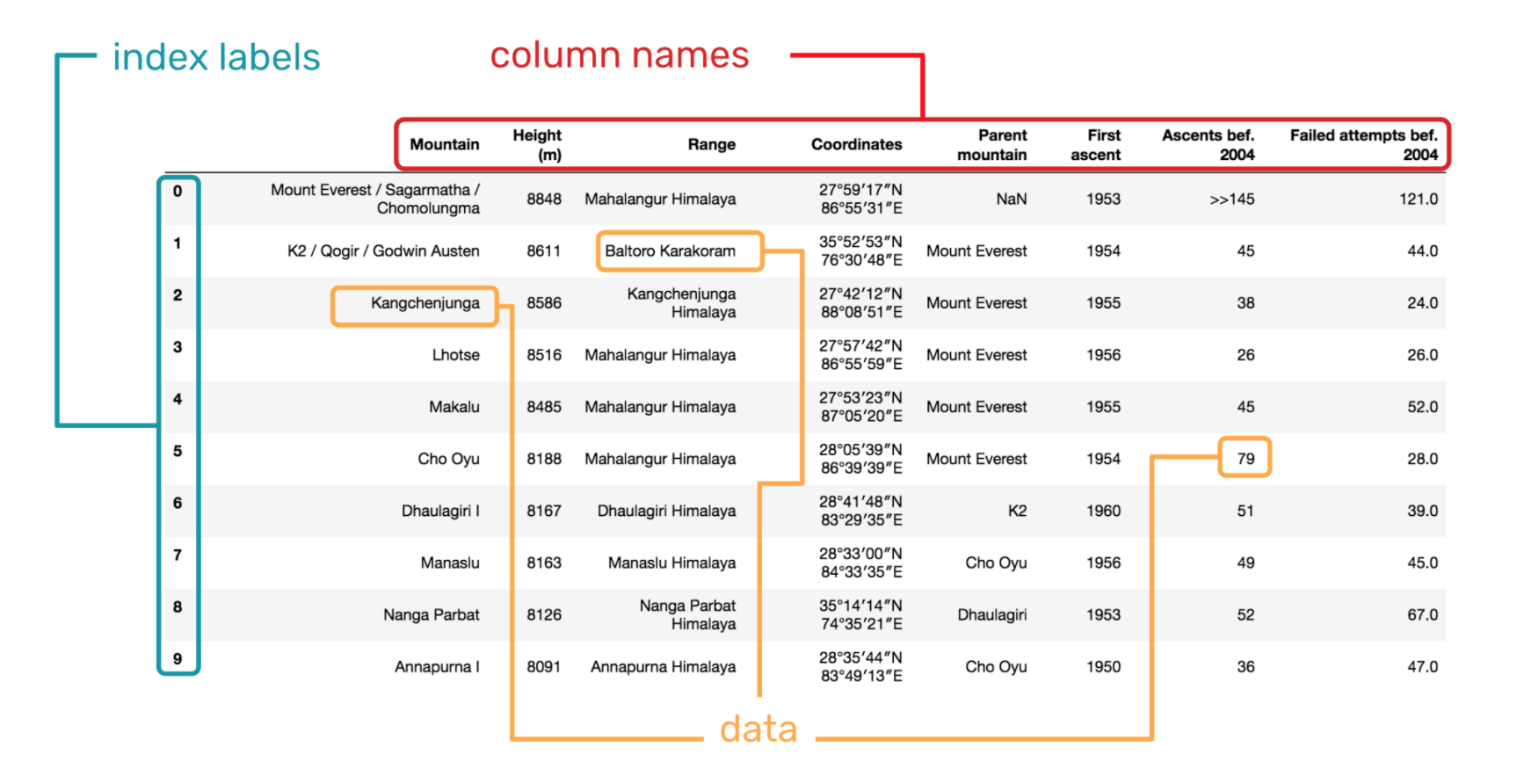
通过上面的内容,我们已经知道一个 DataFrame 结构大致由 3 部分组成,它们分别是列名称、索引和数据。
df = pd.DataFrame([{'one': 1, 'two': 4},
{'one': 2, 'two': 5},
{'one': 3, 'two': 6},
{'777': 3, '888': 6}])
df
| one | two | 777 | 888 | |
|---|---|---|---|---|
| 0 | 1.0 | 4.0 | NaN | NaN |
| 1 | 2.0 | 5.0 | NaN | NaN |
| 2 | 3.0 | 6.0 | NaN | NaN |
| 3 | NaN | NaN | 3.0 | 6.0 |
这个是输出结果,我们可以看到,相同的键就会合并,会在一列上面,然后根据索引位置摆放,不同的键就会单独做一列,然后更具索引位置摆放数据,有些地方没有数据,就是NaN,
一定要自己操作体验一下
在数据处理和分析中,NaN 是一个常见的术语,代表 “Not a Number”。它是一个特殊的浮点值,用于表示未定义或不可表示的值。在 Pandas 中,NaN 通常用来表示缺失或空缺的数据。
以下是关于 NaN 的几个要点:
- 数据缺失的表示:在 Pandas 的
DataFrame或Series中,NaN用于表示缺失的或未知的数据。 - 数学运算中的行为:
NaN与任何数字进行数学运算的结果都是NaN,这是为了避免给出错误的计算结果。 - 数据清洗:在数据分析过程中,经常需要处理
NaN值。常用的方法包括删除含有NaN的行或列、用特定值填充NaN(例如平均值、中位数等),或使用插值方法估算NaN的值。 - 检测和过滤:Pandas 提供了函数如
isna()或notna()来检测数据中的NaN值,以便进行过滤或其他处理。
数据选择
数据预处理过程中,我们往往会对数据集进行切分,只将需要的某些行、列,或者数据块保留下来,输出到下一个流程中去。这也就是所谓的数据选择,或者数据索引。
由于 Pandas 的数据结构中存在索引、标签,所以我们可以通过多轴索引完成对数据的选择。
基于索引数字选择
当我们新建一个 DataFrame 之后,如果未自己指定行索引或者列对应的标签,那么 Pandas 会默认从 0 开始以数字的形式作为行索引,并以数据集的第一行作为列对应的标签。其实,这里的「列」也有数字索引,默认也是从 0 开始,只是未显示出来。
所以,我们首先可以基于数字索引对数据集进行选择。这里用到的 Pandas 中的 .iloc 方法。该方法可以接受的类型有:
- 整数。例如:
5 - 整数构成的列表或数组。例如:
[1, 2, 3] - 布尔数组。
- 可返回索引值的函数或参数。
下面,我们使用上方的示例数据进行演示。
首先,我们可以选择前 3 行数据。这和 Python 或者 NumPy 里面的切片很相似。
df.iloc[:3] #第一到第三行
df.iloc[5] #第五行
df.iloc[[1, 3, 5]] #单独选择需要的行
选择列是不是很简单几乎和切片一模一样
选择行学会以后,选择列就应该能想到怎么办了。例如,我们要选择第 2-4 列。
df.iloc[:, 1:4] #前面是不是全部的行都要呀,之后就是2-4列的切片
基于标签名称选择
除了根据数字索引选择,还可以直接根据标签对应的名称选择。这里用到的方法和上面的 iloc 很相似,少了个 i 为 df.loc[]
df.loc[] 可以接受的类型有:
- 单个标签。例如:
2或'a',这里的2指的是标签而不是索引位置。 - 列表或数组包含的标签。例如:
['A', 'B', 'C']。 - 切片对象。例如:
'A':'E',注意这里和上面切片的不同之处,首尾都包含在内。 - 布尔数组。
- 可返回标签的函数或参数。
df.loc[0:2] #0,1,2行包含首尾
| Zip Code | Total Population | Median Age | Total Males | Total Females | Total Households | Average Household Size | |
|---|---|---|---|---|---|---|---|
| 0 | 91371 | 1 | 73.5 | 0 | 1 | 1 | 1.00 |
| 1 | 90001 | 57110 | 26.6 | 28468 | 28642 | 12971 | 4.40 |
| 2 | 90002 | 51223 | 25.5 | 24876 | 26347 | 11731 | 4.36 |
再选择 1,3,5 行:
df.loc[[0, 2, 4]]
| Zip Code | Total Population | Median Age | Total Males | Total Females | Total Households | Average Household Size | |
|---|---|---|---|---|---|---|---|
| 0 | 91371 | 1 | 73.5 | 0 | 1 | 1 | 1.00 |
| 2 | 90002 | 51223 | 25.5 | 24876 | 26347 | 11731 | 4.36 |
| 4 | 90004 | 62180 | 34.8 | 31302 | 30878 | 22547 | 2.73 |
然后,选择 2-4 列,是列,所以需要输入列名:
df.loc[:, 'Total Population':'Total Males']
| Total Population | Median Age | Total Males | |
|---|---|---|---|
| 0 | 1 | 73.5 | 0 |
| 1 | 57110 | 26.6 | 28468 |
| 2 | 51223 | 25.5 | 24876 |
| 3 | 66266 | 26.3 | 32631 |
| 4 | 62180 | 34.8 | 31302 |
| … | … | … | … |
| 314 | 38158 | 28.4 | 18711 |
| 315 | 2138 | 43.3 | 1121 |
| 316 | 18910 | 32.4 | 9491 |
| 317 | 388 | 44.5 | 263 |
| 318 | 7285 | 30.9 | 3653 |
最后,选择 1,3 行和 Median Age 后面的列:
df.loc[[0, 2], 'Median Age':]
| Median Age | Total Males | Total Females | Total Households | Average Household Size | |
|---|---|---|---|---|---|
| 0 | 73.5 | 0 | 1 | 1 | 1.00 |
| 2 | 25.5 | 24876 | 26347 | 11731 | 4.36 |