【Pytorch 入门】DAY 4 损失函数 模型的保存与下载
损失函数
通俗理解,如下图所示,为理想与现实的差距
- 计算实际输出和目标之间的差距
- 为我们更新输出提供一定的依据(反向传播)grad

官方文档
L1lOSS

import torch
from torch.nn import L1Loss
inputs=torch.tensor([1,2,3],dtype=torch.float32)
targets=torch.tensor([1,2,5],dtype=torch.float32)
inputs=torch.reshape(inputs,(1,1,1,3))
tragets=torch.reshape(targets,(1,1,1,3))
loss=L1Loss()
result=loss(inputs,tragets)
print(result)
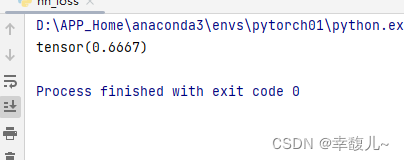
MSELoss
均方误差

loss_mse=MSELoss()
result_mse=loss_mse(inputs,targets)
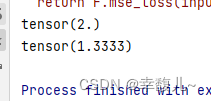
CROSSENTROPYLOSS
计算公式
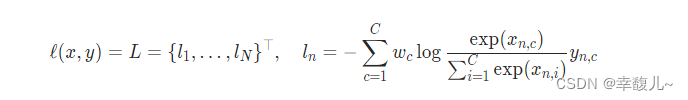
x=torch.tensor([0.1,0.2,0.3])
y=torch.tensor([1])
x=torch.reshape(x,(1,3))
loss_cross=nn.CrossEntropyLoss()
result_cross=loss_cross(x,y)
print(result_cross)#tensor(1.1019)
交叉熵应用
该网络的输出概率如图所示,batch_size设为1是为了方便查看每一个的输出概率,实际不会设置为1。
dataset=torchvision.datasets.CIFAR10('dataset',train=False,transform=torchvision.transforms.ToTensor(),download=False)
dataloader=DataLoader(dataset,batch_size=1)
class Felix(nn.Module):
def __init__(self):
super(Felix,self).__init__()
self.model1=Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
felix=Felix()
for data in dataloader:
imgs,targets=data
outputs=felix(imgs)
print(outputs)
print(targets)

接下来加入交叉熵函数。
loss=nn.CrossEntropyLoss()
felix=Felix()
for data in dataloader:
imgs,targets=data
outputs=felix(imgs)
result_loss=loss(outputs,targets)
print(result_loss)
结果是实际输出和目标之间的差距
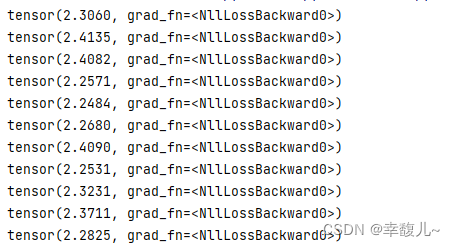
然后可以实现第二个目的,反向传播,进行参数的更新。
先断点运行。
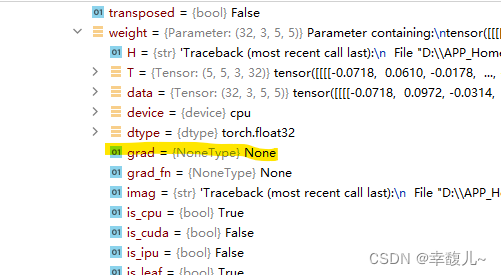
网络名称(felix)->model1->Protected Attributes->_models->卷积层(‘0’)->weight->grad
此时梯度为none,还没有开始求值
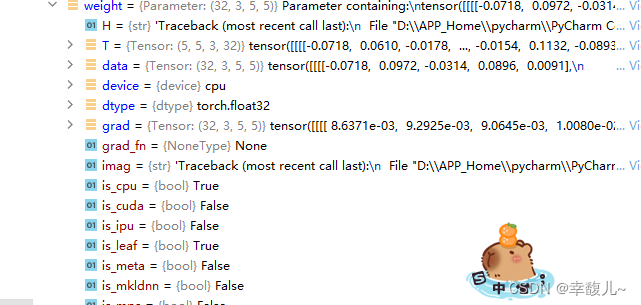
接着运行该行代码,可以看到此时梯度被更新
优化器
在官方文档中的位置
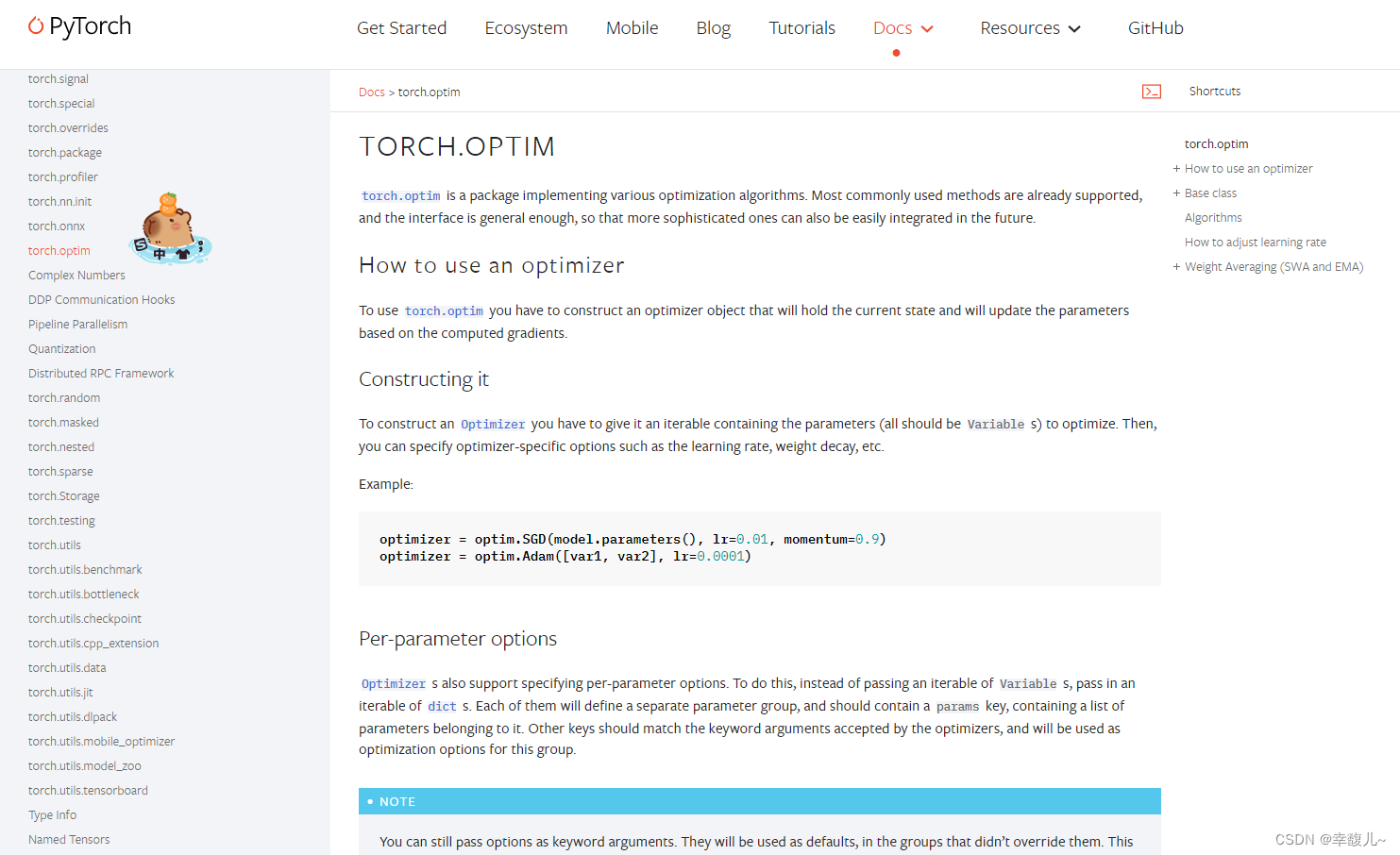
lr:训练速率
步骤
- 先定义一个优化器
- 用优化器对网络中的每一个梯度清零
- 调用损失函数的backward,求出每个节点的grad
- optim.step()对模型的每个参数进行调优
loss=nn.CrossEntropyLoss()
felix=Felix()
optim=torch.optim.SGD(felix.parameters(),lr=0.01)#随机梯度下降
for data in dataloader:
imgs,targets=data
outputs=felix(imgs)
result_loss=loss(outputs,targets)
optim.zero_grad()#梯度设置为0
result_loss.backward()
optim.step()
loss=nn.CrossEntropyLoss()
felix=Felix()
optim=torch.optim.SGD(felix.parameters(),lr=0.01)#随机梯度下降
for epoch in range(20):
running_loss=0.0
for data in dataloader:
imgs,targets=data
outputs=felix(imgs)
result_loss=loss(outputs,targets)
optim.zero_grad()#梯度设置为0
result_loss.backward()
optim.step()
running_loss=running_loss+result_loss#每轮开始前将loss设置为0,在学习过程中所有的loss总和
print(running_loss)
运行结果

现有网络模型的使用及修改
Imagnet
root:下载路径
split:
transform:是否在数据集上进行变换
target_transform:在target上进行变换
准备
-
查看是否有 scipy这个包
没有,安装
-
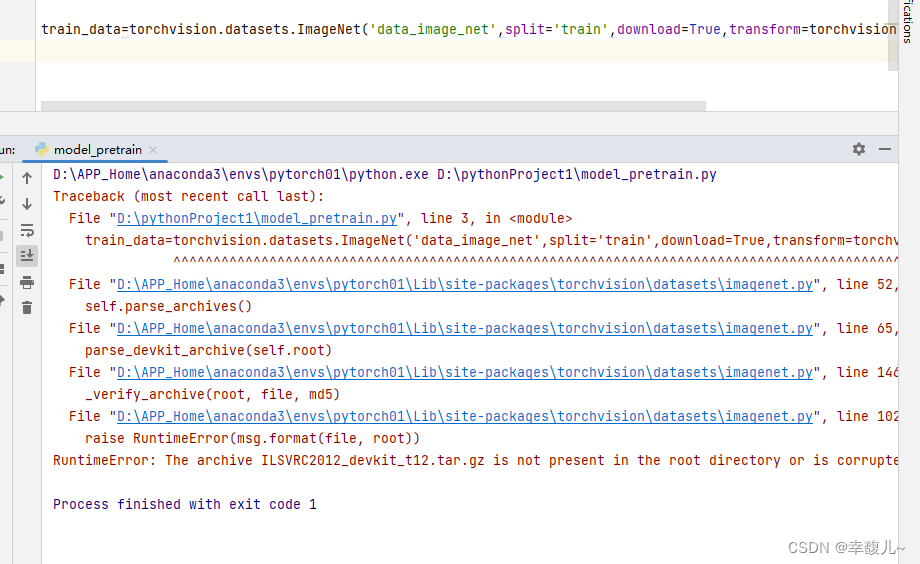
下载数据集
但是发现并不能下载,该数据集很大,不适合用于学习
模型的保存与加载
1. 不仅保存了网络模型的结构,也保存了网络模型的参数
保存模型
vgg16=torchvision.models.vgg16(pretrained=False)#使用网络模型的参数没有经过训练
#保存方式1
torch.save(vgg16,'vgg16_method1.pth')
加载模型
import torch
# 方式1-》保存方式1,加载模型
model=torch.load('vgg16_method1.pth')
print(model)

2. VGG模型中的参数保存成字典,不保存结构(官方推荐,与第一种比需要的空间小)
保存模型
#保存方式2
torch.save(vgg16.state_dict(),'vgg16_method2.pth')
加载模型
可以看出来是字典的形式
#方式2
model=torch.load('vgg16_method2.pth')
print(model)

可以加载模型的结构
vgg16=torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load('vgg16_method2.pth'))
print(vgg16)
备注
from model_save import *#其中model_save为要保存的模型