面试数据库八股文十问十答第二期
面试数据库八股文十问十答第二期
作者:程序员小白条,个人博客
相信看了本文后,对你的面试是有一定帮助的!
⭐点赞⭐收藏⭐不迷路!⭐
1.MySQL的主从复制
- MySQL的主从复制是什么?
- MySQL主从复制是一种常见的数据库复制技术,它的目的是将主数据库的更新同步到从数据库中,从而实现数据的备份和负载均衡。
- 原理:MySQL主从复制采用了基于日志的复制机制,即主库将更新操作记录在二进制日志中,从库通过读取主库的二进制日志来复制主库的更新操作。从库接收到主库的更新操作后,会将这些操作应用到自己的数据库中,从而实现数据的同步。
- 主从复制的作用
- 作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
- 业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的评率,提高单个机器的I/O性能。
- 读写分离使数据库能支持更大的并发。在报表中尤其重要。由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。
- 怎么实现主从复制?
- (1)创建主库和从库。(2)在主库上开启二进制日志,并设置唯一的 server-id。(3)在从库上设置唯一的 server-id,并将主库的二进制日志同步到从库中。(4)在从库上创建复制账户,并授权给主库的 IP 地址。(5)在从库上启动复制进程,连接到主库,并开始复制数据。(6)在主库上进行数据更新操作,更新的操作将被记录在二进制日志中。(7)从库接收到主库的更新操作后,将这些操作应用到自己的数据库中,从而实现数据的同步。
- 注意点: 由于主从复制是异步的,从库可能会有一定的延迟,需要根据具体的应用场景进行调整和优化。
2.MySQL存储引擎,MyISAM和InnoDB的特点和使用场景
MySQL常见存储引擎:
InnoDB是MySQL的默认存储引擎,支持ACID事务,具有高并发性、可靠性和稳定性。InnoDB采用MVCC(多版本并发控制)来实现高并发的读写操作,支持行级锁定,可以提高并发性能。InnoDB也支持外键、回滚等特性,适合于事务性应用场景,例如电子商务、金融等。
- MyISAM是一种简单、高效的存储引擎,不支持事务和行级锁定,但具有快速的读取和写入速度,适合于大量查询和少量更新的场景,例如博客、新闻网站等。
- MEMORY存储引擎可以将数据存储在内存中,具有快速的读取和写入速度,但是数据存储在内存中,容易丢失。MEMORY存储引擎适合于对数据进行快速计算和缓存数据的场景。
- NDB Cluster存储引擎是一种分布式存储引擎,具有高可用性和高可伸缩性,可以实现多台服务器之间的数据共享和负载均衡,适合于大型高并发的应用场景,例如电信、游戏等。
- CSV存储引擎将数据存储在文本文件中,具有快速的导入和导出数据的特点,但是不支持事务和索引,适合于对数据进行批量处理的场景。
- ARCHIVE存储引擎是一种存档式存储引擎,可以实现快速的数据压缩和解压缩,适合于存储历史数据或备份数据的场景。InnoDB和MyISAM区别1).MyISAM是非事务安全型的,而InnoDB是事务安全型的。2).MyISAM锁的粒度是表级,而InnoDB支持行级锁定。3).MyISAM支持全文类型索引,而InnoDB不支持全文索引。4).MyISAM相对简单,所以在效率上要优于InnoDB,小型应用可以考虑使用MyISAM。5).MyISAM表是保存成文件的形式,在跨平台的数据转移中使用MyISAM存储会省去不少的麻烦。6).InnoDB表比MyISAM表更安全,可以在保证数据不会丢失的情况下,切换非事务表到事务表(alter table tablename type=innodb)。
3.聚簇索引和非聚簇索引
聚簇索引
聚簇索引又称为主索引,是一种物理排序的索引,它决定了表中数据的物理存储顺序。聚簇索引的叶子节点存储的是数据本身,因此聚簇索引可以快速地定位到数据行。由于聚簇索引决定了数据的物理存储顺序,因此一个表只能有一个聚簇索引。
非聚簇索引
非聚簇索引又称为辅助索引,不影响表中数据的物理存储顺序。非聚簇索引的叶子节点存储的是索引键值以及指向数据行的指针,因此需要通过索引键值查找数据行。一个表可以有多个非聚簇索引。
聚簇索引和非聚簇索引的使用场景不同,需要根据具体的应用场景来选择。一般来说,如果需要经常进行范围查询或聚合计算,那么就应该使用聚簇索引。如果需要经常用于查询和排序,那么就应该使用非聚簇索引。
需要注意的是,虽然聚簇索引的查询速度快,但是由于每次插入和更新数据都会改变数据的物理存储顺序,因此会影响性能。在使用聚簇索引时,需要避免频繁的插入和更新操作。同时,在选择索引类型时,需要根据具体的应用场景和需求来综合考虑。
4.b树和b+树的区别
-
在B树中,你可以将键和值存放在内部节点和叶子节点;但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
-
B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
-
由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据也具有更好的缓存命中率。
-
B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
-
但是B树也有优点,其优点在于,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
-
B 树:优点:
-
- 快速的查找和插入操作;
- 适合大数据量、高并发的场景;
- 内部数据结构稳定,能够保证树形结构的可靠性。
-
缺点:
-
- 存储容量较大,需要更多的存储空间;
- 树的高度较高,会导致查询效率降低。
-
使用场景:
-
- 对于需要快速查找、插入操作的大数据量场景,如搜索引擎、数据挖掘等;
- 需要支持并发访问的场景,如金融交易系统等。
-
B+树:优点:
-
- 相对于 B 树,B+树的存储容量较小,更节省存储空间;
- 查询效率更高,更适合大数据量、低并发的场景;
- 内部数据结构更加稳定,能够保证树形结构的可靠性。
-
缺点:
-
- 查找和插入操作的性能比 B 树略低;
- 树的高度较高,会导致查询效率降低。
-
使用场景:
-
- 对于需要高效查询、少量插入和删除操作的大数据量场景,如电子商务网站等;
- 需要支持并发访问的场景,如金融交易系统等。
5.Innodb引擎执行update语句的执行流程?
1.查询解析和优化:当你执行UPDATE语句时,MySQL首先会对查询进行解析,以确定要更新的表和相应的行。然后,它会进行优化,以确定如何执行更新操作。
2.事务的启动:如果你的UPDATE语句没有包含在一个显式的事务中,InnoDB会自动启动一个事务。事务是用来维护数据的一致性和隔离性的机制。
3.锁定行:InnoDB使用行级锁定来确保并发事务不会互相干扰。在执行UPDATE语句时,InnoDB会锁定要更新的行,以防止其他事务同时修改这些行。这可以是排它锁(X锁)或共享锁(S锁),具体取决于事务的隔离级别和行的当前锁定状态。
4.执行更新操作:InnoDB会根据UPDATE语句的条件更新符合条件的行。更新操作将修改数据行中的值。
5.写入redo日志:InnoDB会将更新操作写入事务的redo日志中,以确保数据持久性。这允许数据库在崩溃后恢复到一致的状态。
6.写入binlog日志: 在binlog记录一下逻辑日志,对哪个数据页的哪条数据进行了什么修改。
7.提交事务:如果UPDATE语句没有出现错误,并且没有显式回滚事务,事务将被提交,更新操作将成为持久的。
8.释放锁:在事务提交后,InnoDB会释放之前锁定的行,允许其他事务访问它们。
9.返回结果:UPDATE语句执行完毕后,返回更新的行数或其他相关信息。
6.数据库的两阶段提交是怎么样的?
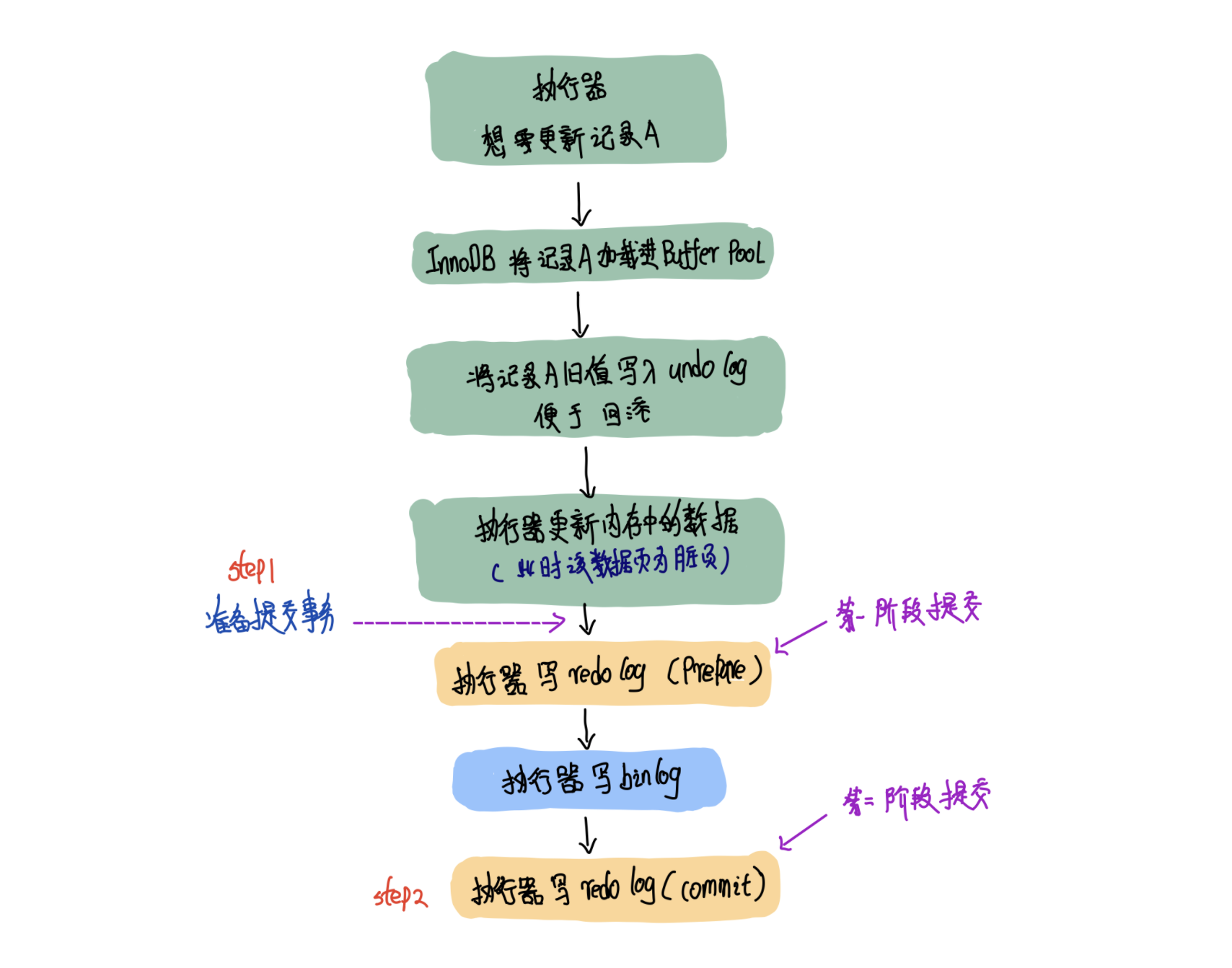
日志文件两阶段提交技术就解决了redo 日志和 binlog 日志文件记录数据不一致的问题
7.MySQL关键字的执行顺序
1.from
-
where
-
group by
-
having
-
select
-
order by
8.什么样的数据不推荐加索引?
1.低选择性的列:低选择性的列指的是具有很少不同值的列。如果一列只有很少几个不同的值,那么为它添加索引可能不会提供显著的性能改进,而且可能浪费存储空间。例如,性别列通常只有两个不同的值(男和女),对其添加索引通常没有太大意义。
2.频繁更新的列:如果一个列经常被更新,特别是大规模的批量更新,那么索引会增加更新操作的开销。每次更新索引列都需要维护索引结构,这可能会导致性能下降。在这种情况下,需要仔细权衡查询性能和更新性能。
3.小表:对于非常小的表,查询通常非常快,即使没有索引。在这种情况下,添加索引可能只会增加存储开销,而不会明显提高性能。
4.不常被查询的列:如果一个列很少被用于查询条件,那么为其添加索引可能没有多大意义。索引应该主要用于加速经常被查询的列。
5.短文本列:对于非常短的文本列,如标签或枚举值,索引的效益可能有限。短文本列通常可以快速地进行全表扫描而不需要索引。
6.临时表:用于存储临时数据的表通常不需要索引,因为它们的生命周期很短暂,不会频繁进行查询操作。
9.索引失效的场景?
1.索引列值为null,索引失效
2.左或左右模糊匹配,因为mysql采用最左匹配原则。
3.查询条件中队索引列使用函数。
4.查询条件对索引列使用表达式计算。
5.如果索引列是字符串,并且条件语句中输入参数是数字,那么索引列会产生隐式类型转换,CAST函数实现,因为等同于堆索引列使函数,导致索引失效,反之索引列是数字,输出参数是字符串,那么不会失效。
6.在 WHERE 子句中,如果在 OR 前的条件列是索引列,但OR后面的条件列不是索引列。
7.数据量极少的情况下,MySQL 不会使用索引,因为全表扫描速度更快。
8.使用 select * 语句,大概率不会走索引,因为不是每一列都加索引。
9.但如果把两个单独建了索引的列,用来做列对比时索引会失效。
10.主键字段使用 Not In 关键字查询数据范围,依然走索引,如果是普通索引使用 Not In 关键字查询数据范围,索引失效。
11.使用 Not Exists 关键字,索引也会失效。
12.使用 Order by 注意最左匹配,并且要加limit或者where关键字,否则索引会失效。
10.介绍一下红黑树和平衡二叉树的区别?
红黑树的规则:
1、根节点为黑色。
2、所有节点都是黑色或红色。
3、所有叶子节点(Null)都是黑色。
4、红色节点的子节点一定是黑色的。
5、任意一个节点到其叶子节点的所有路径上的黑色节点数量相同(黑色完美平衡二叉树)。
- 平衡二叉树的左右子树的高度差绝对值不超过1,但是红黑树在某些时刻可能会超过1,只要符合红黑树的五个条件即可。
- 二叉树只要不平衡就会进行旋转,而红黑树不符合规则时,有些情况只用改变颜色不用旋转,就能达到平衡。