Linux部署HDFS集群
(一)VMware虚拟机中部署
ps、其中node1、node2、node3替换为自己相应节点的IP地址,或者host文件中配置过的主机名,或者看前置准备
或者查看前置准备:Linux部署HDFS集群前置准备
1.下载压缩包
https://www.apache.org/
2.部署配置
3.安装Hadoop
以下操作均在node1节点以root身份执行
-
上传Hadoop安装包到node1节点
-
解压压缩包到/export/server/中
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
- 构建软连接
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
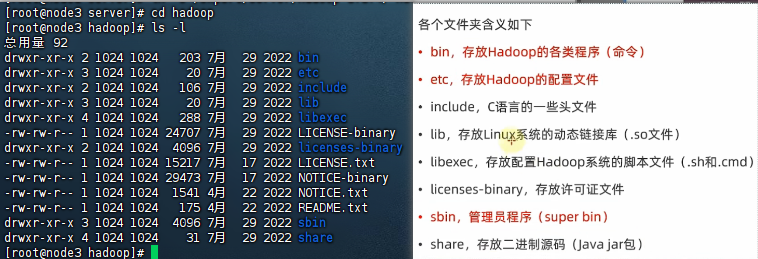
- 进入hadoop安装包内
cd hadoop
ls -l
4.修改配置文件

-
配置workers文件(告诉我们集群里面从节点有哪些)
cd etc/hadoop/ vim workers填入如下内容
node1 node3 node2 -
配置hadoop-env.sh文件
vim hadoop-env.sh填入如下内容
export JAVA_HOME=/export/server/jdk export HADOOP_HOME=/export/server/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_LOG_DIR=$HADOOP_HOME/logs- JAVA_HOME,指明JDK环境的位置在哪
- HADOOP_HOME,指明Hadoop安装位置
- HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
- HADOOP_LOG_DIR,指明Hadoop运行日志目录位置
- 通过记录这些环境变量,来指明上述运行时的重要信息
-
配置core-site.xml文件
vim core-site.xml填入如下内容
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> </configuration>- key: fs.defaultFS
- 含义:HDFS文件系统的网络通讯路径
- 值:hdfs://node1:8020
- 议为hdfs://
- namenode为node1
- namenode通讯端口为8020
- key:io.file.buffer.size
- 含义:操作文件缓冲区大小
- 值:31072bit
- hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)
- 表明DataNode将和node1的8020端口通讯,node1是NameNode所在机器
- 此配置固定了nodel必须启动NameNode进程
-
配置hdfs-site.xml
填入以下内容
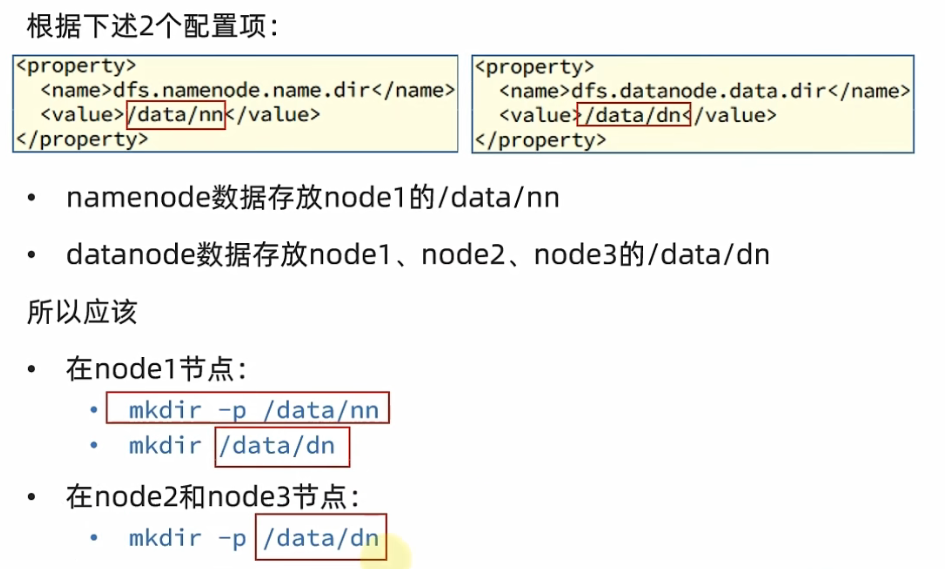
<configuration> <property> <name>dfs.datanode.data.dir.perm</name> <value>700</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/data/nn</value> </property> <property> <name>dfs.namenode.hosts</name> <value>node1,node2,node3</value> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>100</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/dn</value> </property> </configuration>

5.准备数据目录
-
在node1节点
mkdir -p /data/nn mkdir /data/dn -
在node2和node3节点
mkdir -p /data/dn
6.分发Hadoop文件夹
目前,已经基本完成Hadoop的配置操作,可以从node1将hadoop安装文件夹远程复制到node2、node3
-
分发
# 在node1执行如下命令 cd /export/server scp -r hadoop-3.3.4 node2:`pwd`/ scp -r hadoop-3.3.4 node3:`pwd`/ -
在node2执行,为hadoop配置软链接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop -
在node3执行,为hadoop配置软链接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
7.配置环境变量
为了方便我们操作Hadoop,可以将Hadoop的一些脚本、程序配置到PATH中,方便后续使用。
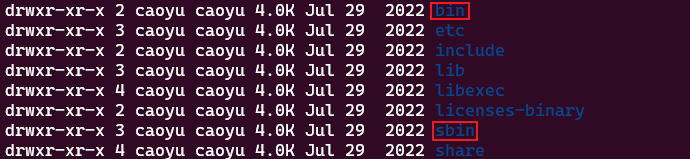
在Hadoop文件夹中的bin、sbin两个文件夹内有许多的脚本和程序,现在来配置一下环境变量
-
编辑环境变量
vim /etc/profile追加如下内容
export HADOOP_HOME=/export/server/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
刷新环境变量
source /etc/profile -
在node2和node3配置同样的环境变量
8.授权为hadoop用户
hadoop部署的准备工作基本完成
为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务
所以,现在需要对文件权限进行授权。
ps:请确保已经提前创建好了hadoop用户(前置准备章节中有讲述),并配置好了hadoop用户之间的免密登录
-
以root身份,在node1、node2、node3三台服务器上均执行如下命令
# 以root身份,在三台服务器上均执行 chown -R hadoop:hadoop /data chown -R hadoop:hadoop /export
9.格式化整个文件系统
前期准备全部完成,现在对整个文件系统执行初始化
-
格式化namenode(node1上执行)
# 确保以hadoop用户执行 su - hadoop # 格式化namenode hadoop namenode -format -
启动
# 一键启动hdfs集群 start-dfs.sh # 一键关闭hdfs集群 stop-dfs.sh # 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行 /export/server/hadoop/sbin/start-dfs.sh /export/server/hadoop/sbin/stop-dfs.sh
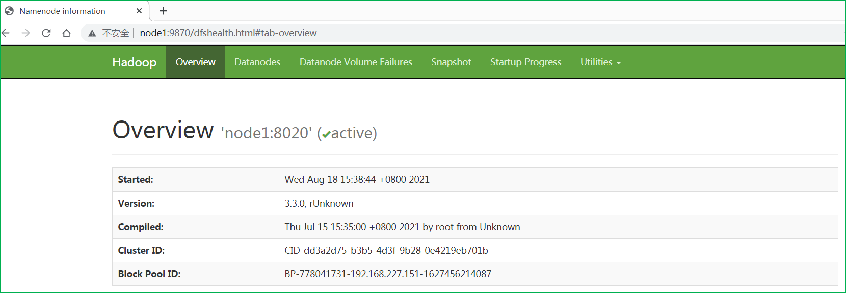
10.查看HDFS WEBUI
启动完成后,可以在浏览器打开:
http://node1:9870,即可查看到hdfs文件系统的管理网页。
11.补充:集群部署常见问题解决
(1)省流自检查
为发挥大家的主观能动性,先将一些常见的出错原因列出来。
这些原因可能导致不同的错误细节,大家可以自行检查是否符合,后面在详细讲解每一种错误的细节。
- 是否遗漏了前置准备章节的相关操作?
- 是否遗漏的将文件夹(Hadoop安装文件夹、/data数据文件夹)chown授权到hadoop用户这一操作
- 是否遗忘了格式化hadoop这一步(hadoop namenode -format)
- 是否是以root用户格式化的hadoop
- 是否以root启动过hadoop,后续以hadoop用户启动出错
- 是否确认workers文件内,配置了node1、node2、node3三个节点
- 是否在/etc/profile内配置了HADOOP_HOME环境变量,并将 H A D O O P H O M E / b i n 和 HADOOP_HOME/bin和 HADOOPHOME/bin和HADOOP_HOME/sbin加入PATH变量
- 是否遗忘了软链接,但环境变量的配置的HADOOP_HOME确是:/export/server/hadoop
- 是否确认配置文件内容的准确(一个字符都不错),并确保三台机器的配置文件均OK
…
(2)详细细节版
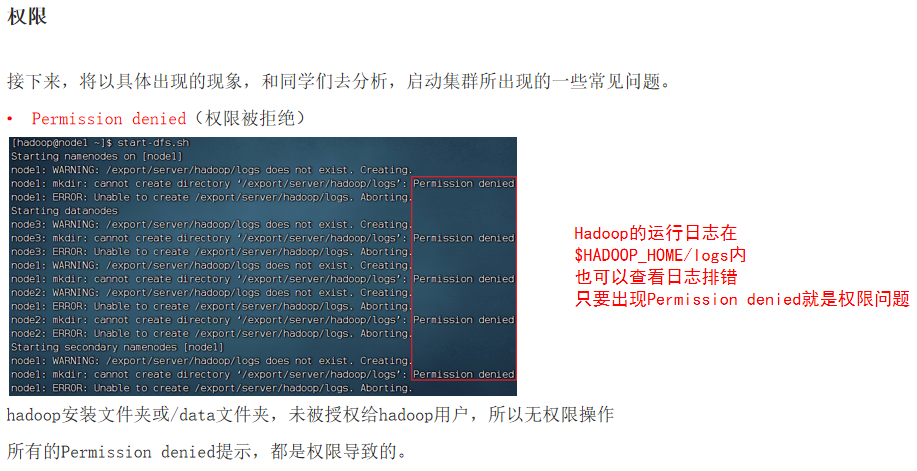
①Permission denied
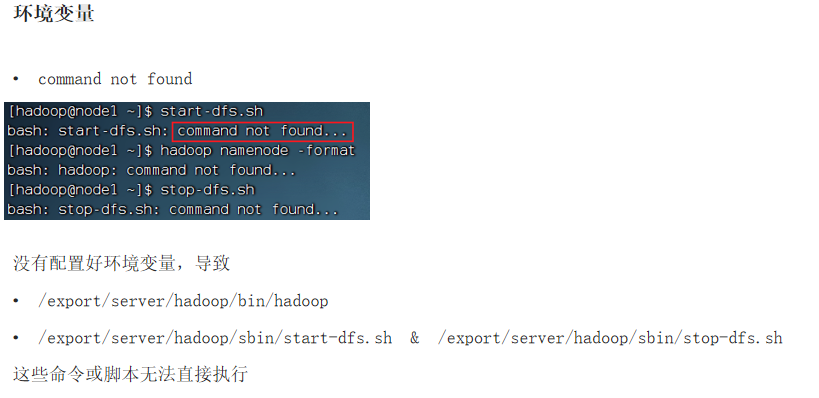
②command not found
③workers文件

④NameNode is not formatted
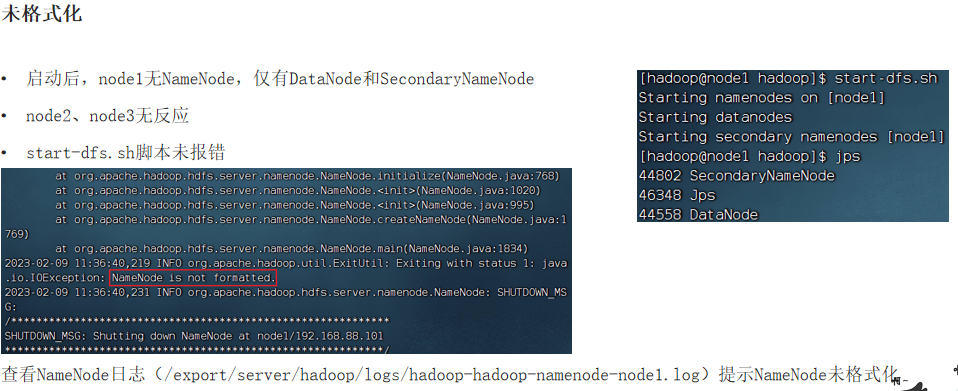
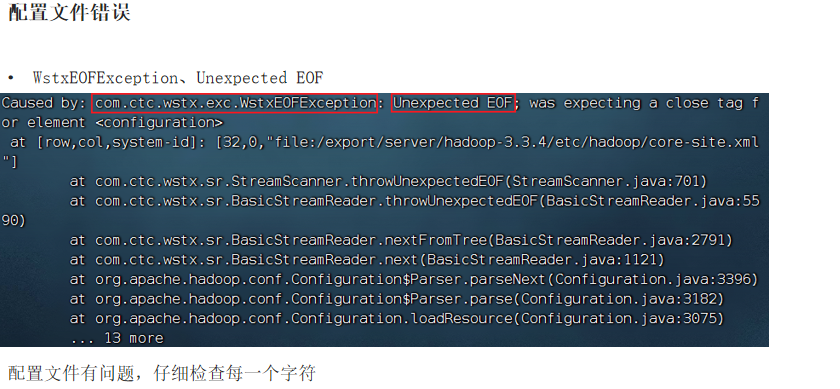
⑤WstxEOFException、Unexpected EOF