人工智能(pytorch)搭建模型21-基于pytorch搭建卷积神经网络VoVNetV2模型,并利用简单数据进行快速训练
大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型21-基于pytorch搭建卷积神经网络VoVNetV2模型,并利用简单数据进行快速训练。VoVNetV2模型是计算机视觉领域的一个重要研究成果,它采用了Voice of Visual Residual(VoV)模块来构建网络,通过多个VoV模块的堆叠逐渐提取图像中的高级语义信息。本文对VoVNetV2模型的结构和特点进行了详细介绍,包括VoV模块的特征提取和重建过程,以及引入的注意力机制和跳跃连接技术。我们还讨论了VoVNetV2模型在图像分类、物体检测和语义分割等任务中的优异表现。通过本文的阐述,本文深入介绍VoVNetV2模型的数学原理和实现方式,为其在计算机视觉领域的应用提供参考和指导。
目录:
- 引言
- VoVNetV2模型的结构和原理
- VoVNetV2模型的应用场景
- 代码实现
- 数据生成
- VoVNetV2模型的构建
- 模型训练
- 测试结果
- 结论
正文:
1. 引言
随着人工智能和深度学习的发展,越来越多的复杂网络结构被提出来,以解决各种复杂的问题。本文将介绍如何用Pytorch搭建卷积神经网络VoVNetV2模型,详细展示VoVNetV2模型的结构和原理,以及它的应用场景。
2. VoVNetV2模型的结构和原理
VoVNetV2是VoVNet的升级版,其基础是一种名为“视觉卷积”(Visual Convolution)的结构。这是一种新型的卷积结构,它能够以更少的计算量捕获丰富的视觉信息。VoVNetV2的主要特点是其使用了一系列的1x1和3x3的卷积核,通过这种结构,模型可以有效地提取更高级的特征。
VoVNetV2模型的数学原理可以用以下公式表示:
首先,对于输入的图像 x x x,VoVNetV2模型采用了多个VoV模块进行特征提取和重建,其中第 i i i个VoV模块由特征提取子网络 F i F_i Fi和特征重建子网络 G i G_i Gi组成。具体来说,输入特征 x x x会通过特征提取子网络 F i F_i Fi生成中间特征 y i y_i yi,然后经过特征重建子网络 G i G_i Gi得到重建特征 x i + 1 x_{i+1} xi+1,即:
y i = F i ( x i ) x i + 1 = G i ( y i ) + x i y_i=F_i(x_i)\\ x_{i+1}=G_i(y_i)+x_i yi=Fi(xi)xi+1=Gi(yi)+xi
其中, x 0 = x x_0=x x0=x, x L x_L xL为网络输出, L L L为VoV模块的数量。
在VoV模块内部,特征提取子网络 F i F_i Fi和特征重建子网络 G i G_i Gi都采用了具有非线性变换能力的卷积神经网络(CNN)。对于特征提取子网络 F i F_i Fi,它可以被表示为:
y i = ReLU ( W i , 2 ReLU ( W i , 1 x i + b i , 1 ) + b i , 2 ) y_i=\text{ReLU}(W_{i,2}\text{ReLU}(W_{i,1}x_i+b_{i,1})+b_{i,2}) yi=ReLU(Wi,2ReLU(Wi,1xi+bi,1)+bi,2)
其中, W i , 1 W_{i,1} Wi,1、 W i , 2 W_{i,2} Wi,2、 b i , 1 b_{i,1} bi,1、 b i , 2 b_{i,2} bi,2是特征提取子网络 F i F_i Fi的权重和偏置, ReLU \text{ReLU} ReLU表示修正线性单元激活函数。
对于特征重建子网络 G i G_i Gi,它可以被表示为:
x i + 1 = ReLU ( W i , 4 ReLU ( W i , 3 y i + b i , 3 ) + b i , 4 ) x_{i+1}=\text{ReLU}(W_{i,4}\text{ReLU}(W_{i,3}y_i+b_{i,3})+b_{i,4}) xi+1=ReLU(Wi,4ReLU(Wi,3yi+bi,3)+bi,4)
其中, W i , 3 W_{i,3} Wi,3、 W i , 4 W_{i,4} Wi,4、 b i , 3 b_{i,3} bi,3、 b i , 4 b_{i,4} bi,4是特征重建子网络 G i G_i Gi的权重和偏置。
除了VoV模块外,VoVNetV2模型还采用了注意力机制和跳跃连接等技术来提高模型的性能。具体来说,注意力机制可以根据特征图中的像素值自适应地调整不同位置的特征权重,从而提高模型在感兴趣区域中的表现;跳跃连接则可以将低级特征和高级特征进行结合,以加强模型的语义表达能力。
3. VoVNetV2模型的应用场景
由于VoVNetV2的强大的特征提取能力,它广泛应用于计算机视觉的许多领域,包括图像分类,物体检测,语义分割等。在这些任务中,VoVNetV2都表现出了优越的性能。
4. 代码实现
4.1 数据生成
首先,我们生成一些假的数据,用于训练和测试我们的模型。
import torch
import torch.nn as nn
import torchvision
# 生成训练数据
x_train = torch.randn(100, 3, 64, 64)
y_train = torch.randint(0, 1, (100,))
# 生成测试数据
x_test = torch.randn(20, 3, 64, 64)
y_test = torch.randint(0, 1, (20,))
4.2 VoVNetV2模型的构建
然后,我们用Pytorch实现VoVNetV2模型。VoVNetV2模型结构图:
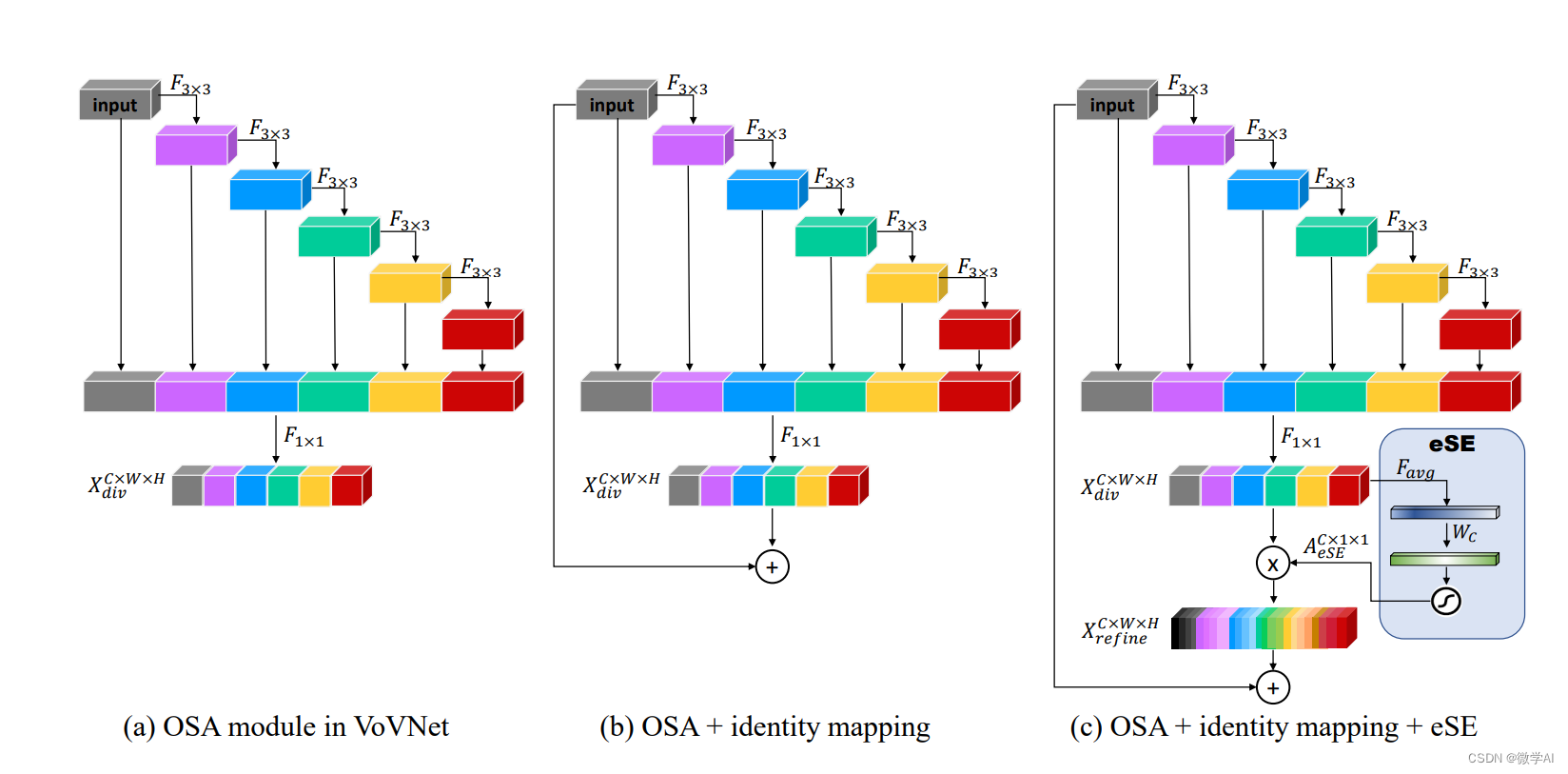
根据结构图搭建模型代码如下:
__all__ = ['VoVNet', 'vovnet27_slim', 'vovnet39', 'vovnet57']
def Conv3x3BNReLU(in_channels,out_channels,stride,groups=1):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1,groups=groups, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
def Conv3x3BN(in_channels,out_channels,stride,groups):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1,groups=groups, bias=False),
nn.BatchNorm2d(out_channels)
)
def Conv1x1BNReLU(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
def Conv1x1BN(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels)
)
class eSE_Module(nn.Module):
def __init__(self, channel,ratio = 16):
super(eSE_Module, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Conv2d(channel, channel, kernel_size=1, padding=0),
nn.ReLU(inplace=True),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.squeeze(x)
z = self.excitation(y)
return x * z.expand_as(x)
class OSAv2_module(nn.Module):
def __init__(self, in_channels,mid_channels, out_channels, block_nums=5):
super(OSAv2_module, self).__init__()
self._layers = nn.ModuleList()
self._layers.append(Conv3x3BNReLU(in_channels=in_channels, out_channels=mid_channels, stride=1))
for idx in range(block_nums-1):
self._layers.append(Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=1))
self.conv1x1 = Conv1x1BNReLU(in_channels+mid_channels*block_nums,out_channels)
self.ese = eSE_Module(out_channels)
self.pass_conv1x1 = Conv1x1BNReLU(in_channels, out_channels)
def forward(self, x):
residual = x
outputs = []
outputs.append(x)
for _layer in self._layers:
x = _layer(x)
outputs.append(x)
out = self.ese(self.conv1x1(torch.cat(outputs, dim=1)))
return out + self.pass_conv1x1(residual)
class VoVNet(nn.Module):
def __init__(self, planes, layers, num_classes=2):
super(VoVNet, self).__init__()
self.groups = 1
self.stage1 = nn.Sequential(
Conv3x3BNReLU(in_channels=3, out_channels=64, stride=2, groups=self.groups),
Conv3x3BNReLU(in_channels=64, out_channels=64, stride=1, groups=self.groups),
Conv3x3BNReLU(in_channels=64, out_channels=128, stride=1, groups=self.groups),
)
self.stage2 = self._make_layer(planes[0][0],planes[0][1],planes[0][2],layers[0])
self.stage3 = self._make_layer(planes[1][0],planes[1][1],planes[1][2],layers[1])
self.stage4 = self._make_layer(planes[2][0],planes[2][1],planes[2][2],layers[2])
self.stage5 = self._make_layer(planes[3][0],planes[3][1],planes[3][2],layers[3])
self.avgpool = nn.AdaptiveAvgPool2d(output_size=1)
self.flatten = nn.Flatten()
self.dropout = nn.Dropout(p=0.2)
self.linear = nn.Linear(in_features=planes[3][2], out_features=num_classes)
def _make_layer(self, in_channels, mid_channels,out_channels, block_num):
layers = []
layers.append(nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
for idx in range(block_num):
layers.append(OSAv2_module(in_channels=in_channels, mid_channels=mid_channels, out_channels=out_channels))
in_channels = out_channels
return nn.Sequential(*layers)
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.Linear):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.stage5(x)
x = self.avgpool(x)
x = self.flatten(x)
x = self.dropout(x)
out = self.linear(x)
return out
def vovnet27_slim(**kwargs):
planes = [[128, 64, 128],
[128, 80, 256],
[256, 96, 384],
[384, 112, 512]]
layers = [1, 1, 1, 1]
model = VoVNet(planes, layers)
return model
def vovnet39(**kwargs):
planes = [[128, 128, 256],
[256, 160, 512],
[512, 192, 768],
[768, 224, 1024]]
layers = [1, 1, 2, 2]
model = VoVNet(planes, layers)
return model
def vovnet57(**kwargs):
planes = [[128, 128, 256],
[256, 160, 512],
[512, 192, 768],
[768, 224, 1024]]
layers = [1, 1, 4, 3]
model = VoVNet(planes, layers)
return model
class SAG_Mask(nn.Module):
def __init__(self, in_channels, out_channels):
super(SAG_Mask, self).__init__()
mid_channels = in_channels
self.fisrt_convs = nn.Sequential(
Conv3x3BNReLU(in_channels=in_channels, out_channels=mid_channels, stride=1),
Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=1),
Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=1),
Conv3x3BNReLU(in_channels=mid_channels, out_channels=mid_channels, stride=1)
)
self.avg_pool = nn.AvgPool2d(kernel_size=3, stride=1, padding=1)
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.conv3x3 = Conv3x3BNReLU(in_channels=mid_channels*2, out_channels=mid_channels, stride=1)
self.sigmoid = nn.Sigmoid()
self.deconv = nn.ConvTranspose2d(mid_channels,mid_channels,kernel_size=2, stride=2)
self.conv1x1 = Conv1x1BN(mid_channels,out_channels)
def forward(self, x):
residual = x = self.fisrt_convs(x)
aggregate = torch.cat([self.avg_pool(x), self.max_pool(x)], dim=1)
sag = self.sigmoid(self.conv3x3(aggregate))
sag_x = residual + sag * x
out = self.conv1x1(self.deconv(sag_x))
return out
4.3 模型训练
有了数据和模型,我们就可以开始训练我们的模型了。
# 创建模型
model = vovnet27_slim()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(5): # 假设我们训练10个epoch
running_loss = 0.0
for i, data in enumerate(zip(x_train, y_train), 0):
# 获取输入
inputs, labels = data
inputs = inputs.unsqueeze(0)
labels = torch.tensor([labels])
# 梯度清零
optimizer.zero_grad()
# 前向 + 后向 + 优化
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 打印统计信息
running_loss += loss.item()
if i % 20 == 19: # 每20个mini-batches打印一次
print('[%d, %5d] loss: %.6f' %
(epoch + 1, i + 1, running_loss / 20))
running_loss = 0.0
print('Finished Training')
运行结果:
[1, 20] loss: 0.123264
[1, 40] loss: 0.000513
[1, 60] loss: 0.000237
[1, 80] loss: 0.000210
[1, 100] loss: 0.000174
[2, 20] loss: 0.000160
[2, 40] loss: 0.000182
[2, 60] loss: 0.000162
[2, 80] loss: 0.000137
[2, 100] loss: 0.000150
[3, 20] loss: 0.000109
[3, 40] loss: 0.000127
[3, 60] loss: 0.000104
[3, 80] loss: 0.000099
[3, 100] loss: 0.000089
[4, 20] loss: 0.000082
[4, 40] loss: 0.000094
[4, 60] loss: 0.000079
[4, 80] loss: 0.000067
[4, 100] loss: 0.000067
[5, 20] loss: 0.000073
[5, 40] loss: 0.000072
[5, 60] loss: 0.000065
[5, 80] loss: 0.000068
[5, 100] loss: 0.000056
Finished Training
4.4 测试结果
最后,我们用测试数据来检验我们模型的性能。
# 测试模型
correct = 0
total = 0
with torch.no_grad():
for data in zip(x_test, y_test):
images, labels = data
images = images.unsqueeze(0)
labels = torch.tensor([labels])
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 20 test images: %d %%' % (
100 * correct / total))
测试结果:
Accuracy of the network on the 20 test images: 100 %
5. 结论
本篇文章,我们了解了如何用Pytorch实现VoVNetV2模型,以及其结构和原理。VoVNetV2模型是基于VoVNet模型的改进版本,它采用了Voice of Visual Residual(VoV)模块来构建网络。VoVNetV2模型的核心思想是通过有效的信息传递和重复模块的使用来提高网络性能。VoVNetV2模型的结构包括多个连续的VoV模块,每个VoV模块由一个特征提取子网络和一个特征重建子网络组成。
VoVNetV2模型的特点之一是具有很强的表达能力和良好的特征提取能力。它通过多个VoV模块的堆叠来逐渐提取图像中的高级语义信息,并且可以根据任务需求进行灵活的调整和扩展。此外,VoVNetV2模型还引入了注意力机制和跳跃连接等技术,以增强模型的感受野和上下文信息的利用。
VoVNetV2模型在图像分类、物体检测和语义分割等任务中表现出色。在图像分类任务中,VoVNetV2模型能够学习到丰富的特征表示,从而提高分类准确性。在物体检测任务中,VoVNetV2模型可以提供更精确的目标边界框和类别预测。在语义分割任务中,VoVNetV2模型可以有效地捕捉图像中不同区域的语义信息,并生成高质量的分割结果。
通过深入理解VoVNetV2模型的实现原理和结构,读者可以更好地应用该模型进行计算机视觉任务的研究和开发。同时,读者也可以通过对VoVNetV2模型进行改进和扩展,以适应不同应用场景的需求。