yolov5实现多图形识别和图像训练
1.使用了yolov7,检测更好,但是训练上有问题,运行不起来,转了一圈发现yolov5是应用更广泛使用简单
2.怎么使用
//下载代码
https://github.com/ultralytics/yolov5
//安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
//按照他的示例就可以运行起来
//直接打开电脑的摄像头进行识别

//我尝试了yolov8和yolov7.pt权重文件不能向上兼容,运行不起来

3.怎么训练图像
1.先下载一个labelImg用于标注我们要识别的物体的位置
引用博客,教你使用这个工具制作
https://blog.csdn.net/weixin_43402278/article/details/131474784?ops_request_misc=&request_id=&biz_id=102&utm_term=lableimg%E6%80%8E%E4%B9%88%E6%89%93%E6%A0%87%E7%AD%BEyolov5&utm_medium=distribute.pc_search_result.none-task-blog-2blogsobaiduweb~default-1-131474784.nonecase&spm=1018.2226.3001.4450
2.运行一次train得到官方的案例下载的数据集是和我们的项目同级的


//源文件注释掉download那句
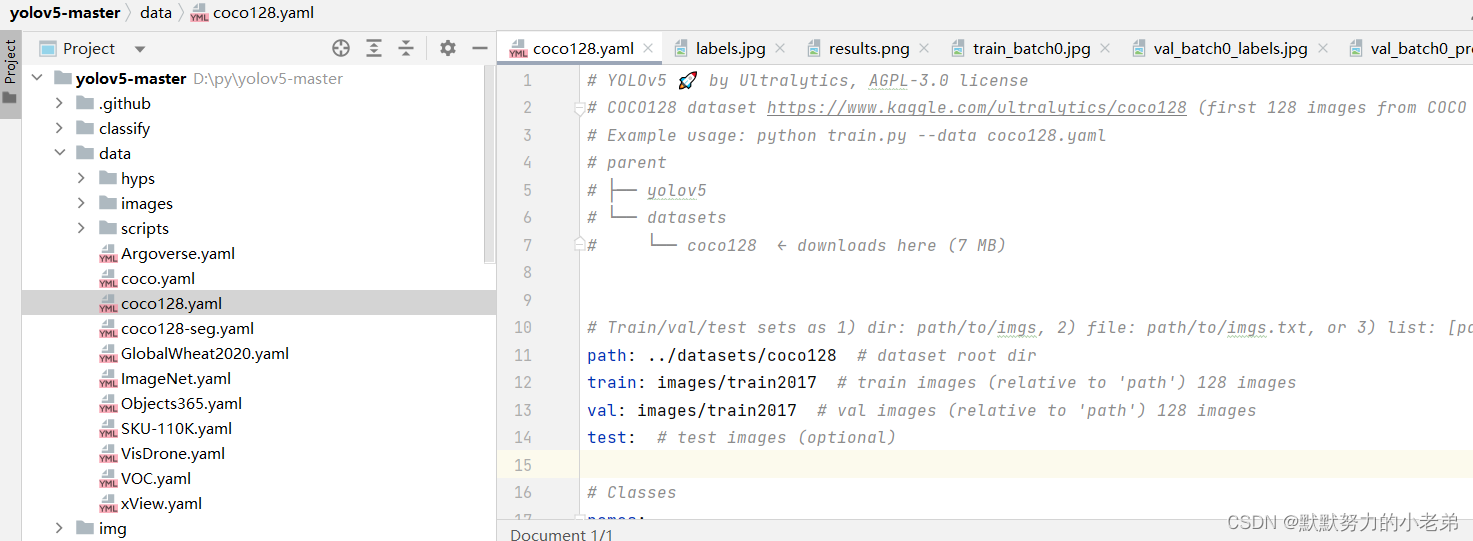
#我已经删除掉了
3.在labelImage生成的文件复制到我们的文件夹 //image放图片 //labels放我们labelimage生成的文件

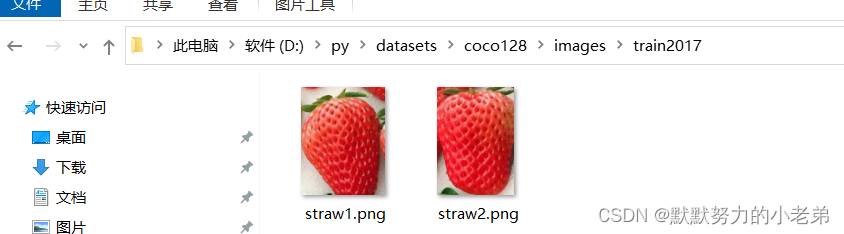
#第一个参数15是对应着类别我们需要修改,其他的是代表识别物体的位置(如,中心x/宽, 中心坐标y/高 为了降低数据大小优化速度)
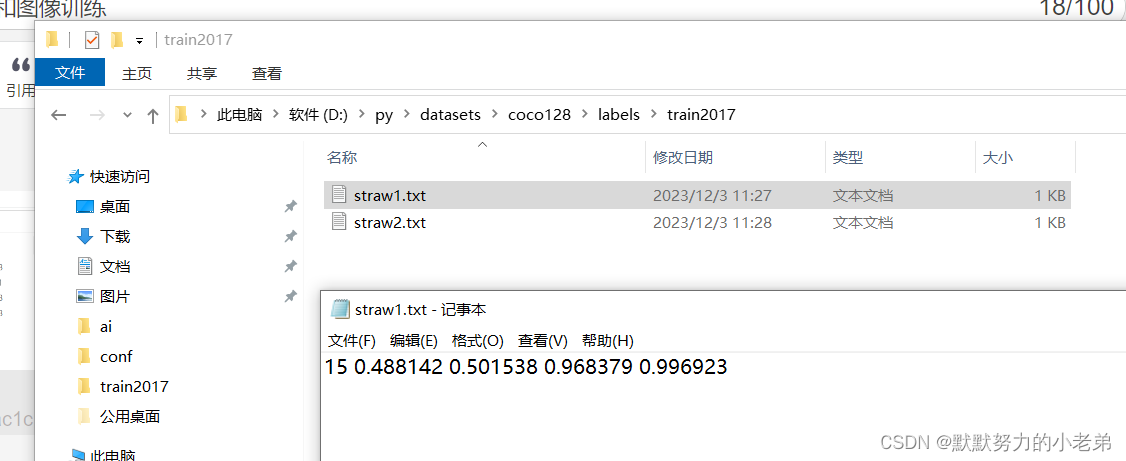
#就是yml文件names的下标
#开始训练

#训练的结果输出到 runs/train/expxx 每次训练xx会加一
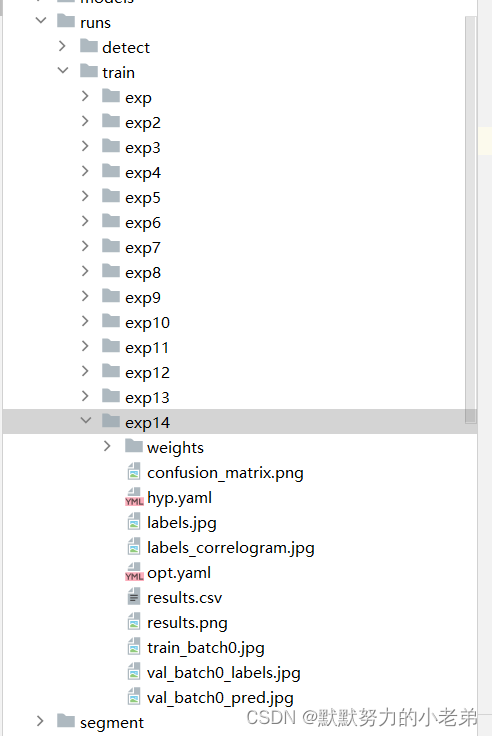
#best是最优的训练结果

#对训练的权重文件进行识别图片,由于训练数据太少,读者可以自行测试