训练 CNN 对 CIFAR-10 数据中的图像进行分类-keras实现
1. 加载 CIFAR-10 数据库
import keras
from keras.datasets import cifar10
# 加载预先处理的训练数据和测试数据
(x_train, y_train), (x_test, y_test) = cifar10.load_data()2. 可视化前 24 个训练图像
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure(figsize=(20,5))
for i in range(36):
ax = fig.add_subplot(3, 12, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_train[i]))
3. 通过将每幅图像中的每个像素除以 255 来调整图像比例
事实上,代价函数的形状是一个碗,但如果特征的比例非常不同,它也可能是一个拉长的碗。下图显示了梯度下降法在特征 1 和特征 2 比例相同的训练集上的应用(左图),以及在特征 1 的值远小于特征 2 的训练集上的应用(右图)。
Tips : 使用梯度下降法时,应确保所有特征的比例相似,以加快训练速度,否则收敛时间会更长。
# rescale [0,255] --> [0,1]
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/2554. 将数据集分为训练集、测试集和验证集
from keras.utils import to_categorical
# 对标签进行一次热编码
num_classes = len(np.unique(y_train))
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# 将训练集分为训练集和验证集
(x_train, x_valid) = x_train[5000:], x_train[:5000]
(y_train, y_valid) = y_train[5000:], y_train[:5000]
# 打印训练集的形状
print('x_train shape:', x_train.shape)
# 打印训练、验证和测试图像的数量
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
print(x_valid.shape[0], 'validation samples')
5. 定义模型架构
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=2, padding='same', activation='relu',
input_shape=(32, 32, 3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(10, activation='softmax'))
model.summary()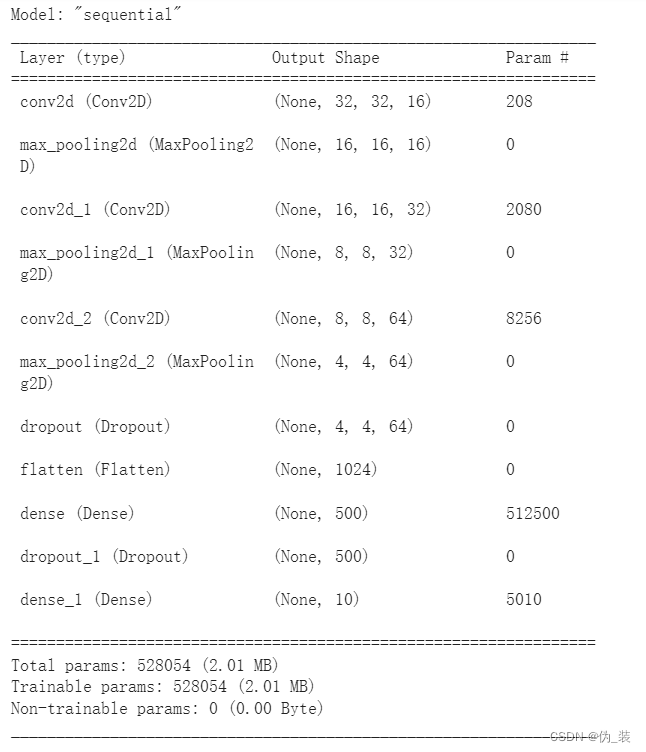
6. 编译模型
# compile the model
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])7. 训练模型
from keras.callbacks import ModelCheckpoint
# 训练模型
checkpointer = ModelCheckpoint(filepath='model.weights.best.hdf5', verbose=1, save_best_only=True)
hist = model.fit(x_train, y_train, batch_size=32, epochs=100,
validation_data=(x_valid, y_valid), callbacks=[checkpointer],
verbose=2, shuffle=True)
8. 加载验证精度最高的模型
# 加载验证精度最高的权重
model.load_weights('model.weights.best.hdf5')9. 计算测试集的分类精度
# 评估和打印测试精度
score = model.evaluate(x_test, y_test, verbose=0)
print('\n', 'Test accuracy:', score[1])10. 可视化一些预测
这可能会让你对网络错误分类某些对象的原因有所了解。
# 在测试集上得到预测
y_hat = model.predict(x_test)
# 定义文本标签 (source: https://www.cs.toronto.edu/~kriz/cifar.html)
cifar10_labels = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']# 绘制测试图像的随机样本、预测标签和基本真实图像
fig = plt.figure(figsize=(20, 8))
for i, idx in enumerate(np.random.choice(x_test.shape[0], size=32, replace=False)):
ax = fig.add_subplot(4, 8, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_test[idx]))
pred_idx = np.argmax(y_hat[idx])
true_idx = np.argmax(y_test[idx])
ax.set_title("{} ({})".format(cifar10_labels[pred_idx], cifar10_labels[true_idx]),
color=("green" if pred_idx == true_idx else "red"))