【powerjob】定时任务调度器 xxl-job和powerjob对比
文章目录
- 同类产品对比
- 资源及部署相关
- 资源占用对比:
- 部署方式:
- xxl job :
- 调度器:
- 执行器:
- powerjob:
- 调度器:
- 执行器:
- 总结
背景:
目前系统的定时任务主要通过Spring框架自带的@Scheduled注解实现 ,这种方式代码简单, 能快速实现基本的定时任务需求。但随着系统规模的扩大和定时任务数量的增加, 原有实现方式暴露出以下问题:
- 在多实例情况下,同一定时任务会在多台服务器上都执行,导致资源浪费,且多任务间没有协调和管理。
- 缺乏任务调度中心,监控和管控功能较弱, 定时任务的触发时点改变,需要重新发布才能修改这些条件。
博主最近上手的项目 后续需要用到定时任务调度器 迁移定时任务, 刚好想到之前用过、听过的两款主流调度器 特此做一个调研记录。
同类产品对比
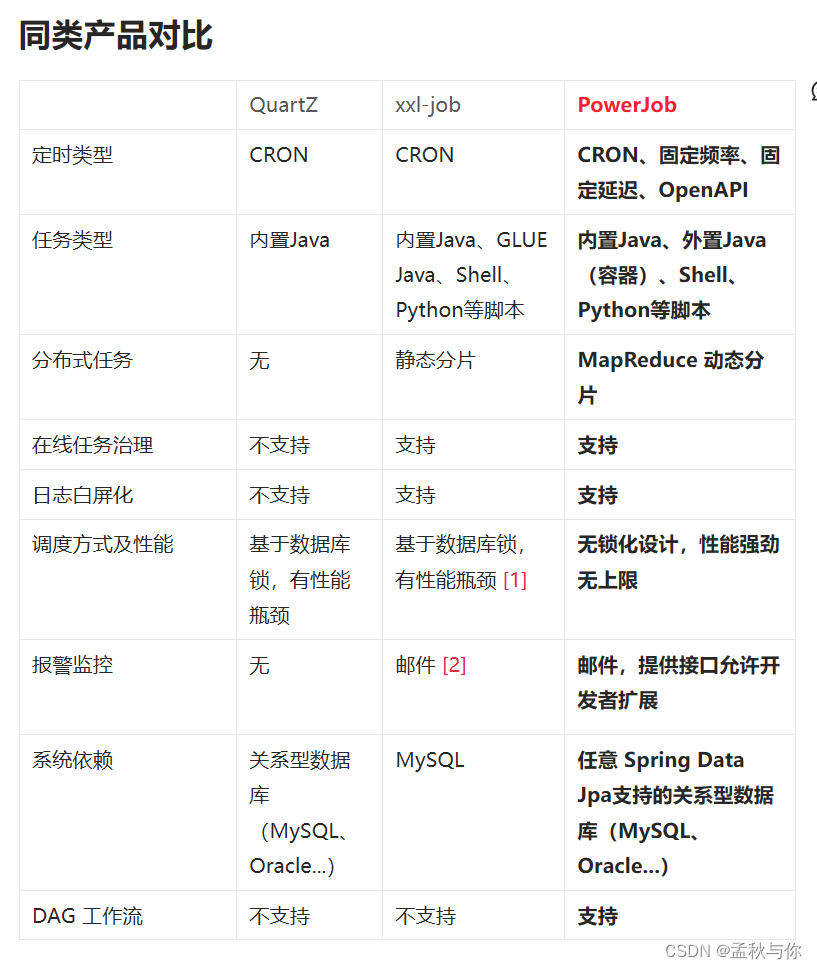
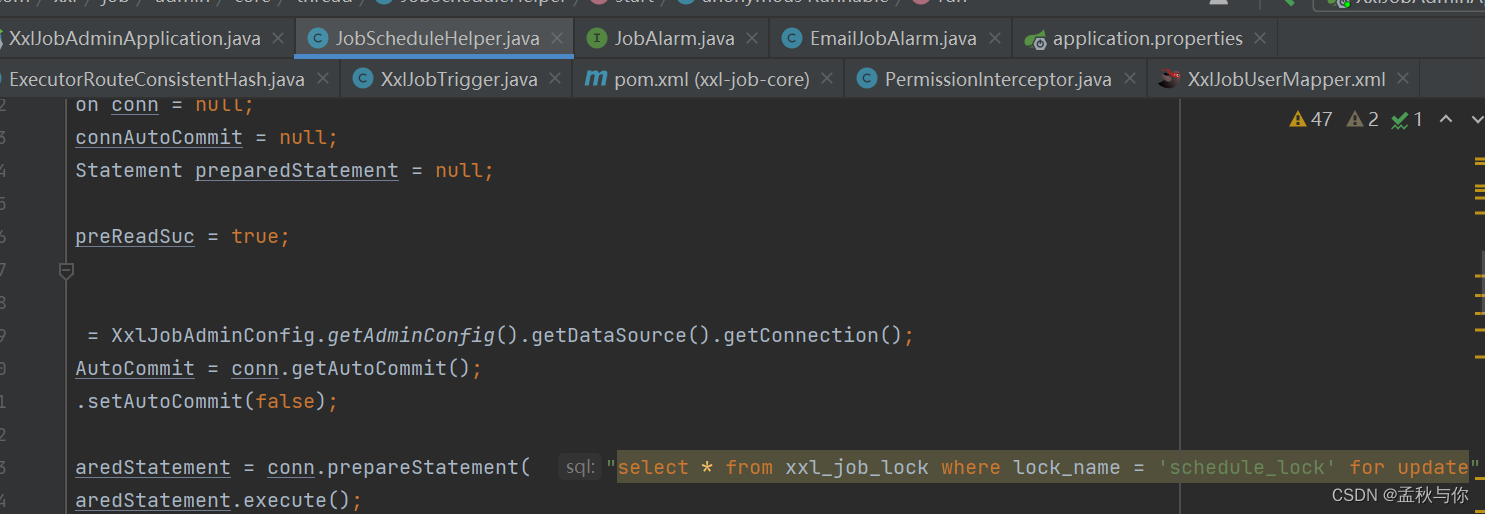
[1] 注: 通过for update锁表
[2] 注:其实可以自己实现 com.xxl.job.admin.core.alarm.JobAlarm 接口推至钉钉等。
QuartZ由于不支持分布式任务,不参与讨论。
重点针对xxl job 与 powerjob 进行对比。
下面给出更多直观的对比:
-
PowerJob支持更多的定时信息配置 ,xxl job仅支持cron

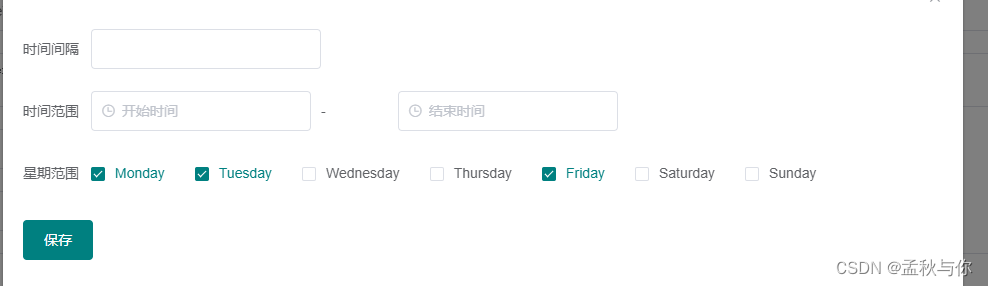
-
PowerJob支持设置任务的生命周期,xxl job不支持

-
PowerJob可以更好的查看执行器的机器信息 (注:内存为jvm内存),xxl job不支持

-
github项目最后维护时间对比:(截至目前,2023.12.01)

-
工作流支持: xxl job支持父子任务执行; powerjob可以支持多级,甚至可以针对条件判断选择执行
资源及部署相关
资源占用对比:
-
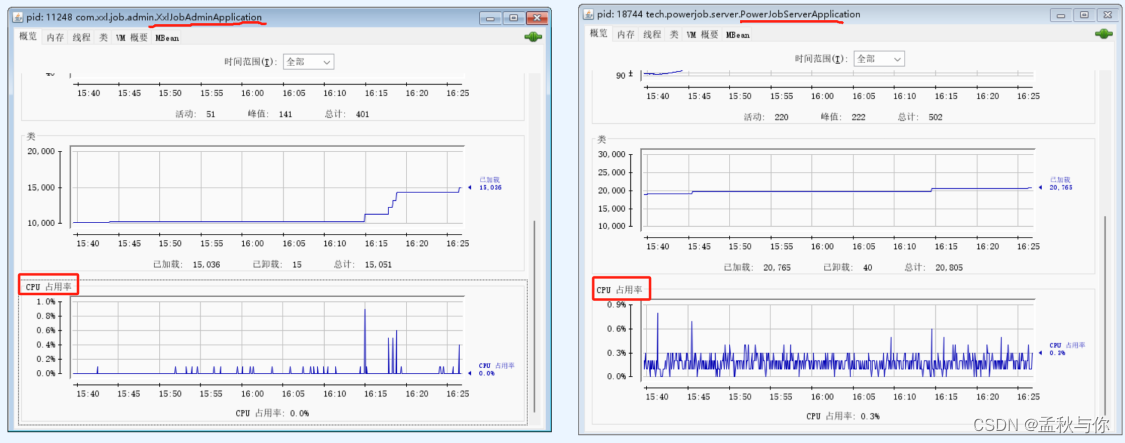
cpu使用对比: xxl job(左) powerjob(右),powerjob整体占用较多,但CPU占用率并不高 可以忽略不计。
-
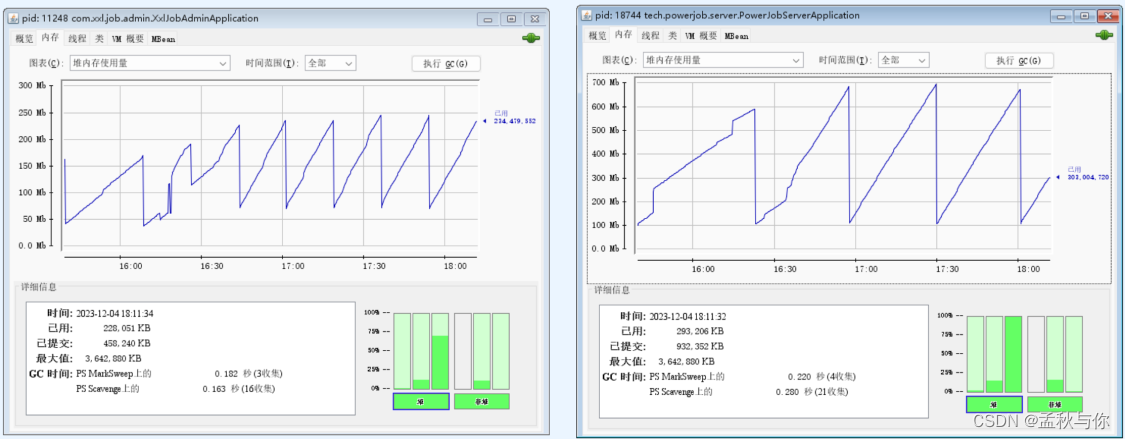
JVM 堆内存对比: xxl job(左) powerjob(右) , 因为powerjob有更多的功能 相应的资源消耗也会更多,xxl job峰值约为250M ,powerjob峰值约为700M, 且powerjob内存占用长期大于xxl job
部署方式:
xxl job :
调度器:
-
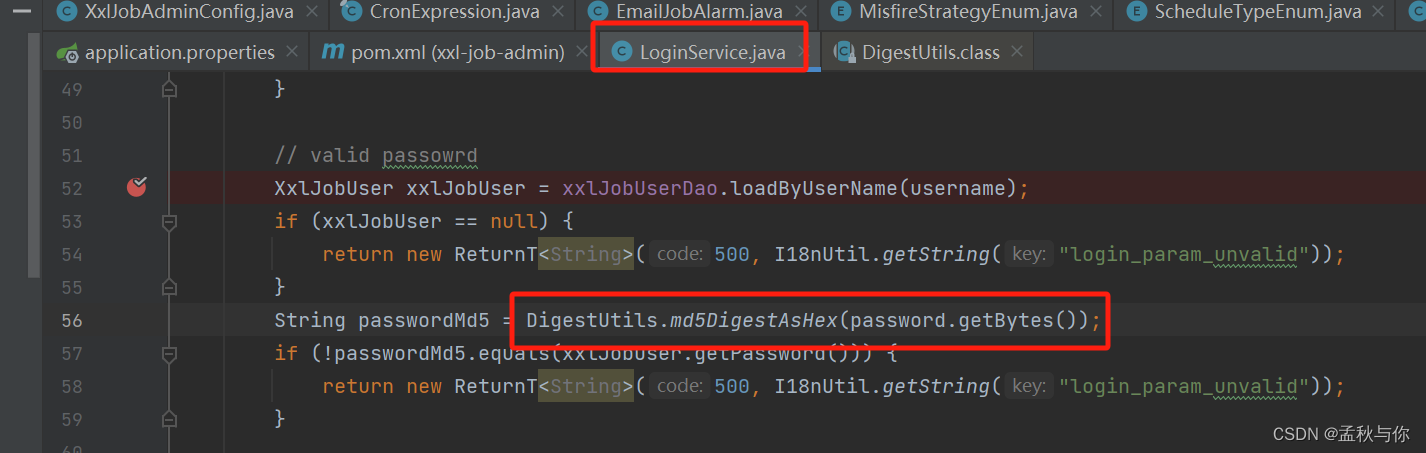
手动执行xxl job的SQL脚本创建库表, SQL语句默认数据库名是xxl_job,用户可自己选择xxl job库表是否要和业务表放在同一个库,脚本会在xxl_job_user表中默认插入admin账号 密码为123456 ,如果后续需要修改密码,可以手动在数据库里面修改password ,数据库表的密码是MD5加密后的结果(32位小写)
-
在xxl-job-admin application.properties修改数据源相关配置,定义accessToken (执行器的accessToken与之对应)
xxl.job.accessToken=default_token -
启动xxl-job-admin项目, java -jar xxl-admin-job.jar
执行器:
(执行器通俗点说 即我们的Java项目)
- 引入xxl-job-core依赖
<!-- xxl-job-core -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.0</version>
</dependency>
- yml配置:addresses为调度器地址,accessToken与上文调度器中的accessToken保持一致,更多解释见注释。
# 执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl:
job:
admin:
addresses: http://192.168.31.165:8080/xxl-job-admin
executor:
# 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
appname: xxl-job-demo
# 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
ip:
#执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
port: 9999
# 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
logpath: E:/log/xxl-jobs/xxl-job/jobhandler
# 执行器日志保存天数 [选填] :值大于3时生效,启用执行器Log文件定期清理功能,否则不生效;
logretentiondays: -1
# 执行器通讯TOKEN [选填]:非空时启用;
accessToken: default_token
- 执行器代码示例
@Component
public class WorkingStartHandler {
/**
* 需要先执行db里面的sql脚本 创建库表
*/
/**
* 新版本注解由原来旧版本的@JobHandler类注解 变成了 @XxlJob 注解
* 且类不需要继承IJobHandler类
*/
@XxlJob("WorkingStartHandler")
public ReturnT<String> execute(String s) throws Exception {
// do something
return ReturnT.SUCCESS;
}
}
- 启动执行器
- 在调度器admin页面添加定时任务并执行
- 执行器可多实例部署,在调度器admin页面的路由策略 推荐使用轮询方式,一致性hash算法在笔者物理机Win11+虚拟机centos stream 8环境中测试发现及其不均衡 ,几乎始终只落在某一台执行器上。
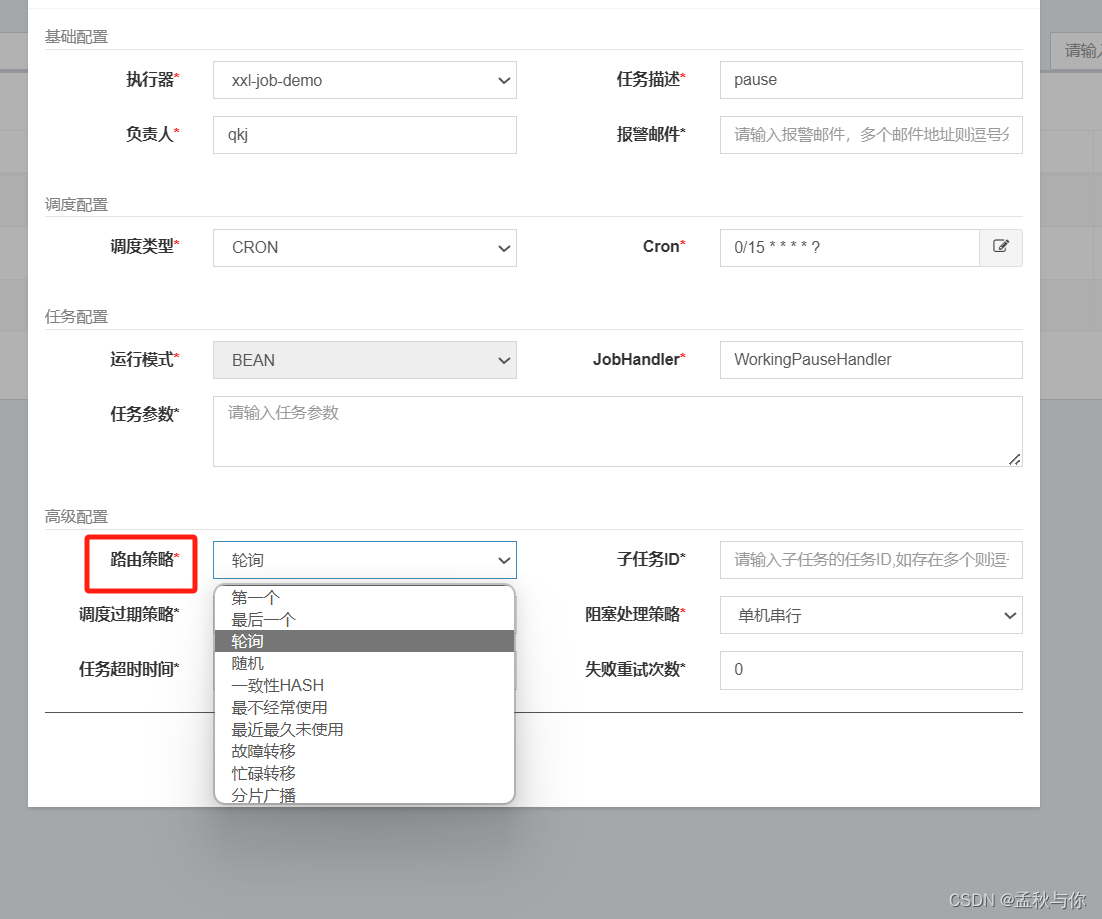
powerjob:
调度器:
- 修改powerjob-server-starter中的application配置文件的数据源配置等, jdbc URL中指定数据库
(如果是新的数据库 即与业务库分离,需要手动创建数据库), 相关表自动创建,无需手动。
需要手动在app_info表中,新增一条记录 填写app_name和password,appname与执行器配置的相对应
调度服务器(powerjob-server)为了支持环境隔离,分别采用了日常(application-daily.properties)、预发(application-pre.properties)和线上(application-product.properties)三套配置文件,请根据实际需求进行修改,以下为配置文件详解。
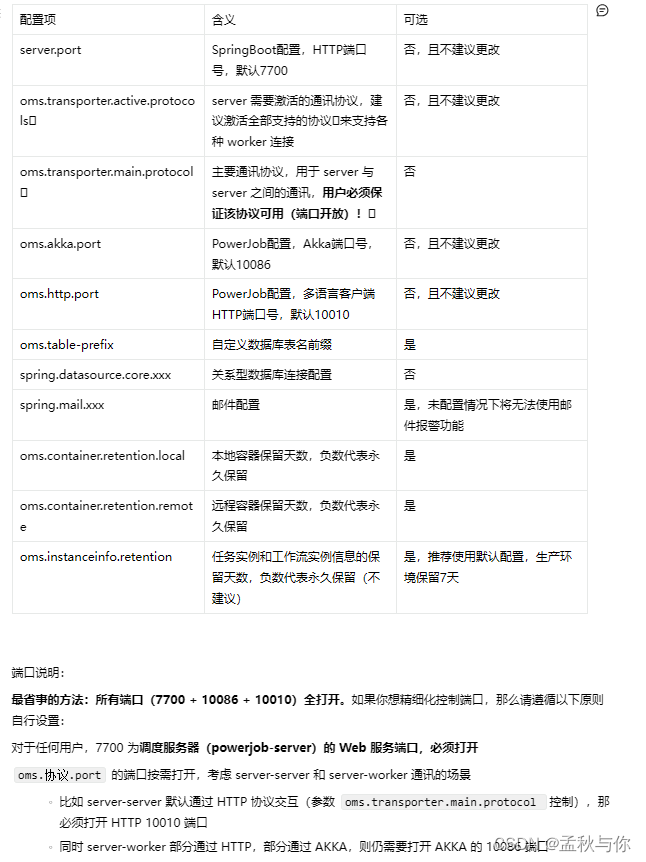
2. 启动powerjob-server: java -jar xxx.jar --spring.profiles.active=product
执行器:
- 引入powerjob starter依赖
<!-- powerjob-worker -->
<dependency>
<groupId>tech.powerjob</groupId>
<artifactId>powerjob-worker-spring-boot-starter</artifactId>
<version>4.3.4</version>
</dependency>
- application配置文件,注意powerjob.worker.server-address,是我们调度器地址,powerjob.worker.app-name与我们调度器中提到的app_info表app_name内容相对应
# Whether to enable PowerJob Worker, default is true
powerjob.worker.enabled=true
# Turn on test mode and do not force the server connection to be verified
powerjob.worker.enable-test-mode=false
# Transport port, default is 27777
powerjob.worker.port=27778
# Application name, used for grouping applications. Recommend to set the same value as project name.
powerjob.worker.app-name=test
# Address of PowerJob-server node(s). Ip:port or domain. Multiple addresses should be separated with comma.
#powerjob.worker.server-address=127.0.0.1:7700,127.0.0.1:7701
powerjob.worker.server-address=127.0.0.1:7700
# transport protocol between server and worker
powerjob.worker.protocol=http
# Store strategy of H2 database. disk or memory. Default value is disk.
powerjob.worker.store-strategy=disk
# Max length of result. Results that are longer than the value will be truncated.
powerjob.worker.max-result-length=4096
# Max length of appended workflow context . Appended workflow context value that is longer than the value will be ignore.
powerjob.worker.max-appended-wf-context-length=4096
- 执行器代码示例:其中注释的代码是模拟工作流场景下的代码,如果不需要使用工作流则忽略。
@Component("WorkingStartProcessors")
public class WorkingStartProcessors implements BasicProcessor {
@Autowired
private WorkingStartJob workingStartJob;
/**
* 第一步:需要先create database powerjob
* 第二步:在app_info表中配置 app name ,与worker (即java服务) 的appname对应, 并设置账号密码(server控制台登录密码)
* 第三步:与xxl job类似,在控制台页面新建任务, 其中全限定类名,也可以填写bean value
* (如本类 被@Component("WorkingStartProcessors")修饰, bean value即为WorkingStartProcessors)
*/
/**
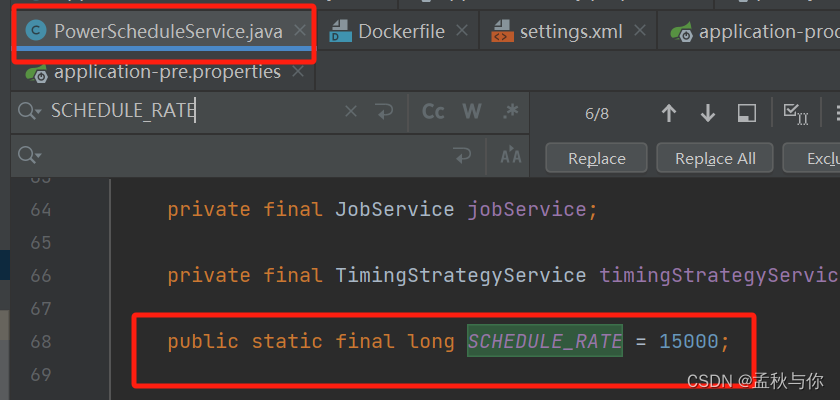
* tips: cron 模式下 最小间隔为15s
* 否则需要修改 powerjob server源码SCHEDULE_RATE数值(不建议)
*/
@Override
public ProcessResult process(TaskContext taskContext) throws Exception {
// do something
//
// WorkflowContext workflowContext = taskContext.getWorkflowContext();
// // 模拟工作流的判断
// if (System.currentTimeMillis() % 2 == 0) {
//
// // 工作流注意事项:
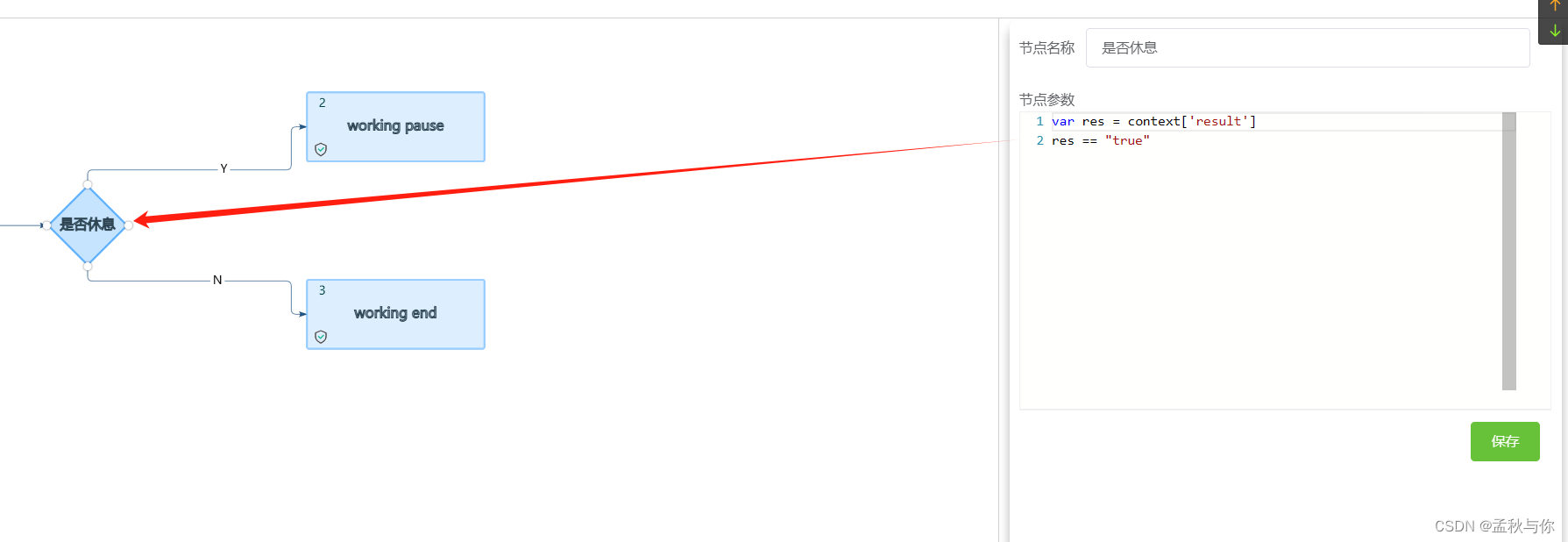
// // 如果有判断节点 需要在代码中声明返回结果 在控制台的流程图中 用var res = context['result'] res == "true"进行判断
// // 流程图的每一个节点都记得要开启
// workflowContext.appendData2WfContext("result",false);
// System.out.println("-------------false-------------");
// } else {
// workflowContext.appendData2WfContext("result",true);
// System.out.println("-------------true-------------");
//
// }
return new ProcessResult(true);
}
}
- 启动执行器
- 控制台界面:
tips: 小于15s时,会按照15s间隔执行,这是powerjob-server源码中限制的
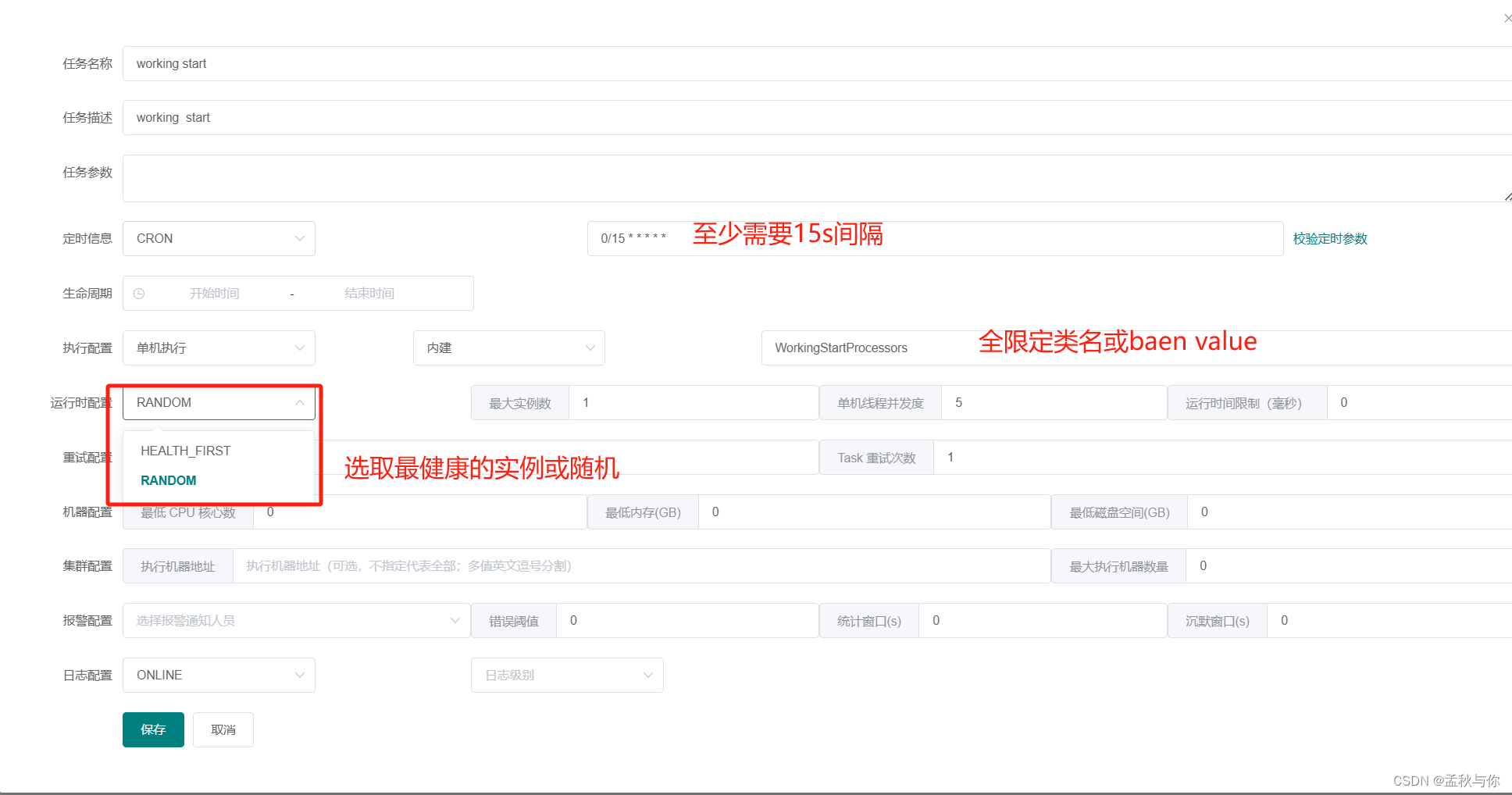
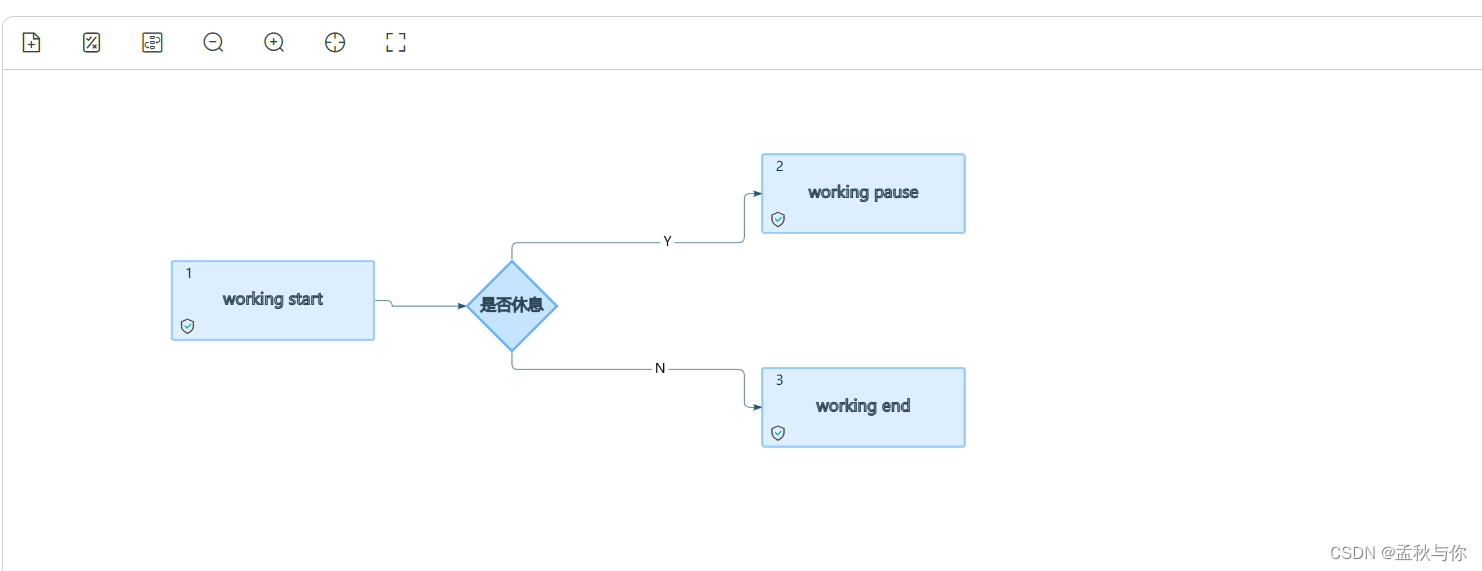
工作流示例 (用不上请忽略):
下图三个节点 都记得点击启用
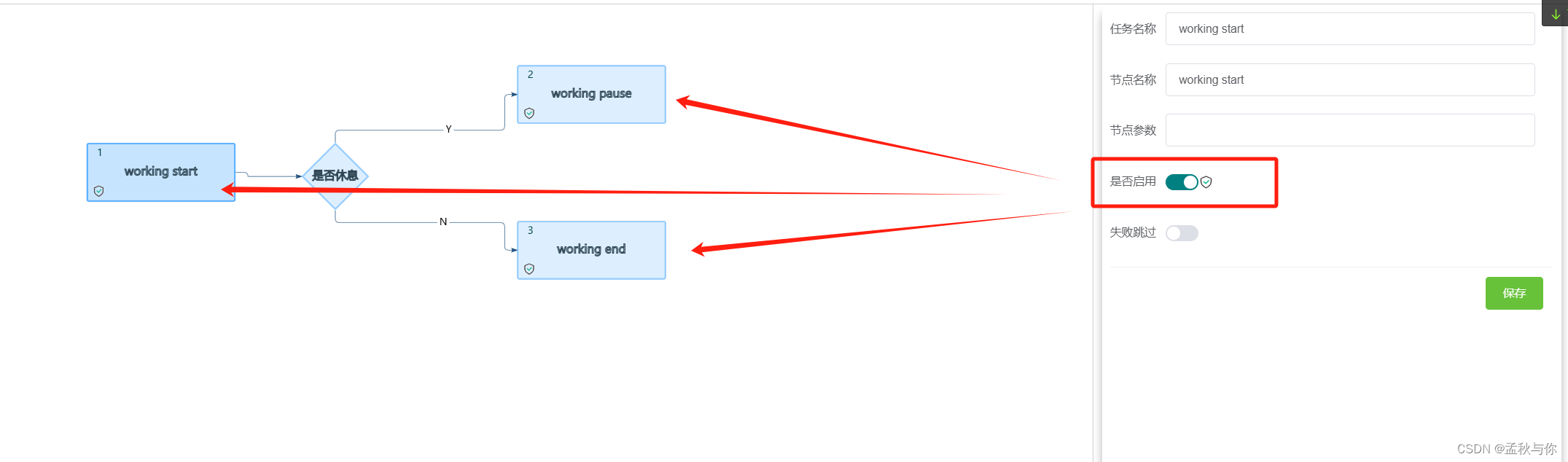
判断节点语法:
(key value是和上文java示例代码中定义的 : workflowContext.appendData2WfContext(“result”,true)😉
总结
powerJob有后发优势 调度任务配置更加灵活, 截至目前仍在维护,功能更全面,但相应的内存占用约为xxl-job的2-3倍,
xxl job用户量会比powerJob庞大,内存占用较小
可以结合实际业务以及服务器资源空闲情况 考虑是否需要使用到灵活配置特性,如服务器资源紧张 在可预见范围内 仅需要基本的定时任务执行功能 推荐 xxl-job, 如服务器资源不紧张 为后续项目灵活性考虑 可选择powerjob。