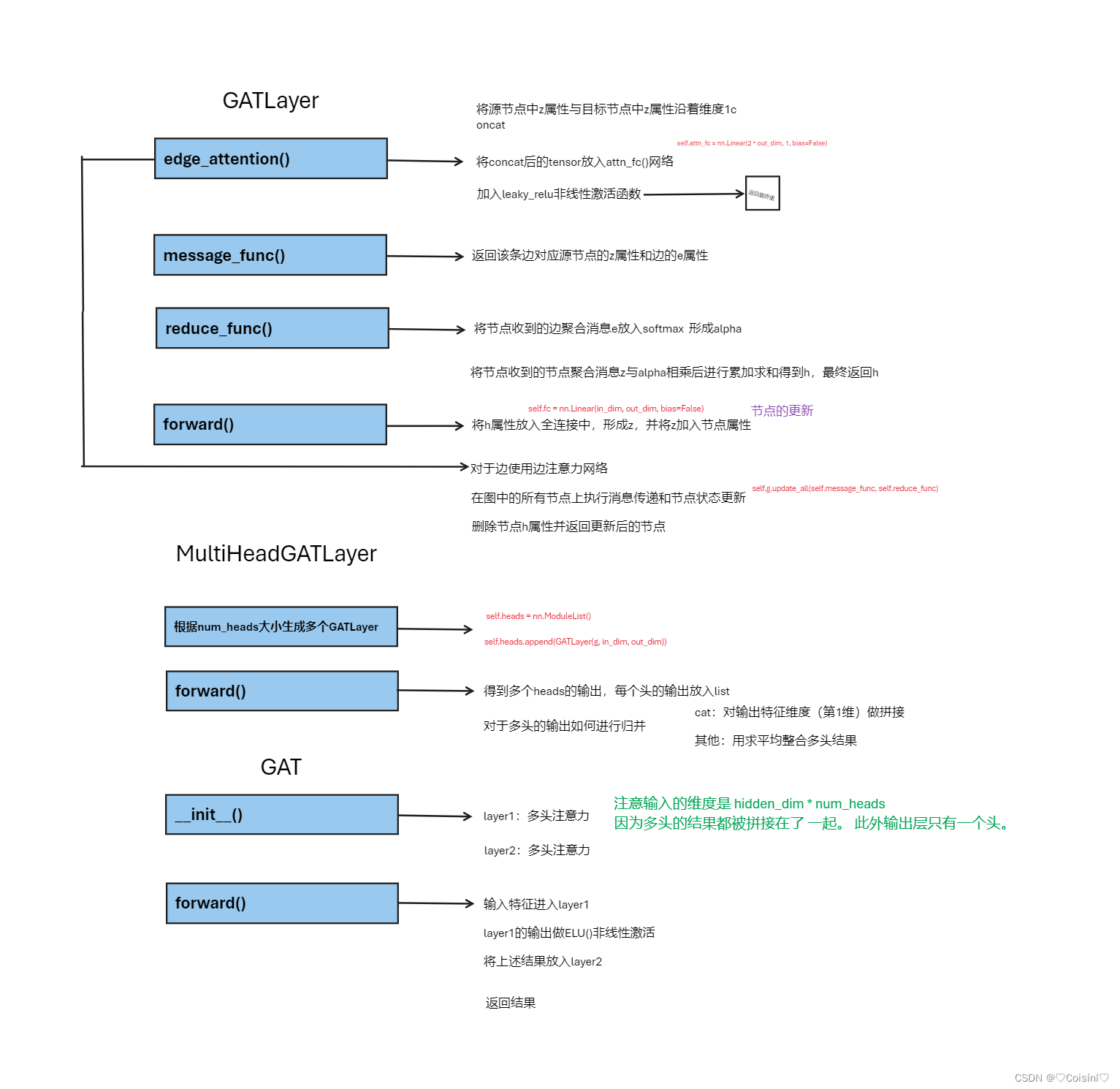
formal文件(在cora数据集上的应用)
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.data import CoraGraphDataset
import time
import numpy as np
from visdom import Visdom
import dgl
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class GATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim):
super(GATLayer, self).__init__()
self.g = g
self.fc = nn.Linear(in_dim, out_dim, bias=False)
self.attn_fc = nn.Linear(2 * out_dim, 1, bias=False)
def edge_attention(self, edges):
z2 = torch.cat([edges.src['z'], edges.dst['z']], dim=1)
a = self.attn_fc(z2)
return {'e': F.leaky_relu(a)}
def message_func(self, edges):
return {'z': edges.src['z'], 'e': edges.data['e']}
def reduce_func(self, nodes):
alpha = F.softmax(nodes.mailbox['e'], dim=1)
h = torch.sum(alpha * nodes.mailbox['z'], dim=1)
return {'h': h}
def forward(self, h):
z = self.fc(h)
self.g.ndata['z'] = z
self.g.apply_edges(self.edge_attention)
self.g.update_all(self.message_func, self.reduce_func)
return self.g.ndata.pop('h')
class MultiHeadGATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim, num_heads, merge='cat'):
super(MultiHeadGATLayer, self).__init__()
self.heads = nn.ModuleList()
for i in range(num_heads):
self.heads.append(GATLayer(g, in_dim, out_dim))
self.merge = merge
def forward(self, h):
head_outs = [attn_head(h) for attn_head in self.heads]
if self.merge == 'cat':
return torch.cat(head_outs, dim=1)
else:
return torch.mean(torch.stack(head_outs))
class GAT(nn.Module):
def __init__(self, g, in_dim, hidden_dim, out_dim, num_heads):
super(GAT, self).__init__()
self.layer1 = MultiHeadGATLayer(g, in_dim, hidden_dim, num_heads)
self.layer2 = MultiHeadGATLayer(g, hidden_dim * num_heads, out_dim, 1)
def forward(self, h):
h = self.layer1(h)
h = F.elu(h)
h = self.layer2(h)
return h
def evaluate(model, features, labels, mask):
model.eval()
with torch.no_grad():
logits = model(features)
logits = logits[mask]
labels = labels[mask]
_, indices = torch.max(logits, dim=1)
correct = torch.sum(indices == labels)
return correct.item() * 1.0 / len(labels)
dataset = CoraGraphDataset('./cora')
graph = dataset[0]
graph = dgl.remove_self_loop(graph)
graph = dgl.add_self_loop(graph)
graph = graph.to(device)
train_mask = graph.ndata['train_mask']
val_mask = graph.ndata['val_mask']
test_mask = graph.ndata['test_mask']
label = graph.ndata['label']
features = graph.ndata['feat']
in_feats = features.shape[1]
n_hidden = 8
n_classes = dataset.num_classes
num_heads = 3
feat_drop = 0.6
attn_drop = 0.5
lr = 0.02
weight_deacy = 3e-4
num_epochs = 31
model = GAT(graph,
in_dim=features.shape[1],
hidden_dim=n_hidden,
out_dim=7,
num_heads=num_heads)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_deacy)
dur = []
vis = Visdom()
x = []
y = []
opt = {
'title': 'GAT on Cora',
'xlabel': 'epoch',
'ylabel': 'loss / acc',
'legend': ['loss', 'val_accuracy']
}
for epoch in range(num_epochs):
if epoch >= 3:
t0 = time.time()
logits = model(features)
logp = F.log_softmax(logits, 1)
loss = F.nll_loss(logp[train_mask], label[train_mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc_val = evaluate(model, features, label, val_mask)
x = epoch
y_loss = loss.cpu().detach().numpy()
y_acc = acc_val
vis.line(
X=[x],
Y=[[y_loss, y_acc]],
win='GAT',
update='append',
opts=opt
)
if epoch >= 3:
dur.append(time.time() - t0)
print("Epoch {:05d} | Loss {:.4f} | Time(s) {:.4f} | Accuracy {:.4f}".format(
epoch, loss.item(), np.mean(dur), acc_val))
acc_test = evaluate(model, features, label, test_mask)
print("Test Accuracy {:.4f}".format(acc_test))
test文件(在6个节点上的二分类应用)
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.data import CoraGraphDataset
import time
import numpy as np
from visdom import Visdom
import dgl
print('----------test: DGL_GAT----------')
device = torch.device('cpu')
class GATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim):
super(GATLayer, self).__init__()
self.g = g
self.fc = nn.Linear(in_dim, out_dim, bias=False)
self.attn_fc = nn.Linear(2 * out_dim, 1, bias=False)
def edge_attention(self, edges):
z2 = torch.cat([edges.src['z'], edges.dst['z']], dim=1)
a = self.attn_fc(z2)
return {'e': F.leaky_relu(a)}
def message_func(self, edges):
return {'z': edges.src['z'], 'e': edges.data['e']}
def reduce_func(self, nodes):
alpha = F.softmax(nodes.mailbox['e'], dim=1)
h = torch.sum(alpha * nodes.mailbox['z'], dim=1)
return {'h': h}
def forward(self, h):
z = self.fc(h)
self.g.ndata['z'] = z
self.g.apply_edges(self.edge_attention)
self.g.update_all(self.message_func, self.reduce_func)
return self.g.ndata.pop('h')
class MultiHeadGATLayer(nn.Module):
def __init__(self, g, in_dim, out_dim, num_heads, merge='cat'):
super(MultiHeadGATLayer, self).__init__()
self.heads = nn.ModuleList()
for i in range(num_heads):
self.heads.append(GATLayer(g, in_dim, out_dim))
self.merge = merge
def forward(self, h):
head_outs = [attn_head(h) for attn_head in self.heads]
if self.merge == 'cat':
return torch.cat(head_outs, dim=1)
else:
return torch.mean(torch.stack(head_outs))
class GAT(nn.Module):
def __init__(self, g, in_dim, hidden_dim, out_dim, num_heads):
super(GAT, self).__init__()
self.layer1 = MultiHeadGATLayer(g, in_dim, hidden_dim, num_heads)
self.layer2 = MultiHeadGATLayer(g, hidden_dim * num_heads, out_dim, 1)
def forward(self, h):
h = self.layer1(h.float())
h = F.elu(h)
h = self.layer2(h.float())
return h
def evaluate(model, features, labels, mask):
model.eval()
with torch.no_grad():
logits = model(features)
logits = logits[mask]
labels = labels[mask]
_, indices = torch.max(logits, dim=1)
correct = torch.sum(indices == labels)
return correct.item() * 1.0 / len(labels)
graph = dgl.graph((torch.tensor([0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1,
2, 2, 2, 2, 2, 2,
3, 3, 3, 3, 3, 3,
4, 4, 4, 4, 4, 4,
5, 5, 5, 5, 5, 5,]),
torch.tensor([0, 1, 2, 3, 4, 5,
0, 1, 2, 3,4, 5,
0, 1, 2, 3, 4, 5,
0, 1, 2, 3, 4, 5,
0, 1, 2, 3, 4, 5,
0, 1, 2, 3, 4, 5,])))
graph.ndata['train_mask'] = torch.tensor([False,True,True,True,False,False])
graph.ndata['val_mask'] = torch.tensor([True,False,False,False,False,False])
graph.ndata['test_mask'] = torch.tensor([False,False,False,False,True,True])
graph.ndata['feat'] = torch.tensor([[0,0,0,0,0,0],[1,1,1,1,1,1],[2,2,2,2,2,2],[3,3,3,3,3,3],[4,4,4,4,4,4],[5,5,5,5,5,5]])
graph.ndata['label'] = torch.tensor([1,2,1,1,2,1])
graph = graph.to(device)
train_mask = graph.ndata['train_mask']
print(graph.ndata['train_mask'])
val_mask = graph.ndata['val_mask']
print(graph.ndata['val_mask'])
test_mask = graph.ndata['test_mask']
print(graph.ndata['test_mask'])
label = graph.ndata['label']
features = graph.ndata['feat']
in_feats = features.shape[1]
print('in_feats:',in_feats)
n_hidden = 8
n_classes = 2
num_heads = 3
feat_drop = 0.6
attn_drop = 0.5
lr = 0.02
weight_deacy = 3e-4
num_epochs = 31
model = GAT(graph,
in_dim=features.shape[1],
hidden_dim=n_hidden,
out_dim=7,
num_heads=num_heads)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_deacy)
dur = []
vis = Visdom()
x = []
y = []
opt = {
'title': 'GAT on Cora',
'xlabel': 'epoch',
'ylabel': 'loss / acc',
'legend': ['loss', 'val_accuracy']
}
for epoch in range(num_epochs):
if epoch >= 3:
t0 = time.time()
logits = model(features)
logp = F.log_softmax(logits, 1)
loss = F.nll_loss(logp[train_mask], label[train_mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc_val = evaluate(model, features, label, val_mask)
x = epoch
y_loss = loss.cpu().detach().numpy()
y_acc = acc_val
vis.line(
X=[x],
Y=[[y_loss, y_acc]],
win='GAT',
update='append',
opts=opt
)
if epoch >= 3:
dur.append(time.time() - t0)
print("Epoch {:05d} | Loss {:.4f} | Time(s) {:.4f} | Accuracy {:.4f}".format(
epoch, loss.item(), np.mean(dur), acc_val))
acc_test = evaluate(model, features, label, test_mask)
print("Test Accuracy {:.4f}".format(acc_test))
print(graph.ndata['z'][1])